











Diseñar modelos de datos en una arquitectura de microservicios requiere un cambio fundamental en el pensamiento en comparación con las aplicaciones monolíticas. En un sistema tradicional, un único Diagrama de Relación de Entidades (ERD) suele cubrir toda la base de datos. En un entorno distribuido, esa visión única se fragmenta en múltiples esquemas independientes. El desafío radica en mantener la coherencia sin acoplar los servicios entre sí. Esta guía explora cómo estructurar eficazmente los modelos de datos, asegurando escalabilidad y resiliencia, al tiempo que se evitan los problemas comunes de la gestión de datos distribuidos.
Cuando los servicios comparten datos directamente, heredan las dependencias mutuas. Esta acoplamiento estrecho conduce a sistemas frágiles en los que un cambio en una área provoca fallos en otra. El objetivo es crear fronteras que permitan a los equipos desplegarse de forma independiente. Alcanzar esto requiere una planificación cuidadosa de las relaciones, modelos de consistencia y patrones de integración.
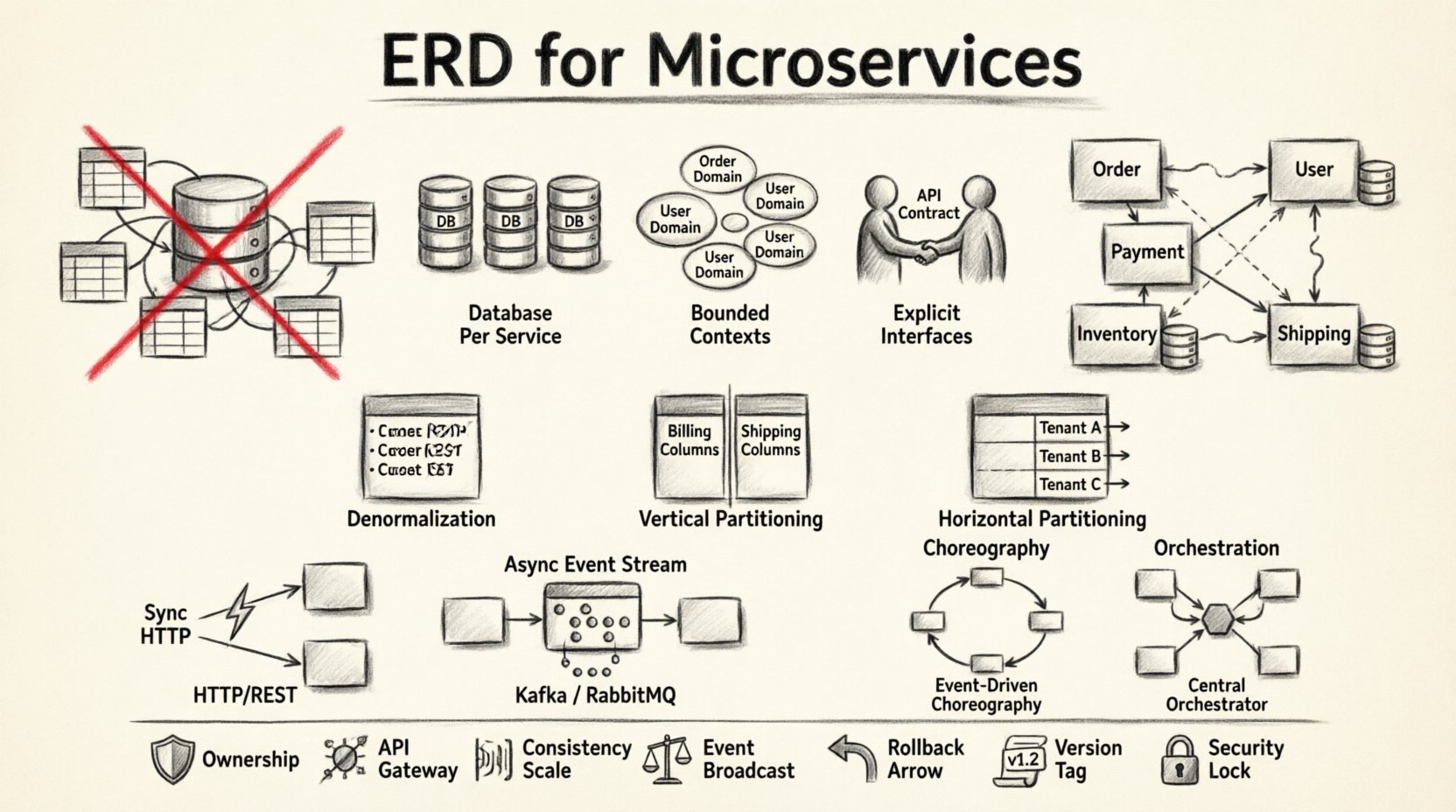
🧱 ¿Por qué los ERD tradicionales fallan en sistemas distribuidos?
Un ERD estándar asume una autoridad central. Representa tablas, columnas y claves foráneas dentro de un único límite transaccional. Los microservicios rechazan esta centralización. Cuando aplicas una mentalidad de ERD monolítica a un sistema distribuido, arriesgas crear un monolito distribuido. Esto ocurre cuando los servicios dependen de tablas de base de datos compartidas en lugar de APIs definidas.
Las siguientes cuestiones suelen surgir al ignorar estos principios:
- Acoplamiento de despliegue:Los cambios en una tabla compartida requieren despliegues simultáneos en múltiples servicios.
- Límites transaccionales:Las transacciones ACID abarcan múltiples servicios, aumentando la latencia y los puntos de fallo.
- Bloqueo de esquemas:Los bloqueos de base de datos en un servicio pueden detener solicitudes en otro servicio.
- Problemas de visibilidad:Ningún equipo posee el estado global de los datos, lo que conduce a silos de datos.
En lugar de un único diagrama, necesitas una colección de esquemas específicos para cada servicio que se comuniquen mediante interfaces bien definidas. Este enfoque prioriza la autonomía sobre la consistencia inmediata.
🧬 Principios Fundamentales de Modelado de Datos Distribuidos
Para mantener el orden, debes adherir a principios arquitectónicos específicos. Estas pautas ayudan a los equipos a tomar decisiones sobre la propiedad de los datos y los patrones de acceso.
1. Base de datos por servicio
Cada microservicio debe poseer su propio almacén de datos. Esto garantiza que el esquema interno de un servicio no sea visible para otros. Si el Servicio A necesita datos del Servicio B, debe solicitarlos a través de una API, no consultando directamente la base de datos. Esta aislamiento protege la integridad de cada dominio.
- Los servicios gestionan su propia evolución de esquemas.
- Los equipos pueden elegir la mejor tecnología de base de datos para sus necesidades específicas (persistencia políglota).
- Un fallo en una base de datos no hace que toda la aplicación se detenga.
2. Contextos acotados
Los datos deben alinearse con las capacidades del negocio. En el diseño centrado en dominios, un Contexto Acotado define el límite semántico de un modelo. Dos servicios podrían usar el término «Cliente», pero los datos dentro de esos contextos difieren. Uno podría almacenar detalles de contacto, mientras que el otro guarda el historial financiero. Combinarlos en un único ERD genera confusión y deuda técnica.
3. Interfaces explícitas
Dado que los servicios no pueden ver directamente los datos de otros, la API se convierte en el contrato de datos. El esquema de la respuesta de la API define la realidad de los datos para el consumidor. Esto desacopla la implementación interna de almacenamiento de la consumición externa.
📐 Patrones de diseño de esquemas para la independencia
Diseñar esquemas para microservicios implica patrones específicos para manejar relaciones que tradicionalmente se gestionarían mediante claves foráneas. No puedes depender de restricciones a nivel de base de datos para imponer relaciones entre servicios.
Denormalización
En un monolito, la normalización reduce la redundancia. En microservicios, a menudo se prefiere la denormalización. Almacenar datos duplicados reduce la necesidad de llamadas remotas. Por ejemplo, un servicio de Pedidos podría almacenar el Nombre y Dirección del Cliente dentro del registro del pedido. Esto evita una búsqueda síncrona al servicio de Usuarios cada vez que se muestra un pedido.
- Beneficio: Mejor rendimiento de lectura y menos saltos de red.
- Riesgo:Inconsistencia de datos si los datos de origen cambian. Debe manejar las actualizaciones mediante eventos.
Particionamiento vertical
Divida las tablas grandes en conjuntos más pequeños y enfocados. Si una tabla contiene información de facturación y direcciones de envío, separe estas preocupaciones. Los datos de facturación podrían pertenecer a un servicio de Pagos, mientras que las direcciones de envío pertenecen a un servicio de Logística. Esto reduce el área de superficie para cambios y mejora la seguridad limitando el acceso.
Particionamiento horizontal
Divida los datos según el ID de cliente o la región geográfica. Esto es útil para escalar servicios específicos sin afectar a otros. Le permite replicar servicios para regiones con alta demanda mientras mantiene otros ligeros.
| Patrón | Mejor caso de uso | Consideración clave |
|---|---|---|
| Denormalización | Cargas de trabajo con muchas lecturas | Requiere lógica de sincronización |
| Particionamiento vertical | Dominios distintos | Límites claros de la API |
| Particionamiento horizontal | Alta escala / Multi-tenencia | Complejidad de la lógica de enrutamiento |
🔄 Manejo de relaciones y consistencia
La parte más difícil del modelado de datos de microservicios es mantener la consistencia sin transacciones distribuidas. Debe elegir entre consistencia fuerte y consistencia eventual.
Comunicación síncrona
Los servicios pueden llamarse directamente entre sí mediante HTTP o gRPC. Esto proporciona consistencia fuerte para operaciones inmediatas. Sin embargo, introduce latencia y crea una cadena de dependencias. Si el servicio A llama al servicio B, y el servicio B está caído, el servicio A falla.
Comunicación asíncrona
Los servicios se comunican mediante colas de mensajes o flujos de eventos. Esto desacopla el momento de las operaciones. El servicio A publica un evento, y el servicio B lo consume más tarde. Esto apoya la consistencia eventual.
- Pros:Resiliencia, escalabilidad y acoplamiento débil.
- Contras:Los datos son temporalmente inconsistentes. Depurar requiere rastrear entre múltiples registros.
🗓️ El patrón Saga para la integridad de los datos
Una saga es una secuencia de transacciones locales. Cada transacción actualiza la base de datos local y publica un evento para desencadenar el siguiente paso. Si un paso falla, la saga ejecuta transacciones compensatorias para deshacer los cambios anteriores.
Coreografía frente a Orquestación
Las sagas se pueden implementar de dos formas:
- Coreografía:Los servicios escuchan eventos y deciden qué hacer a continuación. No hay un controlador central. Esto es flexible, pero más difícil de visualizar.
- Orquestación:Un coordinador central indica a los servicios qué hacer. Esto proporciona una mejor visibilidad y control sobre el flujo de trabajo, pero introduce un punto único de fallo.
Al modelar diagramas ERD para sagas, debes tener en cuenta los cambios de estado. Cada servicio involucrado en una saga debe almacenar su estado para manejar los reembolsos. Esto significa que tu esquema debe soportar estados transaccionales, no solo datos finales.
📝 Gestión de la evolución de esquemas
La evolución de esquemas es inevitable. Los campos cambian, los tipos se modifican y las restricciones se aflojan. En un sistema distribuido, no puedes modificar un esquema de base de datos mientras otros servicios dependan de él. Debes planificar la versión.
Compatibilidad hacia atrás
Mantén siempre la compatibilidad hacia atrás. Al agregar un nuevo campo, no elimines el antiguo de inmediato. Permite que los consumidores migren gradualmente. Si debes cambiar el nombre de un campo, crea un alias del nombre antiguo al nuevo durante el período de transición.
Estrategias de versionado
- Versionado en la URI:Incluye números de versión en la ruta de la API.
- Versionado mediante encabezados:Utiliza encabezados personalizados para especificar la versión esperada del esquema.
- Negociación de contenido:Utiliza encabezados HTTP estándar para solicitar tipos de medios específicos.
La documentación debe mantenerse sincronizada con el código. Las pruebas automatizadas deben verificar que el contrato de la API coincida con el esquema. Esto evita que los cambios que rompen la funcionalidad lleguen a producción.
🛡️ Errores comunes que debes evitar
Aunque se tenga un plan sólido, los equipos a menudo tropiezan con problemas específicos. Conocer estos errores ayuda a diseñar un sistema robusto.
1. La trampa de la base de datos compartida
No compartas tablas entre servicios. Esto crea un acoplamiento oculto. Si el servicio de Pagos lee la tabla del servicio de Pedidos, conoce demasiado sobre la estructura interna. Esto conduce a un acoplamiento fuerte y conflictos en la implementación.
2. Sobre-normalización
Intentar normalizar los datos entre servicios conduce a un exceso de combinaciones y llamadas de red. Acepta cierta redundancia. Es mejor tener datos duplicados que un sistema lento y acoplado.
3. Ignorar la idempotencia
Las llamadas de red fallan. Los mensajes se duplican. Tu esquema y lógica de la API deben manejar solicitudes duplicadas sin causar errores. Diseña tus puntos finales para que sean idempotentes, de modo que volver a intentar una solicitud no cree registros duplicados.
4. Falta de observabilidad
Cuando los datos están distribuidos, no puedes consultar una sola base de datos para rastrear una transacción. Necesitas rastreo distribuido y registro centralizado. Tu esquema debe incluir identificadores de correlación para rastrear las solicitudes a través de los límites de los servicios.
📋 Lista de verificación de gobernanza
Antes de implementar un nuevo servicio, revise la siguiente lista de verificación para asegurarse de que su modelo de datos sea sólido.
- Propiedad: ¿Hay un único servicio responsable de estos datos?
- Interfaz: ¿Los datos se exponen únicamente a través de una API?
- Consistencia: ¿Se documenta el modelo de consistencia (fuerte frente a eventual)?
- Eventos: ¿Se publican los cambios de estado como eventos para otros servicios?
- Compensación: ¿Existe un mecanismo de reversión para transacciones fallidas?
- Versionado: ¿Se realiza el versionado del esquema para manejar cambios futuros?
- Seguridad: ¿Los datos sensibles están cifrados en reposo y en tránsito?
🔍 Visualización de la arquitectura
Aunque no puedes dibujar un único ERD para todo el sistema, puedes crear un mapa de alto nivel. Este mapa muestra los servicios y sus límites de datos, no columnas específicas.
- Dibuja cuadros para cada servicio.
- Etiqueta el dominio de datos dentro del cuadro (por ejemplo, “Datos del perfil de usuario”).
- Dibuja flechas para las llamadas a la API que indican el flujo de datos.
- Indica los flujos de eventos por separado de los flujos de solicitud/respuesta.
Esta ayuda visual ayuda a los interesados a comprender el flujo de información sin quedar atrapados en los detalles técnicos del esquema. Sirve como herramienta de comunicación para arquitectos y analistas de negocios.
🚀 Conclusión
Diseñar ERDs para microservicios no se trata de dibujar líneas entre tablas. Se trata de definir límites entre capacidades empresariales. Al adoptar una base de datos por servicio, aceptar la consistencia eventual y gestionar rigurosamente las APIs, puedes construir sistemas escalables. El caos de los datos distribuidos es manejable con disciplina y contratos claros. Enfócate en la autonomía, minimiza el acoplamiento y asegúrate de que cada servicio posea completamente sus datos.
Recuerda que el modelado de datos es un proceso iterativo. A medida que los servicios crezcan, tu esquema necesitará evolucionar. Revisa periódicamente tu arquitectura frente a estos principios para mantener un sistema sano y resiliente.