








सॉफ्टवेयर विकास में एक टिकाऊ डेटाबेस स्कीमा डिज़ाइन करना सबसे महत्वपूर्ण कार्यों में से एक है। एक एंटिटी रिलेशनशिप डायग्राम (ERD) आपकी डेटा आर्किटेक्चर के लिए नींव के रूप में काम करता है। यदि आधार दोषपूर्ण है, तो उस पर आधारित एप्लिकेशन प्रदर्शन, डेटा अखंडता और स्केलेबिलिटी के मामले में कठिनाइयों का सामना करेगा। डेवलपर्स या डेप्लॉयमेंट टीम को डेटाबेस मॉडल हस्तांतरण से पहले एक कठोर समीक्षा प्रक्रिया आवश्यक है। इस गाइड में आपके ERD की पुष्टि करने के दस आवश्यक चरणों को बताया गया है, जिससे यह सुनिश्चित हो कि आपकी डेटा संरचना उत्पादन के लिए तैयार है।
एक अच्छी तरह से संरचित ERD अतिरेक को कम करता है, प्रतिबंधों को लागू करता है और डेटा एंटिटी के बीच संबंधों को स्पष्ट करता है। वैलिडेशन चरणों को छोड़ने से विकास चक्र के बाद के चरणों में महंगे रीफैक्टरिंग की संभावना होती है। इस चेकलिस्ट में नामकरण प्रणाली, नॉर्मलाइजेशन, प्रतिबंध और दस्तावेज़ीकरण मानकों को शामिल किया गया है। अपने मॉडल को विश्वसनीय और बनाए रखने योग्य बनाने के लिए इन चरणों का पालन करें।
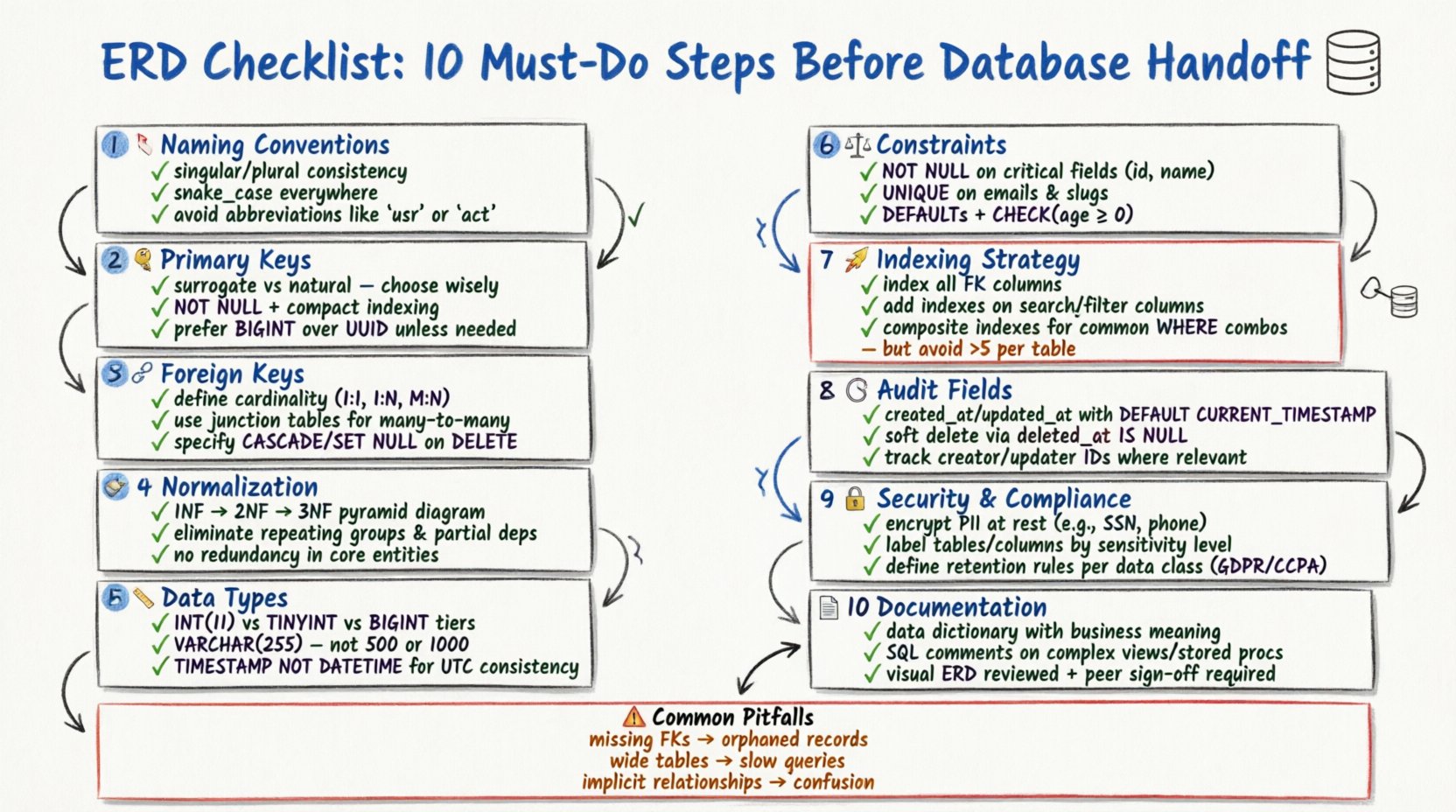
1. एंटिटी नामकरण प्रणाली की जांच करें 🏷️
नामकरण में स्थिरता भ्रम के खिलाफ पहली रक्षा रेखा है। प्रत्येक टेबल (एंटिटी) और कॉलम (एट्रिब्यूट) का मानकीकृत नामकरण प्रणाली का पालन करना आवश्यक है। असंगत नामों के कारण SQL क्वेरी लिखने और रखरखाव के दौरान अस्पष्टता उत्पन्न होती है।
- सिंगुलर या प्लूरल का निरंतर उपयोग करें: टेबल नामों के लिए एक शैली चुनें (उदाहरण के लिए,
उपयोगकर्तायाउपयोगकर्ता) और इसे पूरे स्कीमा में लागू करें। सिंगुलर नामों को अवधारणात्मक मॉडलिंग के लिए आमतौर पर प्राथमिकता दी जाती है, जबकि प्लूरल नामों का भौतिक कार्यान्वयन के लिए अक्सर उपयोग किया जाता है। - आरक्षित कीवर्ड्स से बचें: सुनिश्चित करें कि कोई एंटिटी या कॉलम नाम डेटाबेस-विशिष्ट आरक्षित शब्दों (उदाहरण के लिए,
आदेश,समूह,सूचकांक) के साथ संघर्ष नहीं करता है। आरक्षित शब्दों का उपयोग करने पर अक्सर अलगाव वाले अक्षरों की आवश्यकता होती है, जो कोड पठनीयता को कम करता है। - अल्पविराम के लिए अंडरस्कोर का उपयोग करें: कॉलम और टेबल के लिए स्नेक_केस प्रणाली अपनाएं (उदाहरण के लिए,
उपयोगकर्ता_प्रोफ़ाइल) ताकि विभिन्न डेटाबेस इंजनों में पठनीयता बनी रहे। - संक्षिप्त रूपों को बाहर रखें: संक्षिप्त रूपों को बचाएं, जब तक कि वे सार्वभौमिक रूप से समझे न जाएं।
ग्राहक_आईडीबेहतर हैग्राहक_आईडी। स्पष्टता को हमेशा संक्षिप्तता की तुलना में प्राथमिकता देनी चाहिए।
2. प्राथमिक की रणनीति को परिभाषित करें 🔑
हर टेबल को रिकॉर्ड को अलग करने के लिए एक अद्वितीय पहचानकर्ता होना चाहिए। प्राथमिक कुंजी के चयन का प्रदर्शन, इंडेक्सिंग और डेटा संबंधों पर प्रभाव पड़ता है।
- सरोगेट बनाम प्राकृतिक कुंजियाँ: तय करें कि क्या सरोगेट कुंजी (एक कृत्रिम ID जैसे ऑटो-इनक्रीमेंटिंग पूर्णांक या UUID) या प्राकृतिक कुंजी (पहले से मौजूद डेटा जैसे ईमेल पता) का उपयोग करना है। स्थिरता के लिए सरोगेट कुंजियों को अक्सर प्राथमिकता दी जाती है, क्योंकि प्राकृतिक कुंजियाँ समय के साथ बदल सकती हैं।
- इंडेक्सिंग के प्रभाव:प्राथमिक कुंजियाँ स्वचालित रूप से इंडेक्स की जाती हैं। यह सुनिश्चित करें कि चुनी गई कुंजी प्रकार संक्षिप्त हो। बड़ी कुंजियाँ (जैसे लंबे तारों) इंडेक्स को बढ़ा सकती हैं और जॉइन ऑपरेशन को धीमा कर सकती हैं।
- अद्वितीयता सीमाएँ:प्राथमिक कुंजी कॉलम को स्पष्ट रूप से चिह्नित करें
NOT NULL। एक प्राथमिक कुंजी किसी भी परिस्थिति में नॉल वैल्यू को नहीं रख सकती है। - संयुक्त कुंजियाँ: यदि एक टेबल को संयुक्त प्राथमिक कुंजी (बहुत सारे कॉलम) की आवश्यकता है, तो सुनिश्चित करें कि इस टेबल को संदर्भित करने वाला हर संबंध बहुत सारे कॉलम को हैंडल कर सकता है। इससे विदेशी कुंजी सीमाओं को जटिल बना सकता है।
3. विदेशी कुंजी संबंधों को मैप करें 🔗
संबंध यह निर्धारित करते हैं कि एकता कैसे बातचीत करती हैं। गलत संबंध मैपिंग से डेटा ओर्फन होने और संदर्भात्मक अखंडता की समस्याएँ हो सकती हैं।
- कार्डिनैलिटी: स्पष्ट रूप से निर्धारित करें कि क्या संबंध एक से एक, एक से बहुत या बहुत से बहुत है। एक से बहुत सबसे अधिक आम पैटर्न है रिलेशनल डेटाबेस में।
- बहुत से बहुत समाधान: एक बहुत से बहुत संबंध के लिए एक जंक्शन टेबल (लिंक टेबल) की आवश्यकता होती है। सुनिश्चित करें कि इस टेबल में दोनों मातृ एंटिटीज से विदेशी कुंजियाँ शामिल हैं और आवश्यकता हो तो इसके अपने लक्षण भी हैं।
- संदर्भात्मक क्रियाएँ: निर्दिष्ट करें कि डेटाबेस अपडेट या हटाने के लिए कैसे निपटे। सामान्य विकल्प हैं
CASCADE(बच्चे के रिकॉर्ड को हटाएं),SET NULL, याRESTRICT(हटाने को रोकें)। व्यावसायिक तर्क की आवश्यकताओं के आधार पर चुनें। - स्वयं-संदर्भित: यदि एक टेबल खुद को संदर्भित करती है (उदाहरण के लिए, एक कर्मचारी टेबल जिसमें मैनेजर कॉलम है), तो इस संबंध को स्पष्ट रूप से चिह्नित करें ताकि स्कीमा समीक्षा के दौरान भ्रम न हो।
4. डेटा नॉर्मलाइजेशन नियम लागू करें 🧹
नॉर्मलाइजेशन डेटा अतिरेक को कम करता है और अखंडता में सुधार करता है। जबकि आधुनिक प्रणालियाँ कभी-कभी प्रदर्शन के लिए नॉर्मलाइजेशन को वापस ले लेती हैं, इन रूपों को समझना निर्णायक है।
| नॉर्मल फॉर्म | आवश्यकता | लाभ |
|---|---|---|
| 1NF (पहला सामान्य रूप) | परमाणु मान, कोई दोहराए गए समूह नहीं | सुनिश्चित करता है कि प्रत्येक सेल में एक ही मान हो |
| 2NF (दूसरा सामान्य रूप) | कोई आंशिक निर्भरता नहीं | गैर-कुंजी कॉलम के पूरे कुंजी पर निर्भर रहने की गारंटी देता है |
| 3NF (तीसरा सामान्य रूप) | कोई स्थानांतरित निर्भरता नहीं | गैर-कुंजी कॉलम केवल कुंजी पर निर्भर रहने की गारंटी देता है |
- आवर्धन से बचें: यदि कोई जानकारी बहुत सारी टेबलों में संग्रहीत है, तो इसे एक ही स्थान पर संग्रहीत किया जाना चाहिए ताकि अपडेट विचलन से बचा जा सके।
- प्रदर्शन के साथ संतुलन बनाएं: सख्त सामान्यीकरण कठिन जॉइन की ओर जा सकता है। किसी भी जानबूझकर असामान्यीकरण निर्णयों को दस्तावेज़ित करें जो प्रश्न अनुकूलन के उद्देश्य से लिए गए हों।
- डेटा निर्भरता की जांच करें: सुनिश्चित करें कि कॉलम प्राथमिक कुंजी पर तार्किक रूप से निर्भर हैं और अन्य गैर-कुंजी कॉलम पर नहीं।
5. उपयुक्त डेटा प्रकार चुनें 📏
गलत डेटा प्रकार चुनने से स्टोरेज स्पेस का बर्बाद होना होता है और गणना त्रुटियों के कारण हो सकता है।
- पूर्णांक सटीकता: उपयोग करें
TINYINTछोटी संख्याओं के लिए (0-255) औरBIGINTबड़े आईडेंटिफायर के लिए। कभी भीINTसब कुछ के लिए उपयोग न करें यदिSMALLINTपर्याप्त है। - स्ट्रिंग लंबाई: सामान्य का उपयोग न करें
पाठयाVARCHAR(MAX)आवश्यकता होने पर। विशिष्ट लंबाई को परिभाषित करें (उदाहरण के लिए,VARCHAR(50)एक राज्य कोड के लिए) डेटा सीमाओं को लागू करने और इंडेक्सिंग की कार्यक्षमता में सुधार करने के लिए। - तारीख और समय: उपयोग करें
TIMESTAMPयाDATETIMEसमय क्षेत्र की आवश्यकताओं के आधार पर। सुनिश्चित करें कि प्रारूप संगत है (ISO 8601 एक मानक है)। तारीखों को तारीख के रूप में स्टोर करने से बचें। - बूलियन मान: यदि उपलब्ध हो, तो एक मूल बूलियन प्रकार का उपयोग करें। यदि नहीं, तो उपयोग करें
TINYINT(1)याCHAR(1)। बूलियन मानों को तारीख के रूप में स्टोर करने से बचें (“हाँ”/”नहीं”)।
6. प्रतिबंधों और डिफ़ॉल्ट मानों को लागू करें ⚖️
प्रतिबंध डेटाबेस स्तर पर डेटा गुणवत्ता की रक्षा करते हैं। केवल एप्लिकेशन स्तरीय सत्यापन पर निर्भर रहना जोखिम भरा है।
- नॉन नल: महत्वपूर्ण स्तंभों को चिह्नित करें
NOT NULL। इससे गायब डेटा के रिपोर्ट या तर्क को खराब करने से बचा जाता है। - यूनिक प्रतिबंध: ईमेल पते या उपयोगकर्ता नाम जैसे स्तंभों पर यूनिक प्रतिबंध लागू करें ताकि डुप्लीकेट प्रविष्टियों से बचा जा सके।
- डिफ़ॉल्ट मान: स्थिति स्तंभों के लिए समझदारी भरे डिफ़ॉल्ट मान सेट करें (उदाहरण के लिए,
स्थिति = 'सक्रिय') या समयांक त्रुटियों को बचने के लिए हाथ से दर्ज करने से बचें। - चेक सीमाएँ: व्यापार नियमों की पुष्टि करने के लिए चेक सीमाओं का उपयोग करें (उदाहरण के लिए,
उम्र > 18यामूल्य > 0). इससे यह सुनिश्चित होता है कि डेटा स्रोत के बावजूद तार्किक नियमों का पालन करता है।
7. इंडेक्सिंग रणनीति योजना बनाएं 🚀
इंडेक्स डेटा प्राप्ति को तेज करते हैं, लेकिन लेखन ऑपरेशन को धीमा करते हैं। एक संतुलित दृष्टिकोण आवश्यक है।
- विदेशी कुंजी इंडेक्स: हमेशा विदेशी कुंजी वाले कॉलम को इंडेक्स करें। यह ताबेदार तालिकाओं के बीच जॉइन ऑपरेशन के प्रदर्शन के लिए महत्वपूर्ण है।
- खोज कॉलम: उन कॉलम को पहचानें जिनका निरंतर उपयोग
जहां,क्रम में व्यवस्थित करें, यासमूह बनाएंक्लॉज में किया जाता है। इन कॉलम में इंडेक्स जोड़ें। - संयुक्त इंडेक्स: यदि क्वेरी एक से अधिक कॉलम पर फ़िल्टर करती है, तो एक संयुक्त इंडेक्स बनाएं। इंडेक्स में कॉलम के क्रम का महत्व है और इसे क्वेरी पैटर्न के अनुरूप होना चाहिए।
- अतिरिक्त इंडेक्सिंग से बचें: बहुत सारे इंडेक्स डिस्क उपयोग बढ़ाते हैं और
इनसर्ट,अपडेट, औरहटाएंऑपरेशन को धीमा करते हैं। प्रत्येक इंडेक्स की आवश्यकता की समीक्षा करें।
8. ऑडिट फ़ील्ड्स शामिल करें 🕒
ट्रेसेबिलिटी डिबगिंग और संगति के लिए महत्वपूर्ण है। व्यापार तर्क को संभालने वाली प्रत्येक तालिका को बदलावों को ट्रैक करना चाहिए।
- बनाए गए के समय: एक जोड़ें
बनाए गए के समयकॉलम जो रिकॉर्ड के पहले इन्सर्ट किए जाने के समय को रिकॉर्ड करे। - अपडेट किया गया समय: एक जोड़ें
अपडेट किया गया समयकॉलम जो अंतिम संशोधन समय को रिकॉर्ड करे। - सॉफ्ट डिलीट्स: कठोर डिलीट करने के बजाय, एक जोड़ने के बारे में सोचें
हटाया गया समयकॉलम। इससे आवश्यकता पड़ने पर डेटा को पुनर्स्थापित किया जा सकता है और संदर्भात्मक अखंडता को बनाए रखा जाता है। - किसने बदला: महत्वपूर्ण ऑडिट ट्रेल के लिए, एक शामिल करें
बनाया गया द्वाराऔरअपडेट किया गया द्वाराकॉलम जो क्रिया के लिए जिम्मेदार उपयोगकर्ता ID को स्टोर करे।
9. सुरक्षा और संगति का समाधान करें 🔒
डेटा सुरक्षा को स्कीमा में बेक किया जाना चाहिए, न कि बाद में जोड़ा जाए।
- PII का प्रबंधन: व्यक्तिगत रूप से पहचान योग्य जानकारी (PII) की पहचान करें जैसे कि एसएसएन, क्रेडिट कार्ड नंबर या स्वास्थ्य रिकॉर्ड। इन्हें एन्क्रिप्ट किया जाना चाहिए या टोकनाइज़ किया जाना चाहिए।
- डेटा वर्गीकरण: स्कीमा दस्तावेज़ीकरण में संवेदनशील कॉलम को लेबल करें ताकि डेवलपर्स को पता चले कि किन फ़ील्ड्स को अतिरिक्त सुरक्षा उपायों की आवश्यकता है।
- पहुंच नियंत्रण: जबकि विशिष्ट अनुमतियां अक्सर एप्लिकेशन या डेटाबेस उपयोगकर्ता स्तर पर सेट की जाती हैं, स्कीमा को डेटा संवेदनशीलता को दर्शाना चाहिए (उदाहरण के लिए, सार्वजनिक बनाम निजी डेटा के लिए अलग-अलग तालिकाएं)।
- रखरखाव नीतियां: सुनिश्चित करें कि स्कीमा डेटा रखरखाव आवश्यकताओं का समर्थन करता है। कुछ विधायी क्षेत्रों में एक निश्चित अवधि के बाद डेटा को हटाने की आवश्यकता होती है।
10. स्कीमा का दस्तावेज़ीकरण और प्रमाणीकरण करें 📄
दस्तावेज़ीकरण के बिना एक स्कीमा एक दायित्व है। दस्तावेज़ीकरण भविष्य के रखरखाव को सुनिश्चित करता है।
- डेटा शब्दकोश:हर टेबल, कॉलम और संबंध का वर्णन करने वाला एक दस्तावेज़ बनाए रखें। प्रत्येक क्षेत्र के लिए व्यापारिक परिभाषाएं शामिल करें।
- टिप्पणियां:जटिल तर्क या विशिष्ट व्यापारिक नियमों को समझाने के लिए DDL (डेटा परिभाषा भाषा) स्क्रिप्ट्स के भीतर SQL टिप्पणियों का उपयोग करें।
- दृश्य समीक्षा:चक्रीय संदर्भों, अनाथ टेबलों या गायब संबंधों की जांच करने के लिए दृश्य रूप से ERD उत्पन्न करें।
- सहकर्मी समीक्षा:एक अन्य वास्तुकार या सीनियर डेवलपर को मॉडल की समीक्षा करने के लिए कहें। ताज़ा आंखों वाले लोग अक्सर शुरुआती डिज़ाइन के दौरान छूट जाने वाली तार्किक त्रुटियों को पकड़ लेते हैं।
आम मॉडलिंग त्रुटियां और सुधार 🛠️
चेकलिस्ट की समीक्षा करना पर्याप्त नहीं है। आपको आम जाल में फंसने वाली बातों के बारे में भी जागरूक होना चाहिए।
| त्रुटि | परिणाम | सुधार |
|---|---|---|
| गैर-मौजूद विदेशी कुंजियां | अनाथ रिकॉर्ड, डेटा असंगति | स्पष्ट विदेशी कुंजी प्रतिबंध जोड़ें |
| चौड़ी टेबलें | पढ़ने में कठिन, धीमी क्वेरीज़ | संबंधित टेबलों में विभाजित करें (नॉर्मलाइज़ेशन) |
| अप्रत्यक्ष संबंध | विकास के दौरान भ्रम | ERD में स्पष्ट रेखाएं खींचें, FK कॉलम जोड़ें |
| नलता संबंधी समस्याएं | एप्लिकेशन में तार्किक त्रुटियां | सेट करें NOT NULLजहां डेटा आवश्यक हो |
| कड़े हुए आईडी | माइग्रेशन में कठिनाइयां | हार्डकोडेड ID के बजाय विदेशी कुंजियों का उपयोग करें |
स्कीमा डिज़ाइन पर अंतिम विचार 🎯
एक डेटाबेस मॉडल बनाना सख्त अखंडता और व्यावहारिक प्रदर्शन के बीच संतुलन है। इस चेकलिस्ट का पालन करने से यह सुनिश्चित होता है कि आपकी डेटा संरचना गुणवत्ता के नुकसान के बिना व्यावसायिक आवश्यकताओं को समर्थन देती है। स्कीमा को संस्करण नियंत्रण में समर्पित करने से पहले प्रत्येक चरण की समीक्षा करने के लिए समय निकालें। एरडी के मान्यता प्राप्त करने में आने वाले कुछ घंटे बाद के डिबगिंग और पुनर्गठन में सप्ताहों की बचत कर सकते हैं।
याद रखें कि एक डेटाबेस मॉडल एक जीवित दस्तावेज है। जैसे-जैसे व्यावसायिक आवश्यकताएं बदलती हैं, स्कीमा को विकसित होना चाहिए। इस चेकलिस्ट के खिलाफ नियमित ऑडिट आपकी डेटा संरचना को स्वस्थ रखेंगे और आपके लक्ष्यों के साथ संरेखित रखेंगे। हर निर्णय में स्पष्टता, सामंजस्य और अखंडता को प्राथमिकता दें।
इन दस चरणों का पालन करने से आप अपने एप्लिकेशन के लिए एक ठोस आधार स्थापित करते हैं। आपकी टीम स्पष्टता की सराहना करेगी, और आपके उत्पादन वातावरण को कम त्रुटियों और बेहतर प्रदर्शन के लाभ मिलेंगे। चेकलिस्ट को अपने विकास कार्यप्रणाली का मानक हिस्सा बनाएं।