











डेटा मॉडलिंग को अक्सर संबंधों और एकाधिकारों को परिभाषित करने के एक स्थिर अभ्यास के रूप में देखा जाता है। हालांकि, एक एंटिटी रिलेशनशिप डायग्राम (ERD) केवल स्टोरेज के लिए एक नक्शा नहीं है; यह डेटाबेस इंजन द्वारा जानकारी को कैसे प्राप्त और संशोधित करने की दक्षता का सीधा निर्धारक है। हर रेखा जो खींची जाती है, हर संबंध जो परिभाषित किया जाता है, और हर डेटा प्रकार जो चुना जाता है, आपके प्रश्नों के निष्पादन योजना में तरंग डालता है। स्कीमा डिज़ाइन के पीछे के तकनीकी तत्वों को समझने से लोड के तहत धीरे-धीरे स्केल होने वाले प्रणालियों का निर्माण संभव होता है।
यह मार्गदर्शिका ERD संरचनाओं और प्रश्न प्रदर्शन के बीच तकनीकी संबंधों का अध्ययन करती है। हम बुनियादी परिभाषाओं से आगे बढ़कर विशिष्ट मॉडलिंग निर्णयों के संबंध में अध्ययन करेंगे कि वे संबंधित वातावरण में I/O संचालन, CPU उपयोग और लॉकिंग तंत्रों को कैसे प्रभावित करते हैं।
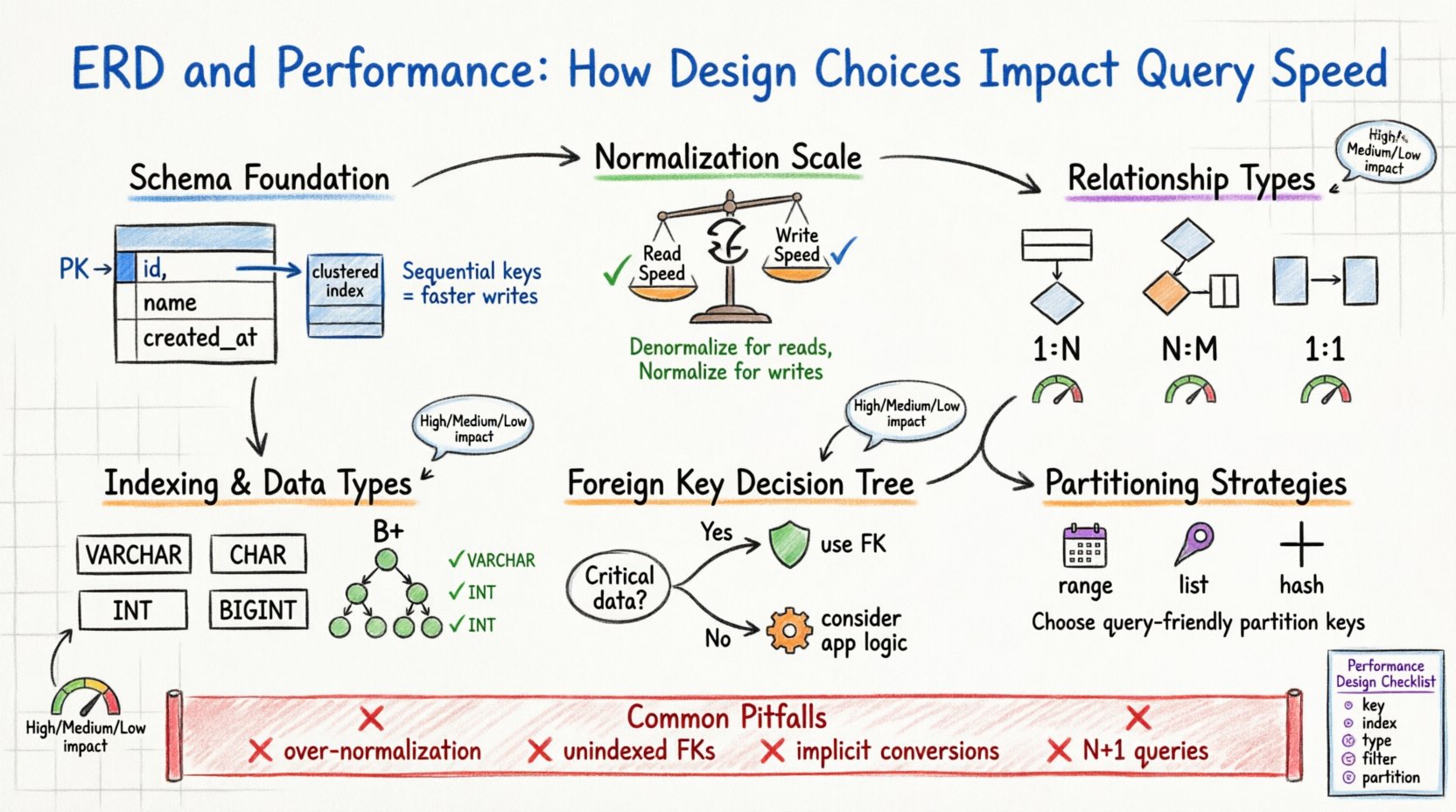
1. आधार: स्कीमा संरचना और भौतिक स्टोरेज 🏗️
आपके ERD में बनाए गए तार्किक डिज़ाइन का अंततः डिस्क पर भौतिक फ़ाइलों में रूपांतरण होता है। डेटाबेस इंजन को इन तार्किक एकाधिकारों को पेज, ब्लॉक और पंक्तियों में मैप करने की आवश्यकता होती है। जब स्कीमा अनुकूलित होता है, तो इंजन एक अनुरोध को पूरा करने के लिए आवश्यक डिस्क पढ़ने की संख्या को न्यूनतम करता है। जब ऐसा नहीं होता है, तो इंजन को पूरी टेबल स्कैन करने के लिए मजबूर किया जा सकता है, जो एक महंगा संचालन है।
प्राथमिक कुंजी के बारे में सोचें। यह एक पंक्ति के लिए एकमात्र पहचानकर्ता के रूप में कार्य करती है। बहुत से स्टोरेज इंजनों में, प्राथमिक कुंजी डिस्क पर डेटा के भौतिक क्रम को परिभाषित करती है (क्लस्टर्ड इंडेक्स)। एक क्रमिक और छोटी प्राथमिक कुंजी चुनने से यह सुनिश्चित होता है कि डेटा लगातार स्टोर हो। इससे विभाजन कम होता है और त्वरित रेंज स्कैन की अनुमति मिलती है। विपरीत रूप से, एक यादृच्छिक, लंबी प्राथमिक कुंजी इन्सर्ट के दौरान पेज विभाजन का कारण बन सकती है, जिससे लेखन प्रदर्शन खराब होता है और स्टोरेज अतिरिक्त लागत बढ़ती है।
प्राथमिक कुंजियों के लिए मुख्य विचार
- क्रमिकता:लेखन-भारी कार्यभार के लिए ऑटो-इनक्रीमेंटिंग पूर्णांक आमतौर पर प्राथमिकता दी जाती है।
- आकार:छोटी कुंजियाँ द्वितीयक सूचियों के आकार को कम करती हैं, क्योंकि उन्हें उन सूचियों में संकेतक के रूप में स्टोर किया जाता है।
- स्थिरता:प्राथमिक कुंजियों में बदलाव नहीं करना चाहिए। प्राथमिक कुंजी के अद्यतन के लिए आमतौर पर सभी संबंधित विदेशी कुंजियों के अद्यतन की आवश्यकता होती है।
2. सामान्यीकरण बनाम प्रदर्शन के विकल्प ⚖️
सामान्यीकरण डेटा को अतिरेक को कम करने और अखंडता में सुधार करने के लिए व्यवस्थित करने की प्रक्रिया है। जबकि इसे पारंपरिक रूप से डेटा गुणवत्ता से जोड़ा जाता है, यह प्रदर्शन पर गहन प्रभाव डालता है। एक अत्यधिक सामान्यीकृत स्कीमा (उदाहरण के लिए, तृतीय सामान्य रूप) आमतौर पर डेटा को पुनर्निर्माण करने के लिए अधिक जॉइन की आवश्यकता होती है, जबकि एक असामान्य स्कीमा जॉइन को कम करती है लेकिन स्टोरेज और अद्यतन की जटिलता बढ़ाती है।
सामान्यीकरण या असामान्यीकरण का निर्णय पढ़ने की गति और लेखन की गति के बीच संतुलन है। एक पढ़ने-भारी वातावरण में, असामान्यीकरण जटिल जॉइन के बचने से प्रश्न समय को महत्वपूर्ण रूप से कम कर सकता है। लेखन-भारी वातावरण में, सामान्यीकरण एक से अधिक टेबलों में अद्यतन करने की आवश्यकता वाली पंक्तियों की संख्या को कम करता है।
सामान्यीकरण प्रभाव विश्लेषण
| पहलू | अत्यधिक सामान्यीकृत | असामान्यीकृत |
|---|---|---|
| पढ़ने का प्रदर्शन | कम (जॉइन की आवश्यकता होती है) | अधिक (एकल टेबल पहुंच) |
| लेखन प्रदर्शन | अधिक (कम अतिरेक) | कम (बहुगुणा प्रतिलिपियों के अद्यतन) |
| डेटा अखंडता | उच्च (एकमात्र सत्य स्रोत) | कम (असंगति का जोखिम) |
| स्टोरेज उपयोग | निचला | उच्च |
3. विदेशी कुंजियाँ और अखंडता ओवरहेड 🔗
विदेशी कुंजियाँ संदर्भात्मक अखंडता को बल देती हैं। वे यह सुनिश्चित करती हैं कि एक तालिका में मान दूसरी तालिका में मान के साथ मेल खाता है। यह अनाथ रिकॉर्ड को रोकता है, लेकिन रनटाइम ओवरहेड लाता है। जब आप एक पंक्ति को सम्मिलित, अद्यतन या हटाते हैं, तो डेटाबेस को विदेशी कुंजी सीमा की जाँच करनी होती है।
इस जाँच की कीमत नहीं है। इंजन को संदर्भित पंक्ति को खोजना और उसके अस्तित्व की पुष्टि करना होता है। यदि संदर्भित तालिका बड़ी है और विदेशी कुंजी कॉलम पर सूची नहीं है, तो जाँच पूरी तालिका स्कैन बन जाती है। इसके अलावा, एक माता पिता रिकॉर्ड को हटाने के लिए इंजन को सभी बच्चे रिकॉर्ड की जाँच करनी होती है ताकि कोई संदर्भ बचा हुआ हो, जिससे बहुत सारी पंक्तियाँ लॉक हो सकती हैं।
विदेशी कुंजियों का उपयोग कब करें
- महत्वपूर्ण डेटा अखंडता: यदि डेटा सही होना अत्यंत महत्वपूर्ण है (उदाहरण के लिए, वित्तीय लेनदेन), तो विदेशी कुंजियों का उपयोग करें।
- एप्लिकेशन तर्क: यदि एप्लिकेशन तर्क जटिल है, तो अखंडता को डेटाबेस में सौंपने से कोड सरल हो जाता है।
- छोटे डेटासेट: छोटी तालिकाओं पर ओवरहेड नगण्य है।
विदेशी कुंजियों से कब बचें
- उच्च लेखन थ्रूपुट: सीमाओं को हटाने से लॉकिंग प्रतिस्पर्धा कम हो सकती है।
- बड़े पैमाने पर विश्लेषण: डेटा वॉर्हाउसिंग में, प्रदर्शन अक्सर सख्त अखंडता को बढ़ावा देता है।
- आर्किटेक्चरल परतें: माइक्रोसर्विसेज में, सेवा सीमाओं के पार विदेशी कुंजियों को बनाए रखना अक्सर अव्यावहारिक होता है।
4. इंडेक्सिंग रणनीतियाँ और कॉलम प्रकार 📑
एक ईआरडी प्रत्येक कॉलम के लिए डेटा प्रकार को परिभाषित करता है। VARCHAR और CHAR, या INT और BIGINT के बीच चयन करना डेटा के भंडारण और इंडेक्सिंग के तरीके को प्रभावित करता है। छोटे डेटा प्रकार कम मेमोरी और डिस्क स्थान का उपयोग करते हैं, जिससे बफर पूल (RAM) में अधिक डेटा फिट हो सकता है।
जब कोई प्रश्न किसी कॉलम पर फ़िल्टर करता है, तो डेटाबेस इंजन त्वरित रूप से पंक्तियों को खोजने के लिए इंडेक्स पर निर्भर करता है। यदि स्कीमा डिज़ाइन प्रश्न पैटर्न के साथ मेल नहीं खाता है, तो इंडेक्स बेकार हो जाते हैं। उदाहरण के लिए, एक कॉलम पर इंडेक्स बनाना जो WHERE क्लॉज में दुर्लभ रूप से उपयोग किया जाता है, संसाधनों का बर्बाद करना है।
कॉलम प्रकार अनुकूलन
- स्थिर लंबाई बनाम चर लंबाई: स्थिर लंबाई वाले डेटा (उदाहरण के लिए, देश कोड) के लिए CHAR का उपयोग करें ताकि फ्रैगमेंटेशन कम हो। चर लंबाई वाले डेटा के लिए VARCHAR का उपयोग करें।
- पूर्णांक सीमाएँ: यदि INT पर्याप्त है, तो BIGINT का उपयोग न करें। छोटे पूर्णांक प्रति पृष्ठ अधिक पंक्तियाँ फिट करते हैं।
- बूलियन प्रतिनिधित्व: ‘हाँ’/‘नहीं’ स्ट्रिंग्स को स्टोर करने के बजाय TINYINT(1) या BOOLEAN प्रकार का उपयोग करें।
5. संबंध बहुलता के प्रभाव 📊
संबंधों की आकारता (एक-से-एक, एक-से-बहुत, बहुत-से-बहुत) यह निर्धारित करती है कि डेटा कैसे जुड़ा है। प्रत्येक संबंध प्रकार की अलग-अलग प्रदर्शन विशेषताएं होती हैं।
एक-से-बहुत (1:N)
यह सबसे आम संबंध है। एक मुख्य तालिका में एक रिकॉर्ड होता है, और बच्चे की तालिका में बहुत सारे होते हैं। प्रदर्शन बच्चे की तालिका में विदेशी कुंजी कॉलम पर इंडेक्स पर बहुत निर्भर करता है। इस इंडेक्स के बिना, एक मुख्य तालिका के सभी बच्चों को खोजने के लिए पूरी बच्चे की तालिका को स्कैन करने की आवश्यकता होती है।
बहुत-से-बहुत (N:M)
इसके लिए एक जंक्शन तालिका (संबंधात्मक एकता) की आवश्यकता होती है। इससे अतिरिक्त एक अंतराल जोड़ा जाता है। N:M संबंधों वाले प्रश्नों को आमतौर पर तीन जॉइन की आवश्यकता होती है: तालिका A, जंक्शन तालिका, तालिका B। इस जटिलता से सीपीयू का उपयोग और मेमोरी की आवश्यकता बढ़ जाती है।
एक-से-एक (1:1)
आमतौर पर एक बड़ी तालिका को तार्किक समूहों में विभाजित करने के लिए उपयोग किया जाता है। यदि केवल एक स्तंभों के उपसमूह को अक्सर प्रश्न किया जाता है, तो यह प्रदर्शन में सुधार कर सकता है। हालांकि, यह पूरे रिकॉर्ड को प्राप्त करने के लिए जॉइन की लागत जोड़ता है।
6. पार्टीशनिंग और शैडिंग के विचार 🗃️
जैसे-जैसे डेटा बढ़ता है, एक ही तालिका प्रबंधन के लिए बहुत बड़ी हो सकती है। पार्टीशनिंग आपको एक बड़ी तालिका को एक कुंजी (उदाहरण के लिए, तारीख) के आधार पर छोटे, अधिक प्रबंधन योग्य टुकड़ों में विभाजित करने की अनुमति देती है। ईआरडी डिजाइन को इसकी अनुमति देनी चाहिए।
यदि आप एक प्रणाली के लिए स्कीमा डिजाइन कर रहे हैं जिसे अंततः शैड (कई सर्वरों पर विभाजित) किया जाएगा, तो पार्टीशन कुंजी का ध्यान से चयन करना आवश्यक है। कुंजी का आमतौर पर प्रश्नों में उपयोग किया जाना चाहिए ताकि इंजन को सही शैड तक अनुरोध राउट करने में सक्षम हो। उन कुंजी का चयन करना जो प्रश्नों में उपयोग नहीं किए जाते हैं, तो प्रणाली को सभी शैड से डेटा संग्रहीत करने के लिए मजबूर करता है, जो धीमा है।
पार्टीशनिंग रणनीतियां
- रेंज पार्टीशनिंग: तारीख या आईडी की सीमा के आधार पर विभाजित करें। समय-श्रृंखला डेटा के लिए अच्छा।
- सूची पार्टीशनिंग: विशिष्ट मानों (उदाहरण के लिए, क्षेत्र कोड) के आधार पर विभाजित करें।
- हैश पार्टीशनिंग: डेटा को बराबर रूप से वितरित करता है ताकि हॉटस्पॉट से बचा जा सके।
7. डिजाइन में सामान्य गलतियां 🚫
यहां तक कि अनुभवी वास्तुकार भी डिजाइन चयनों के माध्यम से प्रदर्शन के बॉटलनेक ला सकते हैं। इन पैटर्नों को जल्दी से पहचानने से बाद में महंगे रीफैक्टरिंग से बचा जा सकता है।
- अत्यधिक नॉर्मलाइजेशन: डेटा को बहुत अधिक छोटी तालिकाओं में विभाजित करने से जॉइन की जटिलता बढ़ जाती है और कैश दक्षता कम हो जाती है।
- चयनशीलता को नजरअंदाज करना: कम चयनशीलता वाले स्तंभों (उदाहरण के लिए, लिंग या स्थिति फ्लैग) पर इंडेक्स लगाने से अक्सर खराब प्रदर्शन मिलता है क्योंकि ऑप्टिमाइज़र इंडेक्स को नजरअंदाज कर सकता है और तालिका को फिर से स्कैन कर सकता है।
- गैर-प्रत्यक्ष रूपांतरण: जब नंबरिक मानों की अपेक्षा की जाती है, तो एक स्तंभ को स्ट्रिंग के रूप में डिजाइन करने से इंजन को प्रश्नों के दौरान प्रकारों के रूपांतरण करने के लिए मजबूर किया जाता है, जिससे इंडेक्स के उपयोग को रोका जाता है।
- एन+1 प्रश्न पैटर्न: लूप में डेटा लाने के लिए प्रोत्साहित करने वाले संबंधों को डिजाइन करना, बैच जॉइन के बजाय, सर्वर को ओवरलोड कर सकता है।
8. भविष्य के लिए सुरक्षा और विकास 🛡️
डेटाबेस विकसित होते हैं। आवश्यकताएं बदलती हैं, और नए फीचर जोड़े जाते हैं। आज प्रदर्शन करने वाला एक स्कीमा कल एक बॉटलनेक बन सकता है यदि इसमें लचीलापन की कमी हो। ईआरडी को बिना पूरी तरह से लिखने के बिना वृद्धि को स्वीकार करना चाहिए।
भविष्य में फ़िल्टरिंग के लिए उपयोग किए जाने वाले स्तंभों को जोड़ने के बारे में सोचें। इससे रो प्रतिशत थोड़ा बढ़ता है, लेकिन बाद में तालिका संरचना बदलने की लागत बचती है, जो बड़े डेटासेट पर एक महंगा ऑपरेशन हो सकता है। साथ ही, नए इंडेक्स जोड़ने के प्रभाव को भी ध्यान में रखें। प्रत्येक इंडेक्स लेखन संसाधन का उपयोग करता है। स्कीमा को आवश्यक इंडेक्स की संख्या को न्यूनतम करने के लिए डिजाइन करें।
प्रदर्शन के लिए डिज़ाइन चेकलिस्ट
- क्या प्राथमिक कुंजियाँ छोटी और क्रमिक हैं?
- क्या विदेशी कुंजियाँ सूचीबद्ध हैं?
- क्या डेटा प्रकार सबसे छोटा संभव मान्य प्रकार है?
- क्या अक्सर उपयोग होने वाले फ़िल्टर सूचियों द्वारा कवर किए गए हैं?
- क्या सामर्थ्य के लिए नॉर्मलाइज़ेशन स्तर उपयुक्त है?
- क्या आपने बड़ी तालिकाओं के लिए पार्टीशनिंग के बारे में सोचा है?
- क्या कोई कॉलम जटिल JSON या टेक्स्ट स्टोर कर रहे हैं जिन्हें संरचित किया जा सकता है?
9. निष्पादन योजना की भूमिका 📋
अंततः, डेटाबेस इंजन स्कीमा और सांख्यिकी के आधार पर एक क्वेरी को कैसे निष्पादित करना है, इसका निर्णय लेता है। ईआरडी इंजन द्वारा एकत्र की जाने वाली सांख्यिकी को प्रभावित करता है। उदाहरण के लिए, एक विशिष्ट मान वितरण वाले कॉलम को विषम डेटा वाले कॉलम के बजाय अलग तरीके से संभाला जाएगा। निष्पादन योजना कैसे काम करती है, इसकी समझ आपको यह समझने में मदद करती है कि क्वेरी क्यों धीमी है।
यदि कोई क्वेरी पूरी तालिका स्कैन करती है, तो यह अक्सर एक गायब सूची या एक डिज़ाइन का संकेत होता है जो कुशल फ़िल्टरिंग का समर्थन नहीं करता है। यदि यह बहुत सारे नेस्टेड लूप करती है, तो इसका मतलब है कि जटिल जॉइन हैं जिन्हें सरल बनाया जा सकता है। ईआरडी को अपेक्षित एक्सेस पैटर्न के साथ मिलाकर, आप इंजन को आदर्श निष्पादन योजनाओं की ओर मार्गदर्शन करते हैं।
10. अखंडता और गति के बीच संतुलन ⚖️
कोई आदर्श स्कीमा नहीं है। प्रत्येक डिज़ाइन चयन एक व्यापार के साथ आता है। लक्ष्य प्रदर्शन समस्याओं को खत्म करना नहीं है, बल्कि उन्हें रणनीतिक रूप से प्रबंधित करना है। कुछ मामलों में, डेटा असंगति के थोड़े जोखिम को स्वीकार करना (डेटाबेस सीमाओं के बजाय एप्लिकेशन-स्तरीय जांच के माध्यम से) चरम लेखन थ्रूपुट के लिए एक वैध व्यापार है।
अपने ईआरडी को वास्तविक क्वेरी लॉग्स के खिलाफ नियमित रूप से समीक्षा करें। सबसे धीमी क्वेरी को पहचानें और उन्हें स्कीमा तक वापस ट्रेस करें। इस फीडबैक लूप सुनिश्चित करता है कि आपका डिज़ाइन अपने एप्लिकेशन की आवश्यकताओं के साथ समानांतर विकसित होता रहे।
प्रभाव क्षेत्रों का सारांश 📝
| डिज़ाइन तत्व | प्रदर्शन प्रभाव | सिफारिश |
|---|---|---|
| प्राथमिक कुंजी प्रकार | उच्च (स्टोरेज और सूचीकरण) | निरंतर रूप से पूर्णांक या यूआरएल का उपयोग करें। |
| विदेशी कुंजियाँ | मध्यम (लेखन ओवरहेड) | एफके कॉलम को सूचीबद्ध करें; यदि अखंडता को अन्यत्र संभाला जाता है तो हटा दें। |
| नॉर्मलाइज़ेशन | उच्च (जॉइन जटिलता) | पढ़ने वाली तालिकाओं को अनॉर्मलाइज़ करें। |
| डेटा प्रकार | मध्यम (मेमोरी उपयोग) | उपलब्ध सबसे विशिष्ट प्रकार का उपयोग करें। |
| कार्डिनैलिटी | उच्च (जॉइन लागत) | एन:एम संबंधों के लिए जंक्शन तालिकाओं को अनुकूलित करें। |
एंटिटी रिलेशनशिप डायग्राम को केवल एक तार्किक मानचित्र के बजाय प्रदर्शन के लिए उपयोगी वस्तु के रूप में लेने से आप ऐसे प्रणालियां बना सकते हैं जो दृढ़, स्केलेबल और कुशल हों। आपके द्वारा अब लिए गए निर्णय आपके एप्लिकेशन के व्यवहार को भविष्य में वर्षों तक निर्धारित करेंगे।