











后端开发常常感觉像是在没有蓝图的情况下建房子。你凭直觉开始砌砖、安装窗户、搭建墙架。有时能成功,但大多数时候不行。几周后,你发现自己不得不拆掉墙壁,为一个忘记规划的门腾出空间。这就是没有坚实设计基础的编码现实实体关系图(ERD)。ERD 是你数据基础设施的无声建筑师,默默运作以防止代价高昂的结构性失败。当你在编写任何代码之前投入时间设计数据模型时,你将获得清晰的思路,减少技术债务,并简化团队间的协作。
本指南探讨了 ERD 对后端工作流程的切实影响。我们将剖析数据建模的机制、跳过设计的隐性成本,以及良好文档化模式的战略优势。通过理解这些原则,你可以从被动编码转向主动架构设计。
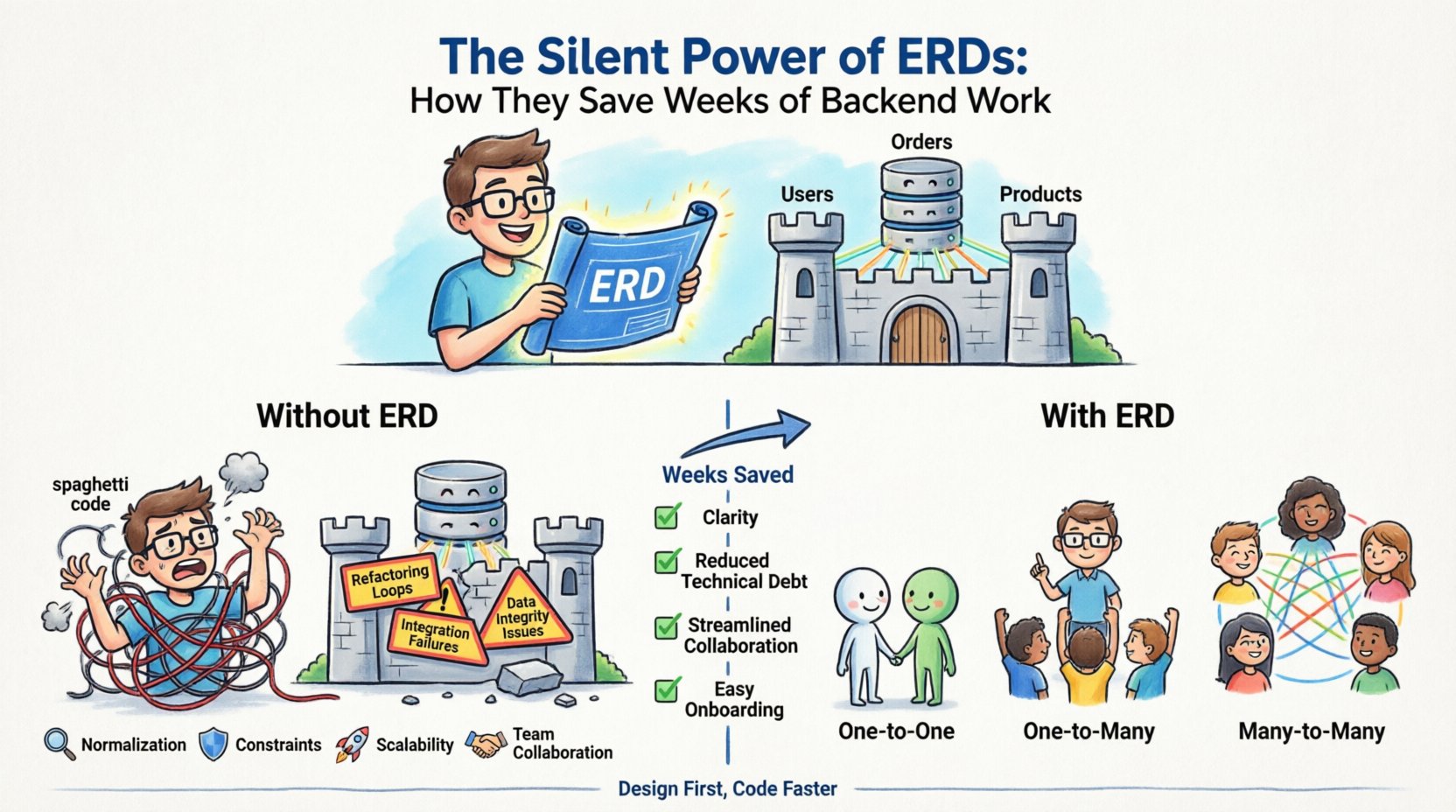
什么是 ERD? 📐
实体关系图是一种数据库逻辑结构的可视化表示。它描绘了不同数据片段之间的相互关系。可以将其视为应用程序内存的地图。没有这张地图,开发者将盲目导航,面临本应保持独立的数据点发生冲突的风险。
本质上,ERD 包含三个主要组成部分:
- 实体: 它们代表你正在追踪的对象或概念。在数据库中,这些对应于表。例如用户, 订单,或产品.
- 属性: 它们是实体的具体属性。在你的表中,它们会成为列。对于一个用户 实体,属性可能包括电子邮件, 密码哈希,以及创建时间.
- 关系: 它们定义了实体之间的交互方式。它们决定了表之间的基数和连接性,例如一个用户 拥有多个订单.
虽然这个概念看起来很简单,但随着规模的扩大,复杂性便随之而来。一个简单的博客可能只需要几张表。而一个企业系统则需要几十个,甚至数百个相互关联的实体。ERD 成为了所有这些交互的唯一可信来源。
跳过设计的隐性成本 💸
许多开发团队为了赶进度而急于编码。他们认为可以稍后再重构数据库。这是一个危险的假设。更改数据库模式的代价远高于更改应用逻辑。一旦数据被写入,修改其结构就需要迁移脚本、可能的停机时间,以及对现有记录的谨慎处理。
考虑以下由于缺乏 ERD 而导致摩擦的场景:
- 重构循环: 你开发了一个功能,却发现数据结构不支持它,不得不重写查询。这种循环反复出现,消耗了数周的冲刺时间。
- 集成失败: 当前端和后端团队在没有共享模式定义的情况下工作时,API 经常会失效。后端发送一种结构,而前端却期望另一种。
- 数据完整性问题: 没有定义约束,无效数据就会进入系统。你最终不得不手动清理孤立记录或修复不一致的状态。
- 入职延迟: 新开发人员难以理解系统。由于数据流没有文档记录,他们不得不花几天时间阅读代码,而不是开发功能。
等到你注意到问题时,成本已经累积。现在,“修复”不仅需要代码更改,还需要数据迁移、测试和部署验证。
像专业人士一样绘制关系 🔗
理解数据如何连接是 ERD 设计的核心。关系决定了查询如何编写以及性能如何优化。你必须明确界定三种主要关系类型。
下表概述了这些关系类型之间的差异:
| 关系类型 | 定义 | 示例场景 | 实现说明 |
|---|---|---|---|
| 一对一(1:1) | 表 A 中的单条记录与表 B 中的单条记录一一对应。 | 用户资料与用户设置表关联。 | 通常通过将表 B 的主键放在表 A 中来实现。 |
| 一对多(1:N) | 表 A 中的单条记录与表 B 中的多条记录相关联。 | 一个分类包含多个产品。 | 在“多”方的表中标准地放置外键。 |
| 多对多(M:N) | 表A中的多个记录与表B中的多个记录相关联。 | 注册了多个课程的学生。 | 需要一个连接表来解决关联关系。 |
忽略这些区别会导致查询效率低下。例如,将一个类别的产品ID列表存储在单个列中,违反了规范化原则。这迫使你解析字符串而不是使用连接操作,随着数据量的增长,性能会明显下降。
规范化:保持数据整洁 🧹
规范化是通过组织数据来减少冗余并提高数据完整性的过程。尽管现代系统有时为了性能而偏离严格的规范化,但理解这些原则仍然至关重要。
规范化的标准形式包括:
- 第一范式(1NF):确保原子性。每一列只包含一个值。单个单元格中不允许有列表或数组。
- 第二范式(2NF):建立在1NF的基础上。要求所有非键属性完全依赖于主键,不能存在部分依赖。
- 第三范式(3NF):建立在2NF的基础上。要求非键属性仅依赖于主键,而不依赖于其他非键属性。
为什么这很重要?考虑一个订单表。如果你在每条订单记录中存储客户姓名,就会产生冗余。如果客户更改姓名,你必须更新数千行数据。如果遗漏一行,数据就会变得不一致。通过将客户姓名移到客户表并通过ID关联,就能确保单一数据源。
然而,规范化并非万能良方。过度规范化可能导致复杂的连接操作,影响性能。目标是取得平衡。你必须理解存储效率与查询速度之间的权衡。
模式设计中的常见陷阱 🚧
即使是经验丰富的开发人员在设计ERD时也会犯错。识别这些常见陷阱可以帮你避免日后出现重大麻烦。
- 循环依赖:实体A需要实体B,而实体B也需要实体A。这会导致初始化时出现死锁,并使迁移脚本难以编写。
- 缺失约束:未能定义外键、唯一性约束或检查约束,会导致无效数据被遗漏。数据库应负责强制执行规则,而不是由应用程序代码来完成。
- 硬编码值:将状态码(如“active”或“inactive”)以整数形式存储,而不使用查找表,会使系统变得脆弱。如果需要添加“suspended”,你必须在所有地方修改逻辑。
- 忽略软删除:永久删除数据会抹去历史记录。设计软删除(将记录标记为已删除,而非实际移除)可以保留审计追踪。
- 过度设计:为尚未存在的使用场景进行设计。应满足当前需求,但确保数据结构具备足够的灵活性以应对合理的增长。
这些陷阱中的每一个都会给你的代码库增加复杂性。ERD 帮助你在问题嵌入生产环境之前就将其可视化。
从图表到实现 🚀
ERD 确定后,下一步就是将其转化为代码。这一过程通常称为模式迁移,需要高度的纪律性。
遵循以下步骤以确保顺利过渡:
- 版本控制:将数据库模式视为应用程序代码。每次变更都应以迁移文件的形式存储在代码仓库中。
- 向后兼容性:添加列时,应先将其设为可为空。填充现有数据后,再在后续迁移中强制约束。这可以避免停机。
- 测试迁移:在与生产环境完全相同的预发布环境中运行迁移脚本。检查是否存在性能退化。
- 回滚计划:如果迁移失败,必须始终有办法回滚。数据丢失是不可接受的。
自动化工具可以帮助从 ERD 生成 SQL,但人工审查至关重要。自动化生成器常常会忽略人类架构师能够察觉的业务逻辑细节。
协作与沟通 🤝
ERD 不仅是数据库管理员的工具。它作为整个团队的沟通工具。产品经理、前端开发人员和 QA 工程师都从理解数据结构中受益。
当利益相关者审查 ERD 时,他们可以及早发现潜在问题:
- 功能可行性:数据库能否支持所请求的功能?如果不能,需要做哪些更改?
- 性能预期:该设计是否支持大规模下的高效查询?
- 安全需求:敏感字段是否已被识别并得到保护?在数据层面实现访问控制是否可行?
这种共同理解减少了冲刺规划中的摩擦。团队不再猜测数据流动方式,而是基于可视化模型进行讨论。分歧通过参考图表来解决,而非凭主观意见。
可扩展性考虑 📈
随着您的应用程序不断增长,您的数据模型也必须随之演变。ERD 帮助您预见这些变化。它使您能够可视化添加新实体对现有关系的影响。
设计时需要考虑的关键可扩展性因素:
- 索引策略:识别哪些列将被频繁查询。为这些字段规划索引,以加快检索速度。
- 分区:某些表是否会变得过大?如有必要,请规划水平分区。
- 读写分离:该设计是否支持独立的读取和写入副本?确保外键不会使复制变得复杂。
- 缓存层:数据模型如何与缓存系统交互?不可变数据比频繁变化的数据更容易缓存。
尽早考虑扩展性可以避免日后完全重写。添加新表比将数据从一台服务器迁移到另一台服务器要容易得多。
关于数据架构的最后思考 🧠
在创建详细ERD上投入的努力,将在项目的整个生命周期中带来回报。它将数据建模从被动的任务转变为战略资产。通过可视化关系、强制约束并规划增长,您将构建出稳健且易于维护的系统。
不要把数据库当作事后考虑的问题。它是您应用程序的基础。在设计阶段投入精力,从长远来看,您将节省数周的后端工作。ERD 的无声力量在于它能够预防问题的发生,而无需等到问题出现。
从今天开始绘制您的数据。您获得的清晰度,将决定代码库是混乱无序还是井然有序。