











मिलियनों उपयोगकर्ताओं को संभाल सकने वाले सिस्टम का निर्माण करने के लिए केवल शक्तिशाली हार्डवेयर या कुशल कोड से अधिक चाहिए। आधार डेटा संरचना में ही है। एक एंटिटी रिलेशनशिप डायग्राम (एरडी) केवल दस्तावेज़ीकरण का एक तत्व नहीं है; यह आपके एप्लिकेशन की लंबाई का नक्शा है। जब वास्तुकार वृद्धि के लिए डिज़ाइन करते हैं, तो वे भविष्य के लोड, संबंधों की जटिलता और डेटा अखंडता की आवश्यकता की भविष्यवाणी करते हैं। एक अच्छी तरह से निर्मित स्कीमा पहले कमिट के बनने से पहले ही तकनीकी देनदारी जमा होने से रोकता है।
यह मार्गदर्शिका स्केलेबल वातावरणों के लिए एंटिटी रिलेशनशिप डायग्राम डिज़ाइन के तरीकों को समझने में मदद करती है। हम सैद्धांतिक आधार, व्यावहारिक व्यापार, और संरचनात्मक पैटर्न को कवर करेंगे जो संगतता को नुकसान नहीं पहुंचाए बिना उच्च थ्रूपुट सिस्टम के समर्थन करते हैं।
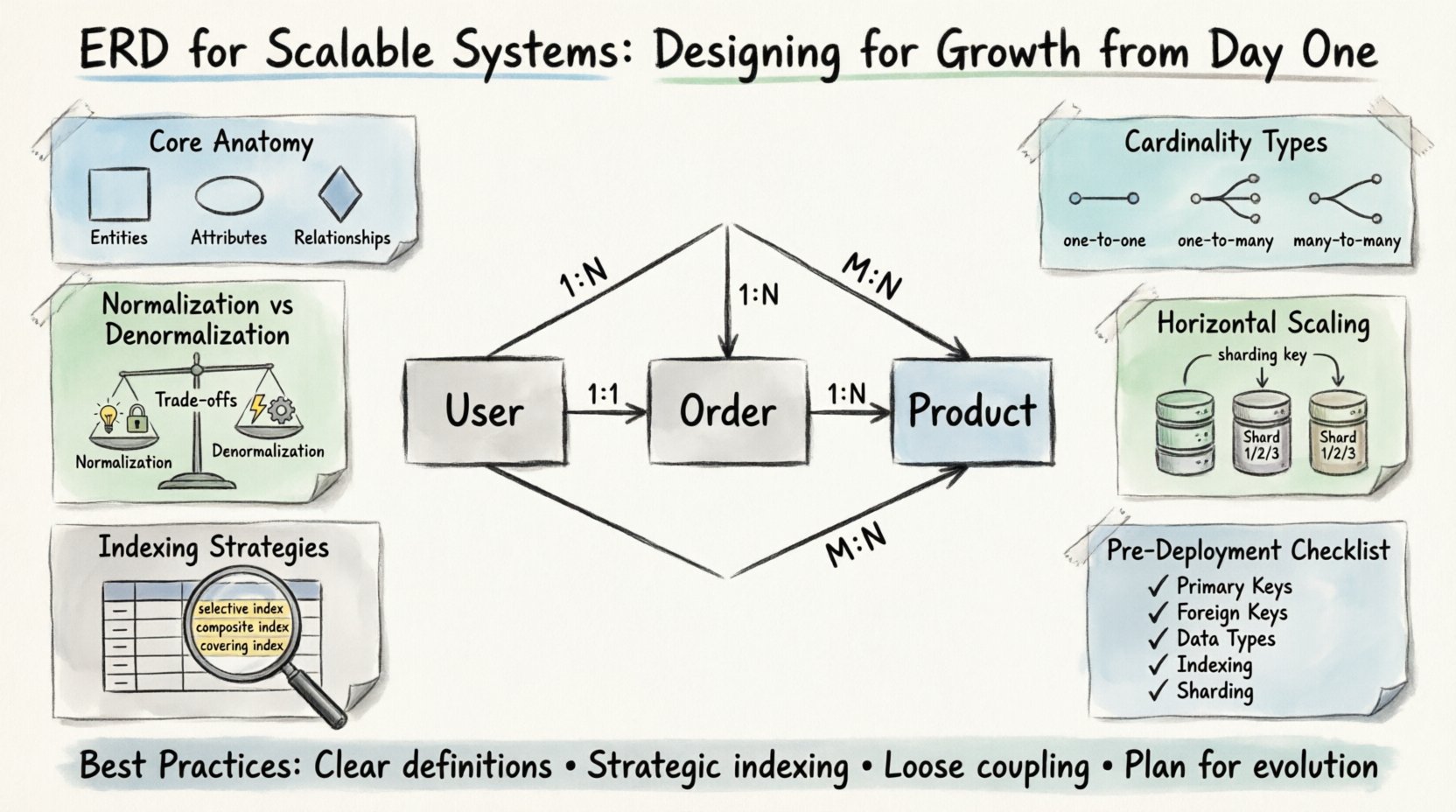
🧩 स्केलेबल एरडी की मूल बनावट
स्केल को ध्यान में रखने से पहले, एक को मूल निर्माण तत्वों को समझना चाहिए। प्रत्येक डायग्राम में एंटिटी, विशेषताएं और संबंध शामिल होते हैं। स्केलेबल संदर्भ में, इन तत्वों को सटीकता से परिभाषित किया जाना चाहिए ताकि बाद में बफलेट न हो।
- एंटिटी: ये आपके व्यवसाय क्षेत्र की मूल वस्तुओं का प्रतिनिधित्व करते हैं। उदाहरण के लिए उपयोगकर्ता, आदेश और उत्पाद हैं। उच्च वृद्धि वाले सिस्टम में, एंटिटी को पर्याप्त रूप से छोटा होना चाहिए ताकि स्वतंत्र स्केलिंग संभव हो, लेकिन तार्किक सीमाओं को बनाए रखने के लिए पर्याप्त एकजुट होना चाहिए।
- विशेषताएं: ये एंटिटी को वर्णित करने वाली विशेषताएं हैं। यहां डेटा प्रकार महत्वपूर्ण हैं। सही प्रकार का चयन भंडारण की दक्षता और प्रश्न प्रदर्शन को प्रभावित करता है। उदाहरण के लिए, आईडी के लिए एक निर्दिष्ट पूर्णांक प्रकार का उपयोग स्ट्रिंग की तुलना में इंडेक्सिंग के उद्देश्य से बेहतर है।
- संबंध: ये एंटिटी के बीच बातचीत को परिभाषित करते हैं। कार्डिनैलिटी को जल्दी से परिभाषित करना सबसे महत्वपूर्ण है। एक से बहुत के संबंध को बहुत से बहुत के रूप में गलत व्याख्या करने से अनावश्यक जॉइन और गंभीर प्रदर्शन गिरावट हो सकती है।
📐 कार्डिनैलिटी और सीमाओं को समझना
कार्डिनैलिटी एक एंटिटी के उन उदाहरणों की संख्या को निर्धारित करती है जो दूसरे एंटिटी के उदाहरणों से संबंधित हो सकते हैं या अनिवार्य हों। स्केलेबल सिस्टम में, कार्डिनैलिटी का चयन अक्सर डेटा के पार्टीशनिंग के तरीके को निर्धारित करता है।
- एक से एक (1:1): प्रदर्शन अनुकूलन के लिए दुर्लभ रूप से उपयोग किया जाता है। अक्सर एक बड़ी एंटिटी को विभाजित करने का अर्थ होता है ताकि लॉकिंग प्रतिस्पर्धा कम हो। केवल तभी उपयोग करें जब डेटा प्राप्त करने के पैटर्न सख्ती से अलग हों।
- एक से बहुत (1:N): सबसे आम संबंध। एक उपयोगकर्ता के कई आदेश होते हैं। इस संरचना में विदेशी कुंजी वाली ओर प्रभावी इंडेक्सिंग समर्थन करती है, जिससे संबंधित रिकॉर्ड को तेजी से प्राप्त करना संभव होता है।
- बहुत से बहुत (M:N): एक जंक्शन टेबल की आवश्यकता होती है। यह लचीला है, लेकिन जैसे-जैसे डेटा का आयतन बढ़ता है, यह प्रदर्शन के बफलेट बन सकता है। यदि पढ़ने की आवृत्ति उच्च है, तो डेनॉर्मलाइजेशन या मैटेरियलाइज्ड दृश्यों के बारे में सोचें।
जब सीमाओं को परिभाषित करते हैं, तो निर्बंधन के अतिरिक्त भार को ध्यान में रखें। वितरित प्रणालियों में, शर्द्स के बीच सख्त विदेशी कुंजी सीमाओं को लागू करने से लेटेंसी आ सकती है। ऐसे मामलों में, डेटा अखंडता को बनाए रखते हुए प्रणाली के थ्रूपुट को बनाए रखने के लिए एप्लिकेशन स्तरीय सत्यापन आवश्यक हो सकता है।
⚖️ नॉर्मलाइजेशन बनाम प्रदर्शन के व्यापार
नॉर्मलाइजेशन अतिरिक्तता को कम करता है और डेटा अखंडता में सुधार करता है। हालांकि, उच्च प्रदर्शन वाली प्रणालियों को अक्सर सख्त नॉर्मलाइजेशन नियमों से विचलन की आवश्यकता होती है। परतों को समझना जानकारीपूर्ण निर्णय लेने में मदद करता है।
- पहला सामान्य रूप (1NF): परमाणु मान। सुनिश्चित करता है कि प्रत्येक सेल में एक ही मान हो। यह संबंधात्मक अखंडता के लिए अनिवार्य है।
- दूसरा सामान्य रूप (2NF): कोई आंशिक निर्भरता नहीं। सभी गैर-कुंजी विशेषताओं को पूर्ण मुख्य कुंजी पर निर्भर होना चाहिए। अपडेट अनोमाली को कम करने में उपयोगी।
- तीसरा सामान्य रूप (3NF): कोई प्रत्यक्ष निर्भरता नहीं। गैर-कुंजी विशेषताओं को अन्य गैर-कुंजी विशेषताओं पर निर्भर नहीं होना चाहिए। यह अधिकांश लेनदेन प्रणालियों के लिए मानक लक्ष्य है।
जबकि 3NF संगतता के लिए आदर्श है, यह अक्सर जटिल जॉइन की आवश्यकता रखता है। पढ़ने वाली प्रणालियों में, बहुत सारी टेबलों को जोड़ने से डेटाबेस इंजन पर दबाव पड़ सकता है। डेनॉर्मलाइजेशन में डेटा की प्रतिलिपि बनाकर जॉइन की आवश्यकता को कम किया जाता है। इससे लेखन की जटिलता बढ़ती है, लेकिन पढ़ने की गति में महत्वपूर्ण वृद्धि होती है।
📊 नॉर्मलाइजेशन बनाम डेनॉर्मलाइजेशन की तुलना
| सुविधा | नॉर्मलाइज्ड (3NF) | डीनॉर्मलाइज्ड |
|---|---|---|
| डेटा अखंडता | उच्च (एकमात्र सत्य का स्रोत) | कम (सिंक लॉजिक की आवश्यकता होती है) |
| लेखन प्रदर्शन | तेज (कम डेटा लिखा गया) | धीमा (आवश्यकता से अधिक लेखन) |
| पढ़ने का प्रदर्शन | धीमा (जॉइन की आवश्यकता होती है) | तेज (सीधी पहुंच) |
| स्टोरेज उपयोग | कुशल | उच्च (आवर्धन) |
| उपयोग के मामले | लेनदेन प्रणाली (OLTP) | रिपोर्टिंग और विश्लेषण (OLAP) |
🚀 क्षैतिज स्केलिंग के लिए डिज़ाइन करना
जैसे-जैसे डेटा का आयतन बढ़ता है, एकल डेटाबेस नोड एक बाधा बन जाता है। क्षैतिज स्केलिंग में लोड को वितरित करने के लिए अधिक नोड्स जोड़ना शामिल है। आपके ईआरडी को शुरू से ही इस आर्किटेक्चर का समर्थन करना चाहिए।
- शार्डिंग कीज़:एक कॉलम की पहचान करें जो डेटा को शार्ड्स के बीच समान रूप से विभाजित करने की अनुमति देता है। यह कॉलम हर उस क्वेरी में उपस्थित होना चाहिए जो डेटा तक पहुंचती है। यदि किसी क्वेरी को सभी शार्ड्स को स्कैन करने की आवश्यकता होती है, तो प्रदर्शन प्रभावित होगा।
- शार्ड्स के बीच विदेशी कुंजियाँ:अलग-अलग शार्ड्स पर स्थित तालिकाओं को जोड़ना गणनात्मक रूप से महंगा होता है। डिज़ाइन चरण में क्रॉस-शार्ड संबंधों को कम करें। यदि संबंध आवश्यक है, तो संदर्भ डेटा को कैश करने के बारे में सोचें।
- ग्लोबल आईडीज़:स्वयं-वृद्धि काउंटर पर निर्भर नहीं रहने वाले अद्वितीय पहचानकर्ता का उपयोग करें, क्योंकि इनके कारण प्रतिस्पर्धा हो सकती है। UUIDs या वितरित आईडी जनरेटर प्राथमिकता दी जाती है।
जब शार्डिंग के लिए मॉडलिंग कर रहे हों, तो डेटा के वितरण पर विचार करें। जब एक शार्ड अन्य शार्ड्स की तुलना में काफी अधिक ट्रैफिक प्राप्त करता है, तो हॉटस्पॉट उत्पन्न होते हैं। सुनिश्चित करने के लिए एक्सेस पैटर्न का विश्लेषण करें कि शार्डिंग कीज़ सबसे अधिक आवृत्ति वाले क्वेरी फ़िल्टर्स के साथ मेल खाती है।
📑 बड़े डेटासेट्स के लिए इंडेक्सिंग रणनीतियाँ
इंडेक्स क्वेरी प्रदर्शन के लिए आवश्यक हैं, लेकिन इनके साथ लागत भी आती है। प्रत्येक इंडेक्स स्टोरेज का उपयोग करता है और लेखन ऑपरेशन को धीमा करता है। इंडेक्सिंग के लिए रणनीतिक दृष्टिकोण बहुत महत्वपूर्ण है।
- चयनात्मक इंडेक्स: उन कॉलम पर इंडेक्स बनाएं जो डेटा को बहुत अधिक फ़िल्टर करते हैं। कम कार्डिनैलिटी वाला कॉलम (जैसे लिंग) आमतौर पर प्राथमिक इंडेक्स के लिए खराब उम्मीदवार होता है।
- कॉम्पोजिट इंडेक्स: एक ऐसे क्रम में कई कॉलम को जोड़ें जो प्रश्न पैटर्न के अनुरूप हों। बाएं से दाएं प्रीफिक्स नियम लागू होता है, जिसका अर्थ है कि इंडेक्स में पहले कॉलम को प्रश्न से मेल खाना चाहिए ताकि इंडेक्स का प्रभावी उपयोग किया जा सके।
- कवरिंग इंडेक्स: इंडेक्स में ही उन सभी कॉलम को शामिल करें जो प्रश्न द्वारा आवश्यक हैं। इससे डेटाबेस को टेबल डेटा तक पहुंचे बिना प्रश्न को संतुष्ट करने की अनुमति मिलती है, जिसे एक “कवरिंग” संचालन कहा जाता है।
- आंशिक इंडेक्स: केवल टेबल की पंक्तियों के एक उपसमूह पर इंडेक्स बनाएं। यह नरम हटाने या विशिष्ट स्थिति झंडियों के लिए उपयोगी है, जिससे इंडेक्स संरचना का आकार कम होता है।
प्रश्न के निष्पादन योजनाओं का नियमित रूप से समीक्षा करें। यदि सांख्यिकी अद्यतन नहीं हैं, तो एक इंडेक्स जो कागज पर अच्छा लगता है, उसे प्रश्न ऑप्टिमाइज़र द्वारा नजरअंदाज कर दिया जा सकता है। नियमित रखरखाव सुनिश्चित करता है कि डेटाबेस इंजन अनुकूल निर्णय लेता है।
🔄 विकास और स्कीमा माइग्रेशन
प्रणालियाँ स्थिर नहीं होती हैं। आवश्यकताएँ बदलती हैं, और डेटा मॉडल को विकसित होना चाहिए। बिना बंदी के संस्करण A से संस्करण B में जाना एक महत्वपूर्ण कौशल है।
- एडिटिव बदलाव: कॉलम या टेबल जोड़ना आमतौर पर सुरक्षित होता है। यह मौजूदा प्रश्नों को नहीं तोड़ता है। नए फीचर्स को लागू करने के लिए यह प्राथमिक विधि है।
- नाम बदलने के संचालन: कॉलम का नाम बदलना जोखिम भरा है। इसके लिए एप्लीकेशन कोड के अपडेट करने की आवश्यकता होती है। एक अप्रचलन अवधि की योजना बनाएं जहां पुराने और नए नाम दोनों का समर्थन किया जाए।
- प्रतिबंध जोड़ना: मौजूदा डेटा में प्रतिबंध (जैसे NOT NULL) जोड़ना तब विफल हो सकता है यदि डेटा मौजूद है। पहले डेटा की पुष्टि करें, फिर एक अलग चरण में प्रतिबंध जोड़ें।
- पीछे की अनुकूलता: सुनिश्चित करें कि नए स्कीमा संस्करण मौजूदा क्लाइंट्स को नहीं तोड़ते हैं। नए तर्क को केवल तब टॉगल करें जब स्कीमा तैयार हो।
🚫 बचने के लिए सामान्य गलतियाँ
यहां तक कि अनुभवी डिजाइनरों को समस्याओं का सामना करना पड़ता है। इन पैटर्न को जल्दी पहचानने से इंजीनियरिंग समय की बड़ी बचत हो सकती है।
- कठोर जुड़ाव: ऐसे संबंध बनाना जो असंबंधित तत्वों के बीच सख्त समन्वय के लिए मजबूर करते हैं। मॉड्यूल को ढीले जुड़े रखें ताकि स्वतंत्र डेप्लॉयमेंट संभव हो।
- अत्यधिक डिजाइन: ऐसे परिदृश्यों के लिए डिजाइन करना जो कभी नहीं हो सकते। 80% उपयोग के मामलों पर ध्यान केंद्रित करें जो 90% ट्रैफ़िक को प्रभावित करते हैं। सरलता रखरखाव में मदद करती है।
- नरम हटाने को नजरअंदाज करना: हार्ड हटाने से डेटा स्थायी रूप से हट जाता है। ऑडिट ट्रेल या पुनर्स्थापना के लिए, भौतिक हटाने के बजाय एक स्थिति झंडी (जैसे is_deleted) का उपयोग करें।
- एन+1 प्रश्न समस्याएँ: डेटा कैसे लाया जाएगा, इसकी योजना बनाने में विफलता। अत्यधिक डेटाबेस राउंड ट्रिप से बचने के लिए डेटा एक्सेस लेयर में त्वरित लोडिंग या बैच लोडिंग की योजना बनाएं।
✅ डेप्लॉयमेंट से पहले डिजाइन चेकलिस्ट
स्कीमा को अंतिम रूप देने से पहले, इस सत्यापन सूची को चेक करें ताकि स्केल के लिए तैयारी सुनिश्चित हो।
- ☐ प्राथमिक कुंजियाँ: क्या सभी तालिकाओं में एक अद्वितीय, सूचीबद्ध प्राथमिक कुंजी है?
- ☐ विदेशी कुंजियाँ: क्या संबंध सही तरीके से परिभाषित हैं? कार्डिनैलिटी सही है?
- ☐ डेटा प्रकार: क्या पहचान संख्या और राशि के लिए संख्यात्मक प्रकार का उपयोग किया जाता है? क्या तारीख प्रकार मानकीकृत हैं?
- ☐ नलता: क्या आवश्यक फ़ील्ड को NOT NULL के रूप में चिह्नित किया गया है?
- ☐ सूचीकरण: क्या उच्च ट्रैफ़िक वाले प्रश्न वाले कॉलम सूचीबद्ध हैं?
- ☐ शार्डिंग: क्या क्षैतिज स्केलिंग की अपेक्षा करने पर एक उपयुक्त शार्डिंग कुंजी है?
- ☐ सीमाएँ: क्या व्यापार तर्क के लिए सीमाएँ आवश्यक हैं, या उन्हें एप्लिकेशन परत पर संभाला जा सकता है?
- ☐ दस्तावेज़ीकरण: क्या एरडी अंतिम कार्यान्वयन को दर्शाने के लिए अद्यतन किया गया है?
🛡️ वितरित परिवेशों में डेटा अखंडता
एक वितरित सेटअप में, नोड्स के बीच एसीआईडी गुण (परमाणुता, सुसंगतता, अलगाव, दृढ़ता) को सुनिश्चित करना मुश्किल होता है। अपने ईआरडी के लिए इसके प्रभावों को समझना निर्णायक है।
- अंततः सुसंगतता: स्वीकार करें कि प्रतिकृतियों के बीच डेटा अस्थायी रूप से असंगत हो सकता है। अपने एप्लिकेशन को इस स्थिति को बेहतर तरीके से संभालने के लिए डिज़ाइन करें।
- पुनरावृत्ति योग्यता: सुनिश्चित करें कि संचालनों को बिना प्रभाव के दोहराया जा सकता है। यह नेटवर्क विफलताओं के लिए महत्वपूर्ण है जहां लेखन सफल हो सकता है लेकिन पुष्टि खो जाती है।
- संघर्ष समाधान: एक ही रिकॉर्ड के समानांतर अपडेट को कैसे संभालना है, इसकी परिभाषा करें। समयचिह्न या वेक्टर घड़ी नवीनतम संस्करण का निर्धारण करने में मदद कर सकते हैं।
इन pertimbangan को अपने संबंध संबंध आरेख में एम्बेड करके, आप एक ऐसा प्रणाली बनाते हैं जो केवल आज कार्यात्मक ही नहीं है, बल्कि भविष्य के लिए भी मजबूत है। उत्पादन में स्कीमा बदलने की लागत मूल रूप से सही तरीके से डिज़ाइन करने की तुलना में एक्सपोनेंशियल रूप से अधिक होती है।
🔍 बेस्ट प्रैक्टिसेज का सारांश
सारांश के लिए, सफल स्केलिंग डेटा मॉडलिंग के एक अनुशासित दृष्टिकोण पर निर्भर करता है। स्पष्ट परिभाषाओं, उचित नॉर्मलाइजेशन और रणनीतिक इंडेक्सिंग पर ध्यान केंद्रित करें। डेटा अखंडता को नुकसान पहुंचाने वाले छोटे रास्तों से बचें। जैसे ही प्रणाली विकसित होती है, अपने आरेखों की नियमित समीक्षा करें। एक स्थिर ERD एक दोष है; एक जीवंत मॉडल एक संपत्ति है।
डिज़ाइन चरण में समय निवेश करें। यह रखरखाव लागत को कम करने और प्रणाली की विश्वसनीयता को बढ़ाने में लाभ देगा। आपके उपयोगकर्ता कभी भी आरेख नहीं देखेंगे, लेकिन वे उस प्रणाली के प्रदर्शन को महसूस करेंगे जिसका आरेख समर्थन करता है।