










बैकएंड इंजीनियरिंग की जटिल दुनिया में, डेटा एप्लिकेशन के निर्माण के आधार के रूप में है। उस डेटा को संशोधित करने के लिए कोड लिखना एक मुख्य जिम्मेदारी है, लेकिन डेटा की संरचना को समझना भी उतना ही महत्वपूर्ण है। एंटिटी रिलेशनशिप डायग्राम (ईआरडी) इस संरचना के लिए ब्लूप्रिंट के रूप में कार्य करता है। यह विजुअल भाषा है जो जानकारी को कैसे संग्रहीत, जोड़ा और प्राप्त किया जाता है, इसके बारे में संचार करती है। बैकएंड डेवलपर के लिए, ईआरडी को आसानी से पढ़ने की क्षमता केवल एक अच्छी बात नहीं है; यह लचीले, स्केलेबल और बनाए रखने योग्य प्रणालियों के डिज़ाइन के लिए एक मूलभूत आवश्यकता है।
बहुत से डेवलपर्स स्कीमा की संरचना को पूरी तरह समझे बिना ही क्वेरी लिखने में कूद पड़ते हैं। इससे अक्सर प्रदर्शन के बॉटलनेक, डेटा अखंडता के मुद्दे और बाद में कठिन रिफैक्टरिंग कार्य होते हैं। ईआरडी के अर्थ को समझने के कला को सीखकर, आप यह भविष्यवाणी करने की क्षमता प्राप्त करते हैं कि डेटा आपके एप्लिकेशन में कैसे बहता है और एक क्षेत्र में बदलाव पूरे डेटाबेस में कैसे फैल सकता है। यह गाइड ईआरडी को पढ़ने के तकनीकी पहलुओं में गहराई से जाने के लिए है, जो सैद्धांतिक बातों के बजाय व्यावहारिक अनुप्रयोग पर ध्यान केंद्रित करता है।
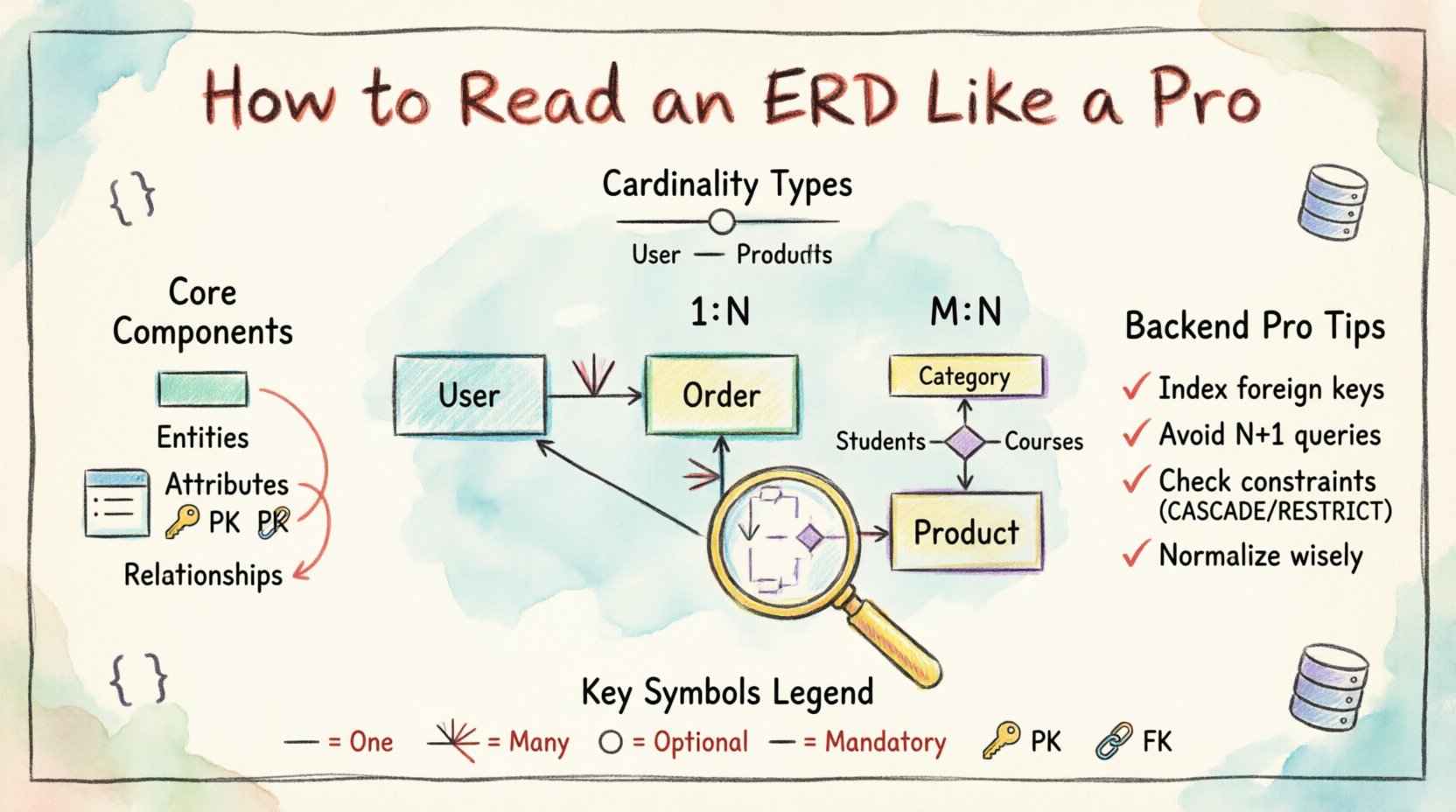
ईआरडी के मुख्य घटकों को समझना 🧱
जोड़ाव को नेविगेट करने से पहले, आपको आरेख के बनने वाले व्यक्तिगत प्रतीकों को समझना होगा। ईआरडी कई अलग-अलग तत्वों से बना होता है, जिनमें से प्रत्येक डेटा मॉडल के एक विशिष्ट पहलू का प्रतिनिधित्व करता है। इन तत्वों को तुरंत पहचानने से आप जटिल स्कीमा को समझने में सक्षम होते हैं बिना लाइनों में खो जाने के।
1. एंटिटी (टेबल)
ईआरडी की सबसे उल्लेखनीय विशेषता एंटिटी है। संबंधात्मक डेटाबेस के संदर्भ में, एंटिटी सीधे एक टेबल के संगत होती है। यह एक विशिष्ट वस्तु या अवधारणा का प्रतिनिधित्व करती है जिसके बारे में डेटा संग्रहीत किया जाता है। जब आप एक आयताकार आकृति देखते हैं जिस पर नाम जैसे ग्राहक या आदेशलेबल किया गया है, तो आप एक टेबल को देख रहे हैं।
- दृश्य संकेत:आमतौर पर एक आयताकार आकृति या नाम वाला बॉक्स।
- कार्य:संबंधित डेटा विशेषताओं को एक साथ जोड़ता है।
- बैकएंड प्रभाव:हर एंटिटी आमतौर पर आपके कोडबेस में एक क्लास या मॉडल के संगत होती है।
एंटिटी को पढ़ते समय अंदर के टेक्स्ट पर ध्यान दें। कभी-कभी यह विशेषताओं (कॉलम) को स्पष्ट रूप से सूचीबद्ध करता है। दूसरी बार, यह एक सारांश प्रतिनिधित्व होता है जहां विवरण अलग दस्तावेज़ में संग्रहीत होते हैं। दोनों मामलों में, एंटिटी का नाम आपको आपकी प्रणाली के संज्ञा के बारे में बताता है।
2. विशेषताएं (कॉलम)
विशेषताएं एंटिटी के गुणों को परिभाषित करती हैं। यदि एंटिटी एक टेबल है, तो विशेषताएं उस टेबल के अंदर कॉलम होती हैं। वे प्रत्येक रिकॉर्ड के लिए आवश्यक विशिष्ट डेटा बिंदुओं का वर्णन करती हैं।
- प्राथमिक कुंजी:आमतौर पर नीचे लाइन या की आइकन के साथ चिह्नित किया जाता है। यह हर पंक्ति को अद्वितीय रूप से पहचानता है।
- विदेशी कुंजी:आमतौर पर दूसरी एंटिटी से जुड़ी लाइन द्वारा चिह्नित किया जाता है। यह संबंध स्थापित करता है।
- डेटा प्रकार:जबकि दृश्य रूप से हमेशा नहीं दिखाया जाता है, अनुभवी पाठक संदर्भ के आधार पर डेटा प्रकार का अनुमान लगाता है (उदाहरण के लिए, एक फील्ड जिसका नाम ईमेल पताएक स्ट्रिंग को इंगित करता है, बनाया गया हैएक समयचिह्न को इंगित करता है)।
अतिरिक्त को समझना प्रभावी प्रश्न लिखने के लिए महत्वपूर्ण है। यदि कोई अतिरिक्त सूचीबद्ध नहीं है, तो उसकी खोज करने से पूरी तालिका का स्कैन होगा। यदि यह एक विदेशी कुंजी है, तो यह जॉइन संचालन को निर्धारित करती है।
3. संबंध (रेखाएँ)
संबंध यह निर्धारित करते हैं कि संस्थाएँ एक दूसरे के साथ कैसे बातचीत करती हैं। ये रेखाएँ दो संस्थाओं को जोड़ती हैं और कार्डिनैलिटी (कितने) का वर्णन करती हैं। बैकएंड तर्क के लिए ERD को पढ़ने के लिए यह सबसे महत्वपूर्ण हिस्सा है, क्योंकि यह निर्धारित करता है कि डेटा तालिकाओं के बीच कैसे जुड़ा है।
- दिशा:रेखाएँ अक्सर दिशात्मकता दिखाने के लिए अंत में तीर या प्रतीकों के साथ होती हैं।
- कार्डिनैलिटी:यह निर्धारित करता है कि संबंध एक-एक, एक-बहुत-से या बहुत-से-बहुत-से है या नहीं।
- वैकल्पिकता:कभी-कभी ठोस रेखाओं बनाम बिंदीदार रेखाओं द्वारा दर्शाया जाता है, जो यह दिखाता है कि कोई संबंध अनिवार्य है या वैकल्पिक है।
कार्डिनैलिटी और संबंधों को समझना 🔗
कार्डिनैलिटी ERD का दिल है। यह आपके डेटाबेस संबंधों के नियम और तर्क को निर्धारित करती है। कार्डिनैलिटी के गलत विश्लेषण से डेटा की दोहराव या अनाथ रिकॉर्ड हो सकते हैं। आइए तीन मुख्य प्रकार के संबंधों को समझें जिन्हें आपको सामना करना होगा।
1. एक-एक (1:1)
यह संबंध तब मौजूद होता है जब तालिका A में एक एकल रिकॉर्ड तालिका B में ठीक एक रिकॉर्ड से जुड़ा होता है, और इसके विपरीत भी।
- उपयोग का मामला:सुरक्षा या प्रदर्शन के लिए बड़ी तालिकाओं को विभाजित करना। उदाहरण के लिए, एक उपयोगकर्ता प्रोफ़ाइल को एक उपयोगकर्ता_सेटिंग्स तालिका से अलग किया जा सकता है।
- कार्यान्वयन:एक तालिका में विदेशी कुंजी दूसरी तालिका में मुख्य कुंजी को संदर्भित करती है, जिसमें अक्सर एक अद्वितीय सीमा होती है।
- बैकएंड प्रभाव:पूर्ण डेटा प्राप्त करने के लिए जॉइन आमतौर पर आवश्यक होते हैं, लेकिन तर्क सरल होता है।
2. एक-बहुत-से (1:N)
यह संबंध संबंधात्मक डेटाबेस में सबसे आम है। तालिका A में एक रिकॉर्ड तालिका B में एक से अधिक रिकॉर्ड से जुड़ सकता है, लेकिन तालिका B में प्रत्येक रिकॉर्ड केवल तालिका A में एक रिकॉर्ड से जुड़ा होता है।
- उपयोग का मामला:एक श्रेणीमें एक से अधिक उत्पादों.
- कार्यान्वयन: विदेशी कुंजी “बहुतायत” वाली तालिका (उत्पादन) में स्थित होती है, जो “एक” वाली तरफ (श्रेणी) को संदर्भित करती है।
- बैकएंड प्रभाव: जब आप एक श्रेणी को प्राप्त करते हैं, तो आप अक्सर उत्पादों की सूची लोड करते हैं। जब आप एक उत्पाद को प्राप्त करते हैं, तो आप एकल श्रेणी लोड करते हैं।
3. बहु-से-बहु (M:N)
यह संबंध तब होता है जब तालिका A में रिकॉर्ड तालिका B में एक से अधिक रिकॉर्ड से जुड़ सकते हैं, और तालिका B में रिकॉर्ड तालिका A में एक से अधिक रिकॉर्ड से जुड़ सकते हैं।
- उपयोग के मामले: छात्र बहुत से कक्षाओं में दाखिला लेते हैं, और कक्षाओं में बहुत से छात्र होते हैं।
- कार्यान्वयन: इसे एकल विदेशी कुंजी द्वारा सीधे प्रतिनिधित्व नहीं किया जा सकता है। इस संबंध को दो एक-से-बहु संबंधों में बदलने के लिए एक संयोजन तालिका (या ब्रिज तालिका) की आवश्यकता होती है।
- बैकएंड प्रभाव: प्रश्न अक्सर तीन तालिकाओं को शामिल करते हैं। आपको अपने कोड में संयोजन तालिका को स्पष्ट रूप से संभालना होगा ताकि संबंधों का प्रबंधन किया जा सके।
तालिका: संबंध गणना सारांश
| संबंध प्रकार | उदाहरण परिदृश्य | कार्यान्वयन रणनीति | प्रश्न जटिलता |
|---|---|---|---|
| एक-से-एक (1:1) | उपयोगकर्ता और प्रोफ़ाइल | एकल विदेशी कुंजी | कम (एकल जॉइन) |
| एक-से-बहु (1:N) | लेखक और पुस्तकें | बहुतायत वाली तरफ विदेशी कुंजी | मध्यम (सूची जॉइन) |
| बहु-से-बहु (M:N) | छात्र और कोर्स | संयोजन तालिका | उच्च (तीन तालिका जॉइन) |
नोटेशन शैलियाँ और प्रतीक 📐
जब तक अवधारणाएँ संगत रहती हैं, दृश्य नोटेशन डायग्राम के डिज़ाइनर के आधार पर बदल सकती है। सामान्य शैलियों के प्रति परिचय आपको सूक्ष्म विवरणों को न छोड़ने देगा।
क्राउ के पैर नोटेशन
यह आधुनिक डेटाबेस डिज़ाइन टूल्स में व्यापक रूप से उपयोग किया जाता है। यह संबंध रेखा के अंत में विशिष्ट प्रतीकों का उपयोग करके कार्डिनैलिटी को दर्शाता है।
- एकल रेखा: “एक” का प्रतिनिधित्व करता है।
- क्राउ के पैर (तीन शाखाएँ): “बहुत सारे” का प्रतिनिधित्व करता है।
- वृत्त: “वैकल्पिक” (शून्य) का प्रतिनिधित्व करता है।
- उर्ध्वाधर छड़: “अनिवार्य” (एक) का प्रतिनिधित्व करता है।
उदाहरण के लिए, एक रेखा जिसके एक तरफ एक छड़ और दूसरी तरफ क्राउ के पैर हो, एक एक से बहुत के संबंध को दर्शाती है जहाँ “एक” तरफ अनिवार्य है।
चेन नोटेशन
एप्लीकेशन विकास में कम प्रचलित है, लेकिन शैक्षणिक या उच्च स्तरीय वास्तुकला के संदर्भ में आम है। इसमें रेखाओं के बजाय हीरे के आकार के प्रतीकों का उपयोग संबंधों का प्रतिनिधित्व करने के लिए किया जाता है।
- प्राधिकरण:आयत।
- संबंध:हीरे।
- गुण:अंडाकार।
जब चेन नोटेशन पढ़ते हैं, तो हीरे के आकार पर ध्यान केंद्रित करें। कार्डिनैलिटी लेबल (1, N, M) हीरे को प्राधिकरणों से जोड़ने वाली रेखाओं पर रखे जाते हैं।
कुंजियाँ और सीमाएँ: खेल के नियम 🔑
एक ईआरडी केवल संबंधों के बारे में नहीं है; यह नियमों के बारे में है। सीमाएँ डेटा अखंडता सुनिश्चित करती हैं। बैकएंड विकासकर्ता के रूप में, आपको यह जानना होगा कि डेटाबेस द्वारा कौन-सी सीमाएँ लागू की जाती हैं और कौन-सी एप्लीकेशन तर्क में संभाली जानी चाहिए।
प्राथमिक कुंजियाँ (पीके)
प्रत्येक तालिका में एक प्राथमिक कुंजी होनी चाहिए। यह मान प्रत्येक पंक्ति को अद्वितीय रूप से पहचानता है। ईआरडी पढ़ते समय, नीचे लाइन वाले गुण की तलाश करें।
- प्रतिस्थापन कुंजियाँ:स्वतः बढ़ते पूर्णांक (उदाहरण के लिए, आईडी) जिनका कोई व्यावसायिक अर्थ नहीं है।
- प्राकृतिक कुंजियाँ:व्यावसायिक पहचानकर्ता (उदाहरण के लिए, ईमेल, एसकेयू) जो प्राकृतिक रूप से अद्वितीय होते हैं।
इसका महत्व क्यों है: विदेशी कुंजियाँ मुख्य कुंजियों को संदर्भित करती हैं। यदि आप मुख्य कुंजी रणनीति बदलते हैं (उदाहरण के लिए, UUID बनाम पूर्णांक), तो आपको सभी निर्भर विदेशी कुंजियों को अपडेट करना होगा और संभवतः अपने एप्लिकेशन के कैशिंग लेयर के पुनर्गठन की आवश्यकता होगी।
विदेशी कुंजियाँ (FK)
एक विदेशी कुंजी एक तालिका में एक फ़ील्ड (या फ़ील्ड का संग्रह) है जो दूसरी तालिका में मुख्य कुंजी को संदर्भित करती है। यह संदर्भात्मक अखंडता को बनाए रखती है।
- ON DELETE CASCADE: यदि मुख्य रिकॉर्ड को हटा दिया जाता है, तो बच्चे के रिकॉर्ड स्वतः ही हटा दिए जाते हैं।
- ON DELETE RESTRICT: यदि बच्चे के रिकॉर्ड मौजूद हैं, तो मुख्य रिकॉर्ड के हटाने को रोकता है।
- ON DELETE SET NULL: यदि मुख्य रिकॉर्ड को हटा दिया जाता है, तो विदेशी कुंजी कॉलम को NULL कर देता है।
डिलीट एंडपॉइंट लिखते समय इन व्यवहारों को समझना महत्वपूर्ण है। यदि संबंध ग्राफ जटिल है, तो कैस्केड डिलीट के अनचाहे प्रभाव हो सकते हैं।
नॉर्मलाइज़ेशन और डेटा संरचना 🧹
जब एक एरडी का विश्लेषण करते हैं, तो आपको नॉर्मलाइज़ेशन के स्तर का भी मूल्यांकन करना चाहिए। नॉर्मलाइज़ेशन डेटा अतिरेक को कम करता है और अखंडता में सुधार करता है। हालांकि, यह प्रदर्शन के लिए हमेशा एक कठोर आवश्यकता नहीं है।
पहला सामान्य रूप (1NF)
सभी कॉलम में परमाणु मान होने चाहिए। एक कोष्ठक में सूचियाँ या ऐरे नहीं होनी चाहिए। यदि आपको एक कॉलम दिखाई दे जिसका नाम हैटैगमें समावेश है“टैग1, टैग2, टैग3”, तो स्कीमा 1NF का उल्लंघन करता है।
दूसरा सामान्य रूप (2NF)
1NF में होना चाहिए और सभी गैर-कुंजी विशेषताओं को मुख्य कुंजी पर पूरी तरह निर्भर होना चाहिए। इसमें अक्सर ऐसी विशेषताओं को अलग तालिका में स्थानांतरित करना शामिल होता है जो केवल संयुक्त कुंजी के केवल एक हिस्से पर निर्भर होती हैं।
तीसरा सामान्य रूप (3NF)
2NF में होना चाहिए और कोई अंतरित निर्भरता नहीं होनी चाहिए। यदिएनिर्धारित करता हैबी, औरबीनिर्धारित करता हैसी, फिर ए निर्धारित करता है सी. 3NF में, सी को उसी तालिका में नहीं होना चाहिए जैसे कि बी.
व्यवहार में अनियमितता
जबकि सामान्यीकरण सैद्धांतिक आदर्श है, बैकएंड विकास के लिए प्रदर्शन के लिए अनियमितता की आवश्यकता होती है। आप तेजी से डिज़ाइन किए गए एक एरडी में डुप्लीकेट डेटा देख सकते हैं।
- पढ़ना बनाम लिखना: सामान्यीकृत स्कीमा लिखने के लिए बेहतर हैं; अनियमित स्कीमा पढ़ने के लिए बेहतर हैं।
- कैशिंग: कभी-कभी डेटा को दोहराया जाता है ताकि उच्च ट्रैफिक एंडपॉइंट्स में जॉइन ऑपरेशन कम किया जा सके।
जब आप एक एरडी में अतिरिक्त डेटा देखते हैं, तो पूछें कि क्यों। क्या यह डिज़ाइन की कमी है, या एक जानबूझकर अनुकूलन रणनीति है?
बैकएंड अनुकूलन के लिए पढ़ना 🚀
एक एरडी को पढ़ना केवल डेटा स्टोरेज को समझने के बारे में नहीं है; यह प्रदर्शन की अपेक्षा करने के बारे में है। एक अच्छी तरह से पढ़ी गई स्कीमा आपको ऐसे क्वेरी लिखने में सक्षम बनाती है जो इंडेक्स का प्रभावी रूप से उपयोग करती हैं।
इंडेक्सिंग के अवसरों की पहचान करना
विशेषताओं की तलाश करें जो खोज फ़िल्टर या क्रमबद्ध ऑपरेशन में अक्सर उपयोग किए जाते हैं। इन्हें इंडेक्स किया जाना चाहिए।
- खोज कॉलम: वे विशेषताएं जो वहां क्लॉज में उपयोग की जाती हैं।
- जॉइन कॉलम: विदेशी कुंजियों को लगभग हमेशा इंडेक्स किया जाना चाहिए ताकि जॉइन को तेज किया जा सके।
- क्रमबद्ध कॉलम: वे विशेषताएं जो ऑर्डर बाई क्लॉज में उपयोग की जाती हैं।
एन+1 क्वेरी से बचना
एरडी संबंध संरचना को उजागर करता है। यदि आपके पास एक से बहुत के संबंध हैं, तो माता-पिता को प्राप्त करना और फिर बच्चों को अलग-अलग प्राप्त करने के लिए लूप करना एन+1 क्वेरी समस्या बनाता है।
- समाधान: एरडी में परिभाषित संबंध मार्ग के आधार पर एगर लोडिंग या स्पष्ट जॉइन का उपयोग करें।
- चेतावनी:जब जंक्शन टेबल के दोनों फॉरेन की कॉलम्स पर इंडेक्स नहीं होता है, तो जटिल बहु-से-बहु संबंध आसानी से प्रदर्शन की समस्याओं का कारण बन सकते हैं।
स्कीमा डिज़ाइन में आम गलतियाँ ⚠️
यहां तक कि अनुभवी वास्तुकार भी गलतियां करते हैं। जब आप एक ईआरडी को पढ़ते हैं, तो बाद में समस्याओं के कारण बन सकने वाले खराब डिज़ाइन के संकेतों को ढूंढें।
1. चक्रीय निर्भरता
जब एंटिटी A एंटिटी B पर निर्भर होती है, और एंटिटी B एंटिटी A पर निर्भर होती है, तो आप एक चक्रीय निर्भरता बनाते हैं। इससे ट्रांजैक्शन कमिट के दौरान डेडलॉक या जटिल इनिशियलाइज़ेशन लॉजिक की समस्या हो सकती है।
2. असंतुलित कार्डिनैलिटी
कभी-कभी बहु-से-बहु संबंध को दोनों दिशाओं में एक-से-बहु के रूप में गलत ढंग से मॉडल किया जाता है, जिससे डेटा की दोहराव या जानकारी के नुकसान की समस्या होती है।
3. मेटाडेटा की कमी
एक ईआरडी जिसमें टाइमस्टैम्प (created_at, updated_at) की कमी होती है, ऑडिटिंग और डिबगिंग को मुश्किल बनाती है। बैकएंड सिस्टम अक्सर इस डेटा को सॉफ्ट डिलीट या वर्जनिंग के लिए आवश्यक मानते हैं।
4. अत्यधिक सामान्यीकरण
बहुत सारी टेबलें सरल क्वेरीज़ को अत्यधिक जॉइन्स की आवश्यकता बना सकती हैं, जिससे एप्लीकेशन धीमा हो जाता है। ऐसी टेबलों को ढूंढें जिन्हें तार्किक रूप से मिलाया जा सकता है यदि उनका एक ही लाइफसाइकल हो।
व्यावहारिक अनुप्रयोग: डायग्राम से कोड तक 💻
जब आप ईआरडी को समझ लेते हैं, तो अगला चरण इसे एप्लीकेशन लॉजिक में बदलना होता है। इस प्रक्रिया में विज़ुअल मॉडल को आपके कोडबेस में मैप करना शामिल होता है।
1. मॉडल मैपिंग
प्रत्येक एंटिटी आपके कोड में एक क्लास या मॉडल बन जाती है। एट्रिब्यूट्स प्रॉपर्टीज़ बन जाते हैं। संबंध संबंधों या मेथड्स बन जाते हैं।
- एक-से-एक:एकल ऑब्जेक्ट प्रॉपर्टी।
- एक-से-बहु:संग्रह या सूची प्रॉपर्टी।
- बहु-से-बहु:ब्रिज के माध्यम से संबंधित मॉडल्स का संग्रह।
2. एपीआई डिज़ाइन
ईआरडी आपकी एपीआई संरचना को निर्धारित करती है। एक सामान्यीकृत स्कीमा के कारण अक्सर नेस्टेड जीसन रिस्पॉन्स या संबंधित संसाधनों के लिए अलग-अलग एंडपॉइंट्स बनते हैं। उदाहरण के लिए, एक /ऑर्डर्स एंडपॉइंट में एक /ऑर्डर-आइटम्स नेस्टेड संरचना शामिल हो सकती है।
3. सत्यापन तर्क
ईआरडी में नियम (जैसे NOT NULL) को आपके एप्लीकेशन-लेवल सत्यापन में दोहराना चाहिए। यदि डेटाबेस NULL मान की अनुमति देता है लेकिन आपकी बिजनेस लॉजिक किसी मान की आवश्यकता करती है, तो एप्लीकेशन को डेटाबेस को डेटा भेजने से पहले उस नियम को लागू करना चाहिए।
समय के साथ स्कीमा अखंडता बनाए रखना 🔧
एक एरडी स्थिर नहीं है। जैसे-जैसे एप्लिकेशन विकसित होता है, स्कीमा बदलता है। एरडी को पढ़ने की आपकी क्षमता आपको माइग्रेशन को प्रभावी ढंग से प्रबंधित करने में मदद करती है।
1. माइग्रेशन का प्रबंधन
जब कोई नया टेबल या संबंध जोड़ते हैं, तो एरडी को तुरंत अपडेट करें। इससे यह सुनिश्चित होता है कि आपकी टीम को सिस्टम का वर्तमान दृश्य मिले। माइग्रेशन को संस्करण बनाया जाना चाहिए और वर्तमान स्कीमा संरचना के खिलाफ परीक्षण किया जाना चाहिए।
2. रिफैक्टरिंग
रिफैक्टरिंग में अक्सर टेबल को बांटना या उन्हें मिलाना शामिल होता है। संबंध रेखाओं को समझने से आपको यह निर्धारित करने में मदद मिलती है कि कौन से डेटा को हटाने की आवश्यकता है और कौन से विदेशी कुंजियों को अपडेट करना है।
3. दस्तावेज़ीकरण
एक एरडी एक जीवित दस्तावेज़ है। यदि आरेख डेटाबेस से मेल नहीं खाता है, तो वह बेकार है। नियमित ऑडिट सुनिश्चित करते हैं कि दृश्य प्रतिनिधित्व भौतिक वास्तविकता से मेल खाता है।
उन्नत अवधारणाएं: पुनरावृत्त संबंध 🔁
कभी-कभी, एक एंटिटी खुद से संबंधित होती है। इसे पुनरावृत्त संबंध कहा जाता है।
- उदाहरण: एक कर्मचारीएक एंटिटी जहां एक कर्मचारी अन्य कर्मचारियों का प्रबंधक है।
- कार्यान्वयन: उसी टेबल में एक विदेशी कुंजी उसी टेबल के मुख्य कुंजी की ओर इशारा करती है।
- बैकएंड तर्क:सभी उपकर्मचारियों या पूरी पदानुक्रम को खोजने के लिए पुनरावृत्त क्वेरी या ट्रैवर्सल एल्गोरिदम की आवश्यकता होती है।
एरडी में इस पैटर्न को पहचानना संगठनात्मक चार्ट या थ्रेडेड कमेंट्स जैसी सुविधाओं के निर्माण के लिए आवश्यक है।
मुख्य बातों का सारांश 📝
एरडी को समझना एक निरंतर अवलोकन और अभ्यास की प्रक्रिया है। हर रेखा को ट्रेस करने और हर प्रतीक के प्रभाव को समझने के लिए धैर्य की आवश्यकता होती है। घटकों, संबंधों और सीमाओं पर ध्यान केंद्रित करके आप एक मानसिक मॉडल बनाते हैं जो आपके विकास को मार्गदर्शन करता है।
- अपने प्रतीकों को जानें:एंटिटीज, गुणधर्मों और संबंधों के बीच अंतर समझें।
- कार्डिनैलिटी को समझें:1:1, 1:N और M:N के बीच अंतर जानें।
- सीमाओं की जांच करें:कुंजियों और नॉल-एबिलिटी नियमों की तलाश करें।
- प्रदर्शन को ध्यान में रखें:इंडेक्सिंग और क्वेरी अनुकूलन की योजना बनाने के लिए एरडी का उपयोग करें।
- इसे अपडेट रखें: सुनिश्चित करें कि आरेख वर्तमान डेटाबेस स्थिति को दर्शाता हो।
जैसे आप बैकएंड विकासकर्ता के रूप में अपनी यात्रा जारी रखते हैं, एरडी को अपना दिशानिर्देश बनाएं। यह डेटा संरचना के बारे में सूचित निर्णय लेने के लिए आवश्यक संदर्भ प्रदान करता है, जिससे यह सुनिश्चित होता है कि आप जो प्रणालियाँ बनाते हैं, वे केवल कार्यात्मक नहीं बल्कि लचीली और कुशल भी हों।
स्कीमा साक्षरता पर अंतिम विचार 🎓
एरडी को प्रभावी ढंग से पढ़ने की क्षमता एक कोडर और इंजीनियर के बीच अंतर बनाती है। यह ध्यान केंद्रित करने के तरीके को सिर्फ कोड चलाने से लेकर लोड के तहत डेटा के व्यवहार, उसके स्थायित्व और अन्य जानकारी से उसके संबंध को समझने की ओर बदल देता है। यह कौशल डिबगिंग समय को कम करता है, डेटा टीमों के साथ सहयोग को बेहतर बनाता है, और बेहतर प्रणाली डिजाइन की ओर ले जाता है।
अपने प्रोजेक्ट्स में आरेखों का अध्ययन करने के लिए समय लें। यह पूछें कि कुछ निश्चित संबंधों का चयन क्यों किया गया है। जब आप अक्षमताओं को देखते हैं, तो डिजाइन को चुनौती दें। इस प्रक्रिया में, आप स्वस्थ डेटा पारिस्थितिकी तंत्र और अधिक स्थिर एप्लिकेशन के लिए योगदान देते हैं।
याद रखें, डेटाबेस सच्चाई का स्रोत है। एरडी को उस सच्चाई के नक्शे के रूप में लें। अभ्यास के साथ, इन आरेखों को पढ़ना आपके लिए दूसरी प्रकृति बन जाएगा, जिससे आप आत्मविश्वास और सटीकता के साथ जटिल डेटा लैंडस्केप को नेविगेट कर सकेंगे।