









एक टिकाऊ डेटा आर्किटेक्चर को डिज़ाइन करने के लिए बॉक्स और लाइनें बनाने से अधिक चाहिए। इसमें एक संगठन में जानकारी के प्रवाह के बारे में गहन समझ और उस प्रवाह के नियमों द्वारा नियंत्रित होने के बारे में जानने की आवश्यकता होती है। एक एंटिटी-रिलेशनशिप डायग्राम (ERD) संरचनात्मक नक्शा के रूप में कार्य करता है, जबकि व्यापार तर्क सिस्टम के व्यवहार को निर्धारित करता है। जब इन दोनों तत्वों में अंतर आता है, तो परिणाम अक्सर एक नाजुक सिस्टम होता है जो वास्तविक दुनिया की आवश्यकताओं के अनुकूल होने में कठिनाई महसूस करता है। यह मार्गदर्शिका डेटा मॉडलिंग और व्यापार नियमों के बीच महत्वपूर्ण संपर्क का अध्ययन करती है, आपके स्कीमा के आवश्यकताओं के समर्थन करने के लिए प्रभावी रणनीतियाँ प्रदान करती है।
चुनौती ऐसी संकल्पनाओं—जैसे कि “एक उपयोगकर्ता स्टॉक में उपलब्ध मात्रा से अधिक ऑर्डर नहीं कर सकता है”—को वास्तविक डेटाबेस संरचनाओं में बदलने में है। यदि मॉडल नियमों का प्रतिनिधित्व नहीं करता है, तो डेटा अखंडता प्रभावित होती है। यदि नियम बहुत कठोर हैं, तो व्यापार की लचीलापन मर जाता है। हमें एक संतुलन खोजना होगा जो संस्थिति को बनाए रखे बिना संचालन को दबाए नहीं। आइए मुख्य घटकों का अध्ययन करें और उन्हें कैसे समायोजित करना है, इसका विश्लेषण करें।
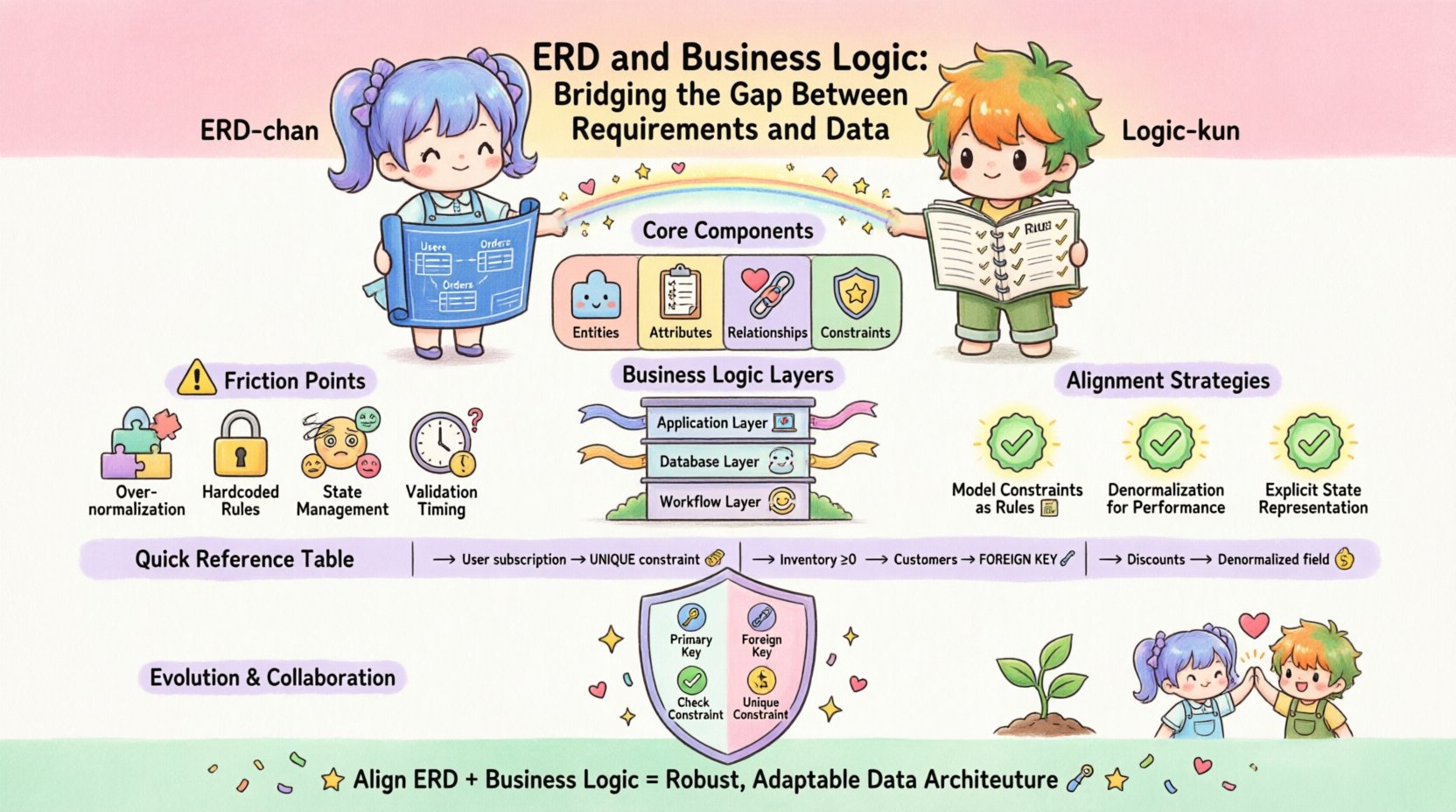
मुख्य घटकों को समझना 🏗️
अंतर को पार करने के लिए, हमें पहले यह परिभाषित करना होगा कि हम किसके साथ काम कर रहे हैं। समीकरण के दोनों पक्षों में अलग-अलग विशेषताएँ हैं जो उनके बीच बातचीत को प्रभावित करती हैं।
एंटिटी-रिलेशनशिप डायग्राम (ERD)
एक ERD डेटा की स्थिर संरचना का प्रतिनिधित्व करता है। यह एंटिटी (तालिकाएँ), विशेषताएँ (स्तंभ), और संबंध (विदेशी कुंजियाँ) को परिभाषित करता है। इसका मुख्य लक्ष्य नॉर्मलाइजेशन और अखंडता है। यह प्रश्न का उत्तर देता है: “हमें किस डेटा को स्टोर करने की आवश्यकता है?” मुख्य पहलू इस प्रकार हैं:
- एंटिटी: सिस्टम की मूल वस्तुएँ, जैसे किग्राहक, आदेश, याउत्पाद.
- विशेषताएँ: एंटिटी का वर्णन करने वाली विशेषताएँ, जैसे किईमेल, मूल्य, यास्थिति.
- संबंध: एंटिटी कैसे जुड़ती हैं, ज्यादातर प्राथमिक और विदेशी कुंजियों द्वारा परिभाषित। इन्हें कार्डिनैलिटी (एक-एक, एक-बहुत) स्थापित करते हैं।
- सीमाएँ: डेटाबेस स्तर पर लागू नियम, जैसे कि
NOT NULL,UNIQUE, याचेक.
जबकि शक्तिशाली, एक एरडी अक्सर सक्रिय नहीं होती है। यह डेटा को रखती है लेकिन इसके आंतरिक रूप से प्रसंस्करण नहीं करती है। यह जहाज है, न कि ड्राइवर।
व्यापार तर्क
व्यापार तर्क उन सक्रिय नियमों का प्रतिनिधित्व करता है जो डेटा के निर्माण, संशोधन और उपयोग के तरीके को नियंत्रित करते हैं। यह प्रश्न का उत्तर देता है: “हम इस डेटा के साथ क्या करने की अनुमति रखते हैं?” इस तर्क को विभिन्न स्तरों पर मौजूद हो सकता है:
- एप्लिकेशन स्तर:बैकएंड या फ्रंटएंड में कोड जो डेटाबेस में पहुंचने से पहले इनपुट की पुष्टि करता है।
- डेटाबेस स्तर:स्टोर्ड प्रोसीजर, ट्रिगर और नियम जो स्टोरेज इंजन के भीतर सीधे नियमों को लागू करते हैं।
- वर्कफ्लो स्तर:किसी कार्य को पूरा करने के लिए आवश्यक घटनाओं का क्रम, जैसे अनुमोदन श्रृंखला या स्थिति संक्रमण।
जब व्यापार तर्क को डेटा संरचना से बहुत दूर अलग कर दिया जाता है, तो असंगतियाँ उत्पन्न होती हैं। उदाहरण के लिए, यदि एप्लिकेशन नकारात्मक मात्रा दर्ज करने की अनुमति देता है लेकिन डेटाबेस की सीमा इसे रोकती है, तो उपयोगकर्ता अनुभव खराब हो जाता है। विपरीत रूप से, यदि डेटाबेस नकारात्मक मात्राओं की अनुमति देता है लेकिन एप्लिकेशन इन्हें रोकता है, तो तर्क दोहराया जाता है और त्रुटि के लिए अधिक झंझट में होता है।
रगड़ के बिंदु: अंतर क्यों होता है 📉
डेवलपर्स और डेटाबेस आर्किटेक्ट अक्सर अलग-अलग भाषाएं बोलते हैं। तकनीकी टीम प्रदर्शन और अखंडता पर ध्यान केंद्रित करती है, जबकि व्यापार पक्ष कार्यक्षमता और उपयोगकर्ता अनुभव पर ध्यान केंद्रित करता है। इस असंगति के कारण कई सामान्य रगड़ के बिंदु उत्पन्न होते हैं।
- अत्यधिक सामान्यीकरण:सामान्यीकरण नियमों का कठोर अनुसरण करने से जटिल व्यापार प्रश्नों को कठिन बना सकता है। एक अत्यधिक सामान्यीकृत स्कीमा किसी विशिष्ट व्यापार नियम के लिए डेटा प्राप्त करने के लिए बहुत सारे जॉइन की आवश्यकता होती है, जिससे एप्लिकेशन तर्क धीमा हो जाता है।
- कड़े नियम:एप्लिकेशन कोड में सीधे व्यापार नियमों को एम्बेड करने से वे डेटा स्तर के लिए अदृश्य हो जाते हैं। यदि डेटाबेस स्कीमा बदलता है, तो एप्लिकेशन चुपचाप विफल हो सकता है या असंगत डेटा लौटा सकता है।
- राज्य प्रबंधन:एरडी अक्सर जटिल राज्य मशीनों (उदाहरण के लिए, “प्रतीक्षा में”, “भेजा गया”, “वापसी किया गया” जैसे आदेश स्थितियाँ) के साथ समस्या में होती है। इन्हें सरल कॉलम के रूप में प्रस्तुत करने से तब अनाथ राज्य उत्पन्न हो सकते हैं यदि तर्क को लागू नहीं किया जाता है।
- पुष्टि का समय:यह तय करना महत्वपूर्ण है कि पुष्टि संग्रहण से पहले या बाद में होती है। प्रारंभिक पुष्टि लोड को कम करती है, लेकिन बाद की पुष्टि सबसे ताजा डेटा के उपयोग की गारंटी देती है।
जब इन बिंदुओं को नजरअंदाज किया जाता है, तो प्रणाली अस्थायी समाधानों के एक फैलाव के रूप में बन जाती है। डेवलपर्स नियमों को बाधित करने के लिए अस्थायी ठीक करते हैं, जिससे तकनीकी ऋण बढ़ता है। डेटा अविश्वसनीय हो जाता है और व्यापार तर्क भंगुर हो जाता है।
समन्वय के लिए रणनीतियाँ 🤝
इस अंतर को पार करने के लिए जानबूझकर डिजाइन की आवश्यकता होती है। हमें स्कीमा को एक जीवंत दस्तावेज के रूप में मानना होगा जो व्यापार आवश्यकताओं के साथ विकसित होता रहे। यहाँ डेटा मॉडलिंग को तर्क के साथ समायोजित करने के लिए साबित रणनीतियाँ हैं।
1. व्यापार नियमों के रूप में सीमाओं का मॉडल बनाएँ
प्रत्येक व्यापार नियम जो अमान्य डेटा को रोकता है, के लिए संबंधित डेटाबेस सीमा होनी चाहिए। केवल एप्लिकेशन कोड पर भरोसा न करें। इससे यह सुनिश्चित होता है कि डेटा कहीं से भी आए—एपीआई, स्क्रिप्ट या सीधे आयात—नियम लागू रहें।
- एकाकीपन:यदि उपयोगकर्ता नाम अद्वितीय होना चाहिए, तो इसे कॉलम स्तर पर लागू करें। पहले एप्लिकेशन में इसकी जांच न करें, क्योंकि रेस कंडीशन उत्पन्न हो सकती है।
- रेंज जांचें: यदि छूट 100% से अधिक नहीं हो सकती है, तो एक का उपयोग करें
जांचेंसीमा। इससे बैच अपडेट से अनजाने डेटा क्षति को रोका जाता है। - संदर्भात्मक अखंडता: एक ऑर्डर हमेशा एक वैध ग्राहक से संबंधित हो, इसकी गारंटी देने के लिए विदेशी कुंजियों का उपयोग करें। यदि एक ग्राहक को हटा दिया जाता है, तो व्यापार की आवश्यकताओं के आधार पर तय करें कि क्या ऑर्डर बना रहे (सॉफ्ट हटाना) या हटा दिया जाए (कैस्केड हटाना)।
2. तर्क प्रदर्शन के लिए अननॉर्मलाइज़ेशन
जबकि नॉर्मलाइज़ेशन स्टोरेज के लिए अच्छा है, यह हमेशा तर्क के लिए अच्छा नहीं होता है। जटिल व्यापार नियमों को अक्सर बहुत स्रोतों से डेटा संग्रहीत करने की आवश्यकता होती है। यदि तर्क रीड-भारी है, तो कुछ विशिष्ट लक्षणों को अननॉर्मलाइज़ करने के बारे में सोचें।
- कैश किए गए कुल मूल्य: प्रत्येक बार कुल मूल्य की आवश्यकता होने पर लाइन आइटम को जोड़ने के बजाय, स्टोर करेंकुल राशि ऑर्डर तालिका पर। जब भी कोई लाइन आइटम बदलता है, इस फ़ील्ड को अपडेट करें।
- स्थिति झंडियाँ: यदि उपयोगकर्ता स्थिति पहुँच निर्धारित करती है, तो इसे एक कॉलम में स्टोर करें, इतिहास तालिका के माध्यम से जोड़ने के बजाय। यह अनुमति जांचने वाले तर्क को तेज करता है।
इस दृष्टिकोण में स्टोरेज स्पेस के बदले में प्रश्न गति और तर्क सरलता का विनिमय होता है। डेटा असंगति से बचने के लिए इसका ध्यान से प्रबंधन करना आवश्यक है।
3. स्पष्ट राज्य प्रतिनिधित्व
कार्यप्रवाह के लिए, डेटाबेस में राज्य को स्पष्ट रूप से प्रतिबिंबित करना चाहिए। एक सीमित मानों के सेट वाले निर्दिष्ट स्थिति कॉलम का उपयोग करें। राज्य के लिए मुक्त-पाठ फ़ील्ड का उपयोग न करें।
- प्रतिलिपि मान: अनुमत स्थितियों को स्पष्ट रूप से परिभाषित करें। इससे रिपोर्टिंग और तर्क को आसान बनाया जाता है।
- संक्रमण तालिकाएँ: जटिल कार्यप्रवाह के लिए, इतिहास को ट्रैक करने के लिए एक संयोजन तालिका का उपयोग करें। इससे आप वर्तमान स्थिति तक पहुँचने के लिए लिया गया तर्क मार्ग को पुनर्निर्मित कर सकते हैं।
तर्क का स्कीमा से मैपिंग: एक व्यावहारिक तालिका 📊
कॉन्क्रीट संरचनाओं में अमूल्य नियमों के रूपांतरण को देखने के लिए नीचे दिए गए मैपिंग को देखें। यह तालिका सामान्य व्यापार आवश्यकताओं और उनके संबंधित डेटा मॉडलिंग पैटर्न को दर्शाती है।
| व्यापार आवश्यकता | तार्किक परिणाम | स्कीमा कार्यान्वयन |
|---|---|---|
| एक उपयोगकर्ता के पास केवल एक सक्रिय सदस्यता हो सकती है | सक्रिय अवस्था पर अद्वितीयता सीमा | UNIQUE (उपयोगकर्ता_आईडी, स्थिति) जहां स्थिति = ‘सक्रिय’ |
| इन्वेंटरी शून्य से नीचे नहीं जा सकती | लेखन पर सत्यापन | CHECK (मात्रा >= 0) या ट्रिगर तर्क |
| आदेश मौजूदा ग्राहकों से संबंधित होने चाहिए | संदर्भात्मक अखंडता | परदार्थी कुंजी (ग्राहक_id) ग्राहकों(id) के संदर्भ में |
| छूट प्रति आइटम के आधार पर गणना की जाती है | अनियमित संग्रहण | स्टोर छूट वाली कीमत ऑर्डर आइटम पर, बदलाव पर अपडेट करें |
| लॉग्स को 5 वर्षों तक बनाए रखा जाना चाहिए | जीवनचक्र प्रबंधन | बनाए गए के समय कॉलम + संग्रहण के लिए पृष्ठभूमि कार्य |
| भूमिकाएं फीचर एक्सेस निर्धारित करती हैं | संबंध मैपिंग | संयोजन सारणी भूमिका अनुमतियां उपयोगकर्ताओं को फीचर्स से जोड़ना |
इस मैपिंग सुनिश्चित करती है कि प्रत्येक नियम के डेटा मॉडल में एक घर हो। यह ऐसी स्थिति से बचाती है जहां तर्क केवल कोड में मौजूद होता है, जिससे डेटा खतरे में पड़ जाता है।
सत्यापन और सीमाएं: सुरक्षा जाल 🛡️
सीमाएं डेटा अखंडता के लिए पहली पंक्ति की रक्षा हैं। उन्हें डेटाबेस इंजन द्वारा लागू किया जाता है, जिससे वे एप्लीकेशन-स्तरीय जांच से तेज और अधिक विश्वसनीय होते हैं। हालांकि, उन्हें केवल केवल परत।
सीमाओं के प्रकार
- मुख्य कुंजियां: सुनिश्चित करें कि प्रत्येक रिकॉर्ड अद्वितीय रूप से पहचाना जा सके। यह सभी संबंधों के लिए मूलभूत है।
- परदार्थी कुंजियां: तालिकाओं के बीच संबंध बनाए रखें। वे अनाथ रिकॉर्ड से बचाते हैं।
- चेक सीमाएँ: कॉलम मानों के लिए विशिष्ट शर्तों को परिभाषित करें। सीमाओं, प्रारूपों या तर्क के लिए उपयोगी जैसे
मूल्य > 0. - यूनिक सीमाएँ: डुप्लीकेट डेटा को रोकें। ईमेल, उपयोगकर्ता नाम या SKUs के लिए आवश्यक है।
ट्रिगर्स और स्टोर्ड प्रोसीजर्स
कभी-कभी, एक सीमा पर्याप्त नहीं होती है। जटिल तर्क, जैसे लेनदेन होने पर एक से अधिक तालिकाओं में बैलेंस के अपडेट करना, ट्रिगर्स की आवश्यकता होती है। हालांकि शक्तिशाली, ट्रिगर्स का दुरुपयोग नहीं करना चाहिए। वे डेवलपर्स के लिए तर्क को छिपा सकते हैं और डीबगिंग कठिन बना सकते हैं।
- उपयोग के मामले: पुराने रिकॉर्ड को स्वचालित रूप से आर्काइव करना।
- उपयोग के मामले: इनसर्ट से पहले व्युत्पन्न क्षेत्रों की गणना करना।
- चेतावनी: ऐसे व्यवसाय तर्क से बचें जो एप्लीकेशन लेयर के लिए बेहतर हैं। ट्रिगर्स केवल डेटा अखंडता पर ध्यान केंद्रित करने चाहिए, उपयोगकर्ता-मुख्य वर्कफ्लो के लिए नहीं।
विकास और रीफैक्टरिंग 🔄
व्यवसाय नियम बदलते हैं। एक कंपनी सब्सक्रिप्शन बेचना शुरू कर सकती है और फिर एकमुश्त खरीदारी में स्थानांतरित हो सकती है। डेटा मॉडल को मौजूदा तर्क को तोड़े बिना विकसित होने की क्षमता होनी चाहिए।
स्कीमा का संस्करण बनाना
ERD में परिवर्तनों को संस्करण बनाया जाना चाहिए। संक्रमण को प्रबंधित करने के लिए माइग्रेशन स्क्रिप्ट का उपयोग करें। इससे आप वापस लौट सकते हैं यदि कोई परिवर्तन अप्रत्याशित रूप से व्यवसाय तर्क को तोड़ देता है।
- पीछे की संगतता: जब किसी कॉलम को जोड़ते हैं, तो उसे शुरू में nullable बनाएं। इससे पुराने तर्क को चलाने की अनुमति मिलती है जबकि नए तर्क को डेप्लॉय किया जाता है।
- प्रत्याहार: कॉलम को तुरंत हटाएं नहीं। उन्हें प्रत्याहित चिह्नित करें और उन्हें एक अवधि के लिए रखें ताकि पुराने इंटीग्रेशन का समर्थन किया जा सके।
- दस्तावेज़ीकरण: स्कीमा दस्तावेज़ीकरण को कोड के साथ समान रखें। ERD में एक टिप्पणी को कॉलम के पीछे के व्यवसाय नियम की व्याख्या करनी चाहिए।
तर्क के लिए रीफैक्टरिंग
आवश्यकताओं के बढ़ने पर, प्रारंभिक ERD एक बफलेट बन सकता है। आपको तालिकाओं को विभाजित करने या उन्हें मिलाने की आवश्यकता हो सकती है। यह एक महत्वपूर्ण कार्य है जिसके लिए सावधानीपूर्वक योजना बनाने की आवश्यकता होती है।
- तर्क की पहचान करें: यह निर्धारित करें कि कौन से व्यवसाय नियम प्रदर्शन या अखंडता की समस्याओं के कारण हैं।
- गतिविधि की योजना बनाएं: नए संरचना में डेटा को स्थानांतरित करने के लिए एक स्क्रिप्ट बनाएं जबकि सुसंगतता बनाए रखें।
- कठोरता से परीक्षण करें: इतिहासगत डेटा के खिलाफ नए तर्क को चलाएं ताकि यह सुनिश्चित हो कि यह अपेक्षित तरीके से व्यवहार करता है।
सहयोग और दस्तावेज़ीकरण 📝
तकनीकी समन्वय केवल लड़ाई का आधा हिस्सा है। दूसरा हिस्सा संचार है। डेटाबेस स्कीमा डेटा परत और एप्लिकेशन परत के बीच एक संविदा है। सभी शामिल लोगों को इसे समझना चाहिए।
साझा शब्दावली
यह सुनिश्चित करें कि डेटाबेस में उपयोग किए जाने वाले शब्द व्यापार शब्दावली के अनुरूप हों। यदि व्यापार इसे “ग्राहक” कहता है, तो टेबल का नाम “ग्राहक” न रखें। यदि व्यापार एक फील्ड को “स्थिति” कहता है, तो उसे “फ्लैग” न कहें। सुसंगतता मनोवैज्ञानिक भार को कम करती है।
दृश्य दस्तावेज़ीकरण
ERD दृश्य हैं, लेकिन वे घने हो सकते हैं। उन्हें उन आरेखों के साथ पूरक करें जो संरचना के साथ-साथ डेटा प्रवाह को दिखाते हैं। वहां जहां व्यापार तर्क डेटा के साथ बातचीत करता है, उसे उजागर करें।
- डेटा शब्दकोश:एक दस्तावेज़ बनाए रखें जो हर टेबल और कॉलम के उद्देश्य को समझाता है।
- तर्क प्रवाह आरेख:यह नक्शा बनाएं कि डेटा इनपुट से स्टोरेज तक कैसे आता है, और जहां वैधता घटित होती है, उसे नोट करें।
- प्रतिबंध सूचियां:विकास के दौरान आसान संदर्भ के लिए डेटाबेस द्वारा लागू सभी नियमों की सूची बनाए रखें।
डेटा अखंडता पर अंतिम विचार 🎯
ERD और व्यापार तर्क के बीच संबंध सहजीवी है। ERD आधार प्रदान करता है, और व्यापार तर्क उद्देश्य प्रदान करता है। जब वे असंगत होते हैं, तो प्रणाली मूल्य प्रदान करने में विफल हो जाती है। जब वे संगत होते हैं, तो प्रणाली व्यापार के लिए एक विश्वसनीय इंजन बन जाती है।
सफलता डेटाबेस को तर्क प्रबंधन में साथी के रूप में देखने से आती है, केवल भंडारण बॉक्स नहीं। प्रतिबंधों को लागू करने, राज्य को स्पष्ट रूप से प्रबंधित करने और स्पष्ट दस्तावेज़ीकरण बनाए रखने से आप एक प्रणाली बनाते हैं जो दोनों बलवान और अनुकूल है। लक्ष्य हर भविष्य की आवश्यकता का अनुमान लगाना नहीं है, बल्कि एक संरचना बनाना है जो बिना ढहे बदलाव को स्वीकार कर सके।
नियमों से शुरुआत करें। डेटा के किस रूप में वैध होने के बारे में पहले परिभाषित करें, फिर उसे कैसे संग्रहीत किया जाएगा इसके बारे में निर्धारित करें। व्यापार तर्क को स्कीमा का मार्गदर्शन करने दें, और स्कीमा को तर्क की रक्षा करने दें। यह संरेखण एक स्थायी डेटा संरचना की नींव है। 🚀