









Concevoir une architecture de données solide exige bien plus que de dessiner des boîtes et des lignes. Il demande une compréhension approfondie de la manière dont les informations circulent au sein d’une organisation et de la manière dont ce flux est régulé par des règles. Un diagramme Entité-Relation (ERD) sert de plan structurel, tandis que la logique métier détermine le comportement du système. Lorsque ces deux éléments divergent, le résultat est souvent un système fragile qui peine à s’adapter aux besoins du monde réel. Ce guide explore l’intersection critique entre la modélisation des données et les règles métiers, en proposant des stratégies pour garantir que votre schéma soutient efficacement vos exigences.
Le défi réside dans la traduction de concepts abstraits — tels que « un utilisateur ne peut pas commander plus qu’il n’a en stock » — en structures de base de données concrètes. Si le modèle ne reflète pas les règles, l’intégrité des données en pâtit. Si les règles sont trop rigides, l’agilité métier s’effondre. Nous devons trouver un équilibre qui maintient la cohérence sans étouffer l’opération. Examinons ensemble les composants fondamentaux et la manière de les aligner.
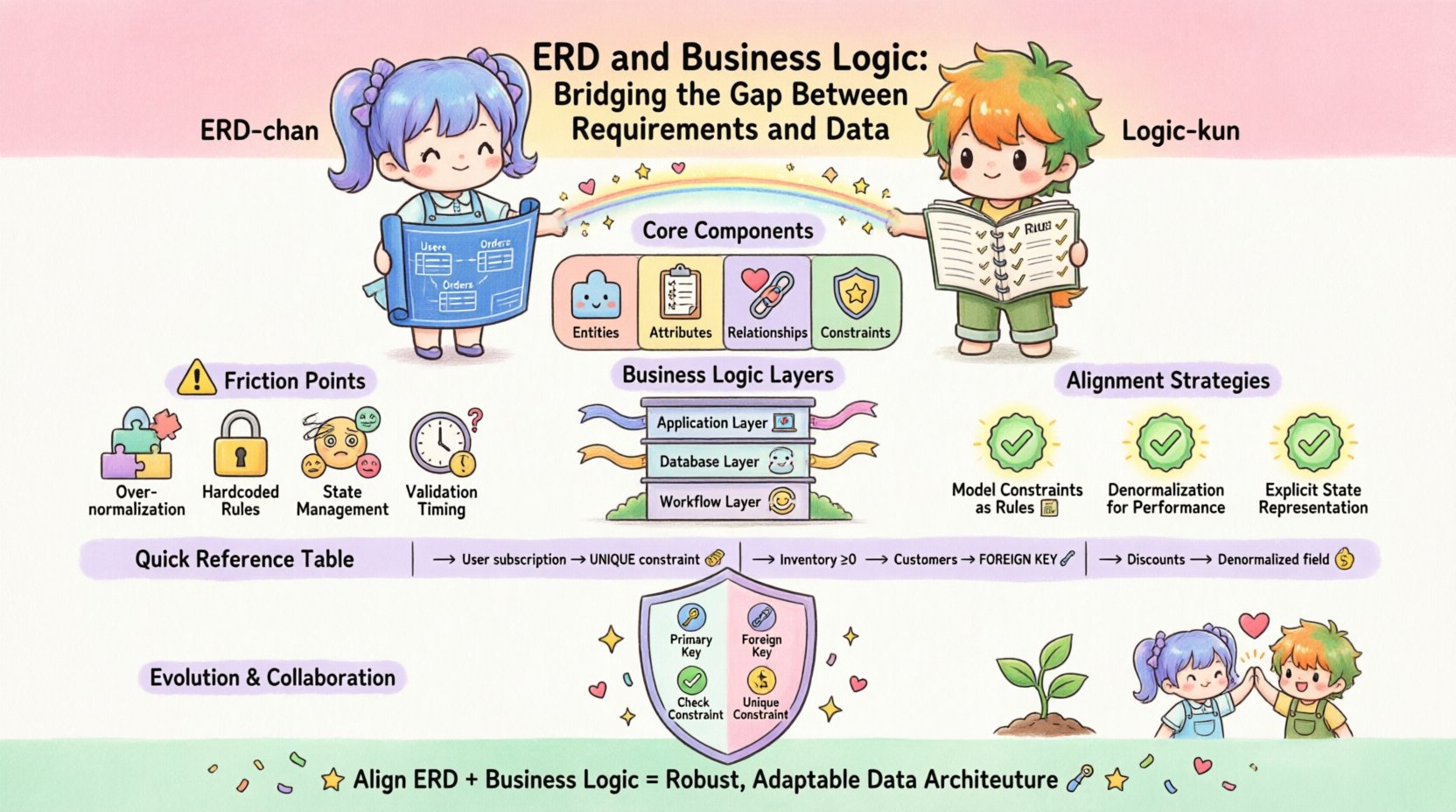
Comprendre les composants fondamentaux 🏗️
Pour combler le fossé, nous devons d’abord définir ce avec quoi nous travaillons. Les deux côtés de l’équation ont des caractéristiques distinctes qui influencent leur interaction.
Le diagramme Entité-Relation (ERD)
Un ERD représente la structure statique des données. Il définit les entités (tables), les attributs (colonnes) et les relations (clés étrangères). Son objectif principal est la normalisation et l’intégrité. Il répond à la question : « Quelles données devons-nous stocker ? » Les aspects clés incluent :
- Entités : Les objets fondamentaux du système, tels que Client, Commande, ou Produit.
- Attributs : Les propriétés décrivant les entités, telles que email, prix, ou statut.
- Relations : La manière dont les entités sont connectées, généralement définie par les clés primaires et étrangères. Elles établissent la cardinalité (un-à-un, un-à-plusieurs).
- Contraintes : Des règles appliquées au niveau de la base de données, telles que
NOT NULL,UNIQUE, ouVÉRIFIER.
Bien que puissant, un MCD est souvent passif. Il stocke les données, mais ne les traite pas intrinsèquement. Il est le récipient, pas le conducteur.
Logique métier
La logique métier représente les règles actives qui régissent la création, la modification et l’utilisation des données. Elle répond à la question : « Qu’est-ce que nous sommes autorisés à faire avec ces données ? » Cette logique peut exister à plusieurs niveaux :
- Couche application :Code côté serveur ou côté client qui valide les entrées avant qu’elles n’atteignent la base de données.
- Couche base de données :Procédures stockées, déclencheurs et contraintes qui appliquent les règles directement dans le moteur de stockage.
- Couche flux de travail :La séquence d’événements nécessaire pour accomplir une tâche, comme les chaînes d’approbation ou les transitions d’état.
Lorsque la logique métier est trop éloignée de la structure des données, des incohérences apparaissent. Par exemple, si l’application autorise l’entrée d’une quantité négative, mais que la contrainte de la base de données l’empêche, l’expérience utilisateur est compromise. À l’inverse, si la base de données autorise les quantités négatives, mais que l’application les bloque, la logique est dupliquée et sujette à des erreurs.
Les points de friction : pourquoi l’écart existe 📉
Les développeurs et les architectes de bases de données parlent souvent des langages différents. L’équipe technique se concentre sur les performances et l’intégrité, tandis que le côté métier se concentre sur la fonctionnalité et l’expérience utilisateur. Ce décalage entraîne plusieurs points de friction courants.
- Sur-normalisation :Une application stricte des règles de normalisation peut rendre les requêtes métier complexes difficiles. Un schéma fortement normalisé nécessite de nombreuses jointures pour récupérer les données liées à une règle métier spécifique, ralentissant ainsi la logique de l’application.
- Règles codées en dur :Intégrer directement les règles métier dans le code de l’application les rend invisibles au niveau de la couche données. Si le schéma de la base de données change, l’application pourrait échouer silencieusement ou retourner des données incohérentes.
- Gestion d’état :Les MCD ont souvent du mal à gérer des machines à états complexes (par exemple, les statuts de commande comme « En attente », « Expédié », « Remboursé »). Représenter ces états par des colonnes simples peut entraîner des états orphelins si la logique n’est pas appliquée.
- Moment de validation :Déterminer si la validation a lieu avant ou après le stockage est crucial. Une validation précoce réduit la charge, mais une validation tardive garantit que les données les plus à jour sont utilisées.
Lorsque ces points sont ignorés, le système devient un patchwork de solutions de contournement. Les développeurs ajoutent des corrections temporaires pour contourner les contraintes, ce qui entraîne une dette technique. Les données deviennent peu fiables, et la logique métier devient fragile.
Stratégies d’alignement 🤝
Comblé cet écart exige une conception intentionnelle. Nous devons considérer le schéma comme un document vivant qui évolue avec les exigences métiers. Voici des stratégies éprouvées pour aligner la modélisation des données avec la logique.
1. Modéliser les contraintes comme des règles métiers
Chaque règle métier qui empêche les données invalides doit avoir une contrainte de base de données correspondante. Ne comptez pas uniquement sur le code de l’application. Cela garantit que, peu importe la source des données — API, script ou importation directe — les règles sont respectées.
- Unicité :Si un nom d’utilisateur doit être unique, appliquez cette contrainte au niveau de la colonne. Ne vérifiez pas d’abord dans l’application, car des conditions de course peuvent survenir.
- Vérifications de plage : Si une remise ne peut pas dépasser 100 %, utilisez une
VÉRIFICATIONcontrainte. Cela empêche la corruption accidentelle des données provenant de mises à jour en masse. - Intégrité référentielle : Utilisez des clés étrangères pour garantir qu’une commande appartient toujours à un client valide. Si un client est supprimé, décidez si la commande doit rester (suppression douce) ou être supprimée (suppression en cascade) en fonction des besoins métiers.
2. Dénormalisation pour des performances logiques
Bien que la normalisation soit bonne pour le stockage, elle n’est pas toujours idéale pour la logique. Les règles métier complexes nécessitent souvent l’agrégation de données provenant de plusieurs sources. Si la logique est très lue, envisagez de dénormaliser des attributs spécifiques.
- Totaux mis en cache : Au lieu d’additionner les lignes de commande chaque fois qu’un total est nécessaire, stockez le montant_total dans la table Commande. Mettez à jour ce champ chaque fois qu’une ligne de commande change.
- Drapeaux d’état : Si l’état d’un utilisateur détermine l’accès, stockez-le dans une colonne plutôt que de le joindre via une table d’historique. Cela accélère la logique de vérification des autorisations.
Cette approche échange de l’espace de stockage contre une vitesse de requête et une simplicité logique. Elle doit être gérée avec soin pour éviter des incohérences de données.
3. Représentation explicite de l’état
Pour les flux de travail, la base de données doit refléter l’état de manière explicite. Utilisez une colonne d’état dédiée avec un ensemble contraint de valeurs. Évitez d’utiliser des champs texte libre pour l’état.
- Valeurs énumérées : Définissez clairement les états autorisés. Cela facilite le reporting et la logique.
- Tables de transition : Pour les flux de travail complexes, utilisez une table de jonction pour suivre l’historique. Cela vous permet de reconstruire le chemin logique suivi pour atteindre un état actuel.
Mappage de la logique vers le schéma : un tableau pratique 📊
Pour visualiser comment les règles abstraites se traduisent en structures concrètes, reportez-vous au mappage ci-dessous. Ce tableau illustre des exigences métiers courantes et leurs modèles de conception de données correspondants.
| Exigence métier | Implication logique | Implémentation du schéma |
|---|---|---|
| Un utilisateur ne peut avoir qu’une seule abonnement actif | Contrainte d’unicité sur l’état actif | UNIQUE (id_utilisateur, statut) où statut = « actif » |
| L’inventaire ne peut pas descendre en dessous de zéro | Validation à l’écriture | VÉRIFIER (quantité >= 0) ou logique de déclenchement |
| Les commandes doivent appartenir à des clients existants | Intégrité référentielle | CLÉ ÉTRANGÈRE (customer_id) RÉFÉRENCE Clients(id) |
| Les remises sont calculées par article | Stockage dénormalisé | Stockez prix_reduit sur OrderItem, mise à jour à chaque modification |
| Les journaux doivent être conservés pendant 5 ans | Gestion du cycle de vie | created_at colonne + tâche en arrière-plan pour l’archivage |
| Les rôles déterminent l’accès aux fonctionnalités | Mappage d’association | Table de jonction RolePermissions liant les utilisateurs aux fonctionnalités |
Ce mappage garantit que chaque règle a sa place dans le modèle de données. Il évite la situation où la logique existe uniquement dans le code, laissant les données vulnérables.
Validation et contraintes : le filet de sécurité 🛡️
Les contraintes sont la première ligne de défense pour l’intégrité des données. Elles sont appliquées par le moteur de base de données, ce qui les rend plus rapides et plus fiables que les vérifications au niveau de l’application. Cependant, elles ne doivent pas être la seulecouche.
Types de contraintes
- Clés primaires : Assurent que chaque enregistrement est identifiable de manière unique. C’est fondamental pour toutes les relations.
- Clés étrangères : Maintenir des relations entre les tables. Elles empêchent les enregistrements orphelins.
- Contraintes de vérification : Définir des conditions spécifiques pour les valeurs de colonne. Utile pour les plages, les formats ou la logique comme
prix > 0. - Contraintes uniques : Empêcher les données en double. Essentiel pour les e-mails, les noms d’utilisateur ou les codes produits.
Déclencheurs et procédures stockées
Parfois, une contrainte n’est pas suffisante. Une logique complexe, comme la mise à jour d’un solde sur plusieurs tables lorsqu’une transaction a lieu, nécessite des déclencheurs. Bien qu’ils soient puissants, les déclencheurs doivent être utilisés avec parcimonie. Ils peuvent cacher la logique aux développeurs et rendre le débogage difficile.
- Cas d’utilisation : Archivage automatique des anciens enregistrements.
- Cas d’utilisation : Calcul des champs dérivés avant l’insertion.
- Attention : Évitez la logique métier qui convient mieux au niveau de l’application. Les déclencheurs doivent se concentrer sur l’intégrité des données, et non sur les flux utilisateur.
Évolution et refactoring 🔄
Les règles métier évoluent. Une entreprise peut commencer à vendre des abonnements, puis passer aux achats ponctuels. Le modèle de données doit pouvoir évoluer sans rompre la logique existante.
Versionnement du schéma
Les modifications du MCD doivent être versionnées. Utilisez des scripts de migration pour gérer les transitions. Cela vous permet de revenir en arrière si une modification brise inattendument la logique métier.
- Compatibilité descendante : Lors de l’ajout d’une colonne, rendez-la d’abord nullable. Cela permet à la logique ancienne de fonctionner pendant le déploiement de la nouvelle logique.
- Dépréciation : Ne supprimez pas les colonnes immédiatement. Marquez-les comme obsolètes et conservez-les pendant une période pour soutenir les anciennes intégrations.
- Documentation : Maintenez la documentation du schéma synchronisée avec le code. Un commentaire dans le MCD doit expliquer la règle métier derrière une colonne.
Refactoring pour la logique
À mesure que les exigences augmentent, le MCD initial peut devenir un goulot d’étranglement. Vous devrez peut-être diviser des tables ou les fusionner. C’est une tâche importante qui nécessite une planification soigneuse.
- Identifier la logique : Déterminez quelles règles métier causent des problèmes de performance ou d’intégrité.
- Planifier le déplacement :Créez un script pour déplacer les données vers la nouvelle structure tout en maintenant la cohérence.
- Testez rigoureusement :Exécutez la nouvelle logique sur les données historiques pour vous assurer qu’elle se comporte comme prévu.
Collaboration et documentation 📝
L’alignement technique n’est que la moitié de la bataille. L’autre moitié est la communication. Le schéma de la base de données est un contrat entre la couche données et la couche application. Tous les participants doivent le comprendre.
Vocabulaire partagé
Assurez-vous que les termes utilisés dans la base de données correspondent à la terminologie métier. Si l’entreprise l’appelle un « client », ne nommez pas la table « client ». Si l’entreprise appelle un champ « statut », ne l’appeliez pas « indicateur ». La cohérence réduit la charge cognitive.
Documentation visuelle
Les diagrammes entité-association sont visuels, mais peuvent être complexes. Complétez-les par des diagrammes qui montrent le flux de données aux côtés de la structure. Mettez en évidence les points où la logique métier interagit avec les données.
- Dictionnaire des données :Maintenez un document qui explique le but de chaque table et de chaque colonne.
- Schémas de flux logique :Représentez le parcours des données depuis l’entrée jusqu’au stockage, en indiquant où la validation a lieu.
- Listes de contraintes :Maintenez une liste de toutes les règles appliquées par la base de données pour une référence facile pendant le développement.
Pensées finales sur l’intégrité des données 🎯
La relation entre un diagramme entité-association et la logique métier est symbiotique. Le diagramme entité-association fournit la fondation, et la logique métier donne le sens. Lorsqu’ils sont mal alignés, le système échoue à produire de la valeur. Lorsqu’ils sont alignés, le système devient un moteur fiable pour l’entreprise.
Le succès vient du fait de traiter la base de données comme un partenaire dans l’application de la logique, et non pas seulement comme un conteneur de stockage. En mettant en œuvre des contraintes, en gérant explicitement l’état et en maintenant une documentation claire, vous créez un système à la fois robuste et adaptable. L’objectif n’est pas de prédire chaque exigence future, mais de construire une structure capable d’accompagner les changements sans s’effondrer.
Commencez par les règles. Définissez ce qui constitue des données valides avant de définir comment elles sont stockées. Laissez la logique métier guider le schéma, et laissez le schéma protéger la logique. Cet alignement est la pierre angulaire d’une architecture de données durable. 🚀