








Diseñar un esquema de base de datos robusto es una de las tareas más críticas en el desarrollo de software. Un diagrama de entidades y relaciones (ERD) sirve como plano de construcción para tu arquitectura de datos. Si la base está defectuosa, la aplicación construida sobre ella tendrá problemas con el rendimiento, la integridad de los datos y la escalabilidad. Antes de entregar un modelo de base de datos a los desarrolladores o equipos de despliegue, es esencial un proceso de revisión riguroso. Esta guía describe diez pasos esenciales para validar tu ERD, asegurando que tu estructura de datos esté lista para producción.
Un ERD bien estructurado minimiza la redundancia, impone restricciones y aclara las relaciones entre entidades de datos. Saltarse los pasos de validación suele conducir a una reestructuración costosa más adelante en el ciclo de desarrollo. Esta lista de verificación cubre convenciones de nomenclatura, normalización, restricciones y estándares de documentación. Sigue estos pasos para asegurarte de que tu modelo sea confiable y mantenible.
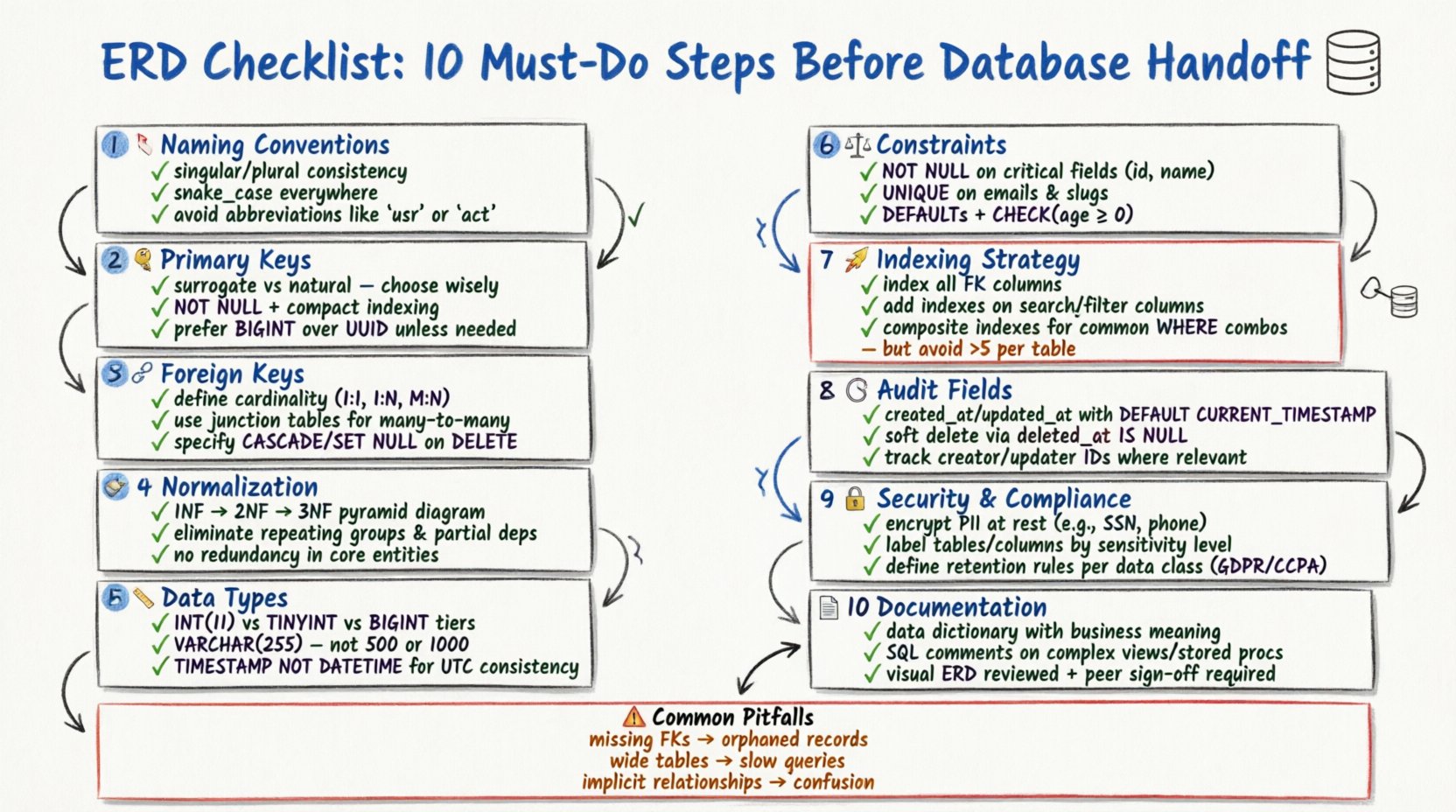
1. Verifica las convenciones de nomenclatura de entidades 🏷️
La consistencia en la nomenclatura es la primera línea de defensa contra la confusión. Cada tabla (entidad) y columna (atributo) debe seguir una convención de nomenclatura estandarizada. Los nombres incoherentes generan ambigüedad durante la escritura de consultas SQL y el mantenimiento.
- Utiliza de forma consistente el singular o el plural: Elige un estilo para los nombres de tablas (por ejemplo,
UsuariovsUsuarios) y aplícalo en todo el esquema. Los nombres en singular suelen preferirse para el modelado conceptual, mientras que los nombres en plural suelen usarse para la implementación física. - Evita palabras reservadas: Asegúrate de que ningún nombre de entidad o columna entre en conflicto con palabras reservadas específicas de la base de datos (por ejemplo,
Orden,Grupo,Índice). El uso de palabras reservadas suele requerir el uso de caracteres de escape, lo que reduce la legibilidad del código. - Utiliza guiones bajos como separadores: Adopta la convención snake_case para columnas y tablas (por ejemplo,
perfil_usuario) para mantener la legibilidad entre diferentes motores de bases de datos. - Excluye abreviaturas: Evita abreviaturas a menos que sean universalmente reconocidas.
id_clientees mejor quecid. La claridad siempre debe prevalecer sobre la brevedad.
2. Define la estrategia de clave primaria 🔑
Cada tabla debe tener un identificador único para distinguir los registros. La elección de la clave primaria afecta el rendimiento, el índice y las relaciones de datos.
- Claves sustitutas frente a claves naturales:Decida si utilizar una clave sustituta (un ID artificial como un entero autoincremental o un UUID) o una clave natural (datos que ya existen, como una dirección de correo electrónico). Las claves sustitutas suelen preferirse por su estabilidad, ya que las claves naturales pueden cambiar con el tiempo.
- Implicaciones de indexación:Las claves primarias se indexan automáticamente. Asegúrese de que el tipo de clave elegido sea compacto. Las claves grandes (como cadenas largas) pueden aumentar el tamaño de los índices y ralentizar las operaciones de unión.
- Restricciones de unicidad:Marque explícitamente la columna clave primaria como
NO NULO. Una clave primaria no puede contener valores nulos en ninguna circunstancia. - Claves compuestas:Si una tabla requiere una clave primaria compuesta (varias columnas), asegúrese de que cada relación que hace referencia a esta tabla pueda manejar múltiples columnas. Esto puede complicar las restricciones de clave foránea.
3. Mapee las relaciones de clave foránea 🔗
Las relaciones definen cómo interactúan las entidades. Un mapeo incorrecto de relaciones conduce a datos huérfanos y problemas de integridad referencial.
- Cardinalidad:Defina claramente si una relación es uno a uno, uno a muchos o muchos a muchos. Uno a muchos es el patrón más común en bases de datos relacionales.
- Resolución de muchas a muchas:Una relación muchos a muchos requiere una tabla de unión (tabla de enlace). Asegúrese de que esta tabla incluya las claves foráneas de ambas entidades principales y, si es necesario, sus propios atributos.
- Acciones referenciales:Especifique cómo debe manejar la base de datos las actualizaciones o eliminaciones. Las opciones comunes incluyen
CASCADEO(eliminar los registros secundarios),ESTABLECER NULO, oRESTRICTO(prevenir la eliminación). Elija según los requisitos de lógica de negocio. - Referencia a sí misma:Si una tabla se referencia a sí misma (por ejemplo, una tabla de empleados con una columna de gerente), etiquétela claramente para evitar confusiones durante la revisión del esquema.
4. Aplicar reglas de normalización de datos 🧹
La normalización reduce la redundancia de datos y mejora la integridad. Aunque los sistemas modernos a veces desnormalizan para mejorar el rendimiento, comprender las formas es crucial.
| Forma normal | Requisito | Beneficio |
|---|---|---|
| 1FN (Primera Forma Normal) | Valores atómicos, sin grupos repetidos | Asegura que cada celda contenga un solo valor |
| 2FN (Segunda Forma Normal) | Sin dependencias parciales | Asegura que las columnas no clave dependan de toda la clave |
| 3FN (Tercera Forma Normal) | Sin dependencias transitivas | Asegura que las columnas no clave dependan únicamente de la clave |
- Evitar redundancia: Si un trozo de información se almacena en múltiples tablas, debería almacenarse en un solo lugar para evitar anomalías de actualización.
- Equilibrar con el rendimiento: La normalización estricta puede llevar a combinaciones complejas. Documente cualquier decisión intencional de denormalización realizada con fines de optimización de consultas.
- Verificar dependencias de datos: Asegúrese de que las columnas dependan lógicamente de la clave primaria y no de otras columnas no clave.
5. Seleccione tipos de datos adecuados 📏
Elegir el tipo de dato incorrecto desperdicia espacio de almacenamiento y puede provocar errores de cálculo.
- Precisión de enteros: Use
TINYINTpara números pequeños (0-255) yBIGINTpara identificadores grandes. No useINTpara todo siSMALLINTes suficiente. - Longitudes de cadenas: Evite usar genéricos
TEXTOoVARCHAR(MAX)a menos que sea necesario. Defina longitudes específicas (por ejemplo,VARCHAR(50)para un código de estado) para imponer límites de datos y mejorar la eficiencia de indexación. - Fecha y hora: Use
TIMESTAMPoDATETIMEdependiendo de los requisitos de zona horaria. Asegúrese de que el formato sea consistente (ISO 8601 es una norma). Evite almacenar fechas como cadenas. - Valores booleanos: Use un tipo booleano nativo si está disponible. Si no, use
TINYINT(1)oCHAR(1). Evite almacenar valores booleanos como cadenas (“sí”/”no”).
6. Imponga restricciones y valores predeterminados ⚖️
Las restricciones protegen la calidad de los datos a nivel de base de datos. Depender únicamente de la validación a nivel de aplicación es arriesgado.
- No nulo: Marque las columnas críticas como
NO NULO. Esto evita que los datos faltantes corrupten informes o lógica. - Restricciones únicas: Aplicar restricciones únicas a columnas como direcciones de correo electrónico o nombres de usuario para evitar entradas duplicadas.
- Valores predeterminados: Establezca valores predeterminados razonables para las columnas de estado (por ejemplo,
estado = 'activo') o marcas de tiempo para evitar errores de entrada manual. - Restricciones de verificación:Utilice restricciones de verificación para validar reglas de negocio (por ejemplo,
edad > 18oprecio > 0). Esto garantiza que los datos cumplan con reglas lógicas independientemente de la fuente.
7. Planifique la estrategia de índices 🚀
Los índices aceleran la recuperación de datos, pero ralentizan las operaciones de escritura. Es necesario un enfoque equilibrado.
- Índices de claves foráneas:Siempre indexe las columnas de claves foráneas. Esto es fundamental para el rendimiento de las operaciones de unión entre tablas.
- Columnas de búsqueda:Identifique las columnas utilizadas con frecuencia en
WHERE,ORDER BY, oGROUP BYcláusulas. Agregue índices a estas columnas. - Índices compuestos: Si las consultas filtran en múltiples columnas, cree un índice compuesto. El orden de las columnas en el índice es importante y debe coincidir con los patrones de consulta.
- Evite el sobreíndice:Demasiados índices aumentan el uso del disco y ralentizan
INSERT,UPDATE, yDELETEoperaciones. Revise la necesidad de cada índice.
8. Incluya campos de auditoría 🕒
La trazabilidad es vital para la depuración y el cumplimiento. Cada tabla que maneja lógica de negocio debe registrar los cambios.
- Creado el: Agregar una
created_atcolumna para registrar cuándo se insertó por primera vez un registro. - Actualizado el: Agregar una
updated_atcolumna para registrar la hora de la última modificación. - Eliminaciones suaves: En lugar de eliminar permanentemente, considere agregar una
deleted_atcolumna. Esto permite restaurar los datos si es necesario y preserva la integridad referencial. - ¿Quién modificó: Para registros de auditoría críticos, incluya una
created_byyupdated_bycolumna para almacenar el ID de usuario responsable de la acción.
9. Aborde la seguridad y el cumplimiento 🔒
La seguridad de los datos debe integrarse en el esquema, no añadirse como una consideración posterior.
- Manejo de información personal identificable (PII): Identifique la información personal identificable (PII), como números de seguro social, números de tarjetas de crédito o registros médicos. Esta información debe cifrarse o tokenizarse.
- Clasificación de datos: Etiquete las columnas sensibles en la documentación del esquema para que los desarrolladores sepan qué campos requieren medidas de seguridad adicionales.
- Control de acceso: Aunque los permisos específicos suelen establecerse a nivel de aplicación o usuario de base de datos, el esquema debe reflejar la sensibilidad de los datos (por ejemplo, tablas separadas para datos públicos frente a privados).
- Políticas de retención: Asegúrese de que el esquema cumpla con los requisitos de retención de datos. Algunas jurisdicciones exigen la eliminación de datos después de un cierto período.
10. Documente y valide el esquema 📄
Un esquema sin documentación es una carga. La documentación garantiza la mantenibilidad futura.
- Diccionario de datos:Mantenga un documento que describa cada tabla, columna y relación. Incluya definiciones comerciales para cada campo.
- Comentarios:Utilice comentarios SQL dentro de los scripts de DDL (Lenguaje de Definición de Datos) para explicar lógica compleja o reglas comerciales específicas.
- Revisión visual:Genere el diagrama ER visualmente para verificar referencias cíclicas, tablas huérfanas o relaciones faltantes.
- Revisión entre pares:Haga que otro arquitecto o desarrollador senior revise el modelo. Una mirada fresca a menudo detecta errores lógicos que se pasaron por alto durante el diseño inicial.
Errores comunes en el modelado y soluciones 🛠️
Revisar la lista de verificación no es suficiente. También debe estar al tanto de los errores comunes.
| Error | Consecuencia | Solución |
|---|---|---|
| Claves foráneas faltantes | Registros huérfanos, inconsistencia de datos | Agregue restricciones de clave foránea explícitas |
| Tablas anchas | Difícil de leer, consultas lentas | Dividir en tablas relacionadas (Normalización) |
| Relaciones implícitas | Confusión durante el desarrollo | Dibuje líneas explícitas en el diagrama ER, agregue columnas de clave foránea |
| Problemas de nulabilidad | Errores lógicos en la aplicación | Establezca NO NULO donde se requiere datos |
| IDs codificados | Dificultades de migración | Utilice claves foráneas en lugar de identificadores codificados |
Reflexiones finales sobre el diseño de esquemas 🎯
Construir un modelo de base de datos es un equilibrio entre una integridad estricta y un rendimiento práctico. Seguir esta lista de verificación garantiza que tu estructura de datos satisfaga las necesidades del negocio sin comprometer la calidad. Tómate el tiempo para revisar cada paso antes de confirmar el esquema en el control de versiones. Unas pocas horas dedicadas a validar el diagrama ER pueden ahorrar semanas de depuración y reestructuración más adelante.
Recuerda que un modelo de base de datos es un documento vivo. A medida que cambian los requisitos del negocio, el esquema debe evolucionar. Las auditorías regulares contra esta lista de verificación mantendrán tu arquitectura de datos sana y alineada con tus objetivos. Prioriza la claridad, la consistencia e integridad en cada decisión que tomes.
Al adherirte a estos diez pasos, estableces una base sólida para tu aplicación. Tu equipo apreciará la claridad, y tu entorno de producción se beneficiará de errores reducidos y un mejor rendimiento. Haz de esta lista de verificación una parte estándar de tu flujo de trabajo de desarrollo.