











Construir un sistema capaz de manejar millones de usuarios requiere más que hardware potente o código eficiente. La base radica en la propia estructura de datos. Un diagrama de entidades y relaciones (ERD) no es meramente un artefacto de documentación; es el plano maestro para la longevidad de su aplicación. Cuando los arquitectos diseñan para el crecimiento, anticipan la carga futura, la complejidad de las relaciones y la necesidad de integridad de datos. Un esquema bien construido evita que se acumule deuda técnica antes incluso de que se realice el primer commit.
Esta guía explora cómo abordar el diseño de diagramas de entidades y relaciones específicamente para entornos escalables. Cubriremos los fundamentos teóricos, los compromisos prácticos y los patrones estructurales que respaldan sistemas de alta capacidad sin comprometer la consistencia.
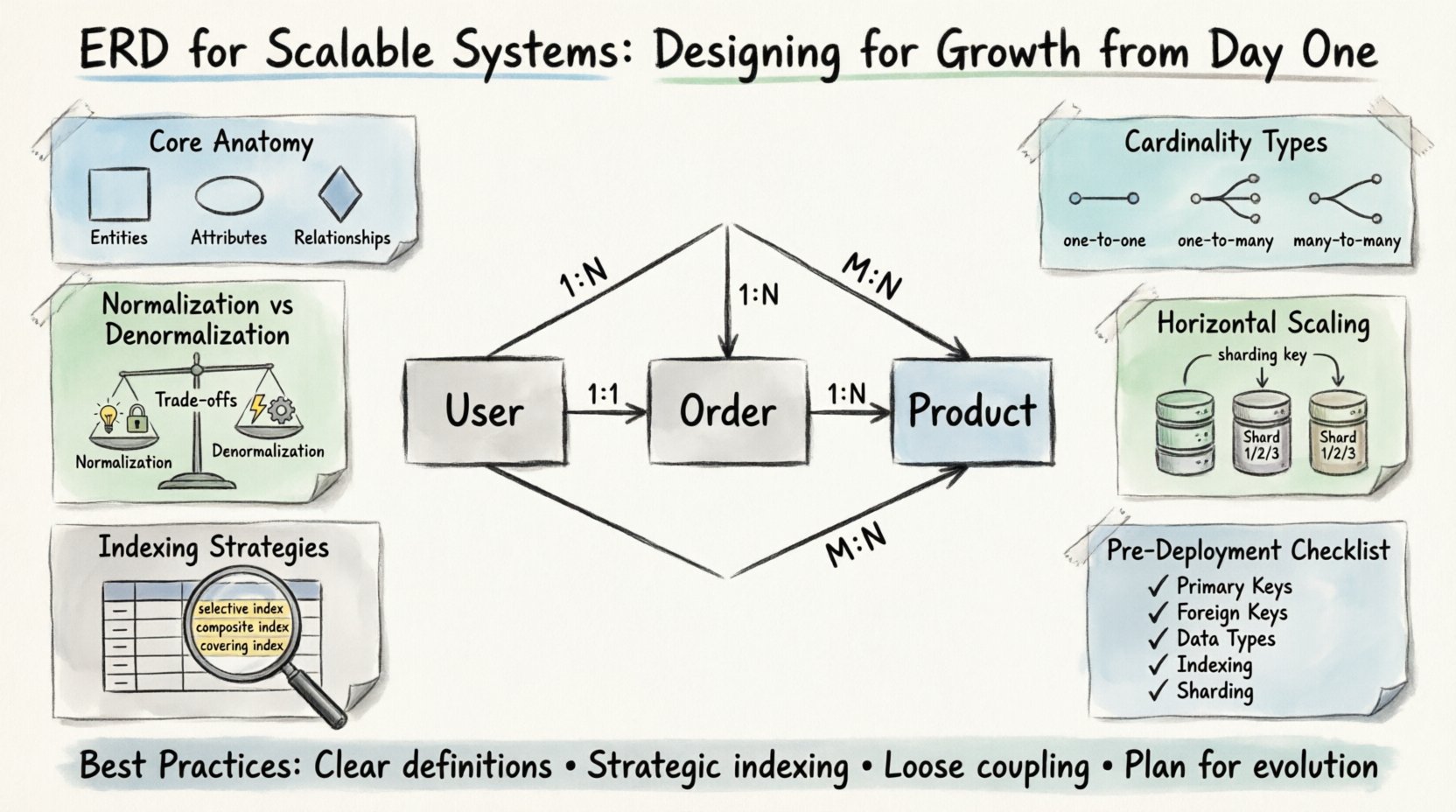
🧩 La anatomía central de un ERD escalable
Antes de considerar la escalabilidad, uno debe comprender los bloques fundamentales. Cada diagrama consta de entidades, atributos y relaciones. En un contexto escalable, estos elementos deben definirse con precisión para evitar cuellos de botella más adelante.
- Entidades:Estas representan los objetos centrales de su dominio empresarial. Ejemplos incluyen Usuarios, Pedidos y Productos. En sistemas de alto crecimiento, las entidades deben ser lo suficientemente granulares como para permitir una escalabilidad independiente, pero lo suficientemente cohesivas como para mantener límites lógicos.
- Atributos:Estos son las propiedades que describen a las entidades. Los tipos de datos son críticos aquí. Elegir el tipo correcto afecta la eficiencia de almacenamiento y el rendimiento de las consultas. Por ejemplo, usar un tipo entero dedicado para las IDs es superior a usar cadenas para fines de indexación.
- Relaciones:Estas definen cómo interactúan las entidades. La cardinalidad es el aspecto más importante que debe definirse desde el principio. Interpretar erróneamente una relación uno a muchos como muchos a muchos puede provocar uniones innecesarias y una degradación grave del rendimiento.
📐 Comprender la cardinalidad y las restricciones
La cardinalidad determina el número de instancias de una entidad que pueden o deben relacionarse con instancias de otra. En sistemas escalables, la elección de cardinalidad a menudo determina cómo se particiona los datos.
- Uno a uno (1:1):Rara vez se utiliza para optimización de rendimiento. A menudo implica dividir una entidad grande para reducir la contención de bloqueos. Úsese solo cuando los patrones de acceso a datos sean estrictamente distintos.
- Uno a muchos (1:N):La relación más común. Un Usuario tiene muchos Pedidos. Esta estructura permite un indexado eficiente en el lado de la clave foránea, lo que permite una recuperación rápida de los registros relacionados.
- Muchos a muchos (M:N):Requiere una tabla de unión. Aunque es flexible, puede convertirse en un cuello de botella de rendimiento a medida que crece el volumen de datos. Considere la desnormalización o vistas materializadas si la frecuencia de lectura es alta.
Al definir restricciones, considere la sobrecarga de su cumplimiento. En sistemas distribuidos, imponer restricciones estrictas de clave foránea entre fragmentos puede introducir latencia. En tales casos, puede ser necesario validar a nivel de aplicación para mantener el rendimiento del sistema mientras se preserva la integridad de los datos.
⚖️ Normalización frente a compromisos de rendimiento
La normalización reduce la redundancia y mejora la integridad de los datos. Sin embargo, los sistemas de alto rendimiento a menudo requieren una desviación de las reglas estrictas de normalización. Comprender las capas ayuda a tomar decisiones informadas.
- Primera Forma Normal (1FN):Valores atómicos. Asegura que cada celda contenga un solo valor. Esto es irrenunciable para la integridad relacional.
- Segunda Forma Normal (2FN):Sin dependencia parcial. Todos los atributos no clave deben depender de toda la clave primaria. Útil para reducir anomalías de actualización.
- Tercera Forma Normal (3FN):Sin dependencia transitiva. Los atributos no clave no deben depender de otros atributos no clave. Esta es la meta estándar para la mayoría de los sistemas transaccionales.
Aunque la 3FN es ideal para la consistencia, a menudo requiere uniones complejas. En sistemas con muchas lecturas, unirse a múltiples tablas puede sobrecargar el motor de base de datos. La desnormalización implica duplicar datos para reducir la necesidad de uniones. Esto aumenta la complejidad de escritura, pero acelera significativamente las lecturas.
📊 Comparación entre normalización y desnormalización
| Característica | Normalizado (3FN) | Denormalizado |
|---|---|---|
| Integridad de datos | Alta (fuente única de verdad) | Más baja (requiere lógica de sincronización) |
| Rendimiento de escritura | Más rápido (menos datos escritos) | Más lento (escrituras redundantes) |
| Rendimiento de lectura | Más lento (requiere combinaciones) | Más rápido (acceso directo) |
| Uso de almacenamiento | Eficiente | Más alto (redundancia) |
| Caso de uso | Sistemas transaccionales (OLTP) | Informes y análisis (OLAP) |
🚀 Diseñando para escalabilidad horizontal
A medida que crece el volumen de datos, un único nodo de base de datos se convierte en un cuello de botella. La escalabilidad horizontal implica agregar más nodos para distribuir la carga. Su ERD debe soportar esta arquitectura desde el principio.
- Claves de fragmentación:Identifique una columna que permita dividir los datos de forma equilibrada entre los fragmentos. Esta columna debe estar presente en cada consulta que acceda a los datos. Si una consulta requiere escanear todos los fragmentos, el rendimiento sufrirá.
- Claves foráneas entre fragmentos:Unir tablas que residen en fragmentos diferentes es computacionalmente costoso. Minimice las relaciones entre fragmentos en la fase de diseño. Si una relación es necesaria, considere almacenar en caché los datos de referencia.
- Identificadores globales:Utilice identificadores únicos que no dependan de contadores autoincrementales, ya que estos pueden causar contención. Se prefieren UUIDs o generadores de identificadores distribuidos.
Al modelar para fragmentación, considere la distribución de los datos. Los puntos calientes ocurren cuando un fragmento recibe tráfico significativamente mayor que los demás. Analice los patrones de acceso para asegurarse de que la clave de fragmentación coincida con los filtros de consulta más frecuentes.
📑 Estrategias de indexación para conjuntos de datos grandes
Los índices son esenciales para el rendimiento de las consultas, pero conllevan un costo. Cada índice consume almacenamiento y ralentiza las operaciones de escritura. Un enfoque estratégico para la indexación es vital.
- Índices selectivos: Cree índices en columnas que filtran los datos de forma significativa. Una columna con baja cardinalidad (por ejemplo, género) suele ser un candidato pobre para un índice principal.
- Índices compuestos: Combine múltiples columnas en un orden que coincida con los patrones de consulta. Se aplica la regla del prefijo más a la izquierda, lo que significa que la primera columna del índice debe coincidir con la consulta para que el índice se utilice de forma eficaz.
- Índices cubrientes: Incluya todas las columnas requeridas por una consulta dentro del índice mismo. Esto permite que la base de datos satisfaga la consulta sin acceder a los datos de la tabla, lo que se conoce como una operación de “cubrimiento”.
- Índices parciales: Indexe solo un subconjunto de las filas de la tabla. Esto es útil para eliminaciones suaves o marcas de estado específicas, reduciendo el tamaño de la estructura del índice.
Revise regularmente los planes de ejecución de las consultas. Un índice que parece bueno en papel podría ser ignorado por el optimizador de consultas si las estadísticas están desactualizadas. El mantenimiento regular asegura que el motor de la base de datos tome decisiones óptimas.
🔄 Evolución y migraciones de esquema
Los sistemas no son estáticos. Los requisitos cambian, y el modelo de datos debe evolucionar. Pasar de la versión A a la versión B sin tiempo de inactividad es una habilidad crítica.
- Cambios aditivos:Agregar una columna o tabla es generalmente seguro. No rompe las consultas existentes. Este es el método preferido para introducir nuevas características.
- Operaciones de renombrar:Renombrar una columna es arriesgado. Requiere actualizar el código de la aplicación. Planee un período de desuso en el que se admitan tanto el nombre antiguo como el nuevo.
- Adición de restricciones:Agregar una restricción (como NOT NULL) a datos existentes puede fallar si ya existen datos. Valide primero los datos, y luego agregue la restricción en un paso separado.
- Compatibilidad hacia atrás: Asegúrese de que las nuevas versiones del esquema no rompan a los clientes existentes. Use banderas de características para activar la nueva lógica solo cuando el esquema esté listo.
🚫 Peligros comunes que deben evitarse
Incluso los diseñadores experimentados enfrentan problemas. Reconocer estos patrones temprano puede ahorrar una cantidad significativa de tiempo de ingeniería.
- Acoplamiento fuerte: Crear relaciones que obliguen a una sincronización estricta entre entidades no relacionadas. Mantenga los módulos débilmente acoplados para permitir despliegues independientes.
- Sobrediseño: Diseñar para escenarios que nunca podrían ocurrir. Enfóquese en el 80% de los casos de uso que generan el 90% del tráfico. La simplicidad facilita la mantenibilidad.
- Ignorar eliminaciones suaves: Las eliminaciones permanentes eliminan los datos de forma definitiva. Para rastros de auditoría o recuperación, use una marca de estado (por ejemplo, is_deleted) en lugar de la eliminación física.
- Problemas de consultas N+1: Fallar al anticipar cómo se recuperarán los datos. Planee la carga anticipada o la recuperación por lotes en la capa de acceso a datos para evitar un número excesivo de interacciones con la base de datos.
✅ Lista de verificación de diseño previa a la implementación
Antes de finalizar el esquema, revise esta lista de verificación para asegurar la preparación para escalar.
- ☐ Claves primarias:¿Todas las tablas cuentan con una clave primaria única e indexada?
- ☐ Claves foráneas:¿Las relaciones están definidas correctamente? ¿La cardinalidad es precisa?
- ☐ Tipos de datos:¿Se utilizan tipos numéricos para IDs y cantidades? ¿Los tipos de fecha están estandarizados?
- ☐ Nulabilidad:¿Los campos obligatorios están marcados como NOT NULL?
- ☐ Indexación:¿Las columnas que participan en consultas de alto tráfico están indexadas?
- ☐ Fragmentación (sharding):¿Existe una clave de fragmentación viable si se anticipa una escalabilidad horizontal?
- ☐ Restricciones:¿Las restricciones son necesarias para la lógica de negocio, o pueden gestionarse en la capa de aplicación?
- ☐ Documentación:¿El diagrama ERD se ha actualizado para reflejar la implementación final?
🛡️ Integridad de datos en entornos distribuidos
En una configuración distribuida, es más difícil garantizar las propiedades ACID (Atomicidad, Consistencia, Aislamiento, Durabilidad) entre nodos. Comprender las implicaciones para su ERD es crucial.
- Consistencia eventual:Acepte que los datos podrían ser temporalmente inconsistentes entre réplicas. Diseñe su aplicación para manejar este estado de forma adecuada.
- Idempotencia:Asegúrese de que las operaciones puedan repetirse sin efectos secundarios. Esto es vital ante fallas de red donde una escritura podría tener éxito pero la confirmación se pierda.
- Resolución de conflictos: Defina cómo manejar actualizaciones simultáneas del mismo registro. Las marcas de tiempo o los relojes vectoriales pueden ayudar a determinar la versión más reciente.
Al incorporar estas consideraciones en su Diagrama de Relaciones de Entidades, crea un sistema que no solo es funcional hoy, sino suficientemente robusto para el futuro. El costo de cambiar un esquema en producción es exponencialmente mayor que diseñarlo correctamente desde el principio.
🔍 Resumen de las mejores prácticas
Para recapitular, la escalabilidad exitosa depende de un enfoque disciplinado en el modelado de datos. Enfóquese en definiciones claras, normalización adecuada e indexación estratégica. Evite atajos que comprometan la integridad de los datos. Revise regularmente sus diagramas a medida que evoluciona el sistema. Un ERD estático es una carga; un modelo vivo es un activo.
Invierta tiempo en la fase de diseño. Le traerá dividendos en costos reducidos de mantenimiento y mayor confiabilidad del sistema. Sus usuarios nunca verán el diagrama, pero sentirán el rendimiento del sistema que respalda.