











बैकएंड विकास अक्सर एक नक्शे के बिना घर बनाने जैसा महसूस करता है। आप बिना योजना के ईंटें रखना शुरू करते हैं, खिड़कियाँ लगाते हैं और दीवारों का ढांचा बनाते हैं। कभी-कभी यह काम करता है। अक्सर नहीं। कई हफ्तों बाद, आपको एक दरवाजे के लिए जगह बनाने के लिए दीवारें तोड़नी पड़ती हैं जिसके बारे में आपने योजना बनाई नहीं थी। यह उस वास्तविकता का प्रतिनिधित्व करता है जब आप एक ठोस योजना के बिना कोडिंग करते हैंएंटिटी रिलेशनशिप डायग्राम (ERD)। ERD आपकी डेटा इंफ्रास्ट्रक्चर का चुप्पी आर्किटेक्ट है, जो लागत वाले संरचनात्मक विफलताओं को रोकने के लिए पीछे से काम करता है। जब आप कोड लिखने से पहले अपने डेटा मॉडल को डिज़ाइन करने में समय लगाते हैं, तो आप स्पष्टता प्राप्त करते हैं, तकनीकी देनदारी कम करते हैं और टीमों के बीच सहयोग को आसान बनाते हैं।
यह गाइड बैकएंड वर्कफ्लो में ERD के भावी प्रभाव का अध्ययन करता है। हम डेटा मॉडलिंग के तकनीकी पहलुओं, डिज़ाइन छोड़ने की छुपी लागत और अच्छी तरह से दस्तावेज़ीकृत स्कीमा के रणनीतिक लाभों को समझेंगे। इन सिद्धांतों को समझकर, आप प्रतिक्रियात्मक कोडिंग से सक्रिय आर्किटेक्चर की ओर बदल सकते हैं।
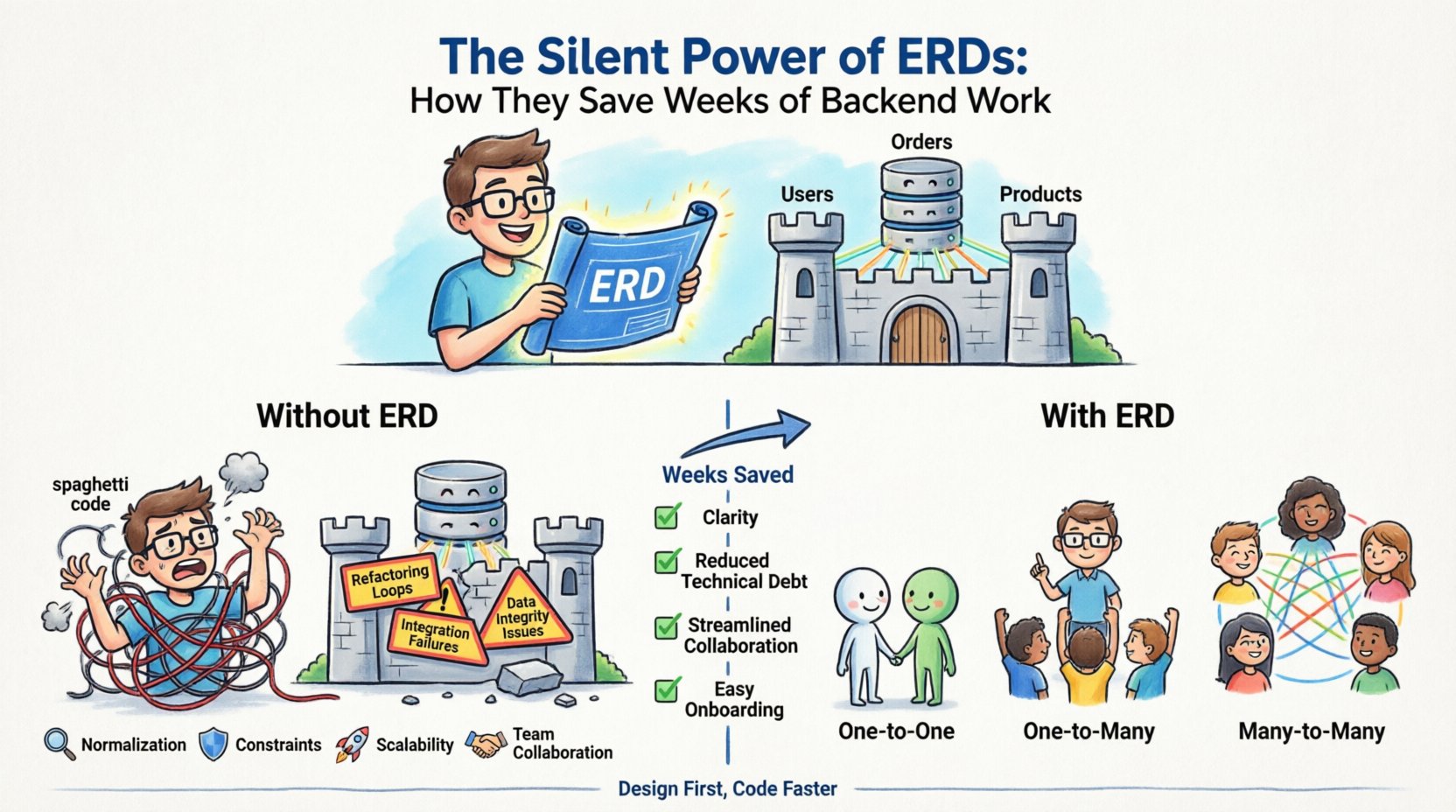
एक ERD वास्तव में क्या है? 📐
एक एंटिटी रिलेशनशिप डायग्राम एक डेटाबेस की तार्किक संरचना का दृश्य प्रतिनिधित्व है। यह यह दिखाता है कि विभिन्न डेटा के टुकड़े एक दूसरे से कैसे संबंधित हैं। इसे अपने एप्लिकेशन की मेमोरी के लिए एक नक्शा समझें। इस नक्शे के बिना, डेवलपर्स अंधेरे में घूमते हैं, जिससे उन डेटा बिंदुओं के बीच टकराव का खतरा होता है जो अलग-अलग रहने चाहिए।
इसके मूल में, एक ERD तीन मुख्य घटकों से बना होता है:
- एंटिटीज: ये वस्तुओं या अवधारणाओं का प्रतिनिधित्व करते हैं जिन्हें आप ट्रैक कर रहे हैं। डेटाबेस में, इन्हें टेबल में बदला जाता है। उदाहरण के लिएउपयोगकर्ता, आदेश, याउत्पाद.
- गुण: ये एक एंटिटी के विशिष्ट गुण हैं। ये आपकी टेबलों के कॉलम बन जाते हैं। एकउपयोगकर्ता एंटिटी के लिए, गुणों में शामिल हो सकते हैंईमेल, पासवर्ड हैश, औरबनाया गया है.
- संबंध: ये एंटिटीज के बीच बातचीत को परिभाषित करते हैं। वे टेबलों के बीच कार्डिनैलिटी और कनेक्टिविटी को निर्धारित करते हैं, जैसे कि एकउपयोगकर्ता कई के साथ होनाआदेश.
जबकि अवधारणा सरल लगती है, पैमाने के प्रबंधन के समय जटिलता उत्पन्न होती है। एक सरल ब्लॉग को केवल कुछ टेबल की आवश्यकता हो सकती है। एक एंटरप्राइज सिस्टम को दर्जनों, यदि नहीं तो सैकड़ों एक साथ जुड़े हुए एंटिटी की आवश्यकता होती है। ईआरडी इन सभी बातचीत के लिए एकमात्र सच्चाई का स्रोत के रूप में कार्य करता है।
डिज़ाइन छोड़ने की छुपी लागत 💸
बहुत से डेवलपमेंट टीम डेडलाइन पूरी करने के लिए कोडिंग की ओर जल्दी करते हैं। वे मानते हैं कि बाद में डेटाबेस को रिफैक्टर किया जा सकता है। यह एक खतरनाक मान्यता है। डेटाबेस स्कीमा बदलना एप्लीकेशन लॉजिक बदलने से काफी अधिक महंगा होता है। जब डेटा लिख दिया जाता है, तो उसकी संरचना बदलने के लिए माइग्रेशन स्क्रिप्ट, संभावित बंदी और मौजूदा रिकॉर्ड्स के सावधानी से प्रबंधन की आवश्यकता होती है।
निम्नलिखित परिदृश्यों पर विचार करें जहां ईआरडी की कमी के कारण अड़चन आती है:
- रिफैक्टरिंग लूप्स: आप एक फीचर बनाते हैं, फिर पता चलता है कि डेटा संरचना इसका समर्थन नहीं करती है, और आपको क्वेरी को फिर से लिखना पड़ता है। यह चक्कर दोहराया जाता है, जिससे स्प्रिंट समय के हफ्तों का नुकसान होता है।
- इंटीग्रेशन विफलताएं: जब फ्रंटएंड और बैकएंड टीमें साझा स्कीमा परिभाषा के बिना काम करती हैं, तो एपीआई अक्सर टूट जाती हैं। बैकएंड एक संरचना भेजता है; फ्रंटएंड दूसरी संरचना की उम्मीद करता है।
- डेटा अखंडता की समस्याएं: परिभाषित सीमाओं के बिना, अमान्य डेटा सिस्टम में प्रवेश करता है। आपको अनाथ रिकॉर्ड्स को साफ करने या असंगत स्थितियों को हाथ से ठीक करने के लिए मजबूर होना पड़ता है।
- ऑनबोर्डिंग देरी: नए डेवलपर्स सिस्टम को समझने में कठिनाई महसूस करते हैं। वे डेटा फ्लो अनाधिकृत होने के कारण फीचर बनाने के बजाय कोड पढ़ने में दिनों बर्बाद कर देते हैं।
जब आप समस्या को नोटिस करते हैं, तो लागत बढ़ चुकी होती है। अब “फिक्स” के लिए केवल कोड बदलाव के अलावा डेटा माइग्रेशन, परीक्षण और डेप्लॉयमेंट की पुष्टि की आवश्यकता होती है।
प्रो की तरह संबंधों को मैप करना 🔗
डेटा के कैसे जुड़ने के बारे में समझना ईआरडी डिज़ाइन का केंद्र बिंदु है। संबंध यह तय करते हैं कि क्वेरी कैसे लिखी जाती है और प्रदर्शन को कैसे अनुकूलित किया जाता है। आपको स्पष्ट रूप से तीन प्रमुख प्रकार के संबंधों को परिभाषित करना होगा।
नीचे दी गई तालिका इन संबंध प्रकारों के बीच के अंतरों को दर्शाती है:
| संबंध प्रकार | परिभाषा | उदाहरण परिदृश्य | कार्यान्वयन नोट |
|---|---|---|---|
| एक से एक (1:1) | टेबल A में एक एकल रिकॉर्ड टेबल B में बिल्कुल एक रिकॉर्ड से संबंधित होता है। | एक उपयोगकर्ता प्रोफाइल जो उपयोगकर्ता सेटिंग्स टेबल से जुड़ा है। | आमतौर पर B के प्राथमिक कुंजी को A में रखकर कार्यान्वित किया जाता है। |
| एक से बहुत (1:N) | टेबल A में एक एकल रिकॉर्ड टेबल B में बहुत सारे रिकॉर्ड्स से संबंधित होता है। | एक श्रेणी जिसमें कई उत्पाद हैं। | बहुत सारे पक्ष वाली टेबल में मानक विदेशी कुंजी स्थापना। |
| बहु-से-बहु (M:N) | तालिका A में कई रिकॉर्ड तालिका B में कई रिकॉर्ड से संबंधित होते हैं। | कई कोर्सेज में दर्ज हुए छात्र। | संबंध को हल करने के लिए एक जंक्शन तालिका की आवश्यकता होती है। |
इन अंतरों को नजरअंदाज करने से अकुशल क्वेरीज बनती हैं। उदाहरण के लिए, एक श्रेणी के लिए एक ही कॉलम में उत्पाद आईडी की सूची संग्रहीत करना नॉर्मलाइजेशन के सिद्धांतों के विरुद्ध है। इससे आपको जॉइन्स के बजाय स्ट्रिंग्स को पार्स करने के लिए मजबूर किया जाता है, जिससे डेटा बढ़ने के साथ प्रदर्शन धीमा हो जाता है।
नॉर्मलाइजेशन: डेटा को साफ रखना 🧹
नॉर्मलाइजेशन डेटा को कम रिडंडेंसी और बेहतर अखंडता के लिए व्यवस्थित करने की प्रक्रिया है। जबकि आधुनिक प्रणालियाँ कभी-कभी प्रदर्शन के लिए सख्त नॉर्मलाइजेशन से विचलित होती हैं, लेकिन सिद्धांतों को समझना अभी भी आवश्यक है।
नॉर्मलाइजेशन के मानक रूप निम्नलिखित हैं:
- पहला नॉर्मल रूप (1NF):परमाणुता सुनिश्चित करता है। प्रत्येक कॉलम में केवल एक मान होता है। एक ही सेल में सूचियाँ या ऐरे नहीं होती हैं।
- दूसरा नॉर्मल रूप (2NF):1NF पर आधारित है। सभी गैर-की विशेषताओं को मुख्य की पर पूर्ण निर्भरता होनी चाहिए। आंशिक निर्भरता नहीं होनी चाहिए।
- तीसरा नॉर्मल रूप (3NF):2NF पर आधारित है। गैर-की विशेषताओं को केवल मुख्य की पर निर्भर होना चाहिए, अन्य गैर-की विशेषताओं पर नहीं।
इसका क्यों महत्व है? एक को ध्यान में रखेंआर्डर तालिका। यदि आप ग्राहक का नाम हर आर्डर पंक्ति में संग्रहीत करते हैं, तो आप रिडंडेंसी बनाते हैं। यदि ग्राहक अपना नाम बदलता है, तो आपको हजारों पंक्तियों को अपडेट करना होगा। यदि आप एक को भी छोड़ देते हैं, तो आपके डेटा असंगत हो जाते हैं। जब आप ग्राहक का नाम को एक ग्राहकोंतालिका में लिंक करने के लिए आईडी का उपयोग करके, आप एकमात्र सत्य के स्रोत को सुनिश्चित करते हैं।
हालांकि, नॉर्मलाइजेशन एक सुनहरी गोली नहीं है। अत्यधिक नॉर्मलाइजेशन के कारण जटिल जॉइन्स बन सकते हैं जो प्रदर्शन को नुकसान पहुंचाते हैं। लक्ष्य संतुलन है। आपको स्टोरेज दक्षता और क्वेरी गति के बीच ताने-बाने को समझना होगा।
स्कीमा डिजाइन में आम गलतियाँ 🚧
यहां तक कि अनुभवी डेवलपर्स भी ईआरडी डिजाइन करते समय गलतियां करते हैं। इन आम जालों को पहचानने से आपको बाद में बहुत दुख बच सकता है।
- चक्रीय निर्भरता:एंटिटी A को एंटिटी B की आवश्यकता होती है, और एंटिटी B को एंटिटी A की आवश्यकता होती है। इससे प्रारंभीकरण में डेडलॉक बनता है और माइग्रेशन स्क्रिप्ट्स लिखना मुश्किल हो जाता है।
- अनुपस्थित सीमाएं:विदेशी की, यूनिक सीमाएं या चेक सीमाएं परिभाषित करने में विफलता अमान्य डेटा के फटकार में जाने देती है। डेटाबेस को नियमों को लागू करना चाहिए, न कि एप्लीकेशन कोड।
- कड़े मान: “सक्रिय” या “निष्क्रिय” जैसे स्थिति कोड को लुकअप तालिका के बिना पूर्णांक के रूप में संग्रहीत करना प्रणाली को नाजुक बना देता है। यदि आप “निलंबित” जोड़ने की आवश्यकता महसूस करते हैं, तो आपको सभी जगह तर्क को बदलना होगा।
- मृदु डिलीट को नजरअंदाज करना: डेटा को स्थायी रूप से हटाने से इतिहास नष्ट हो जाता है। मृदु डिलीट के लिए डिज़ाइन करना (एक रिकॉर्ड को हटाने के बजाय उसे हटाए गए के रूप में चिह्नित करना) ऑडिट ट्रेल को बरकरार रखता है।
- अत्यधिक डिज़ाइन करना: अभी तक अस्तित्व में नहीं आए उपयोग के मामले के लिए डिज़ाइन करना। वर्तमान आवश्यकताओं के लिए बनाएं, लेकिन सुनिश्चित करें कि स्कीमा पर्याप्त लचीला है ताकि उचित वृद्धि को संभाल सके।
इनमें से प्रत्येक त्रुटि आपके कोडबेस में जटिलता के परतें जोड़ती है। एक एरडी आपको उन समस्याओं को उत्पादन में एम्बेड होने से पहले देखने में मदद करता है।
चित्र से कार्यान्वयन तक 🚀
जब एरडी को अंतिम रूप दे दिया जाता है, तो अगला चरण इसे कोड में बदलना होता है। इस प्रक्रिया को अक्सर स्कीमा माइग्रेशन कहा जाता है, जिसमें अनुशासन की आवश्यकता होती है।
एक चिकनी संक्रमण सुनिश्चित करने के लिए इन चरणों का पालन करें:
- संस्करण नियंत्रण: अपने डेटाबेस स्कीमा को एप्लिकेशन कोड की तरह लें। प्रत्येक बदलाव को अपने रिपोजिटरी में संग्रहीत माइग्रेशन फ़ाइल के रूप में रखना चाहिए।
- पीछे की ओर संगतता: जब किसी कॉलम को जोड़ते हैं, तो पहले उसे nullable बनाएं। मौजूदा डेटा को भरें, फिर एक बाद के माइग्रेशन में प्रतिबंध को लागू करें। इससे डाउनटाइम से बचा जा सकता है।
- माइग्रेशन का परीक्षण: उत्पादन के समान एक स्टेजिंग पर्यावरण में माइग्रेशन स्क्रिप्ट चलाएं। प्रदर्शन में गिरावट की जांच करें।
- रोलबैक योजनाएं: हमेशा एक तरीका होना चाहिए जिससे यदि माइग्रेशन विफल हो जाए तो उसे वापस ले लिया जा सके। डेटा के नुकसान को अस्वीकार्य माना जाता है।
स्वचालन उपकरण एरडी से एसक्यूएल उत्पन्न करने में सहायता कर सकते हैं, लेकिन मैन्युअल समीक्षा निर्णायक है। स्वचालित जनरेटर अक्सर व्यापार तर्क के बारीकियों को छोड़ देते हैं जिन्हें एक मानव वास्तुकार पकड़ लेगा।
सहयोग और संचार 🤝
एक एरडी केवल डेटाबेस प्रशासकों के लिए नहीं है। यह पूरी टीम के लिए संचार उपकरण के रूप में कार्य करता है। उत्पाद प्रबंधक, फ्रंटएंड विकासकर्ता और क्वालिटी एस्पेक्ट � ing इंजीनियर सभी डेटा संरचना को समझने से लाभान्वित होते हैं।
जब रुचि रखने वाले पक्ष एरडी की समीक्षा करते हैं, तो वे जल्दी से संभावित समस्याओं की पहचान कर सकते हैं:
- फीचर की वास्तविकता: क्या डेटाबेस अनुरोधित फीचर का समर्थन कर सकता है? यदि नहीं, तो क्या बदलाव की आवश्यकता है?
- प्रदर्शन की अपेक्षाएं: क्या डिज़ाइन बड़े पैमाने पर कुशल प्रश्न पूछने की अनुमति देता है?
- सुरक्षा आवश्यकताएं: क्या संवेदनशील फील्ड की पहचान की गई है और सुरक्षित की गई है? क्या डेटा स्तर पर एक्सेस नियंत्रण संभव है?
इस साझा समझ से स्प्रिंट योजना के दौरान घर्षण कम होता है। डेटा के प्रवाह के बारे में अनुमान लगाने के बजाय, टीम एक दृश्य मॉडल के आधार पर इसके बारे में चर्चा करती है। असहमतियों को विचार के बजाय आरेख के संदर्भ में हल किया जाता है।
स्केलेबिलिटी के मामले 📈
जैसे आपका एप्लिकेशन बढ़ता है, आपके डेटा मॉडल को विकसित होना चाहिए। एक एरडी आपको इन परिवर्तनों की भविष्यवाणी करने में मदद करता है। यह आपको एक नए एंटिटी को जोड़ने के मौजूदा संबंधों पर क्या प्रभाव पड़ता है, इसे देखने की अनुमति देता है।
डिजाइन के दौरान ध्यान रखने योग्य मुख्य स्केलेबिलिटी कारक:
- इंडेक्सिंग रणनीति:वे कॉलम पहचानें जिन्हें अक्सर प्रश्न किया जाएगा। इन फील्ड्स पर इंडेक्स बनाने की योजना बनाएं ताकि प्राप्त करने में तेजी आए।
- पार्टीशनिंग:क्या कुछ टेबल बहुत बड़ी हो जाएंगी? आवश्यकता पड़ने पर क्षैतिज पार्टीशनिंग की योजना बनाएं।
- रीड/राइट स्प्लिट:क्या डिजाइन अलग-अलग रीड और राइट रिप्लिका का समर्थन करता है? सुनिश्चित करें कि विदेशी कुंजियाँ प्रतिलिपि बनाने में जटिलता न लाएं।
- कैशिंग लेयर्स:डेटा मॉडल कैश सिस्टम के साथ कैसे बातचीत करता है? बार-बार बदलने वाले डेटा की तुलना में अपरिवर्तनीय डेटा को कैश करना आसान होता है।
स्केल के बारे में शुरुआती चरण में सोचने से बाद में पूरी तरह से लिखने की आवश्यकता नहीं पड़ती है। एक नई टेबल जोड़ना एक सर्वर से डेटा ले जाने की तुलना में आसान है।
डेटा आर्किटेक्चर पर अंतिम विचार 🧠
एक विस्तृत एरडी बनाने में लगाए गए प्रयास प्रोजेक्ट के जीवनकाल भर लाभ देते हैं। यह डेटा मॉडलिंग को एक प्रतिक्रियाशील कार्य से एक रणनीतिक संपत्ति में बदल देता है। संबंधों को दृश्यमान बनाने, प्रतिबंधों को लागू करने और वृद्धि की योजना बनाने से आप ऐसी प्रणालियाँ बनाते हैं जो टिकाऊ और रखरखाव योग्य होती हैं।
डेटाबेस को बाद में सोचने वाली चीज के रूप में न लें। यह आपके एप्लिकेशन की नींव है। डिजाइन चरण में निवेश करें, और लंबे समय में आप हफ्तों के बैकएंड काम को बचा सकते हैं। एरडी की चुप्पी शक्ति उसकी क्षमता में निहित है कि वह समस्याओं को उत्पन्न होने से पहले ही रोक सकता है।
आज ही अपने डेटा को मैप करना शुरू करें। जो स्पष्टता आपको मिलेगी, वह एक अव्यवस्थित कोडबेस और एक सुव्यवस्थित प्रणाली के बीच का अंतर होगी।