











डेटाबेस डिज़ाइन किसी भी विश्वसनीय सॉफ्टवेयर एप्लिकेशन की रीढ़ है। हालांकि, अनुभवी इंजीनियर भी दृश्य ब्लूप्रिंट्स और भौतिक कार्यान्वयन के बीच अंतर को समझाते समय अक्सर गलती कर देते हैं। भ्रम आमतौर पर एंटिटी-रिलेशनशिप डायग्राम (ERD) और डेटाबेस स्कीमा के बीच होता है। जबकि इन शब्दों का दैनिक बातचीत में अक्सर बदले-बदले उपयोग किया जाता है, लेकिन वे डेटा आर्किटेक्चर प्रक्रिया के अलग-अलग स्तरों का प्रतिनिधित्व करते हैं। इनके बीच अंतर को समझना केवल शैक्षणिक नहीं है; यह निर्धारित करता है कि डेटा कैसे प्रवाहित होता है, नियमों को कैसे लागू किया जाता है, और प्रणाली समय के साथ कैसे विकसित होती है।
इस गाइड में, हम डेटा मॉडलिंग के सैद्धांतिक निर्माणों को डेटाबेस मैनेजमेंट सिस्टम की व्यावहारिक वास्तविकताओं के खिलाफ विश्लेषण करेंगे। हम यह जांचेंगे कि अमूर्त अवधारणाएं कैसे भौतिक संरचनाओं में बदलती हैं, इस परिवर्तन के प्रभाव, और इन दोनों के बीच स्पष्ट मानसिक अंतर बनाए रखने के महत्व को जांचेंगे, जो लंबे समय तक बनाए रखने के लिए आवश्यक है। चाहे आप एक नई प्रणाली का डिज़ाइन कर रहे हों या मौजूदा प्रणाली को फिर से बनाने का प्रयास कर रहे हों, इस जगह स्पष्टता के कारण लागत वाले तकनीकी ऋण से बचा जा सकता है।
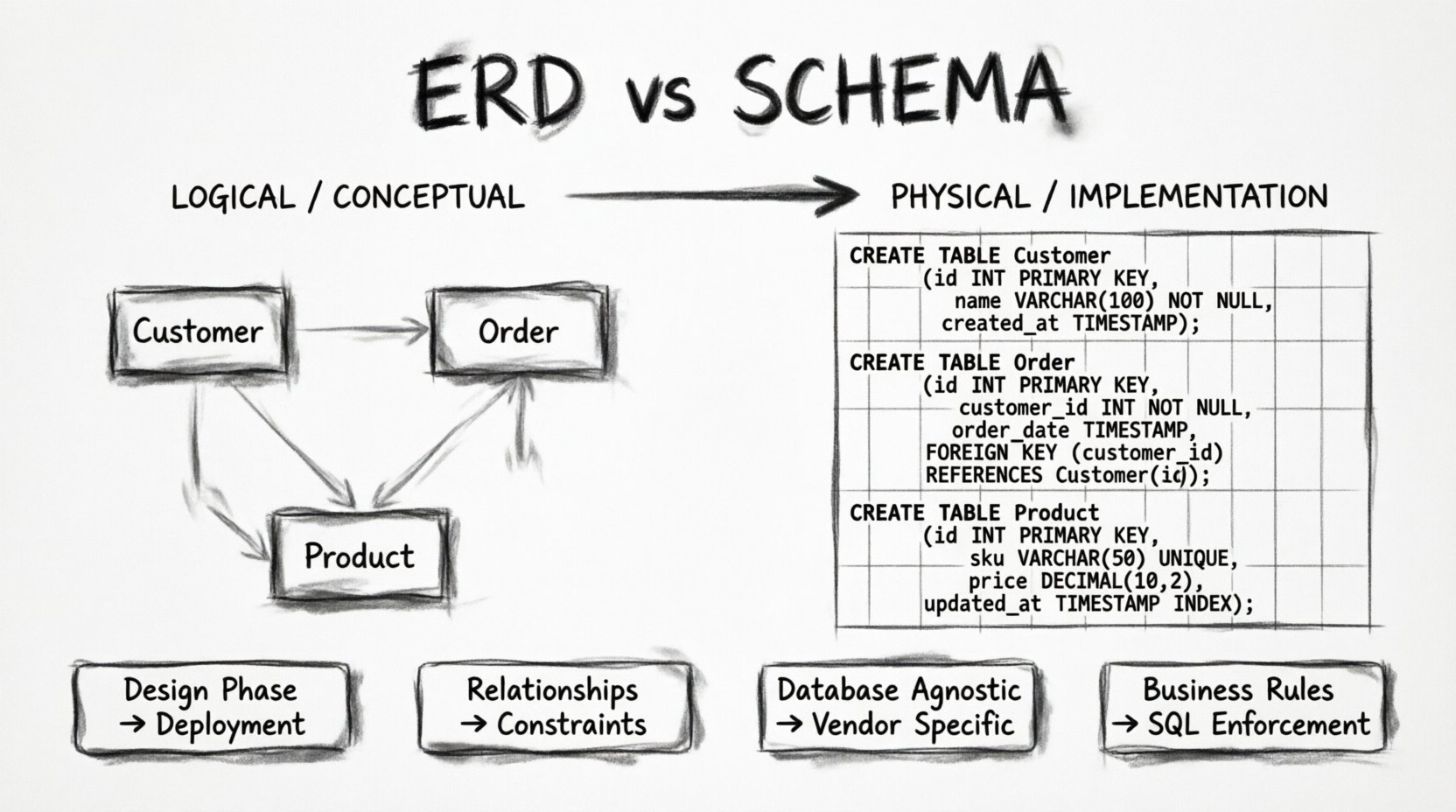
एक ERD वास्तव में क्या है? 📐
एंटिटी-रिलेशनशिप डायग्राम डेटा का एक संकल्पनात्मक या तार्किक प्रतिनिधित्व है। यह व्यावसायिक हितधारकों, विश्लेषकों और डेवलपर्स के बीच संचार का सेतु के रूप में कार्य करता है। इसका मुख्य उद्देश्य डेटा तत्वों के बीच कैसे संबंध हैं, इसका दृश्य रूप देना है, बिना किसी विशिष्ट डेटाबेस इंजन के विवरणों में फंसे रहे।
इसके केंद्र में, एक ERD तीन मूलभूत घटकों पर ध्यान केंद्रित करता है:
- एंटिटीज: ये वास्तविक दुनिया की वस्तुओं या अवधारणाओं का प्रतिनिधित्व करते हैं। एक रिटेल प्रणाली में, एक एंटिटी हो सकती हैग्राहक, उत्पाद, याआदेश। एंटिटीज आपके डेटा ब्रह्मांड के संज्ञाएं हैं।
- लक्षण: ये वे गुण या विशेषताएं हैं जो एक एंटिटी का वर्णन करती हैं। एक के लिएग्राहक, लक्षण में शामिल हो सकते हैंपहला नाम, ईमेल पता, यापंजीकरण तिथि। लक्षण यह निर्धारित करते हैं कि हमें एंटिटी के बारे में कौन सी डेटा स्टोर करने की आवश्यकता है।
- संबंध: यह यह निर्धारित करता है कि एंटिटीज कैसे बातचीत करती हैं। क्या एक ग्राहक बहुत सारे आदेश देता है? क्या एक उत्पाद कई श्रेणियों में से एक का हिस्सा है? संबंध नामों को जोड़ने वाले क्रियापद हैं।
एक ERD की सुंदरता इसकी अमूर्तता में है। यह नहीं चाहता कि डेटा अंततः PostgreSQL, MySQL या एक NoSQL दस्तावेज़ स्टोर में रहेगा। यह जानकारी की अखंडता और तार्किक प्रवाह के बारे में चिंतित है। नोटेशन शैलियां भिन्न होती हैं, जिसमें क्राउ के फुट नोटेशन एक सामान्य मानक है जो कार्डिनैलिटी (एक-एक, एक-बहुत, बहुत-बहुत) को दर्शाने के लिए उपयोग किया जाता है। इस दृश्य भाषा के कारण टीमें एक भी कोड लाइन लिखे बिना ही डेटा मॉडल की तार्किकता की पुष्टि कर सकती हैं।
ERD बनाते समय, नॉर्मलाइजेशन पर ध्यान केंद्रित किया जाता है। इसमें डेटा को अतिरिक्त दोहराव को कम करने और डेटा अखंडता को बेहतर बनाने के लिए व्यवस्थित करना शामिल है। हम यह देखते हैं कि बड़ी टेबलों को छोटी, संबंधित टेबलों में तोड़ने का तरीका क्या है, ताकि एक जगह जानकारी के अपडेट करने पर वह जहां भी महत्वपूर्ण है, वहां भी अपडेट हो जाए। ERD क्षेत्र का नक्शा है; यह सड़कों और स्थानों को दिखाता है, लेकिन विशिष्ट सड़क के सामग्री को नहीं दिखाता।
डेटाबेस स्कीमा को परिभाषित करना 🏗️
अगर ERD नक्शा है, तो स्कीमा वास्तविक क्षेत्र है। डेटाबेस स्कीमा डेटाबेस की भौतिक संरचना है। यह डेटाबेस मैनेजमेंट सिस्टम (DBMS) को डेटा को कैसे स्टोर करना है, इसके बारे में बिल्कुल स्पष्ट निर्देश देने वाला एक निश्चित सेट है। जबकि ERD अवधारणाओं में बोलता है, स्कीमा डेटा प्रकारों, सीमाओं और स्टोरेज इंजनों में बोलता है।
एक स्कीमा निम्नलिखित तकनीकी विशिष्टताओं को परिभाषित करता है:
- तालिकाएँ: एरडी का संस्था एक भौतिक तालिका बन जाता है। स्कीमा तालिका के नाम को निर्दिष्ट करता है, जिसे अक्सर सख्त नामकरण नियमों (उदाहरण के लिए, स्नेक_केस) का पालन करना होता है।
- डेटा प्रकार: एक गुणवत्ता जैसे उम्र एक बन जाता है
इंटयास्मॉलइंट. एक ईमेल एक बन जाता हैवर्चारजिसकी विशिष्ट लंबाई सीमा होती है। एक टाइमस्टैम्प बन जाता हैटाइमस्टैम्प विथ टाइम ज़ोन. इन चयनों का भंडारण स्थान और प्रश्न प्रदर्शन पर प्रभाव पड़ता है। - सीमाएँ: यहीं एरडी की तर्कवादितता को लागू किया जाता है। प्राथमिक कुंजियाँ (पीके) अद्वितीयता सुनिश्चित करती हैं। परावर्ती कुंजियाँ (एफके) तालिकाओं के बीच संदर्भात्मक अखंडता को सुनिश्चित करती हैं।
नॉट नलसीमाएँ सुनिश्चित करती हैं कि अनिवार्य फील्ड्स भरे जाएँ। अद्वितीय सीमाएँ डुप्लीकेट प्रविष्टियों को रोकती हैं। - इंडेक्सेज: जबकि अक्सर उच्च स्तरीय एरडी में छोड़ दिए जाते हैं, स्कीमा यह तय करती है कि इंडेक्स कहाँ बनाए जाएँ। इंडेक्स पढ़ने के संचालन को तेज करते हैं लेकिन लेखन को धीमा करते हैं। स्कीमा डेटाबेस के भौतिक अनुकूलन को निर्धारित करती है।
स्कीमा सुरक्षा और पहुँच नियंत्रण के लिए भी जिम्मेदार है। यह तय करती है कि कौन विशिष्ट तालिकाओं में पढ़ सकता है या लिख सकता है। यह लेनदेन का प्रबंधन करती है, यह सुनिश्चित करती है कि डेटा में परिवर्तन परमाणु हों। जब कोई विकासकर्ता एक लिखता है क्रिएट टेबल विवरण, वे स्कीमा को परिभाषित कर रहे होते हैं। यह वह कार्यान्वयन परत है जिसके साथ एप्लिकेशन कोड सीधे बातचीत करता है।
एक नज़र में मुख्य अंतर 📊
अंतर को स्पष्ट करने के लिए, अंतरों को एक साथ देखना उपयोगी होता है। एरडी सारांश और डिज़ाइन-केंद्रित है, जबकि स्कीमा वास्तविक और कार्यान्वयन-केंद्रित है।
| सुविधा | ERD (एंटिटी-रिलेशनशिप डायग्राम) | डेटाबेस स्कीमा |
|---|---|---|
| प्रकृति | तार्किक / अवधारणात्मक मॉडल | भौतिक मॉडल |
| फोकस | संबंध और डेटा प्रवाह | स्टोरेज और लागू करना |
| प्रतीक प्रणाली | बॉक्स, रेखाएँ, क्राउज़ फुट प्रतीक | SQL बयान, DDL स्क्रिप्ट्स |
| निर्भरता | डेटाबेस अनन्य | डेटाबेस विशिष्ट (आपूर्तिकर्ता) |
| सीमाएँ | अनुमानित (व्यापार नियम) | स्पष्ट (PK, FK, चेक) |
| चरण | डिज़ाइन चरण | विकास / डेप्लॉयमेंट चरण |
यह तालिका इस बात पर जोर देती है कि जब तक वे जुड़े हुए हैं, वे सॉफ्टवेयर जीवनचक्र के अलग-अलग चरणों पर काम करते हैं। दोनों को गलती से मिलाने से अक्सर डेवलपर्स तार्किक मॉडल पर भौतिक सीमाओं को लागू करने की कोशिश करते हैं, जब तक कि वह पूरी तरह से मान्य नहीं हो जाता।
अनुवाद प्रक्रिया: डायग्राम से कोड तक 🔄
ERD से स्कीमा तक का सफर हमेशा सीधा 1:1 मैपिंग नहीं होता है। यह अनुवाद परत वह जगह है जहाँ बहुत से प्रोजेक्ट्स को दुविधा का सामना करना पड़ता है। तार्किक मॉडल आदर्श स्थितियों को मानता है, लेकिन भौतिक मॉडल को प्रदर्शन, पुराने सिस्टम और विशिष्ट इंजन क्षमताओं के साथ निपटना होता है।
नॉर्मलाइजेशन बनाम प्रदर्शन
एक ERD आमतौर पर तृतीय सामान्य रूप (3NF) तक नॉर्मलाइज़ किया जाता है। इससे डेटा की दोहराव कम होता है। हालांकि, एक उच्च ट्रैफिक एप्लिकेशन के लिए स्कीमा में अनुवाद करते समय, डेवलपर्स अक्सर नॉर्मलाइज़ेशन को छोड़ देते हैं। इसका मतलब है कि जानबूझकर डेटा की दोहराव करना ताकि क्वेरी के दौरान जॉइन की आवश्यकता कम हो। उदाहरण के लिए, ग्राहक नाम सीधे आदेश टेबल पर स्टोर करना, भले ही यह सख्त नॉर्मलाइज़ेशन नियमों के विरुद्ध हो, रिपोर्टिंग क्वेरी को काफी तेज कर सकता है। ERD में संबंध दिखाया जा सकता है, लेकिन स्कीमा डेटा को तेजी से प्राप्त करने के लिए बार-बार स्टोर कर सकता है।
डेटा प्रकार विशेषताएँ
एक एरडी सिर्फ कहता है कि एक फ़ील्ड एक हैतारीख. स्कीमा को बीच फैसला करना होगातारीख, तारीख_समय, यासमय_सामयिक_चिह्न. इसे अक्षर सेट (यूटीएफ8, एससीआईआई) और कॉलेशन नियमों का फैसला करना होगा। इन निर्णयों का एप्लिकेशन द्वारा अंतर्राष्ट्रीयकरण और व्यवस्था के तरीके पर प्रभाव पड़ता है। एक सामान्य एरडी इन बातों को नहीं दर्शा सकता है।
बहु-से-बहु संबंधों का प्रबंधन
एक एरडी में, बहु-से-बहु संबंध को डबल क्राउज़ फुट वाली रेखा के रूप में बनाया जाता है। भौतिक स्कीमा में इसका सीधे अस्तित्व नहीं हो सकता। इसे एक जंक्शन टेबल (या ब्रिज टेबल) के माध्यम से दो एक-से-बहु संबंधों में बदलना होगा। स्कीमा को इस जंक्शन टेबल के प्राथमिक कुंजी को परिभाषित करना होगा, जो एक संयुक्त कुंजी या एक सुरोगेट कुंजी (यूयूआईडी) हो सकती है। यह संरचनात्मक परिवर्तन उच्च स्तर के आरेख में अदृश्य है लेकिन डेटाबेस संरचना में महत्वपूर्ण है।
विकासकर्मियों के लिए अंतर क्यों महत्वपूर्ण है 🛠️
इन दो अवधारणाओं के बीच के अंतर को समझना केवल सिद्धांत के बारे में नहीं है; यह दैनिक कार्य पर प्रभाव डालता है। जब डेटा अखंडता में कोई बग आता है, तो यह जानना कि समस्या तार्किक डिज़ाइन में है या भौतिक कार्यान्वयन में, समाधान की पहली कदम है।
डेटा अखंडता का निराकरण
अगर आपको ऐसी स्थिति का सामना करना पड़े जहाँ डेटा अप्रत्याशित रूप से दोहराया जा रहा हो, तो आपको पूछना चाहिए: क्या एरडी दोषपूर्ण है, या स्कीमा सीमा गायब है? स्कीमा में गायब विदेशी कुंजी अनाथ रिकॉर्ड की अनुमति देती है जिनके बारे में एरडी तर्क ने मान लिया था कि वे असंभव हैं। विपरीत रूप से, अगर एरडी बहुत कठोर है और सॉफ्ट-डिलीट को ध्यान में नहीं रखती है, तो स्कीमा कठोर डिलीट को लागू कर सकती है जो व्यापार तर्क को तोड़ देती है। चिंताओं को अलग करने से आप त्रुटि के स्रोत को सटीक रूप से पहचान सकते हैं।
संस्करण नियंत्रण और सहयोग
जब डेटाबेस का प्रबंधन किया जाता है, तो संस्करण नियंत्रण अनिवार्य है। हालांकि, एरडी और स्कीमा अलग-अलग तरीके से विकसित होते हैं। एरडी तब बदलती है जब व्यापार आवश्यकताएँ बदलती हैं। स्कीमा तब बदलती है जब डेटाबेस को अनुकूलित करने की आवश्यकता होती है या जब माइग्रेशन लागू की जाती है। इन्हें समन्वित रखना एक चुनौती है। अगर स्कीमा बदलती है लेकिन एरडी को अपडेट नहीं किया जाता है, तो दस्तावेज़ीकरण प्रामाणिक नहीं रहता है। अगर एरडी बदलती है लेकिन माइग्रेशन स्क्रिप्ट नहीं होती है, तो डेटाबेस डिज़ाइन के साथ असंगत रहता है।
नए टीम सदस्यों का स्वागत
नए विकासकर्मी अक्सर डेटाबेस संरचना को समझने में कठिनाई महसूस करते हैं। उन्हें एरडी दिखाने से यह समझ में आता है कि सिस्टम अवधारणात्मक रूप से कैसे काम करता है। उन्हें स्कीमा दिखाने से यह समझ में आता है कि सिस्टम तकनीकी रूप से कैसे काम करता है। प्रभावी ओनबोर्डिंग के लिए दोनों की आवश्यकता होती है। एरडी उत्तर देती है“इसका क्या अर्थ है?” और स्कीमा उत्तर देती है“मैं इसे कैसे प्राप्त कर सकता हूँ?”.
डेटा मॉडलिंग में सामान्य त्रुटियाँ 🚧
स्पष्ट परिभाषाओं के बावजूद, बहुत सी टीमें एरडी और स्कीमा को समान मानने पर त्रुटियों में फंस जाती हैं।
- एरडी को छोड़ना:सीधे SQL स्कीमा स्क्रिप्ट लिखने की ओर बढ़ने से अक्सर संरचनात्मक देनदारी बढ़ती है। दृश्य मॉडल के बिना, संबंध अक्सर भूल जाते हैं या असंगत ढंग से लागू किए जाते हैं।
- सीमाओं को नजरअंदाज करना:नियमों (जैसे यूनिक ईमेल) को लागू करने के लिए केवल एप्लिकेशन कोड पर भरोसा करना बजाय डेटाबेस सीमाओं (यूनिक इंडेक्स) पर जोखिम भरा है। स्कीमा डेटा अखंडता के लिए अंतिम रक्षा रेखा होनी चाहिए।
- अतिरिक्त डिज़ाइन: आवश्यकताएं स्पष्ट होने से पहले ही प्रत्येक संभावित लक्षण के साथ बहुत विस्तृत एक एरडी बनाना। इससे एक ऐसा स्कीमा बनता है जिसे बाद में माइग्रेट करना मुश्किल हो जाता है।
- उपकरण का अलगाव: कोड जनरेशन का समर्थन न करने वाले डिज़ाइन टूल का उपयोग करना, या रिवर्स इंजीनियरिंग का समर्थन न करने वाले डेटाबेस टूल का उपयोग करना। इससे एक मैन्युअल अंतर बनता है जहां बदलाव एक जगह किए जाते हैं लेकिन दूसरी जगह नहीं।
- समानता मानना: यह मानना कि एक आदर्श एरडी एक आदर्श डेटाबेस की गारंटी देता है। स्कीमा हार्डवेयर सीमाओं, प्रश्न पैटर्न और समानांतरता समस्याओं के कारण बदल सकता है जिन्हें एरडी भविष्यवाणी नहीं कर सकता।
समय के साथ समन्वय बनाए रखना 🔄
जैसे-जैसे एप्लिकेशन बढ़ता है, डेटाबेस विकसित होता है। फीचर्स जोड़े जाते हैं, और पुराने फीचर्स को बंद कर दिया जाता है। एरडी और स्कीमा के बीच संबंध बनाए रखना समय के साथ मुश्किल हो जाता है। इसे अक्सर कहा जाता हैस्कीमा विचलन.
इसके विरुद्ध लड़ने के लिए, टीमों को एक कठोर व्यवस्था अपनानी चाहिए:
- पहले डिज़ाइन करें: माइग्रेशन स्क्रिप्ट्स लिखने से पहले हमेशा एरडी को अपडेट करें।
- जनरेशन को स्वचालित करें: एरडी से SQL DDL जनरेट करने वाले टूल्स का उपयोग करें। इससे यह सुनिश्चित होता है कि स्कीमा डिज़ाइन के अनुरूप हो।
- रिवर्स इंजीनियरिंग: लाइव डेटाबेस पर नियमित रूप से रिवर्स इंजीनियरिंग टूल्स चलाएं ताकि एरडी को अपडेट किया जा सके। इससे वे बदलाव पकड़े जाते हैं जो डिज़ाइन प्रक्रिया को बायपास करके सीधे SQL प्रश्नों द्वारा किए जाते हैं।
- दस्तावेज़ीकरण: सुनिश्चित करें कि एरडी को स्कीमा माइग्रेशन स्क्रिप्ट्स के साथ ही एक ही रिपोजिटरी में स्टोर किया जाए। इससे एकमात्र सच्चाई का स्रोत बनता है।
इस अनुशासन से डेटाबेस के एक काले बॉक्स में बदलने से रोका जाता है। जब एरडी और स्कीमा सिंक में होते हैं, तो सिस्टम स्पष्ट और प्रबंधनीय बना रहता है।
प्रश्न प्रदर्शन और अनुकूलन पर प्रभाव ⚡
स्कीमा एरडी की तुलना में प्रदर्शन को अधिक निर्धारित करता है। जबकि एरडी संबंधों को दिखाता है, स्कीमा निर्धारित करता है कि डेटाबेस इंजन डेटा तक कैसे पहुंचता है। एरडी में शायद उपयोगकर्ताओं और पोस्ट्स के बीच एक तार्किक जॉइन दिखाया गया हो।उपयोगकर्ता और पोस्ट्स। स्कीमा तय करता है कि क्या एक इंडेक्स मौजूद है उपयोगकर्ता_आईडी में पोस्ट्स टेबल में।
स्कीमा में उचित इंडेक्सिंग के बिना, एक सरल प्रश्न एक पूर्ण टेबल स्कैन को ट्रिगर कर सकता है। यह एक भौतिक सीमा है। ईआरडी आपको निष्पादन योजना नहीं दिखा सकता है। डेवलपर्स को स्कीमा को देखकर समझना होगा कि क्यों एक प्रश्न धीमा है। उन्हें इंडेक्स, पार्टीशनिंग रणनीति और डेटा प्रकारों का विश्लेषण करना होगा।
इसके अलावा, स्कीमा लॉकिंग तंत्र को हैंडल करता है। यदि कई उपयोगकर्ता एक ही रिकॉर्ड को अपडेट करते हैं, तो स्कीमा के आइसोलेशन स्तर और लॉकिंग रणनीति निर्धारित करती है कि क्या वे एक दूसरे को ब्लॉक करते हैं। ईआरडी कॉन्करेंसी पर चुप है। यह उच्च लोड वाले सिस्टम के लिए एक महत्वपूर्ण अंतर है।
बेस्ट प्रैक्टिसेज के साथ अंतराल को पार करना 🏆
दोनों मॉडलों के उद्देश्य को प्रभावी ढंग से पूरा करने के लिए, इन मानकों को अपनाने की सोचें:
- मानक नामकरण पद्धति का उपयोग करें: सुनिश्चित करें कि स्कीमा में टेबल के नाम ईआरडी में एंटिटी के नाम के अनुरूप हों। सुसंगतता मनोवैज्ञानिक भार को कम करती है।
- प्रत्यक्ष रूप से सीमाओं का दस्तावेजीकरण करें: ईआरडी में, कार्डिनैलिटी के साथ संबंधों को टिप्पणी करें। स्कीमा में, कॉलम को उनकी सीमाओं के साथ टिप्पणी करें। दोनों स्थानों पर नियमों को स्पष्ट रूप से दिखाएं।
- नियमित रूप से समीक्षा करें: उत्पादन स्कीमा के खिलाफ ईआरडी की तिमाही समीक्षा योजना बनाएं। विचलन और असामान्यताओं की तलाश करें।
- चिंताओं को अलग करें: ईआरडी को एक व्यावसायिक सामग्री और स्कीमा को एक तकनीकी सामग्री के रूप में लें। व्यावसायिक तर्क को भौतिक स्कीमा परिभाषाओं में मिलाएं नहीं।
- माइग्रेशन की योजना बनाएं: जब ईआरडी बदलती है, तो स्कीमा को माइग्रेशन स्क्रिप्ट के माध्यम से बदलना होगा। कभी भी वर्जन युक्त स्क्रिप्ट के बिना उत्पादन में स्कीमा को सीधे बदलें नहीं।
डेटा मॉडलिंग का मानवीय पहलू 👥
अंततः, ये मॉडल लोगों के लिए बनाए जाते हैं, केवल मशीनों के लिए नहीं। ईआरडी संचार के लिए है। इससे उत्पाद प्रबंधक को एसक्यूएल जाने बिना डेटा संरचना को समझने में सक्षम बनाता है। स्कीमा मशीन के लिए है। यह एप्लिकेशन को डेटा को कुशलता से प्राप्त करने में सक्षम बनाता है।
जब डेवलपर्स इस मानव-मशीन विभाजन को समझते हैं, तो वे बेहतर प्रणालियां डिज़ाइन कर सकते हैं। वे जानते हैं कि जब स्टेकहोल्डर्स के लिए ईआरडी को सरल बनाना है और जब डेटाबेस इंजन के लिए स्कीमा को विस्तार से बनाना है। यह द्वैत डेटाबेस आर्किटेक्चर की आत्मा है।
तार्किक आरेख और भौतिक कार्यान्वयन के बीच सीमा का सम्मान करके, टीमें डेटा क्षति और प्रदर्शन के बॉटलनेक के सामान्य जाल में नहीं फंसती हैं। ईआरडी दृष्टि प्रदान करता है; स्कीमा वास्तविकता प्रदान करता है। एक सफल प्रणाली के लिए दोनों की आवश्यकता होती है।
डेटा आर्किटेक्चर पर अंतिम विचार 🧠
एक एंटिटी-रिलेशनशिप डायग्राम और डेटाबेस स्कीमा के बीच अंतर सॉफ्टवेयर इंजीनियरिंग का एक मूल आधार है। यह विचार से क्रिया में, विचार से कार्यान्वयन में संक्रमण का प्रतिनिधित्व करता है। जबकि ईआरडी व्यावसाय को चलाने वाले संबंधों और तर्क को दर्ज करता है, स्कीमा एप्लिकेशन को चलाने वाली सीमाओं और संरचनाओं को दर्ज करता है।
इन दो मॉडलों के बीच संबंध को समझना नियमों को याद रखने के बारे में नहीं है। यह डेटा के जीवनचक्र को समझने के बारे में है। यह जानने के बारे में है कि डायग्राम में बदलाव को कोड में बदलाव की आवश्यकता होती है, और कोड में बदलाव को डायग्राम में दोहराना होता है। इस चक्र से यह सुनिश्चित होता है कि प्रणाली संगत, विश्वसनीय और स्केलेबल बनी रहे।
जैसे आप अपने विकास यात्रा में आगे बढ़ते हैं, इन दो मॉडलों को अलग रखें। ईआरडी का उपयोग योजना बनाने और संचार के लिए करें। स्कीमा का उपयोग निर्माण और लागू करने के लिए करें। जब आप इन्हें एक साथ लाते हैं, तो आप ऐसी प्रणालियां बनाते हैं जो समय और बदलाव की परीक्षा में खड़ी हो सकती हैं।
याद रखें, लक्ष्य केवल डेटा को स्टोर करना नहीं है, बल्कि उसे एक ऐसे तरीके से स्टोर करना है जो समझ में आए। यह समझ ईआरडी की तार्किक स्पष्टता और स्कीमा की संरचनात्मक कठोरता से आती है। एक साथ, वे आपकी डेटा आर्किटेक्चर की नींव बनाते हैं।