











एक टिकाऊ डेटा संरचना बनाना किसी भी विश्वसनीय सॉफ्टवेयर एप्लिकेशन की नींव है। जब आप जानकारी स्टोर करने वाले सिस्टम को बनाना शुरू करते हैं, तो आपको एक ब्लूप्रिंट की आवश्यकता होती है। वह ब्लूप्रिंट ही एंटिटी रिलेशनशिप डायग्राम है, जिसे सामान्यतः ERD के रूप में जाना जाता है। यह दृश्य प्रतिनिधित्व डेवलपर्स और स्टेकहोल्डर्स को एक लाइन कोड लिखे बिना ही डेटा के जुड़ाव को समझने में सक्षम बनाता है। इस योजना चरण के बिना, डेटाबेस अक्सर भारी, धीमी और बनाए रखने में कठिन हो जाती है। 🏗️
यह गाइड ERD डिज़ाइन के मूल सिद्धांतों को समझाती है। हम आवश्यक घटकों, डेटा संबंधों को नियंत्रित करने वाले नियमों और एक स्केल करने योग्य स्कीमा बनाने के लिए आवश्यक तार्किक चरणों का अध्ययन करेंगे। चाहे आप एक छात्र हों, एक जूनियर डेवलपर हों या एक प्रोडक्ट मैनेजर हों, इन अवधारणाओं को समझने से यह सुनिश्चित होता है कि आपकी डेटा आर्किटेक्चर समय के साथ भी स्थिर रहे।
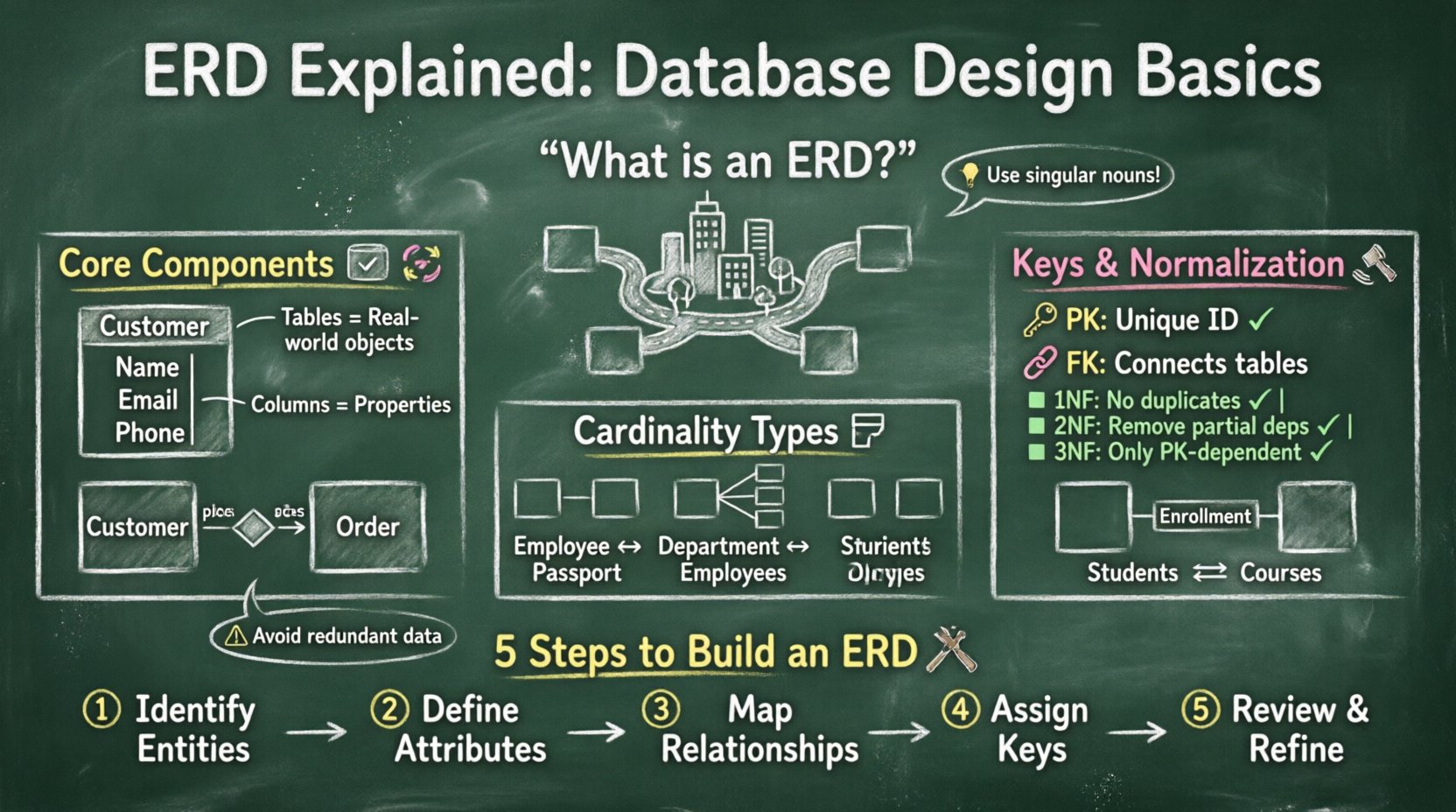
एक ERD वास्तव में क्या है? 🤔
एक एंटिटी रिलेशनशिप डायग्राम एक उच्च स्तरीय मॉडल है जिसका उपयोग डेटाबेस की संरचना का वर्णन करने के लिए किया जाता है। यह एंटिटीज़ को नक्शा बनाता है, जो वास्तविक दुनिया की वस्तुओं या अवधारणाओं का प्रतिनिधित्व करते हैं, और उनके बीच मौजूद संबंधों को दर्शाता है। इसे अपने डेटा के लिए एक नक्शा समझें। जैसे एक शहर का नक्शा रोड्स को निकटवर्ती इलाकों से जोड़ता है, वैसे ही ERD टेबल्स को विशिष्ट डेटा बिंदुओं से जोड़ता है।
इस डायग्राम का प्राथमिक उद्देश्य डेटाबेस की तार्किक संरचना को संचारित करना है। यह तकनीकी टीमों और बिजनेस एनालिस्ट्स के बीच एक सार्वभौमिक भाषा के रूप में कार्य करता है। डेटा प्रवाह को दृश्याकृत करके, आप जैसे कि अतिरिक्त डेटा या गायब लिंक्स जैसी संभावित समस्याओं को जल्दी से पहचान सकते हैं। इस सक्रिय दृष्टिकोण से विकास चरण के दौरान महत्वपूर्ण समय बचता है।
ERD के उपयोग के मुख्य लाभ इस प्रकार हैं:
- स्पष्टता:जटिल डेटा संरचनाओं को दृश्याकृत करने से उन्हें समझना आसान हो जाता है।
- स्थिरता:सुनिश्चित करता है कि सभी टीम सदस्य डेटा को कैसे परिभाषित किया जाए, इस पर सहमत हों।
- कार्यक्षमता:अनावश्यक जॉइन्स को कम करके प्रश्न प्रदर्शन को अनुकूलित करने में मदद करता है।
- दस्तावेज़ीकरण:भविष्य के रखरखाव के लिए एक संदर्भ गाइड के रूप में कार्य करता है।
डेटाबेस स्कीमा के मुख्य घटक 🔑
एक डायग्राम को प्रभावी ढंग से बनाने के लिए, आपको निर्माण ब्लॉक्स को समझना होगा। प्रत्येक डायग्राम तीन मुख्य तत्वों पर निर्भर करता है: एंटिटीज़, एट्रिब्यूट्स और संबंध। इन मूल बातों को समझने से किसी भी डेटाबेस प्रोजेक्ट के लिए आवश्यक ढांचा प्राप्त होता है।
1. एंटिटीज़: टेबल्स 📦
एक एंटिटी व्यापार क्षेत्र में एक विशिष्ट वस्तु, व्यक्ति या अवधारणा का प्रतिनिधित्व करती है। एक संबंधात्मक डेटाबेस में, एक एंटिटी एक टेबल के समान होती है। प्रत्येक टेबल उस एंटिटी के बारे में अद्वितीय जानकारी स्टोर करती है। उदाहरण के लिए, एक लाइब्रेरी प्रणाली में, “बुक” और “मेंबर” अलग-अलग एंटिटीज़ हैं।
एंटिटीज़ को आमतौर पर डायग्राम में आयत के रूप में दर्शाया जाता है। उन्हें व्यक्तिगत उदाहरणों को दर्शाने के लिए एकवचन संज्ञा का उपयोग करके नामित किया जाना चाहिए। एक एंटिटी को परिभाषित करते समय, आप वास्तव में डेटा की एक श्रेणी को परिभाषित कर रहे होते हैं।
- स्ट्रॉन्ग एंटिटीज़: ये स्वतंत्र रूप से अस्तित्व में होती हैं। एक “ग्राहक” टेबल अन्य टेबल्स के बिना भी मौजूद होती है।
- वीक एंटिटीज़: ये अस्तित्व के लिए दूसरी एंटिटी पर निर्भर होती हैं। एक “ऑर्डर आइटम” एक दुर्बल एंटिटी हो सकती है क्योंकि इसका अर्थ एक “ऑर्डर” पर निर्भर करता है।
2. एट्रिब्यूट्स: कॉलम्स 📝
एट्रिब्यूट्स वे गुण या विशेषताएं हैं जो एंटिटी का वर्णन करती हैं। डेटाबेस टेबल में, इन्हें कॉलम्स बना दिया जाता है। उदाहरण के लिए, एक “ग्राहक” एंटिटी में नाम, ईमेल और फोन नंबर जैसे एट्रिब्यूट्स हो सकते हैं।
एट्रिब्यूट्स को कई प्रकारों में वर्गीकृत किया जा सकता है:
- सरल एट्रिब्यूट्स:आगे विभाजित नहीं किया जा सकता, जैसे आयु या जन्मतिथि।
- संयुक्त एट्रिब्यूट्स: उप-भागों में विभाजित किया जा सकता है, जैसे पता (सड़क, शहर, जिप)।
- बहु-मूल्य वाले गुण: एक से अधिक मान रख सकता है, जैसे कौशल या फोन नंबर।
- व्युत्पन्न गुण: अन्य गुणों से गणना की गई, जैसे आयु (जन्म तिथि से व्युत्पन्न)।
3. संबंध: संपर्क 🔄
संबंध यह निर्धारित करते हैं कि संस्थाएं एक-दूसरे के साथ कैसे बातचीत करती हैं। यह डिजाइन का सबसे महत्वपूर्ण हिस्सा है क्योंकि यह निर्धारित करता है कि डेटा कैसे जुड़ा है। आरेख में, संबंध हीरे या एकत्रित संस्थाओं को जोड़ने वाली रेखाओं के रूप में दिखाए जाते हैं।
उदाहरण के लिए, एक “ग्राहक” एक “आदेश” देता है। यह एक संबंध है। डेटाबेस को नियमों को लागू करना चाहिए ताकि आदेश को उनके लिए निर्धारित करने से पहले ग्राहक के अस्तित्व की जांच की जा सके। इससे अनाथ डेटा से बचा जा सकता है।
कार्डिनैलिटी और मोडैलिटी को समझना 📏
कार्डिनैलिटी दो संबंधित तालिकाओं में रिकॉर्डों के बीच संख्यात्मक संबंध को परिभाषित करती है। यह प्रश्न का उत्तर देती है: “एंटिटी ए के कितने उदाहरण एंटिटी बी के कितने उदाहरण से संबंधित हैं?” इसकी समझ से डेटा विचलनों से बचा जा सकता है।
कार्डिनैलिटी के तीन मुख्य प्रकार हैं:
- एक से एक (1:1):तालिका ए में एक रिकॉर्ड तालिका बी में बिल्कुल एक रिकॉर्ड से संबंधित होता है।
- एक से बहुत (1:N):तालिका ए में एक रिकॉर्ड तालिका बी में बहुत सारे रिकॉर्ड से संबंधित होता है।
- बहुत से बहुत (M:N):तालिका ए में बहुत सारे रिकॉर्ड तालिका बी में बहुत सारे रिकॉर्ड से संबंधित होते हैं।
नीचे एक तालिका व्यावहारिक उदाहरणों के साथ इन संबंधों को समझाती है।
| कार्डिनैलिटी प्रकार | उदाहरण परिदृश्य | कार्यान्वयन |
|---|---|---|
| एक से एक (1:1) | कर्मचारी से पासपोर्ट | एक तालिका में विदेशी कुंजी |
| एक से बहुत (1:N) | विभाग से कर्मचारी | “बहुत” तालिका में विदेशी कुंजी |
| बहुत से बहुत (M:N) | छात्र से पाठ्यक्रम | मध्यवर्ती संयोजन तालिका |
मॉडैलिटी विवरण की एक और परत जोड़ती है। यह निर्धारित करती है कि क्या संबंध अनिवार्य है या वैकल्पिक। उदाहरण के लिए, क्या एक ऑर्डर ग्राहक के बिना मौजूद हो सकता है? आमतौर पर नहीं। यह एक अनिवार्य संबंध है। क्या एक ग्राहक के पास कोई ऑर्डर नहीं हो सकते? हां, यह वैकल्पिक है।
कीज़: डेटा अखंडता का चिपचिपा चिपकाव 🔗
कीज़ विशिष्ट विशेषताएं हैं जिनका उपयोग रिकॉर्ड को अद्वितीय रूप से पहचानने या तालिकाओं को एक साथ जोड़ने के लिए किया जाता है। ये संबंधों को लागू करने और डेटा अखंडता को बनाए रखने का तंत्र हैं।
प्राथमिक कीज़
एक प्राथमिक की (PK) तालिका में प्रत्येक रिकॉर्ड की पहचान करती है। कोई भी दो पंक्तियां समान प्राथमिक की मान नहीं रख सकती हैं। यह खाली नहीं हो सकती है। सामान्य विकल्प में स्वतः बढ़ते पूर्णांक या UUIDs शामिल हैं। इससे यह सुनिश्चित होता है कि प्रत्येक डेटा का एक अद्वितीय पता होता है।
विदेशी कीज़
एक विदेशी की (FK) एक तालिका में एक फ़ील्ड है जो दूसरी तालिका में प्राथमिक की की ओर इशारा करती है। यह दोनों के बीच संबंध स्थापित करती है। जब आप एक विदेशी की को परिभाषित करते हैं, तो डेटाबेस प्रबंधन प्रणाली तार्किक अखंडता को लागू करती है। इसका मतलब है कि आप एक रिकॉर्ड नहीं जोड़ सकते जिसके विदेशी की मान मातृ तालिका में मौजूद नहीं है।
मिश्रित कीज़
कभी-कभी, एक ही कॉलम के लिए एक रिकॉर्ड को अद्वितीय रूप से पहचानने के लिए पर्याप्त नहीं होता है। एक मिश्रित की दो या अधिक कॉलमों को मिलाकर एक अद्वितीय पहचानकर्ता बनाती है। यह आमतौर पर बहु-से-बहु संबंधों के लिए जंक्शन तालिकाओं में होता है।
नॉर्मलाइजेशन: अपने डेटा को व्यवस्थित करना 🧹
नॉर्मलाइजेशन डेटा को व्यवस्थित करने की प्रक्रिया है जिससे अतिरेक को कम किया जाता है और अखंडता में सुधार होता है। इसमें बड़ी तालिकाओं को छोटी, तार्किक रूप से जुड़ी तालिकाओं में विभाजित करना शामिल है। इन नियमों का पालन करने से अपडेट, इन्सर्शन या डिलीट के दौरान असंगतियों से बचा जा सकता है।
कई नॉर्मल फॉर्म हैं, लेकिन पहले तीन का उपयोग सबसे अधिक किया जाता है:
- पहला सामान्य रूप (1NF):एक ही तालिका से डुप्लीकेट कॉलम को हटाएं। संबंधित डेटा के लिए अलग-अलग तालिकाएं बनाएं और प्रत्येक पंक्ति को प्राथमिक की के साथ पहचानें।
- दूसरा सामान्य रूप (2NF): 1NF की सभी आवश्यकताओं को पूरा करें। उन डेटा के उपसमूहों को हटाएं जो एक तालिका की एक से अधिक पंक्तियों पर लागू होते हैं और उन्हें अलग तालिकाओं में रखें।
- तीसरा सामान्य रूप (3NF): 2NF की सभी आवश्यकताओं को पूरा करें। प्राथमिक की पर निर्भर न होने वाले कॉलम को हटाएं।
हालांकि उच्च रूप (4NF, 5NF) भी मौजूद हैं, लेकिन अधिकांश एप्लिकेशन के लिए 3NF तक पहुंचना आमतौर पर पर्याप्त होता है। अत्यधिक नॉर्मलाइजेशन के कारण जटिल प्रश्न बन सकते हैं जिनके लिए बहुत सारे जॉइन की आवश्यकता होती है, जो प्रदर्शन को प्रभावित कर सकते हैं। संतुलन महत्वपूर्ण है।
एक ईआरडी बनाने के चरण 🛠️
एक आरेख बनाना एक व्यवस्थित प्रक्रिया है। आप आकृतियां बनाने से शुरू नहीं करते; आप आवश्यकताओं को समझने से शुरू करते हैं। एक विश्वसनीय मॉडल बनाने के लिए इन चरणों का पालन करें।
चरण 1: एंटिटीज़ की पहचान करें
व्यावसायिक आवश्यकताओं की समीक्षा करें। वर्णन में वस्तुओं या लोगों का प्रतिनिधित्व करने वाले संज्ञाओं को देखें। यदि आवश्यकता कहती है कि “हर उपयोगकर्ता लॉगिन को ट्रैक करें”, तो एंटिटी “उपयोगकर्ता” या “लॉगिन” है। सभी संभावित एंटिटीज़ की सूची बनाएं।
चरण 2: विशेषताओं को परिभाषित करें
प्रत्येक एंटिटी के लिए यह निर्धारित करें कि कौन सी जानकारी संग्रहीत करने की आवश्यकता है। यह पूछें कि एंटिटी को पूरी तरह से वर्णित करने के लिए कौन सी विवरण आवश्यक हैं। “उपयोगकर्ता” एंटिटी के लिए आपको उपयोगकर्ता नाम, पासवर्ड और ईमेल की आवश्यकता हो सकती है।
चरण 3: संबंधों को निर्धारित करें
एंटिटीज़ को उनके बीच बातचीत के आधार पर जोड़ें। पूछें कि एंटिटीज़ कैसे संबंधित हैं। क्या एक उपयोगकर्ता के बहुत सारे लॉगिन हैं? क्या एक उत्पाद एक श्रेणी से संबंधित है? रेखाएं खींचें और कार्डिनैलिटी को परिभाषित करें।
चरण 4: कीज़ निर्धारित करें
प्रत्येक एंटिटी के लिए प्राथमिक की की पहचान करें। फिर, जहां संबंध मौजूद हैं, वहां विदेशी कीज़ जोड़ें। इस चरण से अवधारणात्मक आरेख को एक तार्किक स्कीमा में बदल दिया जाता है जो कार्यान्वयन के लिए तैयार है।
चरण 5: समीक्षा और सुधार करें
स्टेकहोल्डर्स के साथ मॉडल के माध्यम से चलें। गायब डेटा बिंदु या गलत संबंधों की जांच करें। सुनिश्चित करें कि डिज़ाइन इच्छित प्रश्नों का समर्थन करता है। आवश्यकताओं को पूरा करने तक आरेख को सुधारें।
बचने के लिए सामान्य गलतियाँ ⚠️
यहां तक कि अनुभवी डिज़ाइनर भी गलतियां करते हैं। सामान्य त्रुटियों के बारे में जागरूक होने से आप एक स्पष्ट प्रणाली बना सकते हैं। डिज़ाइन चरण के दौरान ध्यान देने योग्य मुद्दे यहां दिए गए हैं।
- गायब संबंध: तालिकाओं को जोड़ना भूलने से डेटा सिलो में जाने की संभावना होती है जहां जानकारी को जोड़ा नहीं जा सकता।
- आवश्यकता से अधिक डेटा: एक ही जानकारी को बहुत सारी तालिकाओं में संग्रहीत करने से भंडारण बढ़ता है और असंगति का खतरा बढ़ता है।
- गलत कार्डिनैलिटी: जब यह बहु-से-बहु होना चाहिए, तो एक-से-बहु के रूप में संबंध सेट करने से सत्यापन त्रुटियां उत्पन्न होती हैं।
- नाम संघर्ष: “Data1” या “TableA” जैसे अस्पष्ट नामों का उपयोग करने से बाद में स्कीमा समझना मुश्किल हो जाता है।
- नल योग्यता को नजरअंदाज करना: यह निर्दिष्ट करने में विफलता करना कि कॉलम में नल मान स्वीकार्य हैं या नहीं, डेटा एंट्री के दौरान अप्रत्याशित त्रुटियां उत्पन्न कर सकता है।
दृश्य निर्देशांक 🎨
अलग-अलग टीमें ERD बनाने के लिए अलग-अलग शैलियों का उपयोग करती हैं। दो सबसे आम मानक क्राउ के फुट और चेन निर्देशांक हैं।
- क्राउ के फुट निर्देशांक: विशिष्ट अंत वाली रेखाओं का उपयोग कार्डिनैलिटी को दर्शाने के लिए करता है। एक रेखा का अर्थ है एक, एक शाखा वाली रेखा का अर्थ है बहुत सारे। यह आधुनिक उपकरणों में व्यापक रूप से उपयोग किया जाता है।
- चेन निर्देशांक: संबंधों के लिए हीरे के आकार का उपयोग करता है और गुणों के लिए अंडाकार का उपयोग करता है। यह अधिक विस्तृत है लेकिन जटिल प्रणालियों में भारी हो सकता है।
निर्देशांक के प्रकार के बावजूद, स्पष्टता सर्वोच्च महत्व की है। आरेख को प्रोजेक्ट में शामिल किसी भी व्यक्ति द्वारा पढ़ा जा सकना चाहिए, बस डेटाबेस प्रबंधक द्वारा नहीं।
अवधारणा से भौतिक कार्यान्वयन तक 🚀
जब तक तार्किक डिज़ाइन पूरा नहीं हो जाता, उसे भौतिक डेटाबेस में बदलना होगा। इसमें डेटा प्रकार चुनना और प्रदर्शन के लिए अनुकूलन शामिल है।
इस चरण के दौरान, आप अपने गुणों के लिए विशिष्ट डेटा प्रकार चुनते हैं। उदाहरण के लिए, एक तारीख क्षेत्र को डेटा प्रकार का उपयोग करना चाहिए, न कि स्ट्रिंग। एक मूल्य क्षेत्र को दशमलव का उपयोग करना चाहिए, न कि पूर्णांक, ताकि भिन्नांकों को हैंडल किया जा सके। इन चयनों का भंडारण आकार और प्रश्न गति पर प्रभाव पड़ता है।
इंडेक्सिंग भी महत्वपूर्ण है। अक्सर खोजे जाने वाले कॉलम, विशेष रूप से विदेशी कुंजियों पर इंडेक्स बनाने से प्राप्ति तेज हो जाती है। हालांकि, बहुत सारे इंडेक्स लेखन ऑपरेशन को धीमा कर सकते हैं। अपने लोड के लिए सही संतुलन ढूंढें।
योजना का महत्व गति से अधिक क्यों है ⏳
डिज़ाइन चरण को छोड़कर तुरंत कोडिंग शुरू करने के लिए आकर्षक है। हालांकि, बाद में डेटाबेस संरचना बदलना महंगा होता है। डेटा को हटाना या कॉलम को बदलना मौजूदा एप्लिकेशन को तोड़ सकता है।
अच्छी तरह से विचार किए गए ERD एक अनुबंध के रूप में काम करता है। यह डेटा अंतरक्रिया के नियमों को परिभाषित करता है। यदि आप योजना का पालन करते हैं, तो विकास सुचारु हो जाता है। यदि आप आरेख को अपडेट किए बिना विचलन करते हैं, तो तकनीकी देनदारी तेजी से बढ़ती है।
योजना चरण में समय निवेश करने से रीफैक्टरिंग की आवश्यकता कम हो जाती है। यह सुनिश्चित करता है कि प्रणाली भविष्य के विकास को संभाल सकती है। एक स्केलेबल डिज़ाइन नए फीचर्स को बिना पूरी तरह से पुनर्निर्माण किए स्वीकार करता है।
डेटा आर्किटेक्चर पर अंतिम विचार 🏁
डेटाबेस डिज़ाइन करना तर्क और भविष्य की योजना का मिश्रण है। इसमें व्यापार क्षेत्र को गहराई से समझने की आवश्यकता होती है। एंटिटी रिलेशनशिप डायग्राम वह उपकरण है जो अमूल्य आवश्यकताओं और वास्तविक कोड के बीच के अंतर को पार करता है।
एकतत्वों, गुणों और संबंधों पर ध्यान केंद्रित करके, आप एक संरचना बनाते हैं जो सटीक और कुशल डेटा प्रबंधन का समर्थन करती है। नॉर्मलाइजेशन नियमों का पालन करने से अखंडता सुनिश्चित होती है, जबकि स्पष्ट कुंजियाँ संबंधों को बनाए रखती हैं।
याद रखें कि यह एक आवर्ती प्रक्रिया है। जैसे-जैसे आवश्यकताएं विकसित होती हैं, आरेख को उनके साथ विकसित होना चाहिए। शुरुआती डिज़ाइन के समान महत्वपूर्ण है कि दस्तावेज़ीकरण अद्यतन रहे। एक मजबूत आधार के साथ, आपके एप्लिकेशन विश्वसनीयता से काम करेंगे और प्रभावी ढंग से स्केल होंगे।
छोटे से शुरू करें, बड़े विचार करें, और अपने डेटा मॉडल में हमेशा स्पष्टता को प्राथमिकता दें। इस दृष्टिकोण से ऐसी टिकाऊ प्रणालियाँ बनती हैं जो समय की परीक्षा में खड़ी हो सकती हैं।