











डेटाबेस डिजाइन करना कोड टाइप करने के बारे में कम है और रिश्तों को समझने के बारे में अधिक है। कोई भी स्क्रिप्ट की एक पंक्ति लिखे जाने से पहले, एक दृश्य आधार रखना आवश्यक है। यह आधार एंटिटी-रिलेशनशिप डायग्राम है, जिसे सामान्यतः ERD के रूप में जाना जाता है। इस चरण को छोड़ना एक ब्लूप्रिंट के बिना एक ऊंची इमारत बनाने जैसा है। संरचना कुछ समय तक खड़ी रह सकती है, लेकिन जैसे-जैसे डेटा बढ़ता है, दरारें दिखाई देंगी। 🧱
यह मार्गदर्शिका डेटाबेस आर्किटेक्चर के प्रारंभिक चरण के माध्यम से चलती है। इसका ध्यान एक मजबूत स्कीमा बनाने के लिए आवश्यक अवधारणात्मक और तार्किक मॉडल पर केंद्रित है। चाहे आप कस्टमर रिकॉर्ड, इन्वेंट्री या जटिल लेन-देन डेटा का प्रबंधन कर रहे हों, सिद्धांत एक जैसे रहते हैं। हम एंटिटीज, विशेषताओं, संबंधों और कार्डिनैलिटी का अध्ययन करेंगे, जिसमें किसी विशिष्ट उपकरण या स्वामित्व वाले सॉफ्टवेयर पर निर्भर नहीं करेंगे। लक्ष्य एक पैमाने पर बढ़ने वाले, कुशल और आसानी से बनाए रखे जाने वाले सिस्टम का निर्माण करना है। 🚀
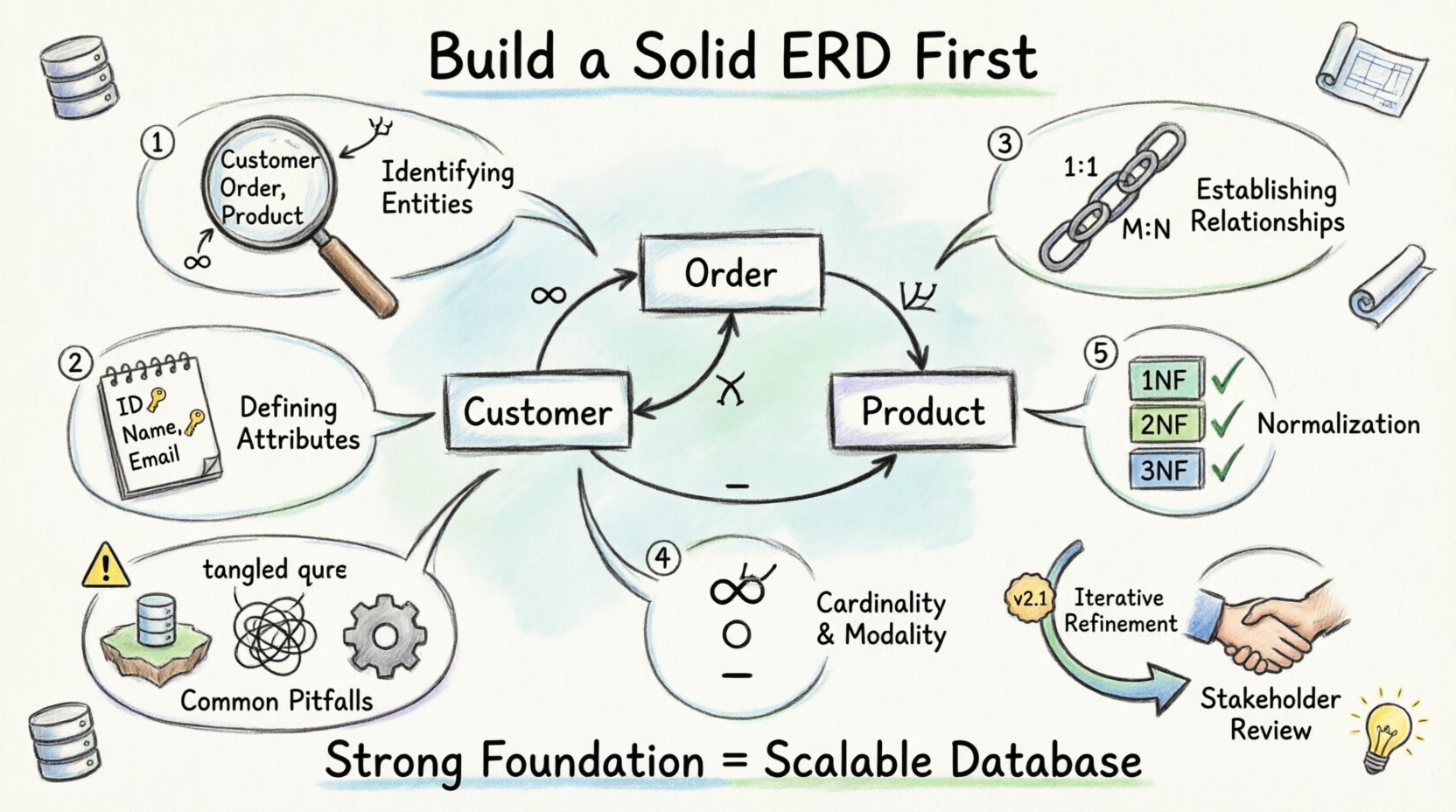
एंटिटी-रिलेशनशिप डायग्राम को समझना 📐
एक ERD एक प्रणाली के भीतर डेटा संरचनाओं का दृश्य प्रतिनिधित्व है। यह उन ‘चीजों’ (एंटिटीज) को नक्शा बनाता है जिन्हें संग्रहीत करने की आवश्यकता होती है और वे एक-दूसरे के साथ कैसे बातचीत करते हैं। इसे डेटाबेस इंजन के लिए एक नक्शे के रूप में सोचें। यह यह नहीं बताता कि डेटा डिस्क पर भौतिक रूप से कैसे संग्रहीत किया जाता है, बल्कि यह बताता है कि डेटा एप्लिकेशन के लिए तार्किक रूप से कैसे व्यवस्थित किया जाता है।
यहां से शुरुआत क्यों करें? 🤔
एक ठोस नक्शे के साथ शुरुआत करने से कई आम समस्याओं को रोका जा सकता है:
- डेटा अतिरिक्तता:एक ही जानकारी को कई स्थानों पर संग्रहीत करने से असंगतियां आती हैं।
- पूर्णता त्रुटियां:संबंध स्पष्ट रूप से परिभाषित किए जाते हैं, जिससे अनाथ रिकॉर्ड की स्थिति रोकी जाती है।
- स्केलेबिलिटी:एक तार्किक मॉडल को व्यवसाय बढ़ने के साथ बिना पूरी तरह से पुनर्निर्माण के अनुकूलित किया जा सकता है।
- संचार:हितधारक विकास शुरू होने से पहले संरचना की समीक्षा कर सकते हैं, जिससे आवश्यकताओं को पूरा करने की गारंटी मिलती है।
ERD के बिना, डेवलपर्स अक्सर संबंधों के बारे में अनुमान लगाते हैं। इससे बाद में जटिल जॉइन्स और प्रदर्शन की समस्याएं आती हैं। एक अच्छी तरह से परिभाषित नक्शा पूरी परियोजना टीम के लिए एकमात्र सच्चाई का स्रोत बनता है। 🤝
चरण 1: एंटिटीज की पहचान करना 🏢
किसी भी डेटाबेस के निर्माण के लिए एंटिटीज बुनियादी इकाइयां हैं। एक एंटिटी एक अलग वस्तु, अवधारणा या व्यक्ति का प्रतिनिधित्व करती है जिसके बारे में डेटा एकत्र किया जाता है। नक्शे के संदर्भ में, ये वे संज्ञाएं हैं जो आप अपनी आवश्यकताओं में पहचानते हैं।
वास्तविक दुनिया बनाम तार्किक एंटिटीज
एक व्यावसायिक प्रक्रिया के विश्लेषण करते समय, आपको भौतिक वस्तुओं और तार्किक अवधारणाओं के बीच अंतर करना होगा। उदाहरण के लिए, एक ‘उत्पाद’ एक तार्किक एंटिटी है। गोदाम में एक विशिष्ट ‘विजेट’ एक भौतिक उदाहरण है। डेटाबेस तार्किक एंटिटी को संग्रहीत करता है, जिसे अद्वितीय पहचानकर्ता के माध्यम से उदाहरणों का अनुसरण किया जाता है।
उम्मीदवार एंटिटीज की पहचान करना
एंटिटीज को खोजने के लिए, व्यावसायिक नियमों और कार्यात्मक आवश्यकताओं की समीक्षा करें। निम्नलिखित चीजों की तलाश करें:
- संज्ञाएं:आपके आवश्यकता दस्तावेज में बड़े अक्षरों वाली संज्ञाओं को देखें।
- मुख्य कार्य:कौन से कार्य किए जाते हैं? कौन शामिल है?
- नियामक आवश्यकताएं:पालन करने के लिए कौन सा डेटा रखा जाना चाहिए?
आम उदाहरणों में शामिल हैं:
- ग्राहक: कौन खरीद रहा है या बातचीत कर रहा है?
- आदेश: लेनदेन का रिकॉर्ड।
- उत्पाद: बेचे जा रहे वस्तु का।
- कर्मचारी: कौन प्रणाली को प्रबंधित करता है?
- स्थान: माल को कहाँ भेजा जाता है?
एंटिटी नामकरण प्रथाएं
स्पष्टता के लिए निरंतरता महत्वपूर्ण है। आरेख में एकल, बहुवचन या संगत नामकरण मानकों का उपयोग करें। संक्षिप्त रूपों से बचें, जब तक वे उद्योग मानक नहीं हैं। उदाहरण के लिए, “ग्राहक” के बजाय “ग्राहक” का उपयोग करें।
| पहलू | सिफारिश | उदाहरण |
|---|---|---|
| मामला | पैस्कलकेस या स्नेककेस | ग्राहकरिकॉर्ड या ग्राहकरिकॉर्ड |
| बहुवचनता | तालिकाओं के लिए एकवचन का उपयोग करें | उपयोग करें ग्राहक, नहीं ग्राहक |
| स्पष्टता | सामान्य नामों से बचें | उपयोग करें बिल, नहीं दस्तावेज |
चरण 2: गुणों को परिभाषित करना 📝
जब एकताओं की पहचान कर ली जाती है, तो आपको उनके बारे में कौन सी जानकारी संग्रहीत की जाती है, इसका निर्धारण करना होता है। इन विवरणों को गुणांक कहा जाता है। गुणांक एकता की विशेषताओं का वर्णन करते हैं।
गुणांकों के प्रकार
गुणांक उनके कार्य और व्यवहार के आधार पर कई श्रेणियों में आते हैं:
- वर्णनात्मक गुणांक:नाम, पता या फोन नंबर जैसी मूल तथ्य।
- मुख्य गुणांक:एकल पहचानकर्ता। प्रत्येक एकता को कम से कम एक मुख्य गुणांक की आवश्यकता होती है ताकि उसे अन्य से अलग किया जा सके।
- मिश्रित गुणांक:वह डेटा जो छोटे हिस्सों में विभाजित किया जा सकता है (उदाहरण के लिए, एक पता सड़क, शहर, जिप में विभाजित किया जा सकता है)।
- व्युत्पन्न गुणांक:अन्य डेटा से गणना की गई मान (उदाहरण के लिए, जन्मतिथि से उम्र निकालना)।
- बहुमूल्य गुणांक:वे क्षेत्र जो कई मान रख सकते हैं (उदाहरण के लिए, एक व्यक्ति के लिए फोन नंबर)।
प्राथमिक कुंजी: आधार 🔑
प्राथमिक कुंजी (PK) सबसे महत्वपूर्ण गुणांक है। यह तालिका में प्रत्येक रिकॉर्ड के लिए अद्वितीय होना चाहिए। यह सुनिश्चित करता है कि कोई भी दो पंक्तियाँ समान नहीं होंगी। प्राथमिक कुंजियाँ अक्सर प्रणाली द्वारा स्वतः उत्पन्न की जाती हैं, जैसे कि स्वतः बढ़ता हुआ पूर्णांक या UUID।
कुंजी चुनने के लिए विचार:
- स्थिरता: मान समय के साथ नहीं बदलना चाहिए। नाम का उपयोग करना जोखिम भरा है; आईडी का उपयोग करना सुरक्षित है।
- अद्वितीयता: दोहराव की अनुमति नहीं है।
- शून्य नहीं होने की आवश्यकता: एक कुंजी के बिना कोई रिकॉर्ड अस्तित्व में नहीं हो सकता।
चरण 3: संबंध स्थापित करना 🔗
एकताएं अक्सर अकेले नहीं रहती हैं। एक ग्राहक एक आदेश देता है। एक कर्मचारी एक परियोजना पर काम करता है। इन कनेक्शन को संबंध कहा जाता है। संबंधों को परिभाषित करना ही एरडी की वास्तविक शक्ति है।
संबंधों के प्रकार
एकताओं के बीच कैसे बातचीत होती है, इसे वर्णित करने के लिए तीन मानक कार्डिनैलिटी का उपयोग किया जाता है:
- एक से एक (1:1):एकता A का एक उदाहरण एकता B के ठीक एक उदाहरण से संबंधित होता है।
- एक से बहुत (1:N):एकता A का एक उदाहरण एकता B के कई उदाहरणों से संबंधित होता है।
- बहु-से-बहु (M:N): एंटिटी A के कई उदाहरण एंटिटी B के कई उदाहरण से संबंधित होते हैं।
बहु-से-बहु संबंधों का प्रबंधन
एक संबंधात्मक मॉडल में, एक सीधे बहु-से-बहु संबंध का भौतिक रूप से समर्थन नहीं किया जाता है। इसे एक सह-संबंधित एंटिटी (जिसे ब्रिज टेबल या जंक्शन टेबल भी कहा जाता है) के उपयोग से हल किया जाना चाहिए। इस नई एंटिटी के कारण M:N संबंध दो एक-से-बहु संबंधों में तोड़ दिया जाता है।
उदाहरण के लिए, एक छात्र बहुत से कोर्स ले सकता है, और एक कोर्स में बहुत से छात्र हो सकते हैं। उन्हें सीधे जोड़ने के बजाय, एक बनाएंपंजीकरण एंटिटी। इस टेबल में छात्र का आईडी और कोर्स का आईडी होता है, साथ ही उस पंजीकरण के लिए कोई विशिष्ट डेटा (जैसे ग्रेड) भी होता है।
चरण 4: कार्डिनैलिटी और मोडैलिटी 🔢
कार्डिनैलिटी संबंधों की संख्या को परिभाषित करती है। मोडैलिटी वैकल्पिकता (कि कोई संबंध अनिवार्य है या वैकल्पिक) को परिभाषित करती है। इन विवरणों से डेटा अखंडता सुनिश्चित होती है।
कार्डिनैलिटी नोटेशन
दृश्य नोटेशन विकासकर्मियों को प्रतिबंधों को समझने में मदद करता है। सामान्य प्रतीकों में शामिल हैं:
- एक: एक एकल रेखा या डैश (-)।
- बहुत सारे: कॉर का पैर संकेत (∞) या तीन तीखे सिरे।
- वैकल्पिक: एक वृत्त (○) जो शून्य की अनुमति दिखाता है।
- अनिवार्य: एक ठोस रेखा जो कम से कम एक की आवश्यकता दिखाती है।
भागीदारी प्रतिबंध
भागीदारी को समझना एप्लिकेशन लॉजिक के लिए बहुत महत्वपूर्ण है। निम्नलिखित परिदृश्यों पर विचार करें:
- पूर्ण भागीदारी: प्रत्येक ग्राहक को अनिवार्य है एक ऑर्डर होना चाहिए। (अनिवार्य)
- आंशिक भागीदारी: एक ऑर्डर को अनिवार्य नहीं है एक शिपिंग पता हो सकता है। (वैकल्पिक)
गलत मोडैलिटी डेटाबेस त्रुटियों का कारण बनती है। यदि कोई प्रणाली एक अनिवार्य संबंध की आवश्यकता करती है लेकिन डेटाबेस में नल मानों की अनुमति है, तो जब डेटा गायब होता है तो एप्लिकेशन लॉजिक टूट जाएगी।
चरण 5: सामान्यीकरण संदर्भ 🔄
जबकि एरडी एक तार्किक मॉडल है, इसे सामान्यीकरण सिद्धांतों के अनुरूप होना चाहिए। सामान्यीकरण अतिरेक को कम करता है और डेटा अखंडता में सुधार करता है। इसमें निर्भरताओं को कम करने के लिए विशेषताओं को तालिकाओं में व्यवस्थित करना शामिल है।
पहला सामान्य रूप (1NF)
परमाणु मान सुनिश्चित करें। एक फ़ील्ड में आइटम की सूची नहीं होनी चाहिए। उदाहरण के लिए, “हॉबीज” फ़ील्ड में “पढ़ाई, हिकिंग, कोडिंग” के बजाय, एक अलग “हॉबीज” तालिका बनाएं।
दूसरा सामान्य रूप (2NF)
आंशिक निर्भरताओं को हटाएं। सभी गैर-की विशेषताओं को पूर्ण मुख्य कुंजी पर निर्भर होना चाहिए, केवल इसके कुछ हिस्से पर नहीं। यह आमतौर पर तब लागू होता है जब एक तालिका में संयुक्त कुंजी होती है।
तीसरा सामान्य रूप (3NF)
स्थानांतरित निर्भरताओं को हटाएं। गैर-की विशेषताओं को अन्य गैर-की विशेषताओं पर निर्भर नहीं होना चाहिए। उदाहरण के लिए, एक “कर्मचारी” तालिका में, यदि आप “शहर” को “कार्यालयआईडी” के आधार पर संग्रहीत करते हैं, तो आपको “कार्यालयआईडी” और “शहर” को एक “कार्यालय” तालिका में अलग करना चाहिए।
एरडी इन निर्भरताओं को दृश्यमान बनाने में मदद करता है। यदि आप विशेषताओं के एक ऐसे समूह में देखते हैं जो पुनरावृत्ति के संकेत देते हैं, तो एरडी को एसक्यूएल लिखने से पहले समायोजित करने की आवश्यकता होती है। ⚙️
बचने के लिए सामान्य गलतियाँ ⚠️
यहां तक कि अनुभवी डिजाइनर भी प्रारंभिक चरण में गलतियां करते हैं। इन गलतियों को जल्दी से पहचानने से विकास के दौरान महत्वपूर्ण समय बचता है।
| गलती | परिणाम | समाधान |
|---|---|---|
| अनुपस्थित संबंध | डेटा अलग-अलग द्वीपों में बदल जाता है | सभी संबंधों के लिए आवश्यकताओं की समीक्षा करें |
| अत्यधिक सामान्यीकरण | क्वेरीज बहुत जटिल हो जाती हैं | अखंडता और पढ़ने के प्रदर्शन के बीच संतुलन बनाएं |
| डेटा प्रकारों के बारे में ध्यान न देना | स्टोरेज अक्षमता और त्रुटियां | प्रकारों (तारीख, संख्या, पाठ) को जल्दी से परिभाषित करें |
| कड़े मान | प्रणाली कठोर हो जाती है | स्थिर डेटा के लिए लुकअप तालिकाओं का उपयोग करें |
| दुर्बल कुंजियां | रिकॉर्ड को ट्रैक करने में कठिनाई | सुनिश्चित करें कि कुंजियां अद्वितीय और स्थिर हैं |
दस्तावेज़ीकरण और समीक्षा 📄
ERD एक बार के लिए बनाया गया ड्राइंग नहीं है। यह परियोजना के साथ विकसित होने वाला एक जीवंत दस्तावेज है। जब प्रारंभिक डिज़ाइन पूरा हो जाता है, तो इसकी समीक्षा करना आवश्यक है।
हितधारक प्रमाणीकरण
आरेख को व्यावसायिक विश्लेषकों और विषय विशेषज्ञों के सामने प्रस्तुत करें। वे उन लापता व्यावसायिक नियमों को देख सकते हैं जिन्हें डेवलपर्स नज़रअंदाज़ कर सकते हैं। उदाहरण के लिए, एक नियम जैसे “30 दिनों के बाद एक रिफंड प्रक्रिया नहीं की जा सकती” तकनीकी आरेख में दिखाई नहीं दे सकता है, लेकिन तर्क के लिए बहुत महत्वपूर्ण है।
तकनीकी लागूता
डेटाबेस प्रशासकों के साथ डिज़ाइन की समीक्षा करें। वे यह आकलन कर सकते हैं कि प्रस्तावित स्कीमा अपेक्षित डेटा आयतन के साथ अच्छा प्रदर्शन करेगा या नहीं। वे संबंधों के आधार पर इंडेक्सिंग रणनीतियों या पार्टीशनिंग योजनाओं की सिफारिश कर सकते हैं।
पुनरावृत्ति प्रक्रिया 🔄
डेटाबेस डिज़ाइन दुर्लभ रूप से रेखीय होता है। नए आवश्यकताएं उभरती हैं। व्यावसायिक प्रक्रियाएं बदलती हैं। ERD को इन परिवर्तनों को दर्शाने के लिए अद्यतन किया जाना चाहिए।
स्कीमा के लिए संस्करण नियंत्रण
कोड की तरह ही, डेटाबेस स्कीमा को संस्करण नियंत्रण में रखा जाना चाहिए। इससे टीमों को समय के साथ परिवर्तनों को ट्रैक करने में मदद मिलती है। यदि कोई परिवर्तन प्रणाली को बिगड़ देता है, तो आप ERD के पिछले संस्करण और संबंधित स्क्रिप्ट पर वापस लौट सकते हैं।
परिवर्तन प्रबंधन
ERD के संशोधन करते समय मौजूदा डेटा पर प्रभाव को ध्यान में रखें। मौजूदा तालिका में एक आवश्यक फ़ील्ड जोड़ने से रिपोर्ट्स बिगड़ सकती हैं। एक नया संबंध जोड़ने के लिए डेटा स्थानांतरण की आवश्यकता हो सकती है। हमेशा डिज़ाइन अपडेट के साथ-साथ स्थानांतरण रणनीति की योजना बनाएं।
उपकरण बनाम पेन और कागज़ 🖊️
हालांकि ERD बनाने के लिए कई सॉफ्टवेयर समाधान मौजूद हैं, प्रारंभिक विचार प्रक्रिया बिना किसी सीमा के सबसे अच्छी होती है। व्हाइटबोर्ड या पेन और कागज़ का उपयोग करने से त्वरित पुनरावृत्ति संभव होती है। आपको फॉर्मेटिंग या सॉफ्टवेयर की सीमाओं के बारे में चिंता किए बिना मिटा सकते हैं, फिर से बना सकते हैं और पुनर्गठित कर सकते हैं।
जब तक तार्किक संरचना सहमति पर नहीं आ जाती, तब तक इसे एक औपचारिक आरेखण उपकरण में बदला जा सकता है। इससे यह सुनिश्चित होता है कि अवधारणात्मक मॉडल सॉफ्टवेयर की सीमाओं के कारण विकृत नहीं होता है। उपकरण मॉडल की सेवा करनी चाहिए, न कि इसे निर्देशित करना चाहिए।
डिज़ाइन पर अंतिम विचार 🌟
डेटाबेस बनाना तर्क का एक अनुशासित अभ्यास है। पहला चरण, एक ठोस ERD बनाना, पूरी परियोजना के लिए दिशा तय करता है। यह आपको कोड लिखने से पहले डेटा संबंधों के बारे में सोचने के लिए मजबूर करता है। इस भविष्यवाणी से तकनीकी दायित्व कम होता है और ऐसी प्रणाली बनती है जो परिवर्तन के प्रति लचीली होती है।
स्पष्टता पर ध्यान केंद्रित करें। मानक नामाकरण का उपयोग करें। कुंजियों को सख्ती से परिभाषित करें। हितधारकों के साथ प्रमाणीकरण करें। आरेख को व्यावसायिक आवश्यकताओं और तकनीकी कार्यान्वयन के बीच के सौदे के रूप में मानें। इन चरणों का पालन करके आप सुनिश्चित कर सकते हैं कि आधार इतना मजबूत है कि आपके डेटा के भार को सहने के लिए पर्याप्त हो। 🏗️