Every robust data architecture begins with a blueprint. In the world of relational data, that blueprint is the Entity-Relationship Diagram, or ERD. It serves as the visual contract between business logic and technical implementation. When you perform an ERD review, you are not merely inspecting lines and boxes; you are validating the structural integrity of the information ecosystem. A flawed model leads to data anomalies, performance bottlenecks, and costly refactoring later. This guide details the critical checkpoints for auditing a database model, ensuring clarity, consistency, and scalability.
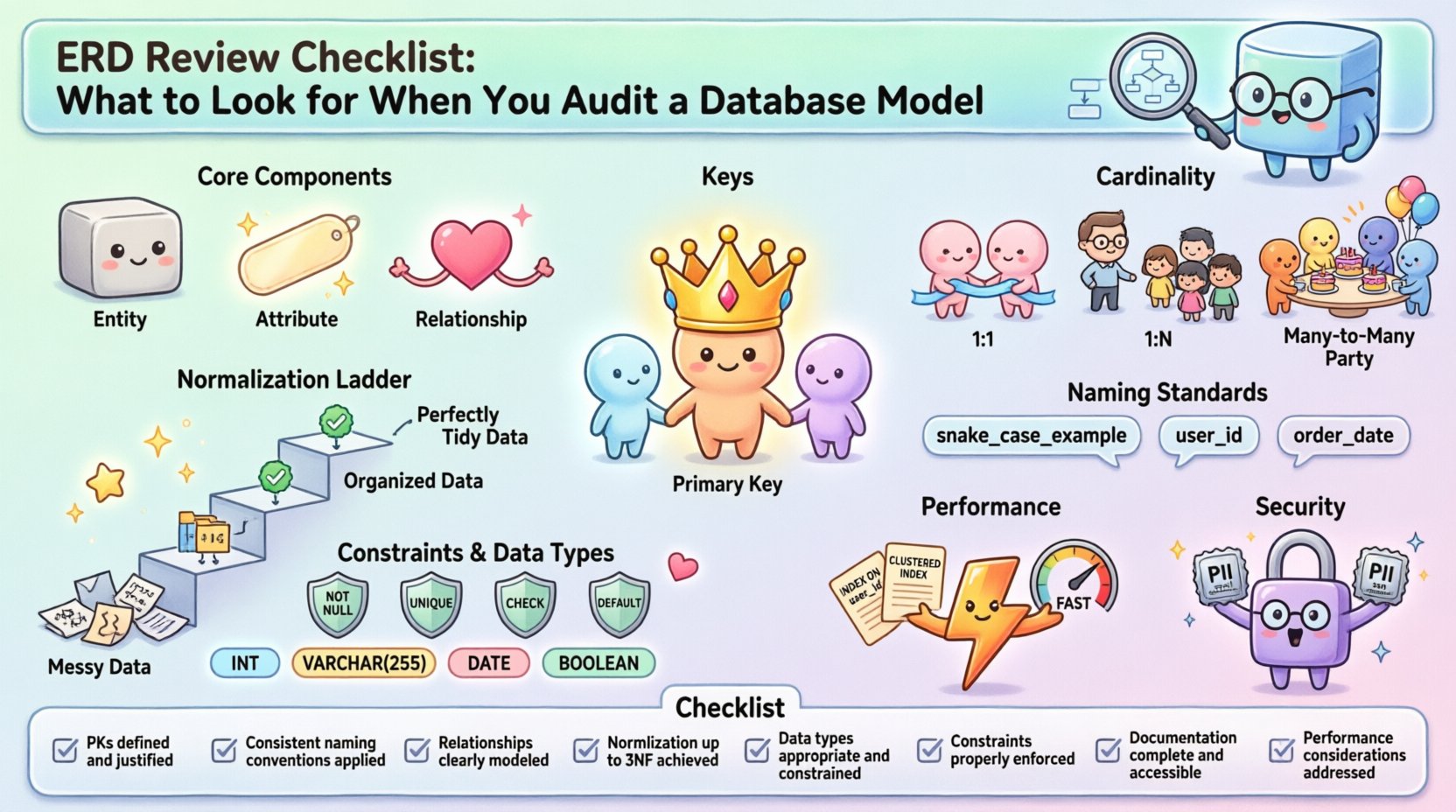
Understanding the Core Components 🧱
Before diving into the audit, you must understand what constitutes a healthy model. An ERD consists of three primary elements: entities, attributes, and relationships. Each element carries weight in how data is stored, retrieved, and maintained.
- Entities: Represent real-world objects or concepts (e.g., Customer, Product, Order). In the model, these become tables.
- Attributes: Define the characteristics of an entity (e.g., Name, Price, Date). These become columns.
- Relationships: Define how entities interact (e.g., A Customer places an Order). These define foreign keys and constraints.
During the initial review, verify that every entity has a clear purpose. Avoid entities that are too granular or too broad. An entity should represent a distinct concept that requires its own storage and identity.
Evaluating Primary and Foreign Keys 🔑
Keys are the backbone of relational integrity. Without them, data becomes unlinked and unreliable. An audit must scrutinize how keys are defined and utilized.
Primary Keys (PK)
Every table must have a unique identifier. This is the Primary Key. During the review, check for the following:
- Uniqueness: Does the PK guarantee no duplicate rows? Composite keys should be avoided unless necessary, as they complicate joins.
- Stability: Will the key value ever change? Surrogate keys (auto-incrementing integers) are often preferred over natural keys (like email addresses) for stability.
- Nullability: A primary key column cannot contain null values. Ensure the constraint is explicitly set.
Foreign Keys (FK)
Foreign keys establish the link between tables. They enforce referential integrity, preventing orphaned records. When auditing relationships, look for:
- Correct Data Types: The foreign key column must match the data type of the referenced primary key. Mismatches lead to errors during insertion or updates.
- Constraint Enforcement: Are cascading updates or deletes defined correctly? If a parent record is deleted, should child records vanish, or should they remain but become orphaned? This decision impacts data safety.
- Naming Conventions: Are foreign keys named consistently? For example,
customer_idshould always be the reference to thecustomerstable.
Relationships and Cardinality 🔗
Cardinality defines the numerical relationship between entities. Misinterpreting this is one of the most common causes of modeling errors. You need to verify that the diagram matches the business rules.
| Cardinality Type | Definition | Implementation Example |
|---|---|---|
| One-to-One (1:1) | A single record in Table A links to exactly one record in Table B. | Employee linked to Office Key. |
| One-to-Many (1:N) | One record in Table A links to multiple records in Table B. | Department has many Employees. |
| Many-to-Many (M:N) | Multiple records in Table A link to multiple records in Table B. | Student enrolls in many Courses. |
Common Pitfalls:
- Missing Junction Tables: A Many-to-Many relationship cannot exist directly in a relational model. It requires a junction table (associative entity) to break it down into two One-to-Many relationships.
- Optional vs. Mandatory: Is the relationship optional? For example, can an Order exist without a Customer? Usually, no. Ensure optionality is reflected in the nullability of the foreign key column.
- Recursive Relationships: Sometimes an entity relates to itself (e.g., an Employee has a Manager who is also an Employee). Ensure the self-referencing foreign key is defined correctly.
Normalization and Data Integrity ⚖️
Normalization is the process of organizing data to reduce redundancy and improve integrity. While the goal is typically Third Normal Form (3NF), the audit must understand why certain denormalization might have occurred.
First Normal Form (1NF)
Ensure there are no repeating groups. Each column should contain atomic values. If a table has a column for Phone_Numbers containing multiple numbers separated by commas, it violates 1NF. This must be split into separate rows.
Second Normal Form (2NF)
All non-key attributes must be fully dependent on the primary key. If you have a composite key (A + B), attributes should depend on both A and B, not just A. This prevents partial dependency anomalies.
Third Normal Form (3NF)
No transitive dependencies. Non-key attributes should depend only on the primary key, not on other non-key attributes. For example, in a Orders table, you should not store Customer_Address if Customer_ID links to a Customers table. Storing the address there duplicates data and creates update anomalies.
Naming Standards and Readability 🏷️
Code and models are read more often than they are written. A consistent naming convention is essential for maintainability. It reduces cognitive load for developers and analysts.
- Entity Names: Use singular nouns for tables (e.g.,
Customer, notCustomers). This aligns with the concept that a table represents a type of object, not a collection. - Attribute Names: Use descriptive, lowercase names with underscores for spaces (e.g.,
first_name,order_date). - Avoid Special Characters: Do not use hyphens, spaces, or reserved keywords (like
orderorgroup) in table or column names unless escaped. - Prefixes: If using specific schemas, consider prefixing columns (e.g.,
cust_idinstead ofid) to avoid ambiguity in joins.
During the audit, check for consistency. If one table uses created_at and another uses date_created, standardize them. Inconsistent naming leads to SQL errors and confusion.
Constraints and Data Types 🛡️
The model dictates the rules of the database engine. Data types and constraints prevent invalid data from entering the system.
Data Types
- Specificity: Do not use generic types like
VARCHAR(255)for everything. If a phone number will never exceed 15 characters, useVARCHAR(15). This saves space. - Date and Time: Distinguish between
DATE(just the day) andTIMESTAMP(date and time). Mixing these can lead to timezone errors. - Boolean: Use proper boolean types rather than integers (0/1) for flags. It improves readability.
Constraints
- NOT NULL: Critical fields like IDs or required business data must be marked as not null.
- UNIQUE: Ensure business rules like unique email addresses or SKUs are enforced at the database level, not just the application level.
- CHECK: Use check constraints to limit value ranges. For example, ensure a discount percentage does not exceed 100.
Performance and Indexing Strategy ⚡
A model that works logically might fail physically. Indexing is the bridge between structure and speed. While you do not need to design every index during the ERD phase, you must evaluate potential performance bottlenecks.
- Foreign Keys: Foreign keys should be indexed. Without an index, joining tables or deleting parent records can lock the entire child table, causing severe performance degradation.
- Search Columns: Identify columns that are frequently used in WHERE clauses. These are candidates for indexing.
- Join Complexity: Deeply nested relationships (A links to B, B links to C, C links to D) require multiple joins. Consider if denormalization is acceptable to reduce query complexity.
- Large Text Fields: Columns storing large text (CLOBs) can slow down queries. Ensure they are separated from the main transactional tables if not always needed.
Security and Access Control Considerations 🔐
Data security starts at the model level. Sensitive information must be identifiable and protected.
- PII Classification: Identify columns containing Personally Identifiable Information (PII) such as SSNs or Credit Card numbers. These should be flagged for encryption or masking.
- Logical Separation: Consider if sensitive data needs to be in a separate table to limit access permissions (Row Level Security).
- Audit Trails: Does the model support tracking changes? Include fields like
created_by,modified_by, andversionto track data lineage.
The ERD Audit Checklist 📋
To streamline the review process, use this checklist. It covers the structural, logical, and physical aspects of the model.
| Item | Check | Priority |
|---|---|---|
| All Tables Have PKs | Verify every table has a unique primary key defined. | High |
| Consistent Naming | Check for snake_case and singular nouns. | Medium |
| Relationships Defined | Ensure all foreign keys are explicitly defined in the diagram. | High |
| Normalization | Verify 3NF compliance or document exceptions. | High |
| Data Types | Ensure specific types are used instead of generic ones. | Medium |
| Constraints | Check for NOT NULL, UNIQUE, and CHECK constraints. | High |
| Documentation | Are tables and columns described with comments? | Low |
| Performance | Are FKs indexed? Are large text fields separated? | Medium |
Handling Evolution and Version Control 🔄
Database models are not static. They evolve as business requirements change. The audit should also assess how the model handles change.
- Migration Paths: If you change a data type or rename a column, can the system migrate without downtime? The model should support additive changes.
- Versioning: The ERD itself should be versioned. Changes to the schema should be tracked alongside application code.
- Backward Compatibility: When adding new attributes, ensure existing reports or applications do not break. Avoid removing columns without a deprecation period.
Conclusion and Impact Summary 📊
An ERD review is a critical step in the data lifecycle. It prevents technical debt before it accumulates. By rigorously checking entities, keys, relationships, and constraints, you ensure the database remains a reliable asset rather than a liability. The effort invested in auditing the model pays dividends in query performance, data accuracy, and developer productivity. Treat the diagram as the source of truth, and validate it against the reality of your business operations.