








Diseñar un modelo de datos robusto no es meramente un ejercicio académico; es la base sobre la cual descansa la estabilidad de la aplicación. Un diagrama de entidades y relaciones (ERD) sirve como plano de construcción para cómo se almacena, vincula y recupera la información dentro de un entorno de producción. Cuando los sistemas crecen, el costo de una mala modelización se vuelve exponencial. Esta guía examina una implementación práctica de un ERD dentro de una arquitectura de backend compleja, centrándose en la integridad de los datos, la escalabilidad y la mantenibilidad.
Con demasiada frecuencia, los desarrolladores se enfocan en la lógica de la aplicación mientras tratan la base de datos como una preocupación secundaria. Sin embargo, el esquema determina los límites de lo que el sistema puede hacer de manera eficiente. Al analizar un escenario del mundo real, podemos comprender las compensaciones involucradas en la normalización de datos, el manejo de relaciones y la garantía de integridad referencial sin depender de proveedores de software específicos.
📋 El escenario empresarial
Considere una plataforma de servicios multi-tenencia diseñada para gestionar proyectos colaborativos. El sistema requiere una aislamiento estricto entre diferentes organizaciones de clientes, al tiempo que permite flexibilidad interna dentro de esas organizaciones. Los requisitos fundamentales incluyen:
- Multi-tenencia:Los datos deben estar segregados por organización para garantizar la seguridad.
- Flujos de trabajo complejos:Las tareas deben asignarse, rastrearse y vincularse a proyectos específicos.
- Registros de auditoría:Cada cambio significativo en un registro debe ser registrado para cumplir con los requisitos de cumplimiento.
- Escalabilidad:El esquema debe soportar millones de registros sin degradar el rendimiento de las consultas.
El desafío radica en traducir estas reglas empresariales en una estructura relacional que prevenga anomalías de datos. Un error común es crear estructuras sobrenormalizadas que requieren uniones excesivas, o estructuras sobredenormalizadas que provocan redundancia de datos y anomalías de actualización.
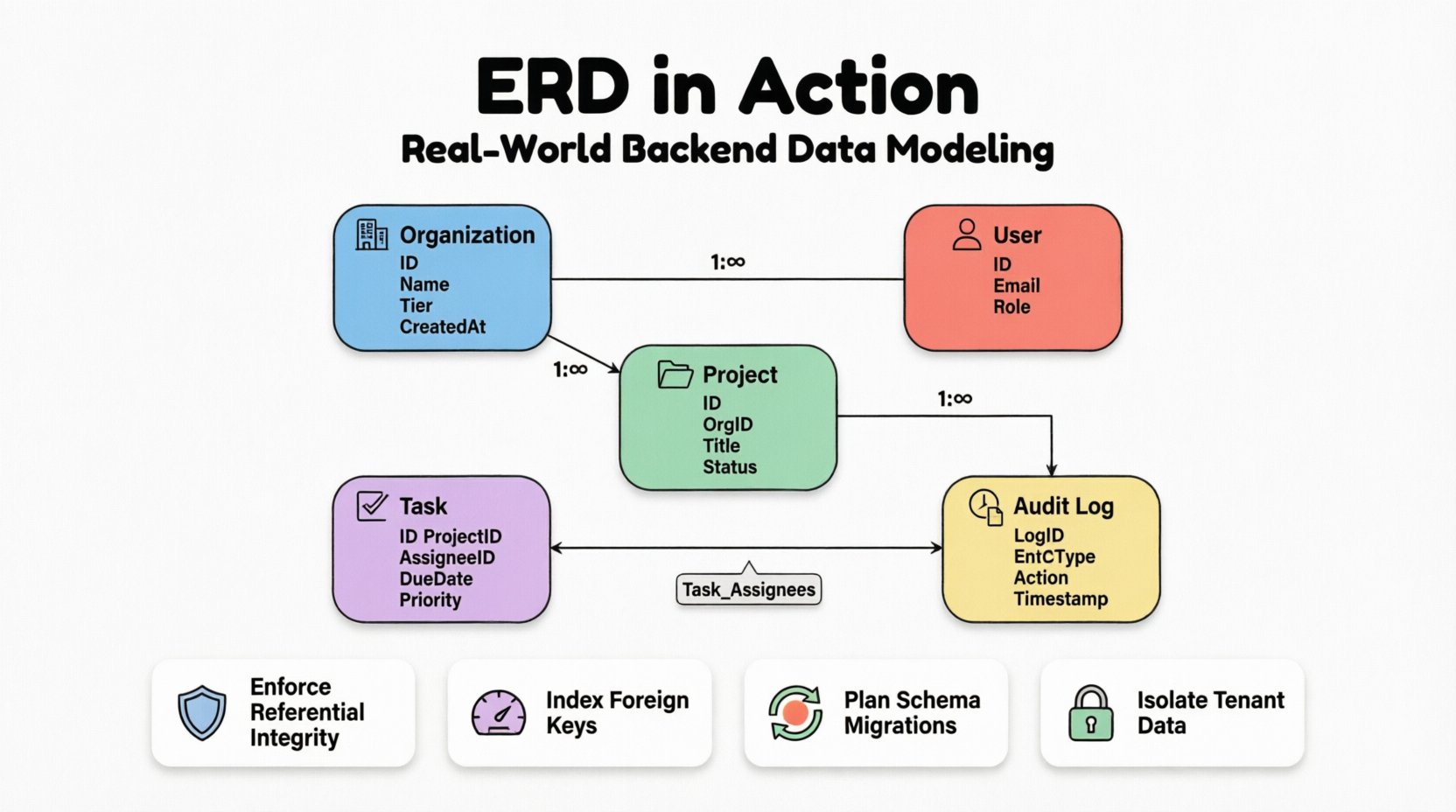
🔍 Entidades y atributos principales
La columna vertebral de cualquier ERD es la definición de entidades. En este estudio de caso, identificamos cinco entidades principales. Cada entidad representa un concepto distinto que debe persistirse en la base de datos. Los atributos asociados a estas entidades definen el nivel de granularidad de los datos almacenados.
1. Entidad Organización
Esta es la raíz de la jerarquía. Cada uno de los demás registros está vinculado a esta entidad para garantizar el aislamiento del tenant.
- ID de organización:Identificador único.
- Nombre de organización:Etiqueta legible para humanos.
- Nivel de suscripción: Determina el acceso a las funciones.
- Creado en:Marca de tiempo para auditoría.
2. Entidad Usuario
Los usuarios pertenecen a organizaciones, pero pueden ser miembros de múltiples proyectos. Los detalles de autenticación se separan de los datos empresariales para cumplir con las mejores prácticas de seguridad.
- ID de usuario:Identificador único.
- Correo electrónico: Utilizado para autenticación y contacto.
- Hash de contraseña: Almacenamiento seguro para credenciales.
- Rol: Define permisos (Administrador, Miembro, Visor).
3. Entidad Proyecto
Los proyectos son los contenedores para los elementos de trabajo. Son propiedad de una organización pero trabajados por usuarios.
- ID de proyecto: Identificador único.
- ID de organización: Clave foránea que enlaza con el inquilino principal.
- Título: Nombre corto para el proyecto.
- Estado: Activo, Archivado o Eliminado.
4. Entidad Tarea
La unidad central de trabajo. Esta entidad requiere las relaciones más complejas ya que enlaza usuarios, proyectos y registros.
- ID de tarea: Identificador único.
- ID de proyecto: Clave foránea.
- ID del asignado: Clave foránea a Usuario.
- Fecha de vencimiento: Restricción temporal.
- Prioridad: Valor enumerado.
5. Entidad Registro de auditoría
Registra cada cambio realizado en entidades críticas. Esto garantiza la trazabilidad.
- ID de registro: Identificador único.
- Tipo de entidad: ¿Qué tabla fue afectada?
- ID del registro: ¿Qué fila fue afectada?
- Acción: Crear, actualizar, eliminar.
- Realizado por: ID de usuario.
- Marca de tiempo: Hora de la acción.
🔗 Modelado de relaciones y cardinalidad
Las relaciones definen cómo interactúan las entidades. En un sistema de producción, estas relaciones se imponen mediante claves foráneas. La cardinalidad (uno a uno, uno a muchos, muchos a muchos) determina cómo se consultan y actualizan los datos.
Organización a Usuario
Esta es una Uno a muchos relación. Una organización puede tener muchos usuarios, pero un registro de usuario está vinculado a una sola organización con fines de aislamiento de datos. Para evitar fugas de datos entre inquilinos, el organization_id es una clave foránea obligatoria en la tabla de Usuario.
Organización a Proyecto
Similarmente, esta es una Uno a muchos relación. Los proyectos no pueden existir sin una organización padre. Si se elimina una organización, se debe considerar cuidadosamente el comportamiento de cascada. En este caso, elegimos eliminar de forma suave los proyectos en lugar de eliminarlos completamente, para preservar el contexto histórico.
Proyecto a Tarea
Otra Uno a muchos relación. Un proyecto contiene múltiples tareas, y una tarea pertenece a exactamente un proyecto. Esta es una conexión estructural estándar.
Usuario a Tarea (Asignación)
Esta es la relación más crítica. Un usuario puede tener asignadas múltiples tareas, y una tarea puede estar asignada a múltiples usuarios (trabajo colaborativo). Esto requiere una Muchos a muchos relación.
Para implementarlo, introducimos una tabla de unión, a menudo llamada entidad asociativa. Esta tabla divide la relación muchos a muchos en dos relaciones uno a muchos.
| Nombre de la tabla | Propósito | Claves |
|---|---|---|
| Tarea_Asignados | Enlaza usuarios con tareas | ID_Tarea, ID_Usuario |
| Organización_Inquilinos | Enlaza organizaciones con usuarios | ID_Organización, ID_Usuario |
Usar una tabla de unión nos permite almacenar metadatos adicionales. Por ejemplo, en la tabla Tarea_Asignados tabla, podríamos almacenar el rol que el usuario tenía en esa tarea específica (por ejemplo, Líder, Colaborador), que difiere de su rol de usuario global.
⚖️ Restricciones e integridad de datos
La validación a nivel de aplicación no es suficiente. Las restricciones de base de datos actúan como la última línea de defensa contra la corrupción de datos. En un entorno de producción, las restricciones deben definirse a nivel de esquema.
Integridad referencial
Las claves foráneas garantizan que un registro en una tabla hija no pueda referenciar a un padre inexistente. Por ejemplo, una tarea no puede asignarse a un usuario que no exista en el sistema.
Sin embargo, los comportamientos de ON DELETE y ON UPDATE son decisiones críticas:
- CASCADE: Si se elimina un padre, se eliminan todos los hijos. Úselo para datos huérfanos que no tienen sentido sin el padre (por ejemplo, comentarios en una publicación eliminada).
- RESTRICT: Evita la eliminación si existen hijos. Úselo para prevenir la pérdida accidental de datos (por ejemplo, eliminar una organización que tenga registros de facturación activos).
- SET NULL: Si se elimina el padre, la columna de clave foránea en la tabla hija se convierte en NULL. Úselo cuando la relación sea opcional.
Restricciones de verificación
SQL estándar admite restricciones de verificación para aplicar reglas específicas del dominio. Ejemplos incluyen:
- Fecha de vencimiento: El
fecha_vencimientocolumna debe ser mayor que lacreado_encolumna. - Prioridad: El
prioridadla columna debe coincidir con una lista específica de valores permitidos (por ejemplo, Baja, Media, Alta). - Monto:Los campos financieros deben ser no negativos.
Restricciones únicas
Asegure la unicidad de los datos cuando sea necesario. Por ejemplo, una dirección de correo electrónico debe ser única en todo el sistema, o dentro de una organización específica, dependiendo del modelo de usuario. Una restricción única compuesta puede garantizar que un usuario solo se asigne a un proyecto específico una vez (evitando asignaciones duplicadas).
🚀 Rendimiento y estrategia de indexación
Un esquema bien diseñado es inútil si las consultas son lentas. La indexación es el mecanismo que permite a la base de datos encontrar datos rápidamente. Sin embargo, los índices conllevan un costo en términos de rendimiento de escritura y almacenamiento.
Identificación de patrones de consulta
Antes de crear índices, analice las operaciones de lectura más comunes. En nuestro estudio de caso, las consultas típicas incluyen:
- Buscar todas las tareas asignadas a un usuario específico.
- Buscar todos los proyectos dentro de una organización.
- Recuperar los registros de auditoría para un ID de entidad específico.
Colocación de índices
Las claves foráneas son los candidatos más comunes para la indexación. Si una consulta filtra con frecuencia por id_organizacion, un índice en esa columna es obligatorio. Sin él, la base de datos realiza una escaneo completo de la tabla, lo que degrada rápidamente a medida que crece la data.
Los índices compuestos son útiles para consultas que filtran por múltiples columnas. Por ejemplo, si el sistema busca con frecuencia tareas por id_proyecto Y estado, un índice compuesto sobre (project_id, estado) es más eficiente que dos índices separados.
Índices parciales
En escenarios donde solo se consulta con frecuencia un subconjunto de datos, los índices parciales ahorran espacio. Por ejemplo, si el sistema solo consulta para activo tareas, un índice que solo incluye filas donde estado = 'Activo' puede ser significativamente más pequeño y más rápido de recorrer que un índice sobre toda la tabla.
🛠️ Mantenimiento y evolución de esquemas
Los requisitos de software cambian. El esquema de la base de datos no es una excepción. Pasar de la versión A a la versión B requiere una planificación cuidadosa para evitar tiempos de inactividad y pérdida de datos. Este proceso a menudo se gestiona mediante scripts de migración.
Agregar columnas
Agregar una nueva columna generalmente es seguro. Si la columna permite valores nulos, las filas existentes no se ven afectadas. Si la columna requiere un valor predeterminado, asegúrese de que el valor predeterminado sea aplicable a todos los datos existentes para evitar violaciones de restricciones.
Eliminar columnas
Eliminar una columna es arriesgado. Es mejor marcar primero la columna como obsoleta. Esto permite a los desarrolladores eliminar las referencias a la columna en el código de la aplicación antes de eliminarla físicamente de la base de datos. Este enfoque en dos fases evita errores de aplicación durante la ventana de despliegue.
Renombrar columnas
Renombrar columnas rara vez se admite en versiones antiguas de bases de datos sin soluciones complejas. A menudo es mejor agregar una nueva columna con el nombre deseado, migrar los datos y luego eliminar la columna antigua. Esto garantiza que el esquema permanezca compatible con versiones anteriores durante la transición.
🚧 Obstáculos comunes en el diseño de ERD
Incluso arquitectos experimentados cometen errores. Comprender los obstáculos comunes ayuda a evitarlos durante la fase de diseño.
- Sobrenormalización:Dividir los datos en demasiadas tablas pequeñas hace que las consultas sean complejas y lentas. Equilibre la normalización con las necesidades de rendimiento de las consultas.
- Subnormalización:Almacenar los mismos datos en múltiples lugares (por ejemplo, repetir nombres de usuarios en cada registro de tarea) conduce a anomalías de actualización. Si un usuario cambia su nombre, debe actualizar cada entrada del registro.
- Dependencias circulares:Crear relaciones de clave foránea circulares puede provocar bloqueos durante la inserción o eliminación. Asegúrese de que el grafo de dependencias sea un grafo acíclico dirigido (DAG).
- Ignorar eliminaciones suaves:Eliminar registros de forma permanente elimina el historial. Implemente una columna de marca de tiempo
eliminado_enpara mantener los registros visibles para auditorías, mientras se ocultan de las vistas estándar. - Tipos de datos implícitos: Usar tipos genéricos como
VARCHAR(255)para todo desperdicia espacio. UseINTpara identificadores,BOOLEANOpara marcas de verificación y límites de longitud específicos para cadenas cuando sea apropiado.
✅ Mejores prácticas para ERD de producción
Para garantizar la longevidad y salud del sistema, adhiera a estas directrices:
- Documente las relaciones: El propio ERD es documentación. Asegúrese de que se mantenga actualizado con el esquema real. Las herramientas automatizadas pueden generar diagramas a partir de la base de datos para verificar la precisión.
- Estandarice las convenciones de nomenclatura: Use
snake_casepara tablas y columnas. Prefija las claves foráneas con el nombre de la relación (por ejemplo,organization_iden lugar de soloorg_id) para mayor claridad. - Use UUIDs frente a autoincremento: Para sistemas distribuidos, los UUID evitan problemas de colisión al fusionar bases de datos. Para sistemas de instancia única, los enteros autoincrementales son más compactos y más rápidos.
- Planee el crecimiento: Diseñe teniendo en cuenta la partición. Si se espera que una tabla crezca hasta miles de millones de filas, considere cómo se dividirá entre fragmentos o particiones según el
organization_id. - Revise los patrones de acceso: Revise periódicamente los registros de consultas lentas para identificar índices faltantes o uniones ineficientes.
🔄 El ciclo de vida de un esquema
Un ERD no es un documento estático. Evoluciona con el producto. El ciclo de vida sigue típicamente estas etapas:
- Fase de diseño: Elaboración del modelo inicial basado en los requisitos.
- Fase de implementación: Creando scripts de migración para construir el esquema.
- Fase de validación: Ejecutando pruebas de carga para verificar las suposiciones de rendimiento.
- Fase de iteración: Agregando nuevos campos o relaciones a medida que se añaden características.
- Fase de optimización: Refinando índices y restricciones basados en datos de producción.
Durante la fase de optimización, podrías descubrir que las suposiciones iniciales sobre la cardinalidad eran incorrectas. Por ejemplo, podrías encontrar que una Uno-a-muchos relación en realidad era una Muchos-a-muchos en la práctica, lo que requiere un cambio en el esquema hacia una tabla de unión. Esto destaca la importancia de la flexibilidad en el diseño.
🛡️ Consideraciones de seguridad en el diseño de esquemas
La seguridad de los datos está profundamente entrelazada con el diseño de esquemas. Las políticas de seguridad a nivel de fila (RLS) dependen a menudo de la estructura del diagrama ER para funcionar correctamente. Si el organization_id no está correctamente indexado y aplicado, un usuario de la Organización A podría consultar accidentalmente los datos de la Organización B.
Además, los datos sensibles deben separarse. Si el sistema maneja información de pagos, esos datos deberían residir idealmente en un esquema o tabla separada con controles de acceso más estrictos, en lugar de mezclarse con los metadatos generales del usuario. Esto limita el radio de daño en caso de una brecha.
📝 Resumen de las decisiones de diseño
La siguiente tabla resume las decisiones clave tomadas en este estudio de caso y la justificación detrás de ellas.
| Decisión | Opción A | Opción B (Seleccionada) | Razón |
|---|---|---|---|
| Multi-tenencia | Bases de datos separadas | Base de datos compartida, esquema compartido | Reducción de la sobrecarga operativa; más fácil de gestionar análisis entre inquilinos. |
| Eliminación de organizaciones | Eliminación permanente | Eliminación suave | Preserva los registros históricos de auditoría y evita la pérdida de datos para cumplir con normativas. |
| Asignaciones de tareas | Columna única | Tabla de unión | Permite múltiples asignados y rastrea roles específicos por asignación. |
| Claves primarias | Autoincremento | UUIDs | Soporta una arquitectura distribuida futura y una fusión de datos más sencilla. |
Construir un backend de producción requiere más que simplemente escribir código. Requiere una comprensión profunda de cómo fluyen los datos y cómo están estructurados. Un ERD es el mapa que guía este viaje. Al seguir estos principios, aseguras que el sistema permanezca estable, seguro y escalable a medida que crece el negocio.
Recuerda, el objetivo no es crear el diagrama más complejo posible, sino el que mejor satisfaga las necesidades de la aplicación al tiempo que minimiza la deuda técnica. La revisión continua y la adaptación son clave para mantener un ecosistema de datos saludable.