Database design is the backbone of any robust software application. Yet, even experienced engineers often stumble when explaining the distinction between the visual blueprints and the physical implementation. The confusion typically lies between the Entity-Relationship Diagram (ERD) and the Database Schema. While these terms are frequently used interchangeably in casual conversation, they represent distinct layers of the data architecture process. Understanding the nuance between them is not merely academic; it dictates how data flows, how constraints are enforced, and how the system evolves over time.
In this guide, we will dissect the theoretical constructs of data modeling against the practical realities of database management systems. We will explore how abstract concepts transform into concrete structures, the implications of this transformation, and why maintaining a clear mental separation between the two is vital for long-term maintainability. Whether you are designing a new system or refactoring an existing one, clarity here prevents costly technical debt.
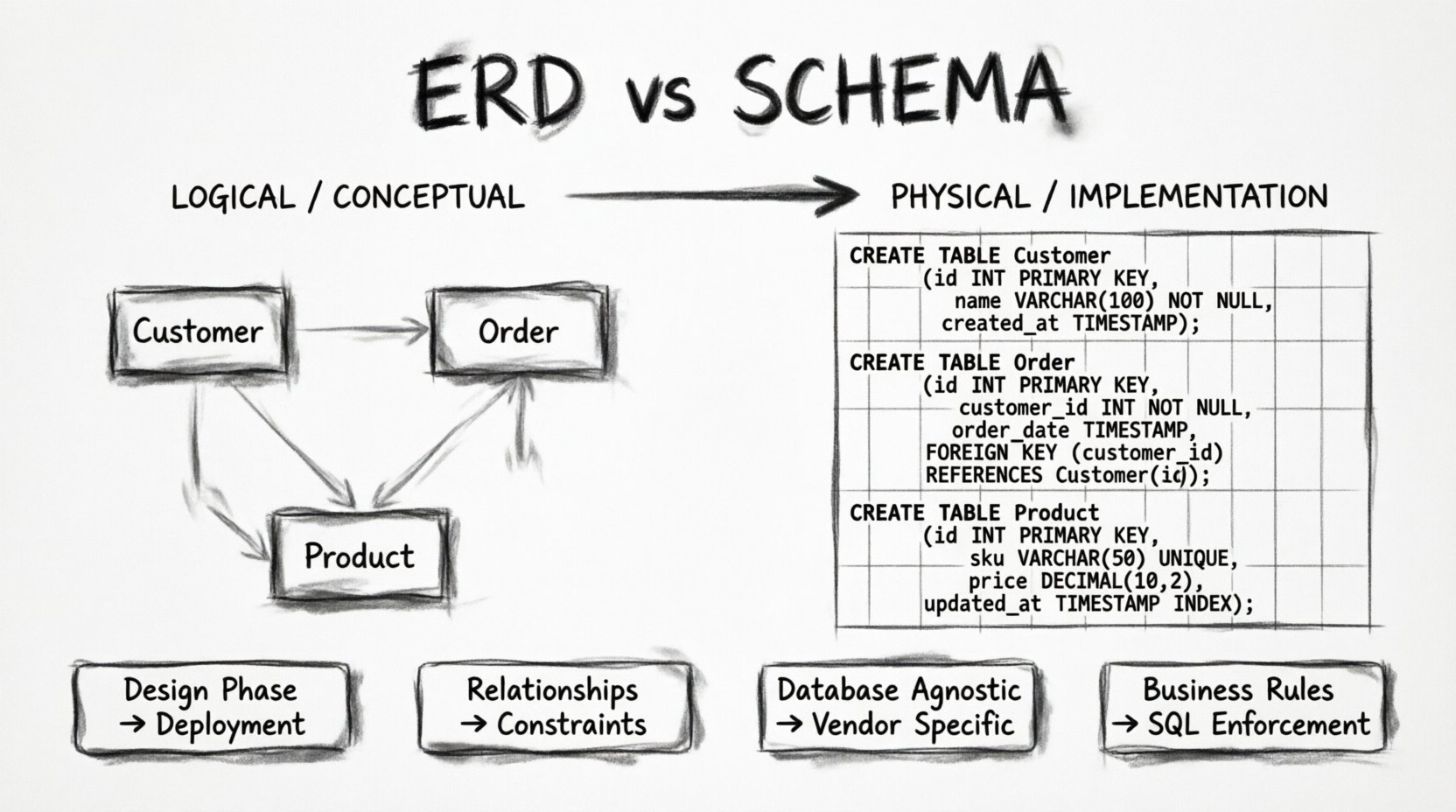
What Exactly is an ERD? 📐
The Entity-Relationship Diagram is a conceptual or logical representation of data. It serves as the communication bridge between business stakeholders, analysts, and developers. Its primary purpose is to visualize how data elements relate to one another without getting bogged down in the specifics of a specific database engine.
At its core, an ERD focuses on three fundamental components:
- Entities: These represent real-world objects or concepts. In a retail system, an entity might be Customer, Product, or Order. Entities are the nouns of your data universe.
- Attributes: These are the properties or characteristics that describe an entity. For a Customer, attributes could include First Name, Email Address, or Registration Date. Attributes define what data we need to store about the entity.
- Relationships: This defines how entities interact. Does one customer place many orders? Does one product belong to multiple categories? Relationships are the verbs connecting the nouns.
The beauty of an ERD lies in its abstraction. It does not care if the data will eventually live in PostgreSQL, MySQL, or a NoSQL document store. It cares about the integrity of the information and the logical flow. Notation styles vary, with Crow’s Foot notation being a common standard for depicting cardinality (one-to-one, one-to-many, many-to-many). This visual language allows teams to validate the logic of the data model before a single line of code is written.
When creating an ERD, the focus is on normalization. This involves organizing data to reduce redundancy and improve data integrity. We look at how to break down large tables into smaller, related ones to ensure that updating a piece of information in one place updates it everywhere it matters. The ERD is the map of the territory; it shows the roads and the landmarks but not the specific pavement material.
Defining the Database Schema 🏗️
If the ERD is the map, the Schema is the territory itself. The database schema is the physical structure of the database. It is the concrete set of definitions that tells the database management system (DBMS) exactly how to store data. While the ERD speaks in concepts, the schema speaks in data types, constraints, and storage engines.
A schema defines the following technical specifics:
- Tables: The ERD entity becomes a physical table. The schema specifies the table name, which must often adhere to strict naming conventions (e.g., snake_case).
- Data Types: An attribute like Age becomes an
INTorSMALLINT. An Email becomes aVARCHARwith a specific length limit. A Timestamp becomesTIMESTAMP WITH TIME ZONE. These choices impact storage space and query performance. - Constraints: This is where the logic of the ERD is enforced. Primary Keys (PK) ensure uniqueness. Foreign Keys (FK) enforce referential integrity between tables.
NOT NULLconstraints ensure mandatory fields are populated. Unique constraints prevent duplicate entries. - Indexes: While often omitted from high-level ERDs, the schema determines where indexes are built. Indexes speed up read operations but slow down writes. The schema dictates the physical optimization of the database.
The schema is also responsible for security and access control. It defines who can read or write to specific tables. It handles transactions, ensuring that data changes are atomic. When a developer writes a CREATE TABLE statement, they are defining the schema. This is the implementation layer that the application code interacts with directly.
Key Differences at a Glance 📊
To clarify the distinction, it helps to view the differences side-by-side. The ERD is abstract and design-oriented, while the schema is concrete and implementation-oriented.
| Feature | ERD (Entity-Relationship Diagram) | Database Schema |
|---|---|---|
| Nature | Logical / Conceptual Model | Physical Model |
| Focus | Relationships and Data Flow | Storage and Enforcement |
| Notation | Boxes, Lines, Crow’s Foot Symbols | SQL Statements, DDL Scripts |
| Dependency | Database Agnostic | Database Specific (Vendor) |
| Constraints | Implied (Business Rules) | Explicit (PK, FK, Check) |
| Stage | Design Phase | Development / Deployment Phase |
This table highlights that while they are linked, they operate at different stages of the software lifecycle. Confusing the two often leads to developers trying to force physical constraints onto a logical model before it is fully validated.
The Translation Process: From Diagram to Code 🔄
The journey from ERD to Schema is not always a direct 1:1 mapping. This translation layer is where many projects encounter friction. The logical model assumes ideal conditions, but the physical model must contend with performance, legacy systems, and specific engine capabilities.
Normalization vs. Performance
An ERD is typically normalized to the Third Normal Form (3NF). This minimizes data duplication. However, when translating to a schema for a high-traffic application, developers often denormalize. This means intentionally duplicating data to reduce the number of joins required during a query. For example, storing the Customer Name directly on the Order table, even if it violates strict normalization rules, can significantly speed up reporting queries. The ERD might show a relationship, but the schema might store the data redundantly for speed.
Data Type Specifics
An ERD simply says a field is a Date. The schema must decide between DATE, DATETIME, or TIMESTAMP. It must decide on character sets (UTF8, ASCII) and collation rules. These decisions affect how the application handles internationalization and sorting. A generic ERD cannot capture these nuances.
Handling Many-to-Many Relationships
In an ERD, a Many-to-Many relationship is drawn as a line with double crow’s feet. In the physical schema, this cannot exist directly. It must be resolved into two One-to-Many relationships via a junction table (or bridge table). The schema must define the primary key of this junction table, which might be a composite key or a surrogate key (UUID). This structural change is invisible in the high-level diagram but critical in the database structure.
Why the Distinction Matters for Developers 🛠️
Understanding the gap between these two concepts is not just about theory; it impacts daily work. When a bug arises in data integrity, knowing whether the issue lies in the logical design or the physical implementation is the first step to resolution.
Debugging Data Integrity
If you encounter a situation where data is being duplicated unexpectedly, you need to ask: Is the ERD flawed, or is the schema constraint missing? A missing Foreign Key in the schema allows orphaned records that the ERD logic assumed were impossible. Conversely, if the ERD is too rigid and doesn’t account for soft-deletes, the schema might enforce hard deletes that break business logic. Separating the concerns allows you to pinpoint the source of the error.
Version Control and Collaboration
When managing a database, version control is essential. However, ERDs and Schemas evolve differently. The ERD changes when the business requirements change. The Schema changes when the database needs optimization or when migrations are applied. Keeping them synchronized is a challenge. If the Schema changes without updating the ERD, the documentation becomes obsolete. If the ERD changes without a migration script, the database remains inconsistent with the design.
Onboarding New Team Members
New developers often struggle to understand the database structure. Showing them an ERD provides the context of how the system works conceptually. Showing them the Schema provides the context of how the system works technically. Effective onboarding requires both. The ERD answers “What does this mean?” and the Schema answers “How do I access it?”.
Common Pitfalls in Data Modeling 🚧
Despite the clear definitions, many teams fall into traps when treating the ERD and Schema as identical.
- Skipping the ERD: Jumping straight to writing SQL schema scripts often leads to structural debt. Without a visual model, relationships are often forgotten or implemented inconsistently.
- Ignoring Constraints: Relying solely on application code to enforce rules (like unique emails) rather than database constraints (UNIQUE indexes) is risky. The schema should be the last line of defense for data integrity.
- Over-Engineering: Creating an ERD that is too detailed with every possible attribute before the requirements are clear. This leads to a schema that is difficult to migrate later.
- Tool Disconnect: Using a design tool that does not support code generation, or using a database tool that does not support reverse engineering. This creates a manual gap where changes are made in one place but not the other.
- Assuming Equivalence: Believing that a perfect ERD guarantees a perfect database. The schema is subject to hardware limitations, query patterns, and concurrency issues that the ERD cannot foresee.
Maintaining Synchronization Over Time 🔄
As an application grows, the database evolves. Features are added, and old features are deprecated. Maintaining the link between the ERD and the Schema becomes harder over time. This is often called schema drift.
To combat this, teams should adopt a strict workflow:
- Design First: Always update the ERD before writing migration scripts.
- Automate Generation: Use tools that can generate SQL DDL from the ERD. This ensures the schema matches the design.
- Reverse Engineering: Periodically run reverse engineering tools on the live database to update the ERD. This catches changes made by direct SQL queries that bypass the design process.
- Documentation: Ensure the ERD is stored in the same repository as the schema migration scripts. This creates a single source of truth.
This discipline prevents the database from becoming a black box. When the ERD and Schema are in sync, the system remains transparent and manageable.
Impact on Query Performance and Optimization ⚡
The schema dictates performance more than the ERD. While the ERD shows relationships, the schema determines how the database engine accesses the data. An ERD might show a logical join between Users and Posts. The schema determines if an index exists on the User_ID in the Posts table.
Without proper indexing in the schema, a simple query can trigger a full table scan. This is a physical constraint. The ERD cannot show you the execution plan. Developers must look at the schema to understand why a query is slow. They must analyze the indexes, the partitioning strategy, and the data types.
Furthermore, the schema handles locking mechanisms. If multiple users update the same record, the schema’s isolation level and locking strategy determine if they block each other. The ERD is silent on concurrency. This is a crucial distinction for high-load systems.
Bridging the Gap with Best Practices 🏆
To ensure both models serve their purpose effectively, consider adopting these standards:
- Use Standard Naming Conventions: Ensure table names in the schema match the entity names in the ERD. Consistency reduces cognitive load.
- Document Constraints Explicitly: In the ERD, annotate relationships with cardinality. In the Schema, annotate columns with their constraints. Make the rules visible in both places.
- Review Regularly: Schedule quarterly reviews of the ERD against the production schema. Look for drift and anomalies.
- Separate Concerns: Treat the ERD as a business artifact and the Schema as a technical artifact. Do not mix business logic into the physical schema definitions.
- Plan for Migration: When the ERD changes, the Schema must change via a migration script. Never alter the schema directly in production without a versioned script.
The Human Element of Data Modeling 👥
Ultimately, these models are created for people, not just machines. The ERD is for communication. It allows a product manager to understand the data structure without knowing SQL. The Schema is for the machine. It allows the application to retrieve data efficiently.
When developers understand this human-machine divide, they can design better systems. They know when to simplify the ERD for stakeholders and when to detail the Schema for the database engine. This duality is the essence of database architecture.
By respecting the boundary between the logical diagram and the physical implementation, teams avoid the common pitfalls of data corruption and performance bottlenecks. The ERD provides the vision; the Schema provides the reality. Both are required for a successful system.
Final Thoughts on Data Architecture 🧠
The distinction between an Entity-Relationship Diagram and a Database Schema is a fundamental pillar of software engineering. It represents the transition from thought to action, from idea to execution. While the ERD captures the relationships and logic that drive the business, the Schema captures the constraints and structures that drive the application.
Mastering the relationship between these two models is not about memorizing definitions. It is about understanding the lifecycle of data. It is about knowing that a change in the diagram requires a change in the code, and that a change in the code must reflect back to the diagram. This cycle ensures that the system remains coherent, reliable, and scalable.
As you move forward in your development journey, keep these two models distinct. Use the ERD to plan and communicate. Use the Schema to build and enforce. When you align them, you build systems that stand the test of time and change.
Remember, the goal is not just to store data, but to store it in a way that makes sense. That sense comes from the logical clarity of the ERD and the structural rigor of the Schema. Together, they form the foundation of your data architecture.