











Toute application commence par une idée. Cette idée nécessite un stockage de données, et ce stockage exige un plan. Ce plan est le diagramme Entité-Relation (MCD). Il s’agit du document fondamental qui détermine la manière dont votre système comprend les informations. Toutefois, un plan pour une petite cabane ne convient pas à un gratte-ciel. De même, un schéma de base de données conçu pour un prototype échoue souvent sous le poids du trafic de production et de la logique métier complexe.
Comprendre l’évolution du MCD est essentiel pour les chefs techniques, les administrateurs de bases de données et les architectes logiciels. Cela implique de naviguer entre la flexibilité et l’intégrité. À mesure que votre base d’utilisateurs grandit, vos besoins en données évoluent. Vous ne pouvez pas conserver indéfiniment le modèle initial. Vous devez l’adapter. Ce guide explore le cycle de vie d’un modèle de données, de la première ligne de code jusqu’à l’architecture à l’échelle d’une entreprise.
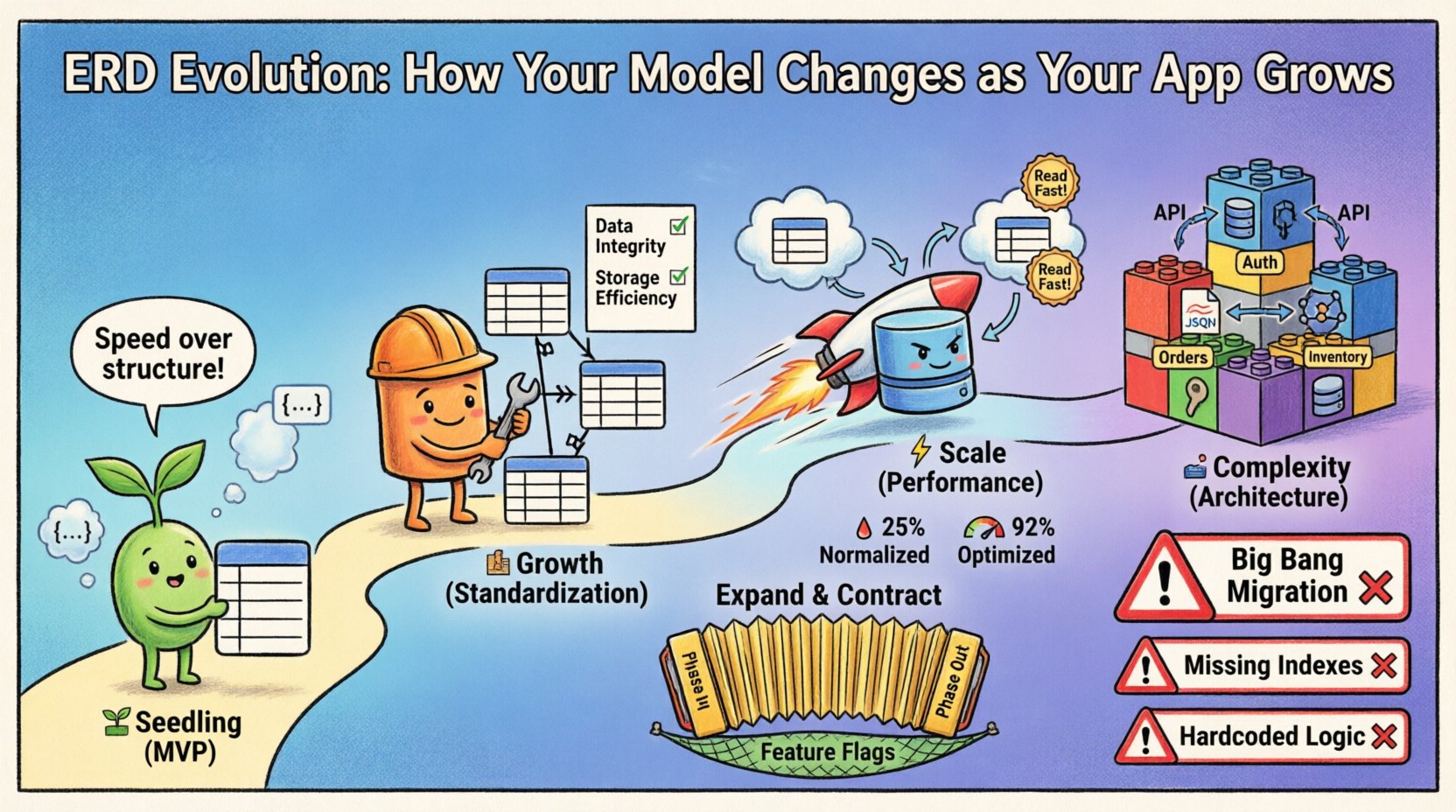
Phase 1 : La phase de la pousse (MVP) 🌱
Au début, la vitesse est le critère principal. L’objectif est de valider l’hypothèse centrale avec le moins de friction possible. À ce stade, le MCD est souvent fluide, reflétant les besoins immédiats plutôt que des prévisions à long terme.
- Focus :Fonctionnalité plutôt que structure.
- Structure :Les schémas plats sont fréquents. Les relations sont souvent dénormalisées pour réduire la complexité des jointures.
- Contraintes :Les clés étrangères peuvent être souples ou omises afin de permettre une itération rapide.
- Modifications :Les modifications de schéma ont lieu hebdomadairement, parfois quotidiennement.
Pendant cette phase, vous pouvez observer des entités fortement couplées. Par exemple, une Utilisateurtable peut contenir un blob JSON de paramètres de profil au lieu d’une table séparée Profiltable. Cela réduit le besoin de jointures, accélérant les opérations de lecture pour le tableau de bord. Toutefois, cela crée une dette technique. À mesure que l’application mûrit, interroger ces données imbriquées devient plus lent et plus difficile à maintenir.
Caractéristiques clés des modèles de phase initiale
- Contraintes minimales de clés étrangères.
- Types de colonnes flexibles (par exemple, utiliser VARCHAR pour tout).
- Instance unique de base de données.
- Mappage direct entre les objets applicatifs et les tables de base de données.
Phase 2 : La phase de croissance (normalisation) 🏗️
Dès que le produit gagne en popularité, la flexibilité initiale devient un fardeau. La duplication des données entraîne des incohérences. Si un utilisateur met à jour son adresse e-mail en un endroit mais pas ailleurs, le système perd sa crédibilité. C’est à cette phase que la normalisation prend le dessus.
Pourquoi normaliser maintenant ?
- Intégrité des données : En imposant l’intégrité référentielle, on évite les enregistrements orphelins.
- Efficacité du stockage : En supprimant les données redondantes, on économise de l’espace disque.
- Maintenabilité : La mise à jour d’un seul enregistrement dans une table normalisée le met à jour partout logiquement.
- Prévisibilité des requêtes : Les structures standardisées rendent l’écriture des requêtes moins sujette aux erreurs.
Pendant cette transition, vous devez refactoer le MCD. Une table utilisateur plate pourrait être divisée en Utilisateurs et DétailsUtilisateur. Cela introduit des relations. Vous devez définir si elles sont un-à-un, un-à-plusieurs ou plusieurs-à-plusieurs.
Liste de contrôle de la transition
- Identifiez tous les champs redondants entre les tables.
- Définissez des clés primaires pour toutes les entités.
- Implémentez des contraintes de clé étrangère pour imposer les relations.
- Revoyez les requêtes existantes afin d’évaluer les impacts sur les performances des nouveaux joints.
- Prévoyez la compatibilité descendante pendant la migration.
Phase 3 : Étape d’échelle (Performance) ⚡
Lorsqu’il existe des millions d’enregistrements, la structure normalisée peut devenir un goulot d’étranglement. Les jointures sont coûteuses en calcul à grande échelle. C’est là que le modèle évolue à nouveau, souvent en s’éloignant de la normalisation stricte vers une dénormalisation stratégique pour des raisons de performance.
Dénormalisation stratégique
Ce n’est pas un retour en arrière vers la phase MVP. C’est une décision réfléchie. Vous dupliquez intentionnellement des données pour éviter les jointures coûteuses sur de grandes tables.
- Charge de travail principalement en lecture : Si votre application est principalement en lecture, le cache des données dans le schéma réduit la charge de la base de données.
- Tables de reporting : Les données pré-agrégées pour les tableaux de bord évitent de calculer les sommes en temps réel.
- Partitionnement : Le partitionnement des tables par date ou région nécessite une conception spécifique du schéma pour permettre des requêtes efficaces.
Comparaison : Normalisé vs. Optimisé
| Fonctionnalité | Normalisé (Phase 2) | Optimisé (Phase 3) |
|---|---|---|
| Intégrité | Élevé (imposé par la base de données) | Géré par la logique de l’application |
| Vitesse d’écriture | Rapide | Plus lent (mise à jour de plusieurs tables) |
| Vitesse de lecture | Plus lent (nécessite des jointures) | Rapide (recherche unique) |
| Stockage | Efficace | Moins efficace (redondance) |
Phase 4 : Étape de complexité (architecture) 🏛️
Au niveau entreprise, un seul modèle de base de données est souvent insuffisant. Le système peut se scinder en microservices ou utiliser une persistance polyglotte. Le MCD ne représente plus un seul diagramme physique, mais un ensemble de modèles qui communiquent.
Microservices et propriété des données
Dans une architecture monolithique, la Commandestable est partagée par les services de facturation, d’expédition et de notification. Dans un système distribué, chaque service possède ses propres données. Cela exige un changement dans la manière dont vous modélisez les relations.
- Consistance éventuelle :Vous ne pouvez pas compter sur les transactions ACID entre les services. Le MCD doit tenir compte de la synchronisation d’état.
- Contrats API :Les relations sont souvent définies par les réponses d’API plutôt que par des clés étrangères.
- Synchronisation des données :Des outils sont nécessaires pour maintenir la cohérence des données entre différents magasins (par exemple, SQL pour les commandes, NoSQL pour les journaux).
Persistence polyglotte
Les données différentes nécessitent des moteurs de stockage différents. Le MCD évolue pour inclure des concepts non relationnels.
- Données graphes :Pour les réseaux sociaux ou les moteurs de recommandation, un modèle graphique remplace les tables relationnelles.
- Bases de documents :Pour des contenus flexibles comme les catalogues de produits, les documents JSON remplacent les colonnes rigides.
- Bases clé-valeur : Pour la gestion des sessions et le cache, des paires clé-valeur simples remplacent les lignes complexes.
Approfondissement technique : Niveaux de normalisation 🔬
Pour évoluer efficacement votre modèle, vous devez comprendre les règles que vous suivez ou que vous brisez. La normalisation est le processus d’organisation des données afin de réduire les redondances.
Première forme normale (1NF)
- Valeurs atomiques : Chaque colonne ne contient qu’une seule valeur.
- Pas de groupes répétés : Vous ne pouvez pas avoir des colonnes telles que
couleur1,couleur2,couleur3. - Identifiants uniques : Chaque ligne doit être identifiable de manière unique.
Deuxième forme normale (2NF)
- Doit être en 1NF.
- Toutes les attributs non clés doivent dépendre entièrement de la clé primaire.
- Élimine les dépendances partielles (par exemple, déplacer les informations du fournisseur vers une table séparée si elles dépendent uniquement de l’ID du fournisseur, et non de l’ID de commande).
Troisième forme normale (3NF)
- Doit être en 2NF.
- Les dépendances transitives sont supprimées.
- Une colonne ne peut pas dépendre d’une autre colonne non clé (par exemple,
Villedépend deÉtat, et non pas uniquementCode postal). DéplacerVilleetÉtatà unEmplacementtable.
Péchés courants dans l’évolution des modèles ERD ⚠️
Même les équipes expérimentées commettent des erreurs lors de la refonte des modèles. Reconnaître ces schémas aide à éviter des temps d’arrêt coûteux.
1. La migration « Big Bang »
Tenter de modifier l’ensemble du schéma en une seule déploiement. Cela comporte un risque élevé. Si le script de migration échoue, le système est endommagé.
- Solution : Utilisez des migrations incrémentales. Ajoutez des colonnes, remplissez les données, modifiez la logique, puis supprimez les anciennes colonnes.
2. Ignorer les implications de l’indexation
Modifier les relations modifie les schémas de requête. Une nouvelle relation clé étrangère pourrait nécessiter un nouvel index pour bien fonctionner.
- Solution : Analysez les journaux des requêtes lentes avant et après les modifications du schéma.
- Solution : Prévoyez la création des index pendant les heures creuses.
3. Durcir les contraintes dans la logique de l’application
Certaines équipes préfèrent valider les données dans le code plutôt que dans la base de données. Cela peut entraîner une corruption des données si plusieurs services écrivent dans le même magasin.
- Solution : Maintenez les contraintes au niveau de la couche base de données (NOT NULL, contraintes CHECK), même si l’application est distribuée.
Stratégies de migration 🔄
Lorsque vous devez évoluer le modèle ERD, vous avez besoin d’une stratégie qui minimise les temps d’arrêt et les pertes de données.
Schéma d’expansion et de contraction
C’est la norme d’or pour l’évolution sécurisée du schéma.
- Ajouter : Ajoutez la nouvelle colonne ou table au schéma. Ne modifiez pas encore la logique existante.
- Écrire : Mettez à jour l’application pour qu’elle écrive dans les structures ancienne et nouvelle.
- Lire : Mettez à jour l’application pour qu’elle lise à partir de la nouvelle structure.
- Compléter les données : Exécutez une tâche en arrière-plan pour remplir la nouvelle structure avec les anciennes données.
- Contrat : Une fois vérifié, supprimez les anciennes colonnes et la logique.
Drapeaux de fonctionnalité
Utilisez des drapeaux de fonctionnalité pour basculer entre l’ancien schéma et le nouveau schéma. Cela vous permet de revenir immédiatement en arrière en cas de problème, sans déployer de script d’annulation.
Documentation et versioning 📝
Un MCD n’est pas un livrable ponctuel. C’est un document vivant. À mesure que le modèle évolue, la documentation doit suivre.
Contrôle de version pour les schémas
- Traitez les fichiers de schéma (scripts SQL) comme du code. Stockez-les dans votre système de contrôle de version.
- Utilisez des outils de migration pour suivre les modifications au fil du temps.
- Marquez les versions avec les versions de schéma (par exemple,
v1.2.0-schema).
Consistance visuelle
- Standardisez les conventions de nommage (par exemple, snake_case vs camelCase).
- Assurez-vous que les noms de table reflètent le domaine (par exemple,
clientau lieu det1). - Gardez les commentaires dans le schéma pour le contexte de la logique métier.
Préparer votre modèle pour l’avenir 🚀
Vous ne pouvez pas prédire l’avenir, mais vous pouvez construire de la flexibilité. Bien que le surconception soit mauvaise, concevoir pour le changement est intelligent.
Modèles de conception extensibles
- EAV (Entité-Attribut-Valeur) : Utile pour les données très variables, bien qu’il sacrifie les performances des requêtes.
- Colonnes JSON : Les bases de données modernes prennent en charge les types JSON. Cela vous permet de stocker des attributs flexibles sans modifier la structure de la table.
- Systèmes d’étiquetage : Utilisez une relation plusieurs à plusieurs pour les métadonnées plutôt que de coder en dur des attributs spécifiques.
Surveillance et audit
- Suivez les modifications du schéma. Qui a modifié quoi et quand ?
- Surveillez les tendances de croissance des données. Si une table croît de 50 % par mois, prévoyez la partition avant qu’elle ne ralentisse.
- Configurez des alertes en cas de violation de contraintes.
Conclusion sur l’adaptabilité 🔄
L’évolution d’un MCD est un reflet de la maturité de l’application. Elle passe de la flexibilité à l’intégrité, puis à la performance. Chaque phase présente de nouveaux défis. L’essentiel est de prévoir ces changements et de les gérer de manière délibérée.
Il n’existe pas de modèle « parfait » unique. Il n’y a que le modèle qui correspond à vos contraintes actuelles et à votre trajectoire de croissance. En comprenant les compromis entre normalisation, dénormalisation et modèles architecturaux, vous pouvez garantir que votre couche de données soutiendra votre entreprise pendant de nombreuses années.
- Commencez simplement, mais prévoyez une structure.
- Normalisez pour l’intégrité, dénormalisez pour la vitesse.
- Documentez chaque modification.
- Testez rigoureusement les migrations.
Vos données sont votre actif le plus précieux. Traitez le modèle qui les contient avec le soin qu’il mérite.