











माइक्रोसर्विस आर्किटेक्चर में डेटा मॉडल डिज़ाइन करने के लिए एक मोनोलिथिक एप्लिकेशन की तुलना में एक मौलिक बदलाव की आवश्यकता होती है। एक पारंपरिक प्रणाली में, एक ही एंटिटी रिलेशनशिप डायग्राम (ERD) अक्सर पूरे डेटाबेस को कवर करता है। एक वितरित वातावरण में, वह एकल दृष्टिकोण बहुत स्वतंत्र स्कीमा में टूट जाता है। चुनौती यह है कि सेवाओं को एक साथ कपल न करते हुए सुसंगतता बनाए रखना। यह गाइड यह जांचता है कि डेटा मॉडल को कैसे प्रभावी ढंग से संरचित किया जाए, जिससे स्केलेबिलिटी और लचीलापन सुनिश्चित हो, और वितरित डेटा प्रबंधन के सामान्य जाल में फंसने से बचा जाए।
जब सेवाएं डेटा को सीधे साझा करती हैं, तो वे एक दूसरे के निर्भरता को विरासत में प्राप्त करती हैं। इस तंग कपलिंग के कारण बेहद नाजुक प्रणालियां बनती हैं, जहां एक क्षेत्र में बदलाव दूसरे को नष्ट कर देता है। लक्ष्य यह है कि सीमाएं बनाई जाएं जो टीमों को स्वतंत्र रूप से डेप्लॉय करने की अनुमति दें। इसे प्राप्त करने के लिए संबंधों, सुसंगतता मॉडलों और एकीकरण पैटर्नों की सावधानीपूर्वक योजना बनाने की आवश्यकता होती है।
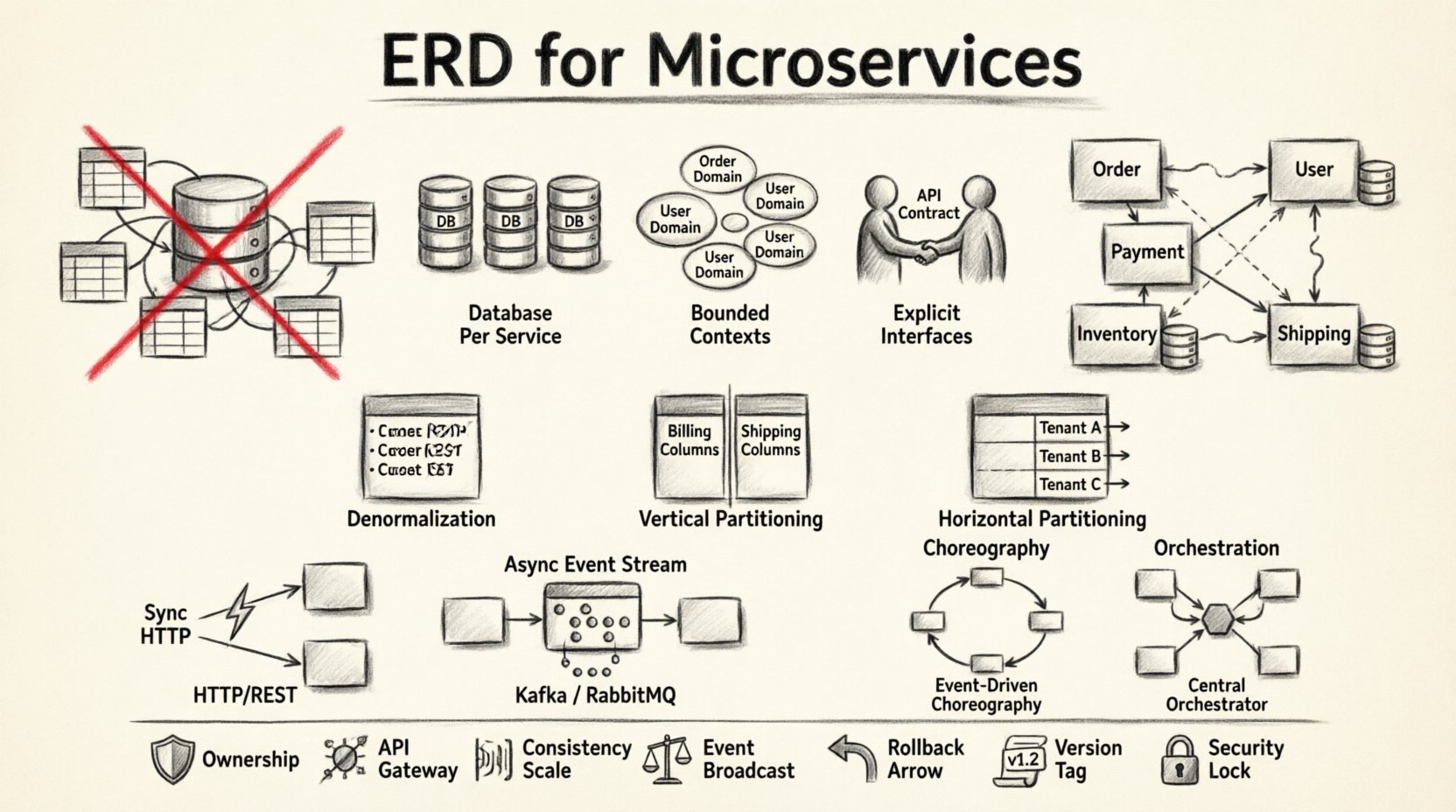
🧱 वितरित प्रणालियों में पारंपरिक ERD क्यों टूटते हैं
एक मानक ERD में केंद्रीय अधिकार की धारणा होती है। यह एकल लेनदेन सीमा के भीतर तालिकाओं, कॉलम और विदेशी कुंजियों को मैप करता है। माइक्रोसर्विसेज इस केंद्रीकरण को अस्वीकार करते हैं। जब आप एक वितरित प्रणाली पर मोनोलिथिक ERD के विचार को लागू करते हैं, तो आप एक वितरित मोनोलिथ बनाने का जोखिम उठाते हैं। यह तब होता है जब सेवाएं साझा डेटाबेस तालिकाओं पर निर्भर होती हैं, बजाय निर्धारित API के।
इन सिद्धांतों के उपेक्षा करने पर निम्नलिखित समस्याएं आमतौर पर उत्पन्न होती हैं:
- डेप्लॉयमेंट कपलिंग:एक साझा तालिका में बदलाव करने के लिए बहुत सेवाओं में एक साथ डेप्लॉयमेंट की आवश्यकता होती है।
- लेनदेन सीमाएं:एसीआईडी लेनदेन बहुत सेवाओं तक फैलते हैं, जिससे लेटेंसी और विफलता के बिंदु बढ़ जाते हैं।
- स्कीमा लॉकिंग:एक सेवा में डेटाबेस लॉक दूसरी सेवा में अनुरोधों को रोक सकते हैं।
- दृश्यता समस्याएं:कोई एक टीम ग्लोबल डेटा स्थिति के मालिक नहीं है, जिससे डेटा सिलो बनते हैं।
एकल डायग्राम के बजाय, आपको सेवा-विशिष्ट स्कीमा के संग्रह की आवश्यकता होती है, जो अच्छी तरह से परिभाषित इंटरफेस के माध्यम से संचार करते हैं। इस दृष्टिकोण में तुरंत सुसंगतता की तुलना में स्वायत्तता को प्राथमिकता दी जाती है।
🧬 वितरित डेटा मॉडलिंग के मूल सिद्धांत
क्रम को बनाए रखने के लिए, आपको विशिष्ट आर्किटेक्चरल सिद्धांतों का पालन करना होगा। इन दिशानिर्देशों में टीमों को डेटा स्वामित्व और एक्सेस पैटर्न के संबंध में निर्णय लेने में मदद मिलती है।
1. सेवा प्रति डेटाबेस
प्रत्येक माइक्रोसर्विस को अपना डेटा स्टोर होना चाहिए। इससे यह सुनिश्चित होता है कि किसी सेवा का आंतरिक स्कीमा दूसरों के लिए दृश्यमान नहीं होता है। यदि सेवा A को सेवा B से डेटा की आवश्यकता है, तो इसे API के माध्यम से मांगना चाहिए, डेटाबेस को सीधे प्रश्न नहीं करना चाहिए। इस अलगाव से प्रत्येक क्षेत्र की अखंडता की रक्षा होती है।
- सेवाएं अपने स्कीमा विकास का प्रबंधन करती हैं।
- टीमें अपनी विशिष्ट आवश्यकताओं के लिए सबसे अच्छी डेटाबेस तकनीक का चयन कर सकती हैं (बहुभाषी स्थिरता)।
- एक डेटाबेस में विफलता पूरे एप्लिकेशन को गिरा नहीं देती है।
2. सीमित संदर्भ
डेटा को व्यावसायिक क्षमताओं के साथ मेल बैठाना चाहिए। डोमेन-ड्राइवन डिज़ाइन में, एक सीमित संदर्भ मॉडल की अर्थपूर्ण सीमा को परिभाषित करता है। दो सेवाएं “ग्राहक” शब्द का उपयोग कर सकती हैं, लेकिन उन संदर्भों में डेटा भिन्न होता है। एक में संपर्क विवरण स्टोर किए जा सकते हैं, जबकि दूसरे में वित्तीय इतिहास स्टोर किया जा सकता है। इन्हें एक ही ERD में मिलाने से भ्रम और तकनीकी देनदारी उत्पन्न होती है।
3. स्पष्ट इंटरफेस
चूंकि सेवाएं एक दूसरे के डेटा को सीधे नहीं देख सकती हैं, इसलिए API डेटा अनुबंध बन जाता है। API प्रतिक्रिया का स्कीमा उपभोक्ता के लिए डेटा की वास्तविकता को परिभाषित करता है। इससे आंतरिक भंडारण कार्यान्वयन को बाहरी उपभोग से अलग किया जाता है।
📐 स्वतंत्रता के लिए स्कीमा डिज़ाइन पैटर्न
माइक्रोसर्विसेज के लिए स्कीमा डिज़ाइन करने में विशिष्ट पैटर्न शामिल होते हैं जो विदेशी कुंजियों द्वारा पारंपरिक रूप से संभाले जाने वाले संबंधों को संभालने के लिए होते हैं। आप सेवाओं के बीच संबंधों को बल देने के लिए डेटाबेस स्तरीय प्रतिबंधों पर भरोसा नहीं कर सकते हैं।
अनॉर्मलाइज़ेशन
एक मोनोलिथ में, नॉर्मलाइज़ेशन अतिरिक्तता को कम करता है। माइक्रोसर्विसेज में, अनॉर्मलाइज़ेशन को अक्सर प्राथमिकता दी जाती है। डुप्लीकेट डेटा स्टोर करने से दूरस्थ कॉल की आवश्यकता कम हो जाती है। उदाहरण के लिए, ऑर्डर सेवा ऑर्डर रिकॉर्ड के भीतर ग्राहक का नाम और पता स्टोर कर सकती है। इससे ऑर्डर को दिखाए जाने पर हर बार उपयोगकर्ता सेवा में सिंक्रोनस लुकअप से बचा जा सकता है।
- लाभ: तेज़ पढ़ने का प्रदर्शन और कम नेटवर्क हॉप्स।
- जोखिम: यदि स्रोत डेटा बदलता है तो डेटा असंगति हो सकती है। आपको घटनाओं के माध्यम से अपडेट को संभालना होगा।
ऊर्ध्वाधर विभाजन
बड़ी तालिकाओं को छोटे, लक्षित सेटों में विभाजित करें। यदि एक तालिका में बिलिंग जानकारी और शिपिंग पते दोनों हैं, तो इन चिंताओं को अलग करें। बिलिंग डेटा एक भुगतान सेवा में हो सकता है, जबकि शिपिंग पते लॉजिस्टिक्स सेवा में होंगे। इससे बदलाव के क्षेत्र को कम किया जाता है और पहुंच सीमित करके सुरक्षा में सुधार होता है।
क्षैतिज विभाजन
टेंटेंट आईडी या भौगोलिक क्षेत्र के आधार पर डेटा को विभाजित करें। यह किसी विशिष्ट सेवा को बिना अन्य के प्रभावित किए स्केल करने के लिए उपयोगी है। इससे उच्च ट्रैफिक वाले क्षेत्रों के लिए सेवाओं की प्रतिलिपि बनाने की अनुमति मिलती है, जबकि अन्य सेवाओं को हल्का रखा जा सकता है।
| पैटर्न | सर्वोत्तम उपयोग केस | मुख्य विचार |
|---|---|---|
| अनियमितता | पढ़ने पर अधिक आधारित कार्यभार | समन्वय तर्क की आवश्यकता होती है |
| ऊर्ध्वाधर विभाजन | अलग-अलग क्षेत्र | स्पष्ट API सीमाएं |
| क्षैतिज विभाजन | उच्च स्केल / बहु-टेंटेंसी | रूटिंग तर्क की जटिलता |
🔄 संबंधों और संगति का प्रबंधन
माइक्रोसर्विसेज डेटा मॉडलिंग का सबसे कठिन हिस्सा वितरित लेनदेन के बिना संगति बनाए रखना है। आपको मजबूत संगति और अंततः संगति के बीच चयन करने की आवश्यकता होती है।
समकालिक संचार
सेवाएं एचटीटीपी या gRPC के माध्यम से एक दूसरे को सीधे कॉल कर सकती हैं। इससे तुरंत संचालन के लिए मजबूत संगति मिलती है। हालांकि, यह लेटेंसी लाता है और निर्भरता श्रृंखला बनाता है। यदि सेवा A सेवा B को कॉल करती है और सेवा B बंद है, तो सेवा A विफल हो जाती है।
असमकालिक संचार
सेवाएं संदेश भंडार या घटना प्रवाह के माध्यम से संचार करती हैं। इससे संचालन के समय को अलग किया जाता है। सेवा A एक घटना प्रकाशित करती है, और सेवा B बाद में इसे स्वीकार करती है। इससे अंततः संगति का समर्थन होता है।
- लाभ: लचीलापन, स्केलेबिलिटी और कम निर्भरता।
- नुकसान: डेटा अस्थायी रूप से असंगत होता है। डिबगिंग के लिए बहुत सारे लॉग्स में ट्रेसिंग की आवश्यकता होती है।
🗓️ डेटा अखंडता के लिए सागा पैटर्न
एक सागा स्थानीय लेनदेन का क्रम है। प्रत्येक लेनदेन स्थानीय डेटाबेस को अपडेट करता है और अगले चरण को ट्रिगर करने के लिए एक घटना प्रकाशित करता है। यदि कोई चरण विफल होता है, तो सागा पिछले परिवर्तनों को वापस लेने के लिए संतुलित लेनदेन निष्पादित करता है।
कोरियोग्राफी बनाम ऑर्केस्ट्रेशन
सागाओं को दो तरीकों से लागू किया जा सकता है:
- कोरियोग्राफी: सेवाएं घटनाओं के लिए सुनती हैं और अगला क्या करना है, इसका निर्णय लेती हैं। कोई केंद्रीय नियंत्रक नहीं है। यह लचीला है लेकिन दृश्यमान करना मुश्किल है।
- ऑर्केस्ट्रेशन: एक केंद्रीय समन्वयक सेवाओं को बताता है कि क्या करना है। इससे वर्कफ्लो पर बेहतर दृश्यता और नियंत्रण मिलता है, लेकिन एकल विफलता के बिंदु को जोड़ता है।
जब सागाओं के लिए एरडीएस का मॉडलिंग करते हैं, तो आपको राज्य परिवर्तनों को ध्यान में रखना होगा। सागा में शामिल प्रत्येक सेवा को रोलबैक के लिए अपनी स्थिति संग्रहीत करने की आवश्यकता होती है। इसका मतलब है कि आपके स्कीमा को अंतिम डेटा के अलावा लेनदेन स्थितियों का समर्थन करना होगा।
📝 स्कीमा विकास का प्रबंधन
स्कीमा विकास अनिवार्य है। फ़ील्ड बदलते हैं, प्रकार बदलते हैं, और सीमाएं ढीली होती हैं। एक वितरित प्रणाली में, आप तब तक डेटाबेस स्कीमा में परिवर्तन नहीं कर सकते जब तक अन्य सेवाएं इस पर निर्भर रहती हैं। आपको संस्करण प्रबंधन की योजना बनानी होगी।
पीछे की अनुकूलता
हमेशा पीछे की अनुकूलता बनाए रखें। एक नया फ़ील्ड जोड़ते समय, पुराने को तुरंत हटाएं नहीं। उपभोक्ताओं को धीरे-धीरे स्थानांतरित करने की अनुमति दें। यदि आपको फ़ील्ड का नाम बदलना हो, तो संक्रमण अवधि के दौरान पुराने नाम को नए नाम के लिए एलियास बनाएं।
संस्करण प्रबंधन रणनीतियां
- यूआरआई संस्करण प्रबंधन: एपीआई पथ में संस्करण संख्या शामिल करें।
- हेडर संस्करण प्रबंधन: अपेक्षित स्कीमा संस्करण को निर्दिष्ट करने के लिए कस्टम हेडर का उपयोग करें।
- सामग्री समझौता: विशिष्ट मीडिया प्रकार के लिए अनुरोध करने के लिए मानक HTTP हेडर का उपयोग करें।
दस्तावेज़ीकरण को कोड के साथ समान रखना चाहिए। स्वचालित परीक्षणों को यह सत्यापित करना चाहिए कि एपीआई अनुबंध स्कीमा के साथ मेल खाता है। इससे उत्पादन में तोड़ने वाले परिवर्तनों को रोका जा सकता है।
🛡️ बचने के लिए सामान्य त्रुटियां
एक मजबूत योजना के साथ भी, टीमें अक्सर विशिष्ट समस्याओं में फंस जाती हैं। इन त्रुटियों के बारे में जागरूकता एक टिकाऊ प्रणाली के डिज़ाइन में मदद करती है।
1. साझा डेटाबेस की जाल
सेवाओं के बीच टेबल साझा न करें। इससे छिपी हुई बाध्यता बनती है। यदि भुगतान सेवा आर्डर सेवा की टेबल पढ़ती है, तो इसे आ inter्नाल संरचना के बारे में बहुत कुछ पता चलता है। इससे तंग बाध्यता और डेप्लॉयमेंट संघर्ष उत्पन्न होते हैं।
2. अत्यधिक सामान्यीकरण
सेवाओं के बीच डेटा को सामान्यीकृत करने की कोशिश करने से अत्यधिक जॉइन और नेटवर्क कॉल होती हैं। कुछ अतिरिक्तता स्वीकार करें। धीमी, जुड़ी हुई प्रणाली के बजाय डुप्लीकेट डेटा होना बेहतर है।
3. आइडेम्पोटेंसी को नजरअंदाज करना
नेटवर्क कॉल विफल होते हैं। संदेश डुप्लीकेट हो जाते हैं। आपके स्कीमा और एपीआई तर्क को त्रुटि नहीं उत्पन्न किए बिना डुप्लीकेट अनुरोधों का प्रबंधन करना होगा। अपने एंडपॉइंट्स को आइडेम्पोटेंट डिज़ाइन करें ताकि अनुरोध को दोहराने से डुप्लीकेट रिकॉर्ड न बनें।
4. अवलोकन की कमी
जब डेटा वितरित होता है, तो आप एकल डेटाबेस को प्रश्न करके लेनदेन का पता नहीं लगा सकते। आपको वितरित ट्रेसिंग और केंद्रीकृत लॉगिंग की आवश्यकता होती है। आपके स्कीमा में संबंधित आईडी को शामिल करना चाहिए ताकि सेवा सीमाओं के पार अनुरोधों का अनुसरण किया जा सके।
📋 शासन सूची
किसी नई सेवा को डेप्लॉय करने से पहले, निम्नलिखित सूची की समीक्षा करें ताकि आपका डेटा मॉडल ठीक हो।
- मालिकाना हक:क्या इस डेटा के लिए एकल सेवा जिम्मेदार है?
- इंटरफेस:क्या डेटा केवल API के माध्यम से उपलब्ध कराया जाता है?
- सुसंगतता:क्या सुसंगतता मॉडल दस्तावेजीकृत है (मजबूत बनाम अंततः)?
- घटनाएँ:क्या स्थिति परिवर्तन अन्य सेवाओं के लिए घटनाओं के रूप में प्रकाशित किए जाते हैं?
- संपूर्णता:क्या विफल लेनदेन के लिए एक रोलबैक तंत्र है?
- संस्करण निर्धारण:क्या स्कीमा के भविष्य के परिवर्तनों को संभालने के लिए संस्करण निर्धारित किया गया है?
- सुरक्षा:क्या संवेदनशील डेटा आराम के समय और प्रवाह के दौरान एन्क्रिप्ट किया गया है?
🔍 आर्किटेक्चर का दृश्यीकरण
जब आप पूरे सिस्टम के लिए एकल ERD नहीं बना सकते, तो आप एक उच्च स्तर का नक्शा बना सकते हैं। इस नक्शे में सेवाओं और उनकी डेटा सीमाओं को दिखाया जाता है, विशिष्ट कॉलम नहीं।
- प्रत्येक सेवा के लिए बॉक्स बनाएं।
- बॉक्स के भीतर डेटा क्षेत्र को लेबल करें (उदाहरण के लिए, “उपयोगकर्ता प्रोफाइल डेटा”)।
- डेटा प्रवाह को दर्शाते हुए API कॉल के लिए तीर खींचें।
- घटना प्रवाह को अनुरोध/प्रतिक्रिया प्रवाह से अलग रूप से दर्शाएं।
यह दृश्य सहायता स्टेकहोल्डर्स को तकनीकी स्कीमा विवरणों में फंसे बिना सूचना के प्रवाह को समझने में मदद करती है। यह आर्किटेक्ट्स और व्यापार विश्लेषकों के लिए संचार उपकरण के रूप में कार्य करती है।
🚀 निष्कर्ष
माइक्रोसर्विसेज के लिए ERD डिज़ाइन करना टेबलों के बीच रेखाएँ खींचने के बारे में नहीं है। यह व्यावसायिक क्षमताओं के बीच सीमाओं को परिभाषित करने के बारे में है। सेवा प्रत्येक डेटाबेस को स्वीकार करने, अंततः सुसंगतता को स्वीकार करने और API का कठोर रूप से प्रबंधन करने के माध्यम से आप पैमाने पर बढ़ने वाले प्रणालियों का निर्माण कर सकते हैं। वितरित डेटा की अव्यवस्था अनुशासन और स्पष्ट अनुबंधों के साथ प्रबंधित की जा सकती है। स्वतंत्रता पर ध्यान केंद्रित करें, कनेक्शन को न्यूनतम करें, और सुनिश्चित करें कि प्रत्येक सेवा अपने डेटा का पूर्ण मालिक है।
याद रखें कि डेटा मॉडलिंग एक आवर्ती प्रक्रिया है। जैसे-जैसे सेवाएँ बढ़ती हैं, आपके स्कीमा को विकसित होने की आवश्यकता होगी। एक स्वस्थ, लचीली प्रणाली बनाए रखने के लिए इन सिद्धांतों के आधार पर अपनी आर्किटेक्चर की नियमित समीक्षा करें।