











在微服务架构中设计数据模型,相比单体应用需要根本性的思维转变。在传统系统中,一个实体关系图(ERD)通常涵盖整个数据库。在分布式环境中,这种单一视图会分裂为多个独立的模式。挑战在于保持一致性的同时不耦合服务。本指南探讨如何有效构建数据模型,确保可扩展性和弹性,同时避免分布式数据管理中的常见陷阱。
当服务直接共享数据时,它们会继承彼此的依赖关系。这种紧密耦合会导致系统脆弱,一个区域的更改会破坏另一个区域。目标是建立边界,使团队能够独立部署。实现这一点需要对关系、一致性模型和集成模式进行仔细规划。
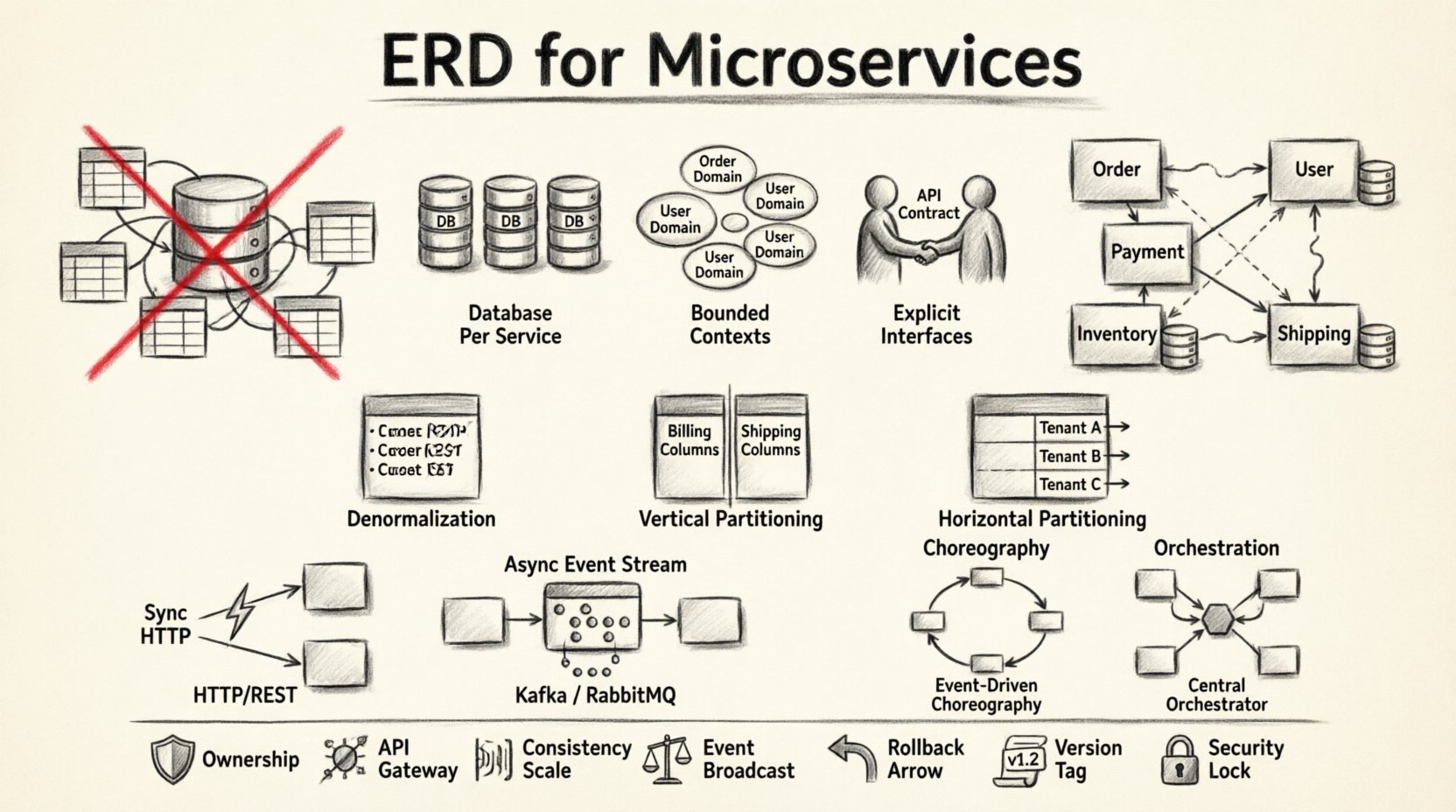
🧱 为什么传统ERD在分布式系统中会失效
标准的ERD假设存在一个中心权威。它在单一事务边界内映射表、列和外键。微服务拒绝这种中心化。当你将单体ERD的思维模式应用于分布式系统时,可能会导致分布式单体的出现。这种情况发生在服务依赖共享数据库表而非定义好的API时。
忽略这些原则时,通常会出现以下问题:
- 部署耦合:对共享表的更改需要在多个服务中同时部署。
- 事务边界:ACID事务跨越多个服务,增加了延迟和故障点。
- 模式锁定:一个服务中的数据库锁可能会阻塞另一个服务的请求。
- 可见性问题:没有单一团队拥有全局数据状态,导致数据孤岛。
与其使用单一图表,你需要一组通过明确定义接口通信的服务特定模式。这种方法优先考虑自主性而非即时一致性。
🧬 分布式数据建模的核心原则
为了保持秩序,你必须遵循特定的架构原则。这些指南有助于团队在数据所有权和访问模式方面做出决策。
1. 每个服务拥有自己的数据库
每个微服务都应拥有自己的数据存储。这确保了服务的内部模式对其他服务不可见。如果服务A需要服务B的数据,必须通过API请求,而不是直接查询数据库。这种隔离保护了每个领域的完整性。
- 服务自行管理其模式的演进。
- 团队可以根据自身需求选择最适合的数据库技术(多语言持久化)。
- 一个数据库的故障不会导致整个应用程序崩溃。
2. 有界上下文
数据必须与业务能力保持一致。在领域驱动设计中,有界上下文定义了模型的语义边界。两个服务可能都使用“客户”这一术语,但这些上下文中的数据是不同的。一个可能存储联系信息,另一个则存储财务历史。将它们合并到一个ERD中会造成混淆并产生技术债务。
3. 明确的接口
由于服务无法直接查看彼此的数据,API便成为数据契约。API响应的模式定义了数据对消费者而言的真实状态。这使得内部存储实现与外部使用解耦。
📐 实现独立性的模式设计模式
为微服务设计模式涉及特定的模式,以处理传统上由外键处理的关系。你不能依赖数据库级别的约束来强制跨服务的关系。
反规范化
在单体系统中,规范化减少了冗余。而在微服务中,通常更倾向于反规范化。存储重复数据可以减少远程调用的需求。例如,订单服务可能在订单记录中存储客户姓名和地址。这样每次显示订单时,就不必每次都同步查询用户服务。
- 优势: 更快的读取性能和更少的网络跳数。
- 风险: 如果源数据发生变化,可能导致数据不一致。您必须通过事件来处理更新。
垂直分片
将大表拆分为更小、更专注的集合。如果一张表同时包含账单信息和配送地址,应将这些关注点分离。账单数据可能属于支付服务,而配送地址则属于物流服务。这可以减少变更的影响范围,并通过限制访问来提高安全性。
水平分片
根据租户ID或地理区域拆分数据。这在无需影响其他服务的情况下扩展特定服务时非常有用。您可以为高流量区域复制服务,同时保持其他服务轻量。
| 模式 | 最佳使用场景 | 关键考虑因素 |
|---|---|---|
| 去规范化 | 读取密集型工作负载 | 需要同步逻辑 |
| 垂直分片 | 不同的领域 | 清晰的API边界 |
| 水平分片 | 高扩展性 / 多租户 | 路由逻辑复杂性 |
🔄 处理关系与一致性
微服务数据建模中最困难的部分是在没有分布式事务的情况下保持一致性。您需要在强一致性与最终一致性之间做出选择。
同步通信
服务可以通过HTTP或gRPC直接相互调用。这为即时操作提供了强一致性。然而,它会引入延迟并形成依赖链。如果服务A调用服务B,而服务B宕机,服务A也会失败。
异步通信
服务通过消息队列或事件流进行通信。这解耦了操作的时间。服务A发布一个事件,服务B稍后消费该事件。这支持最终一致性。
- 优点: 弹性、可扩展性和松耦合。
- 缺点: 数据暂时不一致。调试需要跨多个日志进行追踪。
🗓️ 保证数据完整性的Saga模式
Saga是一系列本地事务的组合。每个事务都会更新本地数据库,并发布一个事件以触发下一步。如果某一步骤失败,Saga会执行补偿事务来撤销之前的所有更改。
编排与编排
Saga可以通过两种方式实现:
- 编排:服务监听事件并决定下一步操作。没有中央控制器。这种方式灵活,但更难可视化。
- 编排:一个中央协调者告诉各个服务该做什么。这能提供更好的工作流可见性和控制力,但会引入单点故障。
在为Saga建模ERD时,必须考虑状态变化。Saga中涉及的每个服务都需要存储其状态以处理回滚。这意味着你的数据模式必须支持事务状态,而不仅仅是最终数据。
📝 管理模式演进
模式演进是不可避免的。字段会变化,类型会调整,约束会放宽。在分布式系统中,当其他服务依赖某个数据库模式时,你无法随意更改它。因此必须为版本控制做好规划。
向后兼容性
始终维护向后兼容性。添加新字段时,不要立即删除旧字段。应允许消费者逐步迁移。如果必须更改字段名称,请在过渡期内将旧名称别名为新名称。
版本化策略
- URI版本化:在API路径中包含版本号。
- 请求头版本化:使用自定义请求头来指定期望的模式版本。
- 内容协商:使用标准HTTP请求头来请求特定的媒体类型。
文档必须与代码保持同步。自动化测试应验证API契约与模式是否匹配。这可以防止破坏性变更进入生产环境。
🛡️ 常见陷阱与规避方法
即使有完善的计划,团队仍常常在某些具体问题上出错。了解这些陷阱有助于设计出更健壮的系统。
1. 共享数据库陷阱
不要在服务之间共享表。这会造成隐藏的耦合。如果支付服务读取订单服务的表,它就了解了太多内部结构信息。这会导致紧密耦合和部署冲突。
2. 过度规范化
试图在服务之间进行数据规范化会导致过多的连接操作和网络调用。应接受一定程度的冗余。拥有重复数据总比拥有一个缓慢且耦合紧密的系统要好。
3. 忽视幂等性
网络调用会失败。消息可能被重复发送。你的模式和API逻辑必须能够处理重复请求而不会出错。设计端点时应保证幂等性,这样重试请求不会产生重复记录。
4. 缺乏可观测性
当数据分布时,你无法通过查询单个数据库来追踪事务。你需要分布式追踪和集中式日志记录。你的数据模式应包含关联ID,以跨服务边界追踪请求。
📋 治理检查清单
在部署新服务之前,请审查以下检查清单,以确保你的数据模型是合理的。
- 所有权:是否有单一服务负责此数据?
- 接口:数据是否仅通过API暴露?
- 一致性:一致性模型是否已记录(强一致性 vs. 最终一致性)?
- 事件:状态变更是否作为事件发布给其他服务?
- 补偿机制:是否有失败事务的回滚机制?
- 版本控制:数据模式是否已版本化以应对未来的变化?
- 安全性:敏感数据是否在静态和传输过程中都已加密?
🔍 可视化架构
虽然你无法为整个系统绘制单一的ERD,但可以创建一个高层次的架构图。该图展示服务及其数据边界,而非具体字段。
- 为每个服务绘制方框。
- 在方框内标注数据域(例如:“用户资料数据”)。
- 用箭头表示API调用,以指示数据流向。
- 将事件流与请求/响应流分开标识。
这种可视化辅助工具帮助利益相关者理解信息流,而不会陷入技术模式细节中。它可作为架构师和业务分析师之间的沟通工具。
🚀 结论
为微服务设计ERD并非只是在表之间画线,而是定义业务能力之间的边界。通过采用每个服务一个数据库的模式,接受最终一致性,并严格管理API,你就能构建可扩展的系统。通过纪律和明确的契约,分布式数据的混乱是可以管理的。专注于自主性,最小化耦合,并确保每个服务完全拥有其数据。
请记住,数据建模是一个迭代过程。随着服务的增长,你的数据模式也需要演进。定期根据这些原则审查你的架构,以保持系统的健康与韧性。