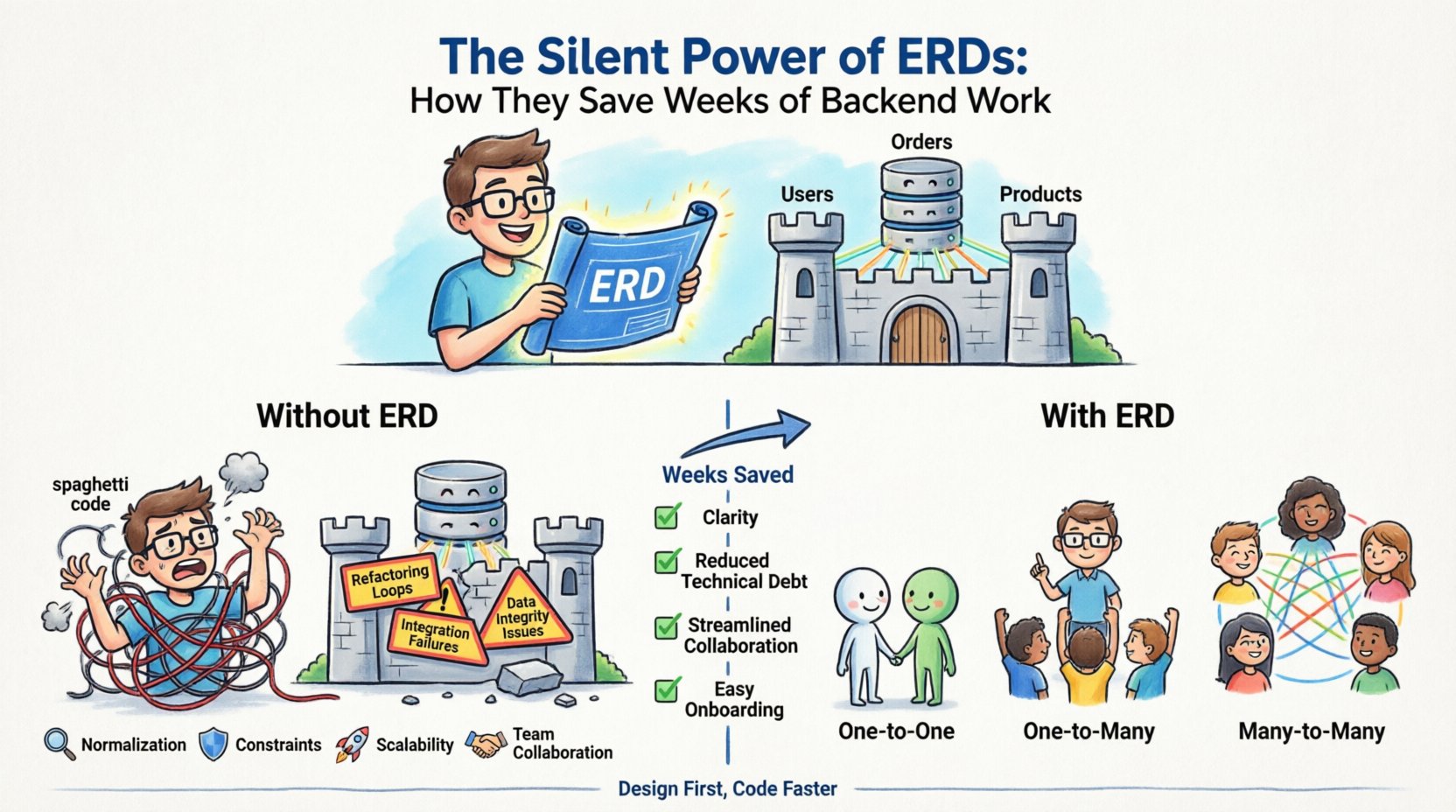
Backend development often feels like building a house without a blueprint. You start laying bricks, adding windows, and framing walls based on intuition. Sometimes, it works. Often, it doesn’t. Weeks later, you find yourself tearing down walls to accommodate a door you forgot to plan. This is the reality of coding without a solid Entity Relationship Diagram (ERD). The ERD is the silent architect of your data infrastructure, operating behind the scenes to prevent costly structural failures. When you invest time in designing your data model before writing a single line of code, you gain clarity, reduce technical debt, and streamline collaboration across teams.
This guide explores the tangible impact of ERDs on backend workflows. We will break down the mechanics of data modeling, the hidden costs of skipping design, and the strategic advantages of a well-documented schema. By understanding these principles, you can shift from reactive coding to proactive architecture.
What Exactly Is an ERD? 📐
An Entity Relationship Diagram is a visual representation of the logical structure of a database. It maps out how different pieces of data relate to one another. Think of it as a map for your application’s memory. Without this map, developers navigate blindly, risking collisions between data points that should remain separate.
At its core, an ERD consists of three main components:
- Entities: These represent the objects or concepts you are tracking. In a database, these translate to tables. Examples include Users, Orders, or Products.
- Attributes: These are the specific properties of an entity. They become the columns within your tables. For a User entity, attributes might include email, password_hash, and created_at.
- Relationships: These define how entities interact. They dictate the cardinality and connectivity between tables, such as a User having many Orders.
While the concept seems simple, the complexity arises when managing scale. A simple blog might only need a few tables. An enterprise system requires dozens, if not hundreds, of interconnected entities. The ERD acts as the single source of truth for all these interactions.
The Hidden Cost of Skipping Design 💸
Many development teams rush to code to meet deadlines. They assume they can refactor the database later. This is a dangerous assumption. Changing a database schema is significantly more expensive than changing application logic. Once data is written, altering its structure requires migration scripts, potential downtime, and careful handling of existing records.
Consider the following scenarios where the lack of an ERD causes friction:
- Refactoring Loops: You build a feature, realize the data structure doesn’t support it, and have to rewrite the queries. This cycle repeats, consuming weeks of sprint time.
- Integration Failures: When frontend and backend teams work without a shared schema definition, APIs often break. The backend sends one structure; the frontend expects another.
- Data Integrity Issues: Without defined constraints, invalid data enters the system. You end up cleaning up orphaned records or fixing inconsistent states manually.
- Onboarding Delays: New developers struggle to understand the system. They spend days reading code instead of building features because the data flow is undocumented.
By the time you notice the issue, the cost has compounded. The “fix” now requires not just code changes, but data migration, testing, and deployment verification.
Mapping Relationships Like a Pro 🔗
Understanding how data connects is the heart of ERD design. Relationships determine how queries are written and how performance is optimized. There are three primary types of relationships you must define clearly.
The table below outlines the differences between these relationship types:
| Relationship Type | Definition | Example Scenario | Implementation Note |
|---|---|---|---|
| One-to-One (1:1) | A single record in Table A relates to exactly one record in Table B. | A User profile linked to a User settings table. | Often implemented by placing the primary key of B in A. |
| One-to-Many (1:N) | A single record in Table A relates to multiple records in Table B. | A Category containing multiple Products. | Standard foreign key placement in the “many” side table. |
| Many-to-Many (M:N) | Multiple records in Table A relate to multiple records in Table B. | Students enrolled in multiple Courses. | Requires a junction table to resolve the link. |
Ignoring these distinctions leads to inefficient queries. For instance, storing a list of product IDs in a single column for a category violates normalization principles. It forces you to parse strings instead of using joins, slowing down performance as data grows.
Normalization: Keeping Data Clean 🧹
Normalization is the process of organizing data to reduce redundancy and improve integrity. While modern systems sometimes deviate from strict normalization for performance, understanding the principles remains essential.
The standard forms of normalization include:
- First Normal Form (1NF): Ensures atomicity. Each column contains only one value. No lists or arrays in a single cell.
- Second Normal Form (2NF): Builds on 1NF. Requires that all non-key attributes are fully dependent on the primary key. No partial dependencies.
- Third Normal Form (3NF): Builds on 2NF. Requires that non-key attributes depend only on the primary key, not on other non-key attributes.
Why does this matter? Consider an Order table. If you store the Customer Name in every order row, you create redundancy. If the customer changes their name, you must update thousands of rows. If you miss one, your data becomes inconsistent. By moving Customer Name to a Customers table and linking via ID, you ensure a single source of truth.
However, normalization is not a silver bullet. Over-normalization can lead to complex joins that hurt performance. The goal is balance. You must understand the trade-offs between storage efficiency and query speed.
Common Pitfalls in Schema Design 🚧
Even experienced developers make mistakes when designing ERDs. Recognizing these common traps can save you significant headache later.
- Circular Dependencies: Entity A needs Entity B, and Entity B needs Entity A. This creates a deadlock in initialization and makes migration scripts difficult to write.
- Missing Constraints: Failing to define foreign keys, unique constraints, or check constraints allows invalid data to slip through the cracks. The database should enforce rules, not the application code.
- Hardcoded Values: Storing status codes like “active” or “inactive” as integers without a lookup table makes the system brittle. If you need to add “suspended,” you change the logic everywhere.
- Ignoring Soft Deletes: Deleting data permanently removes history. Designing for soft deletes (marking a record as deleted rather than removing it) preserves audit trails.
- Over-Engineering: Designing for a use case that doesn’t exist yet. Build for the current requirements, but ensure the schema is flexible enough to handle reasonable growth.
Each of these pitfalls adds layers of complexity to your codebase. An ERD helps you visualize these issues before they become embedded in production.
From Diagram to Implementation 🚀
Once the ERD is finalized, the next step is translating it into code. This process, often called schema migration, requires discipline.
Follow these steps to ensure a smooth transition:
- Version Control: Treat your database schema like application code. Every change should be a migration file stored in your repository.
- Backward Compatibility: When adding a column, make it nullable first. Populate existing data, then enforce the constraint in a subsequent migration. This prevents downtime.
- Testing Migrations: Run migration scripts in a staging environment identical to production. Check for performance regressions.
- Rollback Plans: Always have a way to undo a migration if it fails. Data loss is unacceptable.
Automation tools can assist in generating SQL from ERDs, but manual review is crucial. Automated generators often miss business logic nuances that a human architect would catch.
Collaboration and Communication 🤝
An ERD is not just for database administrators. It serves as a communication tool for the entire team. Product managers, frontend developers, and QA engineers all benefit from understanding the data structure.
When stakeholders review the ERD, they can identify potential issues early:
- Feature Feasibility: Can the database support the requested feature? If not, what changes are needed?
- Performance Expectations: Does the design allow for efficient querying at scale?
- Security Requirements: Are sensitive fields identified and protected? Is access control feasible at the data level?
This shared understanding reduces friction during sprint planning. Instead of guessing how data flows, the team discusses it based on a visual model. Disagreements are resolved with reference to the diagram rather than opinion.
Scalability Considerations 📈
As your application grows, your data model must evolve. An ERD helps you anticipate these changes. It allows you to visualize how adding a new entity affects existing relationships.
Key scalability factors to consider during design:
- Indexing Strategy: Identify which columns will be queried frequently. Plan indexes on these fields to speed up retrieval.
- Partitioning: Will certain tables grow too large? Plan for horizontal partitioning if necessary.
- Read/Write Split: Does the design support separate read and write replicas? Ensure foreign keys don’t complicate replication.
- Caching Layers: How does the data model interact with cache systems? Immutable data is easier to cache than frequently changing data.
Thinking about scale early prevents the need for a complete rewrite later. It is easier to add a new table than to move data from one server to another.
Final Thoughts on Data Architecture 🧠
The effort spent on creating a detailed ERD pays dividends throughout the lifecycle of a project. It transforms data modeling from a reactive chore into a strategic asset. By visualizing relationships, enforcing constraints, and planning for growth, you build systems that are robust and maintainable.
Don’t treat the database as an afterthought. It is the foundation of your application. Invest in the design phase, and you will save weeks of backend work in the long run. The silent power of the ERD lies in its ability to prevent problems before they ever occur.
Start mapping your data today. The clarity you gain will be the difference between a chaotic codebase and a streamlined system.