











किसी भी सॉफ्टवेयर एप्लिकेशन के लिए एक टिकाऊ डेटाबेस का डिज़ाइन आधारभूत है। एक संरचित योजना के बिना, डेटा बिखर जाता है, प्रश्न करने में कठिनाई होती है, और त्रुटियों के लिए अधिक झंझट होता है। एक एंटिटी रिलेशनशिप डायग्राम (ERD) इस संरचना के लिए ब्लूप्रिंट के रूप में कार्य करता है। यह डेटा एंटिटीज के बीच बातचीत को दृश्यमान बनाता है, जिससे एक भी कोड लाइन लिखे जाने से पहले ही अखंडता सुनिश्चित होती है। यह मार्गदर्शिका आपको अपना पहला ERD बनाने की प्रक्रिया के माध्यम से ले जाती है, जिसमें मूल अवधारणाओं, नोटेशन और व्यावहारिक चरणों पर ध्यान केंद्रित किया गया है।
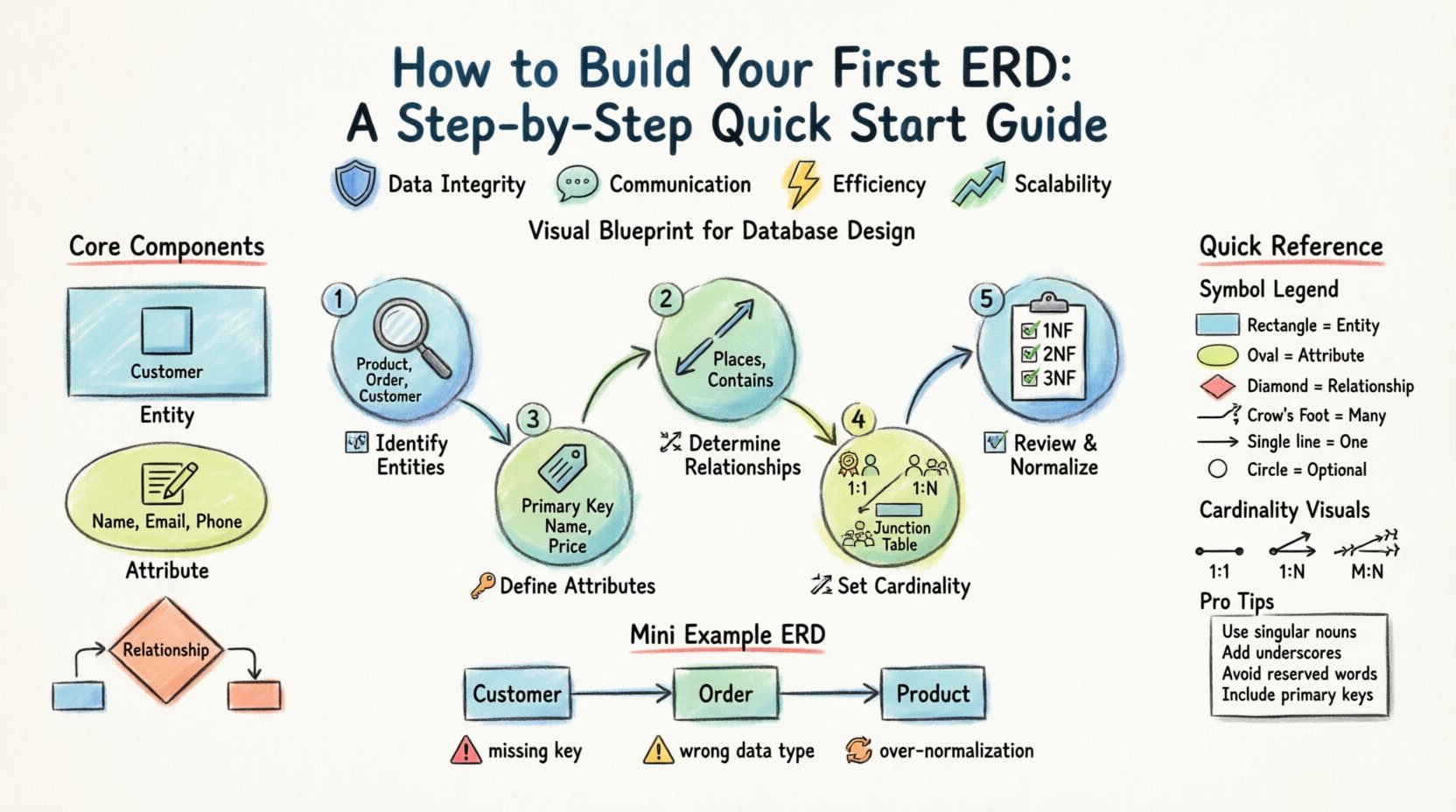
एंटिटी रिलेशनशिप डायग्राम को समझना 📊
एक ERD एक डेटाबेस स्कीमा का दृश्य प्रतिनिधित्व है। यह एंटिटीज, उनके गुणधर्मों और उनके बीच संबंधों को नक्शा बनाता है। इसे अपने डेटा के लिए एक नक्शे के रूप में सोचें। जैसे कि एक सड़क नक्शा बिंदु A से बिंदु B तक जाने में मदद करता है, वैसे ही एक ERD आपके डेटाबेस मैनेजमेंट सिस्टम को टेबलों के बीच संबंधों को समझने में मदद करता है।
इसका क्यों महत्व है?
- डेटा अखंडता: यह सुनिश्चित करता है कि डेटा पूरे सिस्टम में संगत और सटीक रहे।
- संचार: यह डेवलपर्स, डेटाबेस एडमिनिस्ट्रेटर्स और स्टेकहोल्डर्स के लिए एक सामान्य भाषा प्रदान करता है।
- कार्यक्षमता: यह बाद में अतिरिक्त डेटा की पहचान करने में मदद करता है, जिससे कार्यान्वयन चरण में समय बचता है।
- स्केलेबिलिटी: अच्छी तरह से डिज़ाइन किया गया स्कीमा डेटाबेस को पूरी तरह से बदले बिना बढ़ने देता है।
ERD के मुख्य घटक
रेखाओं और बॉक्स बनाने से पहले, आपको निर्माण तत्वों को समझना होगा। प्रत्येक डायग्राम इन तीन मूल तत्वों पर निर्भर करता है।
- एंटिटी: एक वास्तविक दुनिया की वस्तु या अवधारणा जिसके बारे में डेटा संग्रहीत किया जाता है। उदाहरण हैं ग्राहक, आदेश, या उत्पाद.
- गुणधर्म: एक एंटिटी का एक विशिष्ट गुण या विशेषता। एक ग्राहक के लिए, गुणधर्म में शामिल हो सकते हैं नाम, ईमेल, और फ़ोन नंबर.
- संबंध: दो या अधिक संस्थाओं के बीच संबंध। यह एक संस्था में डेटा के दूसरी संस्था में डेटा से जुड़ने के तरीके को परिभाषित करता है।
सामान्य ईआरडी प्रतीक और नोटेशन 🛠️
इन घटकों को दृश्य रूप से प्रस्तुत करने के अलग-अलग तरीके हैं। दो सबसे आम शैलियां चेन नोटेशन और क्राउ के फुट नोटेशन हैं। जबकि चेन नोटेशन आयताकार और हीरे के आकार के चिह्नों का उपयोग करता है, क्राउ के फुट नोटेशन आयताकार और विशिष्ट छोरों वाली रेखाओं का उपयोग करता है। अधिकांश आधुनिक डेटाबेस मॉडलिंग उपकरण क्राउ के फुट के विभिन्न रूपों का उपयोग करते हैं।
| प्रतीक | अर्थ | उपयोग उदाहरण |
|---|---|---|
| आयत | एक संस्था का प्रतिनिधित्व करता है | एक बॉक्स जिस पर लेबल है छात्र |
| अंडाकार | एक गुण का प्रतिनिधित्व करता है | एक अंडाकार जो छात्रलेबल किया गया आईडी |
| हीरा | एक संबंध का प्रतिनिधित्व करता है | एक हीरा जो छात्रऔर पाठ्यक्रम |
| क्राउ के फुट वाली रेखा | “बहुतायत” (एम) को इंगित करता है | एक छात्र बहुत से पाठ्यक्रम ले सकता है |
| एकल टिक वाली रेखा | “एक” (1) को इंगित करता है | एक कोर्स का एक इंस्ट्रक्टर होता है |
| वृत्त | वैकल्पिक भागीदारी को इंगित करता है | एक छात्र को अभी तक निर्धारित आईडी नहीं मिली हो सकती है |
अपना पहला ERD बनाने का चरण-दर-चरण मार्गदर्शिका 🚀
ERD बनाना एक तार्किक प्रक्रिया है। शुरुआत करने के लिए आपको अंतिम कोड के बारे में जानने की आवश्यकता नहीं है। आपको व्यापार आवश्यकताओं को समझने की आवश्यकता है। एक मजबूत आधार बनाने के लिए इन चरणों का पालन करें।
चरण 1: संसाधनों की पहचान करें 📦
पहला कार्य अपने प्रणाली में प्रत्येक अलग-अलग वस्तु की सूची बनाना है। अपने व्यापार आवश्यकता दस्तावेज़ को देखें या रुचि रखने वाले पक्षों से साक्षात्कार करें ताकि संज्ञाएँ पता लगाई जा सकें। इन संज्ञाओं को आमतौर पर आपके संसाधन माना जाता है।
- संज्ञाओं के लिए खोजें: यदि आप एक पुस्तकालय प्रणाली बना रहे हैं, तो Book, Member, Loan और Fine जैसे शब्दों की तलाश करें।
- असंबंधित आइटम को फ़िल्टर करें: हर संज्ञा एक संसाधन नहीं होती है। शब्द जैसेप्रोसेसिंग याचेकिंग आमतौर पर क्रियाएँ होती हैं, संसाधन नहीं।
- इसे छोटे-छोटे हिस्सों में रखें: एक बॉक्स में कई अवधारणाओं को मिलाने से बचें। एकग्राहक पता संसाधन को अंततः दो हिस्सों में बाँटने की आवश्यकता हो सकती हैग्राहक औरपता यदि आपको कई पतों को ट्रैक करने की आवश्यकता हो।
उदाहरण सूची:
- उत्पाद
- आपूर्तिकर्ता
- आदेश
- ग्राहक
चरण 2: गुणवत्ता को परिभाषित करें 🏷️
जब एकताओं की पहचान कर ली जाती है, तो आपको यह तय करना होगा कि उनके बारे में कौन सी जानकारी संग्रहीत करने की आवश्यकता है। गुणवत्ता आपकी अंतिम डेटाबेस तालिका में कॉलम होती हैं।
- प्राथमिक कुंजियाँ: प्रत्येक एकता को एक अद्वितीय पहचानकर्ता की आवश्यकता होती है। यह आमतौर पर एक आईडी फ़ील्ड होती है (उदाहरण के लिए,
ग्राहकआईडी,उत्पादआईडी)। प्रत्येक रिकॉर्ड के लिए यह अद्वितीय होना चाहिए। - वर्णनात्मक गुणवत्ताएँ: ये एकता का वर्णन करती हैं। एक उत्पाद के लिए, इसमें शामिल है नाम, मूल्य, और स्टॉकमात्रा.
- विदेशी कुंजियाँ: इन्हें बाद में संबंध चरण के दौरान पहचाना जाएगा, लेकिन यह ध्यान रखें कि डेटा कहाँ अन्य तालिकाओं से जुड़ेगा।
सर्वोत्तम व्यवहार: गणना किए गए मूल्यों को गुणवत्ता के रूप में संग्रहीत करने से बचें (उदाहरण के लिए, कुलमूल्य)। डेटा असंगति से बचने के लिए इन्हें रनटाइम पर गणना करें।
चरण 3: संबंधों का निर्धारण करें 🔗
अब आप एकताओं को जोड़ते हैं। इस चरण में डेटा के बारे में बातचीत का निर्धारण किया जाता है। ऐसे प्रश्न पूछें: क्या एक ग्राहक के कई आदेश हो सकते हैं? क्या एक आदेश कई ग्राहकों के लिए हो सकता है?
- संबंधों की पहचान करें: अपनी आवश्यकताओं में क्रियाओं को खोजें। स्थानों, समावेश करता है, आपूर्ति करता है.
- दिशा परिभाषित करें: निर्धारित करें कि संबंध एक दिशात्मक है या द्विदिशात्मक।
- संक्रामकता की जांच करें: सुनिश्चित करें कि संबंध सीधे हों। यदि A, B से संबंधित है और B, C से संबंधित है, तो जांचें कि क्या A को C से सीधा संबंध होना आवश्यक है।
चरण 4: कार्डिनैलिटी और भागीदारी स्थापित करें 📏
कार्डिनैलिटी एक एकांकी के उन उदाहरणों की संख्या को परिभाषित करती है जो दूसरे एकांकी के उदाहरणों से संबंधित होते हैं। यह विदेशी कुंजी सीमाओं को परिभाषित करने के लिए महत्वपूर्ण है।
कार्डिनैलिटी के प्रकार
- एक से एक (1:1): एकांकी A का एक उदाहरण एकांकी B के ठीक एक उदाहरण से संबंधित होता है। उदाहरण: एक कर्मचारी के एक कर्मचारी बैज होते हैं।
- एक से बहुत (1:N): एकांकी A का एक उदाहरण एकांकी B के कई उदाहरणों से संबंधित होता है। उदाहरण: एक प्रबंधक बहुत से कर्मचारियों का निरीक्षण करता है।
- बहुत से से बहुत (M:N): एकांकी A के कई उदाहरण एकांकी B के कई उदाहरणों से संबंधित होते हैं। उदाहरण: बहुत से छात्र बहुत से पाठ्यक्रमों में नामांकित होते हैं।
भागीदारी सीमाएं
- अनिवार्य: एकांकी को संबंध में भाग लेना आवश्यक है। प्रत्येक आदेश को एक ग्राहक होना चाहिए।
- वैकल्पिक: एकांकी को भाग लेना आवश्यक नहीं है। यदि ग्राहक केवल दुकान पर भुगतान करता है, तो उसके पास शिपिंग पता नहीं हो सकता है।
बहुत से से बहुत के बारे में नोट: अधिकांश संबंधात्मक डेटाबेस बहुत से से बहुत संबंधों को सीधे संग्रहीत नहीं कर सकते। आपको एक संयोजन तालिका (या ब्रिज तालिका) बनाकर उन्हें हल करना होगा। छात्रों और पाठ्यक्रमों के लिए, एक तालिका बनाएं जिसका नाम हैनामांकन जो स्टूडेंटआईडी और कोर्सआईडी को जोड़ती है।
चरण 5: समीक्षा और सामान्यीकरण 🧹
संबंध बनाने के बाद, अपने आरेख की संरचनात्मक कमियों के लिए समीक्षा करें। सामान्यीकरण डेटा को व्यवस्थित करने की प्रक्रिया है जिससे अतिरिक्तता को कम किया जाता है और अखंडता में सुधार होता है।
- पहला सामान्य रूप (1NF): सुनिश्चित करें कि प्रत्येक कॉलम में परमाणु मान हों। एक कोष्ठक में कोई सूची या ऐरे नहीं होनी चाहिए।
- द्वितीय सामान्य रूप (2NF): सुनिश्चित करें कि सभी गैर-कुंजी विशेषताएं मुख्य कुंजी पर पूर्ण रूप से निर्भर हों। आंशिक निर्भरताओं को हटाएं।
- तृतीय सामान्य रूप (3NF): सुनिश्चित करें कि कोई अनुक्रमिक निर्भरता न हो। गैर-कुंजी विशेषताओं पर निर्भर विशेषताओं को हटाएं।
अधिकांश अनुप्रयोगों के लिए आपको 3NF से आगे जाने की आवश्यकता नहीं है, लेकिन इन नियमों का पालन करने से डेटा विचलनों से बचा जा सकता है।
बचने के लिए सामान्य त्रुटियां ⚠️
यहां तक कि अनुभवी डिजाइनर भी गलतियां करते हैं। सामान्य त्रुटियों के बारे में जागरूक रहने से आप बाद में बड़े पुनर्निर्माण से बच सकते हैं।
- मौजूद नहीं मुख्य कुंजी: कभी भी एक अद्वितीय पहचानकर्ता के बिना तालिका न बनाएं। इससे रिकॉर्ड के अद्यतन और हटाने करना लगभग असंभव हो जाता है।
- गलत डेटा प्रकार: सुनिश्चित करें कि विशेषताएं डेटा के अनुरूप हों। तारीखों को पाठ के रूप में संग्रहीत न करें। अगर आपको पैसे के आधे रुपये की आवश्यकता है, तो मूल्यों को पूर्णांक के रूप में संग्रहीत न करें।
- अत्यधिक सामान्यीकरण: जबकि सामान्यीकरण अच्छा है, बहुत सारी तालिकाएं प्रश्नों को धीमा और जटिल बना सकती हैं। आंतरिक अखंडता और प्रदर्शन के बीच संतुलन बनाएं।
- केस संवेदनशीलता को नजरअंदाज करना: जल्दी से तय करें कि क्या आपका प्रणाली केस-संवेदनशील है।ईमेल@डोमेन.कॉम को अलग तरीके से नहीं माना जाना चाहिएईमेल@डोमेन.कॉम.
- कड़े मान: ऐसे स्थिति कोड को संग्रहीत करने से बचें जैसे
1या2बिना संदर्भ तालिका के। स्थिति के लिए जैसे उपयोग करेंसक्रिय, अक्रिय, प्रतीक्षा में.
नामकरण प्रथाओं के लिए सर्वोत्तम व्यवहार 📝
नामकरण में निरंतरता आपके एरडी और परिणामस्वरूप डेटाबेस को सभी शामिल पक्षों के लिए पढ़ने योग्य बनाती है। भ्रमित नाम कोड में भ्रम का कारण बनता है।
- एकवचन संज्ञा का उपयोग करें: तालिकाओं के नाम एकवचन रूप में रखें (उदाहरण के लिए, ग्राहक के बजाय ग्राहक).
- अंडरस्कोर का उपयोग करें: पठनीयता के लिए शब्दों को अंडरस्कोर से अलग करें (उदाहरण के लिए,
ग्राहक_नामके बजायग्राहकनाम). - आरक्षित शब्दों से बचें: ऐसे कीवर्ड्स का उपयोग न करें जैसे आदेश, उपयोगकर्ता, या समूह बिना संशोधन के तालिका नाम के रूप में, क्योंकि वे एसक्यूएल सिंटैक्स के साथ टकराव का कारण बन सकते हैं।
- विवरणात्मक बनें: स्पष्ट नाम का उपयोग करें।
ग्राहक_आईडीठीक है, लेकिनग्राहक_आईडीस्पष्टता के लिए बेहतर है। - प्रीफिक्स को मानकीकृत करें: यदि विशिष्ट स्कीमा का उपयोग कर रहे हैं, तो प्रीफिक्स बनाए रखें (उदाहरण के लिए,
tbl_याref_).
डेटा फ्लो का दृश्यीकरण 🔄
जब आपका आरेख पूरा हो जाए, तो देखें कि डेटा सिस्टम के माध्यम से कैसे आगे बढ़ता है। इससे एप्लिकेशन लॉजिक को समझने में मदद मिलती है।
- प्रविष्टि: नई डेटा प्राथमिक एंटिटी में कैसे प्रवेश करती है? (उदाहरण के लिए, एक नया ग्राहक रिकॉर्ड).
- संशोधन: डेटा कैसे अपडेट होता है? (उदाहरण के लिए, पते को बदलना).
- हटाना: जब कोई रिकॉर्ड हटाया जाता है तो संबंधित डेटा पर क्या प्रभाव पड़ता है? (उदाहरण के लिए, कैस्केड हटाना बनाम प्रतिबंधित करना).
- प्रश्न पूछना: आप डेटा कैसे प्राप्त करेंगे? (उदाहरण के लिए, ऑर्डर और ग्राहक तालिकाओं को जोड़ना).
आरेखण के लिए उपकरण 🖥️
आप कागज पर बना सकते हैं, लेकिन डिजिटल उपकरणों में संस्करण नियंत्रण और स्वचालित SQL उत्पादन जैसे लाभ होते हैं। एक उपकरण चुनते समय, मानक ERD नोटेशन का समर्थन करने वाली विशेषताओं की तलाश करें।
- सहयोग: क्या एक साथ कई उपयोगकर्ता आरेख को संपादित कर सकते हैं?
- निर्यात विकल्प: क्या आप SQL स्क्रिप्ट, PNG या PDF में निर्यात कर सकते हैं?
- सत्यापन: क्या उपकरण नॉर्मलाइजेशन नियमों या सर्कुलर निर्भरता की जांच करता है?
- एकीकरण: क्या यह आपके मौजूदा कार्यप्रणाली या प्रोजेक्ट प्रबंधन उपकरणों के साथ एकीकृत है?
अक्सर पूछे जाने वाले प्रश्न ❓
यहां उन सामान्य प्रश्नों के उत्तर हैं जो शुरुआती लोग डेटाबेस डिजाइन के आरंभ में अक्सर पूछते हैं।
1. क्या मुझे ERD बनाने से पहले SQL जानने की आवश्यकता है?
नहीं। एक ERD एक डिजाइन उपकरण है। आप SQL लिखे बिना तार्किक संरचना बना सकते हैं। आरेख आपको यह समझने में मदद करता है कि आपको अंततः कौन सा SQL लिखने की आवश्यकता होगी।
2. क्या एक ERD बाद में बदल सकता है?
हाँ, लेकिन इसे न्यूनतम करना चाहिए। डेटाबेस के भरे होने के बाद ERD में बदलाव करना महंगा और जोखिम भरा हो सकता है। डेप्लॉयमेंट से पहले डिज़ाइन को अंतिम रूप देना सबसे अच्छा है।
3. लॉजिकल और फिजिकल ERD में क्या अंतर है?
- लॉजिकल ERD: विशिष्ट डेटाबेस सॉफ्टवेयर विवरणों के बारे में चिंता किए बिना एंटिटीज़ और संबंधों पर ध्यान केंद्रित करता है।
- फिजिकल ERD: एक विशिष्ट डेटाबेस मैनेजमेंट सिस्टम के लिए आवश्यक विशिष्ट डेटा प्रकार, इंडेक्स और सीमाएँ शामिल करता है।
4. कितनी टेबलें बहुत अधिक हैं?
कोई निश्चित संख्या नहीं है। यह जटिलता पर निर्भर करता है। हालांकि, यदि आप एक सरल एप्लिकेशन के लिए बहुत सारी टेबलें बना रहे हैं, तो आप ओवर-नॉर्मलाइज़ कर रहे होंगे।
5. क्या मुझे गैर-संबंधित डेटा शामिल करना चाहिए?
मानक ERD के लिए संबंधित डेटा होता है। यदि आप डॉक्यूमेंट स्टोर या ग्राफ डेटाबेस का डिज़ाइन कर रहे हैं, तो अवधारणाएँ थोड़ी अलग होती हैं। इस गाइड में संबंधित मॉडल पर ध्यान केंद्रित किया गया है।
अंतिम विचार 🎯
अपना पहला ERD बनाने के लिए धैर्य और विस्तार से ध्यान देने की आवश्यकता होती है। यह केवल आकृतियाँ बनाने के बारे में नहीं है; यह वास्तविक दुनिया की तर्क को एक संरचित प्रारूप में मॉडल करने के बारे में है। ऊपर बताए गए चरणों का पालन करके, आप सुनिश्चित कर सकते हैं कि आपका डेटाबेस स्केलेबल, कुशल और आसानी से बनाए रखने योग्य होगा।
छोटे से शुरू करें। सबसे पहले एक सरल प्रणाली का नक्शा बनाएं। एंटिटीज़ और संबंधों की पहचान करने का अभ्यास करें। जैसे आप अनुभव प्राप्त करेंगे, आप पाएंगे कि जटिल प्रणालियों का डिज़ाइन करना स्वाभाविक हो जाता है। याद रखें, एक अच्छा डेटाबेस डिज़ाइन उपयोगकर्ता के लिए अदृश्य होता है, लेकिन एप्लिकेशन की सफलता के लिए महत्वपूर्ण होता है।
नॉर्मलाइज़ेशन चरण के साथ अपना समय लें। यह प्रक्रिया का सबसे तकनीकी हिस्सा है, लेकिन यह डेटा गुणवत्ता में लाभ देता है। यहाँ चर्चा किए गए प्रतीकों और प्रथाओं का उपयोग करके अपने आरेख स्पष्ट रखें। एक ठोस ERD के साथ, आप इम्प्लीमेंटेशन के लिए तैयार हैं।