









Projetar um modelo de dados robusto é uma das tarefas mais críticas na engenharia de software. Um Diagrama de Relacionamento de Entidades (ERD) serve como o projeto arquitetônico para como as informações são armazenadas, recuperadas e mantidas. No centro desse projeto está a normalização. Muitos profissionais abordam a normalização como uma lista rígida de verificação a ser concluída antes de passar para a implementação. No entanto, a realidade é muito mais sutil. Existe um equilíbrio delicado entre integridade de dados e desempenho de consultas que exige um entendimento profundo.
Este guia explora as realidades técnicas da normalização de ERD. Ele vai além das definições dos livros-texto para abordar cenários práticos em que a aderência rígida às regras se torna um ônus. Seja você construindo um sistema transacional ou uma plataforma analítica, saber quando parar de normalizar e quando introduzir redundância é essencial para a estabilidade de longo prazo.
🔍 Compreendendo os Princípios Fundamentais do Design Relacional
A normalização não é meramente sobre organizar dados; é sobre gerenciar dependências. Em um modelo relacional, cada coluna deve ter uma relação clara com a chave primária de sua tabela. Quando essa relação é fraca ou indireta, anomalias ocorrem. Essas anomalias se manifestam como inconsistências de dados, armazenamento desperdiçado e lógica de atualização complexa.
Os principais objetivos da normalização incluem:
- Integridade de Dados: Garantir que os dados permaneçam precisos e consistentes em todo o sistema.
- Eficiência de Armazenamento: Eliminar cópias redundantes dos mesmos dados.
- Escalabilidade: Projetar esquemas que possam acomodar o crescimento sem reescritas estruturais.
- Manutenibilidade: Reduzir a complexidade necessária para atualizar informações.
No entanto, alcançar esses objetivos frequentemente vem com um custo. Cada nível de normalização geralmente aumenta o número de tabelas e a complexidade das consultas necessárias para recuperar dados unidos. Compreender essa troca é o primeiro passo no projeto eficaz de esquemas.
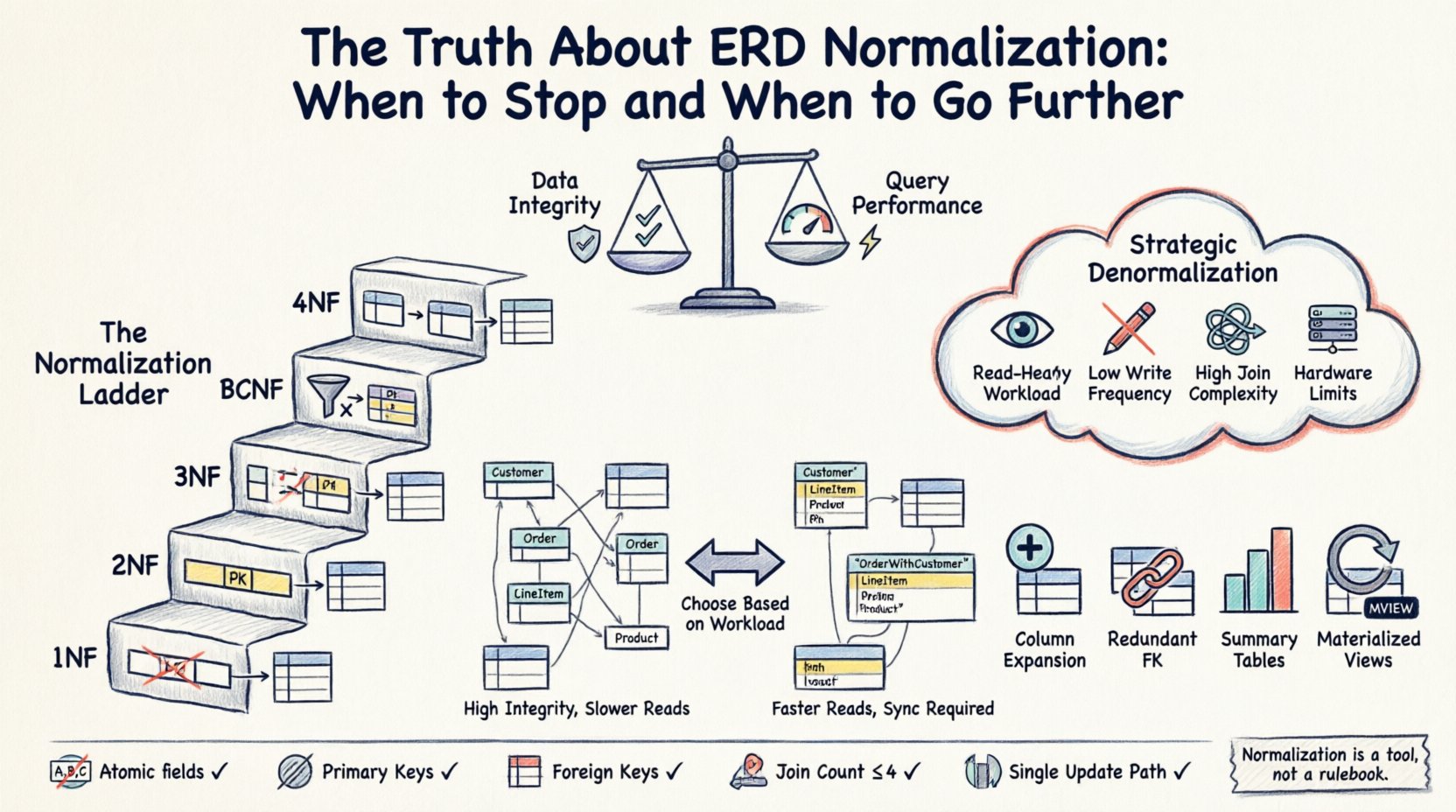
⚙️ Os Três Pilares da Normalização Padrão (1FN, 2FN, 3FN)
Antes de decidir parar ou ir além, é necessário entender a base. As formas padrão fornecem uma escada de aprimoramento estrutural.
Primeira Forma Normal (1FN)
A base de qualquer banco de dados relacional é a 1FN. Uma tabela está na 1FN se atender aos seguintes critérios:
- Todos os valores das colunas são atômicos (indivisíveis).
- Cada coluna contém valores de um único tipo.
- Não há grupos repetidos ou matrizes dentro de uma linha.
Por exemplo, armazenar uma lista de nomes de produtos em uma única coluna viola a 1FN. Em vez disso, cada produto deve ocupar sua própria linha. Embora sistemas modernos lidem frequentemente com tipos de dados complexos, a aderência rigorosa à atomicidade garante que as consultas permaneçam previsíveis e que as estratégias de indexação funcionem conforme planejado.
Segunda Forma Normal (2FN)
Uma vez que uma tabela está na 1FN, ela deve atender aos requisitos da 2FN. Essa forma aplica-se especificamente a tabelas com chaves primárias compostas (chaves formadas por múltiplas colunas). Uma tabela está na 2FN se:
- Ela já está na 1FN.
- Todos os atributos não-chave dependem plenamente da chave primária inteira, e não apenas de parte dela.
Considere uma tabela de detalhes de pedidos onde a chave é uma combinação de ID do Pedido e ID do Produto. Se você armazenar o Nome do Produto nessa tabela, terá uma dependência parcial. O Nome do Produto depende apenas do ID do Produto, e não do ID do Pedido. Para corrigir isso, você move o Nome do Produto para uma tabela separada de Produtos. Isso reduz as anomalias de atualização; se o nome de um produto mudar, você atualiza apenas em um lugar, e não em milhares de registros de pedidos.
Terceira Forma Normal (3FN)
A 3FN é frequentemente considerada o ponto ideal para a maioria dos sistemas operacionais. Uma tabela está na 3FN se:
- Está na 2FN.
- Não existem dependências transitivas. Atributos não-chave devem depender apenas da chave primária.
Uma dependência transitiva ocorre quando a Coluna A determina a Coluna B, e a Coluna B determina a Coluna C. Em um banco de dados, se o ID do Cliente determina a Cidade, e a Cidade determina a Região, armazenar a Região na tabela de Clientes cria uma dependência transitiva. Se a Região mudar para essa Cidade, você precisará atualizar todos os registros de clientes dessa cidade. Normalizar isso remove os dados da Região para um local separado, garantindo que as atualizações ocorram apenas uma vez.
📉 O Custo de Desempenho da Normalização Estrita
Embora a 3FN minimize a redundância, maximiza o número de tabelas. Em um esquema normalizado, recuperar um único registro lógico frequentemente exige a junção de múltiplas tabelas. Esse processo tem um custo computacional.
- Custo de Junção:Cada operação de junção exige que o motor do banco de dados corresponda linhas de tabelas diferentes. À medida que as tabelas crescem, esse processo de correspondência consome CPU e memória.
- Operações de E/S:Dados espalhados por muitas tabelas exigem mais leituras de disco. Se os dados não forem armazenados eficientemente em cache, a latência de leitura aumenta.
- Complexidade:Consultas complexas com muitas junções são mais difíceis de otimizar e manter. Elas também são mais propensas a falhar se o esquema mudar.
Para sistemas com cargas pesadas de escrita, a normalização geralmente é a escolha correta. Ela evita a duplicação de dados e garante que uma atualização de um único fato seja propagada corretamente. No entanto, para sistemas com cargas pesadas de leitura, o custo das junções pode se tornar um gargalo.
🚀 Denormalização Estratégica: Quando Quebrar as Regras
A denormalização é a introdução intencional de redundância para otimizar o desempenho. Não é um erro; é uma decisão arquitetônica deliberada feita quando o custo da normalização supera seus benefícios.
Gatilhos para a Denormalização
Você deveria considerar relaxar as regras de normalização quando:
- Operações de Leitura Dominam:Se o seu aplicativo é pesado em leituras (por exemplo, um painel de relatórios), reduzir as junções pode reduzir significativamente a latência.
- A Complexidade das Consultas é Alta:Se os usuários precisam de dados de 10 ou mais tabelas para visualizar uma única página, a consulta torna-se lenta e difícil de depurar.
- A Frequência de Escrita é Baixa:Se os dados são raramente atualizados, o risco de inconsistência decorrente da redundância é minimizado.
- Existem Restrições de Hardware:Em ambientes onde a E/S de disco é cara ou limitada, armazenar em cache dados redundantes pode reduzir leituras físicas.
Estratégias Comuns de Denormalização
- Expansão de Coluna:Armazenar um valor derivado diretamente em uma tabela. Por exemplo, adicionar uma coluna “Preço Total” à tabela de Pedidos, calculada a partir dos itens da linha, para que você não precise somá-los em cada leitura.
- Chaves Estrangeiras Redundantes:Adicionar um ID de Pai à tabela de Filhos para evitar uma junção ao recuperar a hierarquia.
- Tabelas de Resumo: Pré-cálculo de agregados (contagens, somas) em uma tabela separada que é atualizada periodicamente ou por meio de gatilhos.
- Visualizações Materializadas:Armazenar o resultado de uma consulta complexa como uma tabela física que é atualizada em um cronograma.
📊 Comparação: Normalização vs. Denormalização
Para visualizar os trade-offs, considere a seguinte tabela de comparação.
| Aspecto | Alta Normalização (3NF+) | Projeto Denormalizado |
|---|---|---|
| Integridade dos Dados | Alta – Fonte única de verdade | Menor – Requer lógica de sincronização |
| Uso de Armazenamento | Eficiente – Sem duplicatas | Ineficiente – Dados redundantes |
| Desempenho de Escrita | Rápido – Atualização de uma única linha | Mais lento – Atualização de múltiplas linhas |
| Desempenho de Leitura | Mais lento – Requer junções | Rápido – Acesso direto |
| Complexidade da Consulta | Alta – Muitas junções necessárias | Baixa – Consultas simples |
| Esforço de Manutenção | Baixo – Atualização uma vez | Alto – Sincronização em múltiplos locais |
Esta tabela destaca que não existe uma melhor prática universal. A escolha depende inteiramente da carga de trabalho específica da aplicação.
🛠️ Estrutura de Decisão para Projeto de Esquema
Para determinar o nível adequado de normalização para o seu projeto específico, use este framework de decisão. Avalie cada ponto com base nos requisitos do seu projeto.
1. Analise o Padrão de Carga
Identifique a proporção de leituras para gravações. Se o seu sistema for OLTP (Processamento de Transações Online), priorize a integridade e a 3FN. Se for OLAP (Processamento Analítico Online), priorize a velocidade de leitura e considere a desnormalização.
2. Avalie os requisitos de atualidade dos dados
Os dados precisam ser em tempo real? Se você desnormalizar, introduzirá um atraso entre uma atualização de origem e a mudança refletida nos dados redundantes. Se seus usuários precisam de consistência imediata, a normalização rigorosa é mais segura.
3. Avalie a frequência de atualizações
Olhe para as chaves primárias. Se uma tabela de pesquisa (como uma lista de países) muda raramente, desnormalizar seus dados em tabelas transacionais é seguro. Se uma tabela de pesquisa muda frequentemente, mantenha-a separada para minimizar erros de sincronização.
4. Considere hardware e cache
Bancos de dados modernos frequentemente armazenam dados em cache na memória. Se o conjunto de trabalho couber na RAM, o custo das junções diminui. Nesse caso, você pode permitir uma estrutura ligeiramente mais normalizada sem sacrificar o desempenho.
🧠 Normalização Avançada: BCNF e 4NF
Além da 3FN, existem formas superiores, como a Forma Normal de Boyce-Codd (BCNF) e a Quarta Forma Normal (4NF). Elas abordam casos específicos e marginais.
Forma Normal de Boyce-Codd (BCNF)
A BCNF é uma versão mais rigorosa da 3FN. Ela lida com casos em que um atributo não-primo determina outro atributo não-primo, mesmo que a chave primária seja composta. Embora seja teoricamente perfeita, a BCNF pode, às vezes, resultar na perda da preservação de dependências. Na prática, a 3FN é frequentemente suficiente, e forçar a BCNF pode, às vezes, complicar o esquema sem adicionar valor significativo.
Quarta Forma Normal (4NF)
A 4NF lida com dependências multivaloradas. Isso ocorre quando uma única linha contém múltiplas listas independentes de valores. Por exemplo, uma tabela de alunos armazenando múltiplos hobbies e múltiplas aulas na mesma linha. Isso é raro em aplicações comerciais padrão, mas comum em cenários especializados de modelagem de dados.
🚫 Armadilhas Comuns para Evitar
Mesmo com um entendimento sólido da normalização, é fácil cometer erros. Evite esses erros comuns:
- Sobrenormalização:Criar centenas de tabelas pequenas para relacionamentos simples. Isso torna a lógica da aplicação difícil de acompanhar e desacelera o desenvolvimento.
- Ignorar índices:Um esquema normalizado exige junções. Se as colunas de junção não forem indexadas, o desempenho será afetado, independentemente do design do esquema.
- Desnormalizar sem monitoramento:Introduzir redundância sem um plano para mantê-la sincronizada leva à corrupção de dados com o tempo.
- Codificar lógica diretamente:Não calcule valores derivados na camada de aplicação se eles deveriam estar no banco de dados. Mantenha as regras de negócios próximas aos dados.
✅ Checklist para Validação de Esquema
Antes de implantar um novo esquema, execute-o por esta lista de verificação de validação.
- Atomicidade: Todos os campos são atômicos?
- Chaves Primárias:Cada tabela possui uma chave primária única?
- Chaves Estrangeiras: Os relacionamentos são forçados por meio de chaves estrangeiras?
- Redundância: Existem grupos óbvios de dados repetidos?
- Quantidade de Junções: As consultas críticas exigem mais de 3-4 junções?
- Caminho de Atualização: Uma alteração de dados pode ser feita em um único local?
🔗 Conclusão sobre Arquitetura de Dados
A normalização é uma ferramenta, não um manual de regras. Ela existe para proteger seus dados contra inconsistências, mas não deve impedir que sua aplicação funcione de forma eficiente. A ‘verdade’ sobre a normalização de ERD é que ela é um espectro. Você começa com uma estrutura altamente normalizada para garantir a integridade e, em seguida, denormaliza seletivamente com base nas necessidades de desempenho.
Não existe uma solução única para todos os casos. Um sistema de negociação de alta frequência será muito diferente de um sistema de gerenciamento de conteúdo. A chave está em entender os mecanismos subjacentes de dependências e junções. Equilibrando o custo de armazenamento com o custo de computação, você pode construir sistemas que sejam confiáveis e rápidos ao mesmo tempo.
À medida que você continua projetando, lembre-se de que a evolução do esquema é inevitável. Planeje as mudanças. Use versionamento para suas migrações de banco de dados. E sempre teste suas consultas sob carga antes de tomar uma decisão estrutural. O melhor esquema é aquele que apoia seus objetivos de negócios sem se tornar um gargalo.