











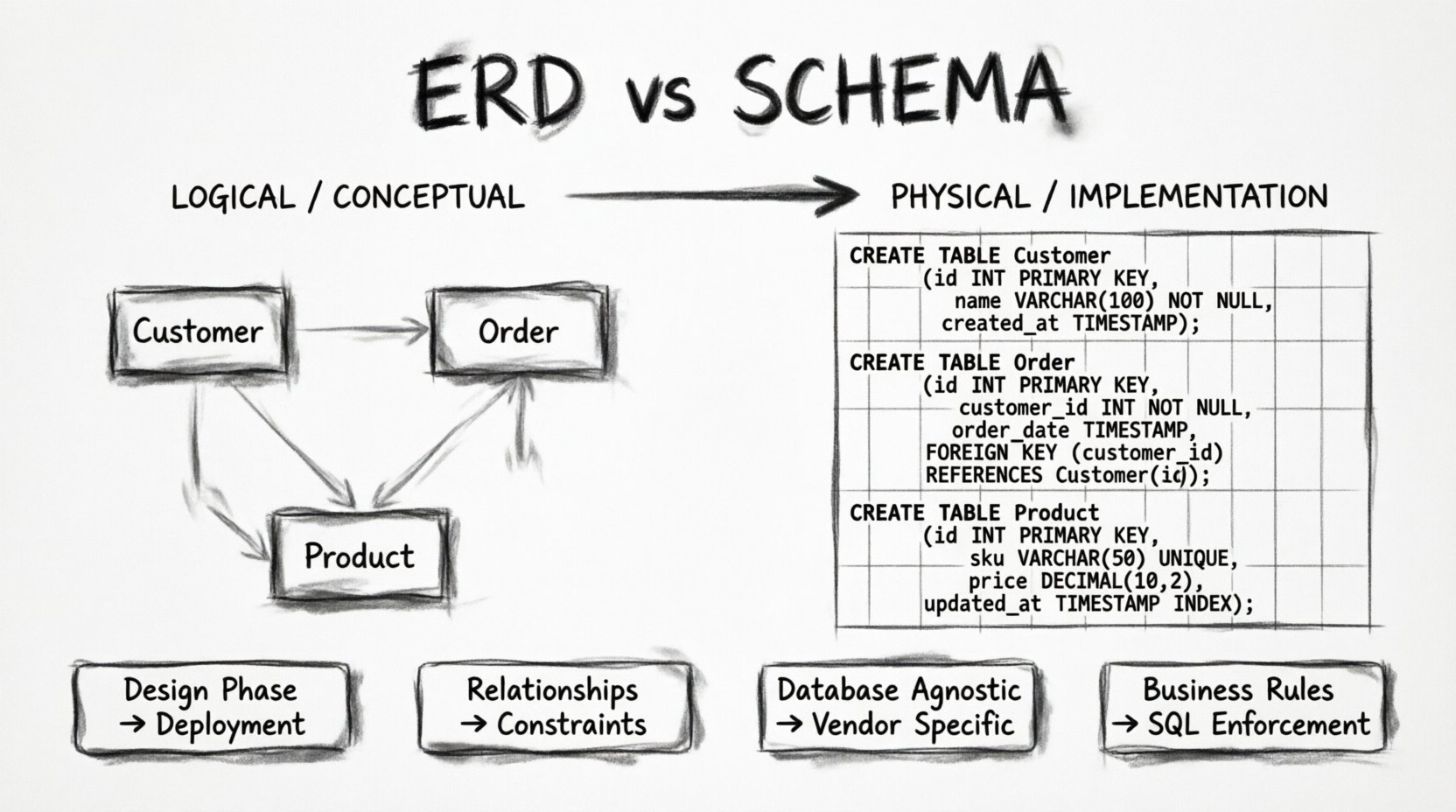
データベース設計は、いかなる堅牢なソフトウェアアプリケーションの基盤である。しかし、経験豊富なエンジニアですら、視覚的な設計図と物理的な実装の違いを説明する際に、しばしばつまずくことがある。混乱の原因は、通常、エンティティ関係図(ERD)とデータベーススキーマの間にある。これらの用語は、日常的な会話では頻繁に互換的に使われるが、データアーキテクチャプロセスの異なる段階を表している。それらの違いを理解することは、単なる学術的な問題ではない。データの流れ、制約の適用方法、システムの時間経過に伴う進化の仕方を決定するのである。
本ガイドでは、データモデリングの理論的構造を、データベース管理システムの実践的現実と対比して検証する。抽象的な概念が具体的な構造にどのように変換されるか、その変換の影響、そして両者の明確な精神的分離を保つことが長期的な保守性にとってなぜ重要かを検討する。新しいシステムを設計している場合でも、既存のシステムを再構築している場合でも、ここでの明確さが高コストな技術的負債を防ぐ。
そもそもERDとは何か? 📐
エンティティ関係図(ERD)は、データの概念的または論理的な表現である。ビジネス関係者、アナリスト、開発者との間のコミュニケーションの橋渡しとして機能する。主な目的は、特定のデータベースエンジンの詳細に囚われることなく、データ要素どうしがどのように関係しているかを可視化することである。
本質的に、ERDは3つの基本的な要素に注目する:
- エンティティ: これらは現実世界のオブジェクトや概念を表す。小売システムでは、エンティティとして「顧客, 製品」、または「注文」が挙げられる。エンティティは、データ宇宙における名詞である。
- 属性: これらはエンティティを記述する性質や特徴である。たとえば「顧客」の場合、属性には「氏名, メールアドレス」、または「登録日」が含まれる。属性は、エンティティについて保存する必要があるデータを定義する。
- 関係: これはエンティティどうしの相互作用を定義する。1人の顧客が多数の注文を行うのか?1つの製品が複数のカテゴリに属するのか?関係は、名詞をつなぐ動詞である。
ERDの美しさは、その抽象性にある。データが最終的にPostgreSQL、MySQL、またはNoSQLドキュメントストアに格納されるかどうかは、気にしない。情報の整合性と論理的な流れにのみ関心がある。表記スタイルはさまざまであるが、クラウズフット表記は、基数(1対1、1対多、多対多)を示すための一般的な標準である。この視覚的言語により、コードが1行も書かれる前でも、データモデルの論理を検証できる。
ERDを作成する際の焦点は正規化にある。これは、データの重複を減らし、データの整合性を高めるためにデータを整理することを意味する。大きなテーブルを、関連性のある小さなテーブルに分割する方法を検討し、1か所で情報を更新すれば、それが重要となるすべての場所で更新されることを保証する。ERDは領土の地図である。道やランドマークは示すが、具体的な舗装素材までは示さない。
データベーススキーマの定義 🏗️
ERDが地図なら、スキーマはその領土そのものである。データベーススキーマは、データベースの物理的構造である。データベース管理システム(DBMS)に、データをどのように格納するかを正確に指示する、具体的な定義の集合である。ERDは概念で語るが、スキーマはデータ型、制約、ストレージエンジンで語る。
スキーマは以下の技術的詳細を定義します:
- テーブル: ERDのエンティティは物理的なテーブルになります。スキーマはテーブル名を指定し、多くの場合、厳格な命名規則(例:snake_case)に従う必要があります。
- データ型: 属性である Age は
INTまたはSMALLINT。属性である Email は特定の長さ制限を持つVARCHARになります。属性である Timestamp はTIMESTAMP WITH TIME ZONEになります。これらの選択はストレージ領域とクエリのパフォーマンスに影響します。 - 制約: これがERDの論理が強制される場所です。主キー(PK)は一意性を保証します。外部キー(FK)はテーブル間の参照整合性を維持します。
NOT NULL制約は必須フィールドが入力されることを保証します。一意制約は重複エントリの防止を図ります。 - インデックス: 高レベルのERDではしばしば省略されますが、スキーマがインデックスの構築場所を決定します。インデックスは読み取り操作を高速化しますが、書き込みを遅くします。スキーマはデータベースの物理的最適化を規定します。
スキーマはセキュリティおよびアクセス制御の責任も負います。特定のテーブルに対する読み取りまたは書き込みを許可するユーザーを定義します。トランザクションを処理し、データの変更が原子的であることを保証します。開発者が CREATE TABLE ステートメントを記述するとき、彼らはスキーマを定義しているのです。これはアプリケーションコードが直接対話する実装レイヤーです。
主な違いを一目で見比べる 📊
違いを明確にするために、違いを並べて見比べると役立ちます。ERDは抽象的で設計志向であり、一方でスキーマは具体的で実装志向です。
| 機能 | ERD(エンティティ関係図) | データベーススキーマ |
|---|---|---|
| 性質 | 論理モデル/概念モデル | 物理モデル |
| 焦点 | 関係性とデータフロー | ストレージと強制 |
| 表記法 | ボックス、線、クロウズフット記号 | SQL文、DDLスクリプト |
| 依存関係 | データベースに依存しない | データベース固有(ベンダー) |
| 制約 | 暗黙の(ビジネスルール) | 明示的(PK、FK、チェック) |
| 段階 | 設計段階 | 開発/展開段階 |
この表は、それらが関連しているものの、ソフトウェアライフサイクルの異なる段階で動作することを強調しています。両者を混同すると、検証が完全に行われる前に、開発者が物理的制約を論理モデルに強制しようとする傾向があります。
翻訳プロセス:図からコードへ 🔄
ERDからスキーマへの移行は、常に直接的な1:1の対応とは限りません。この翻訳層が、多くのプロジェクトで摩擦を生じる原因となります。論理モデルは理想的な状態を仮定しますが、物理モデルはパフォーマンス、レガシーシステム、特定のエンジン機能といった課題に対処しなければなりません。
正規化 vs. パフォーマンス
ERDは通常、第三正規形(3NF)に正規化されます。これによりデータの重複を最小限に抑えます。しかし、高トラフィックのアプリケーション用のスキーマに翻訳する際、開発者はしばしば非正規化を行います。これは、クエリ実行時に必要な結合の数を減らすために、意図的にデータを重複させることを意味します。例えば、顧客名を直接注文テーブルに保存することです。これは厳格な正規化ルールに違反する可能性がありますが、レポートクエリの実行速度を著しく向上させます。ERDでは関係性が示されるかもしれませんが、スキーマでは速度を考慮してデータを重複して保存する場合があります。
データ型の詳細
ERDは単に、フィールドが「」であると述べているだけです日付。スキーマは「」のどちらかを決定しなければなりませんDATE, DATETIME、またはTIMESTAMP。文字セット(UTF8、ASCII)と照合規則を決定しなければなりません。これらの決定は、アプリケーションが国際化や並べ替えをどのように扱うかに影響します。一般的なERDでは、これらの微細な点を捉えることはできません。
多対多関係の扱い方
ERDでは、多対多関係は二重のカラスの足の線で描かれます。物理的なスキーマでは、これ自体は直接存在できません。結合テーブル(またはブリッジテーブル)を介して、二つの1対多関係に分解しなければなりません。この結合テーブルの主キーをスキーマで定義しなければなりません。これは複合キーまたはサロゲートキー(UUID)である可能性があります。この構造的変更は高レベルの図では見えませんが、データベース構造においては非常に重要です。
開発者にとってこの違いが重要な理由 🛠️
この二つの概念の違いを理解することは、理論的なことだけではなく、日々の作業に影響を与えます。データ整合性にバグが発生した場合、問題が論理設計にあるのか、物理的実装にあるのかを知ることは、解決への第一歩です。
データ整合性のデバッグ
予期せぬデータの重複が発生した場合、次のように尋ねるべきです:ERDに欠陥があるのか、それともスキーマの制約が欠けているのか?スキーマに外部キーが欠けていると、ERDの論理が不可能と想定していた孤立レコードが許可されてしまいます。逆に、ERDが厳しすぎてソフトデリートを考慮していない場合、スキーマがハードデリートを強制し、ビジネスロジックを破壊する可能性があります。これらの問題を分離することで、エラーの原因を明確に特定できます。
バージョン管理とコラボレーション
データベースを管理する際、バージョン管理は不可欠です。しかし、ERDとスキーマは異なる方法で進化します。ビジネス要件が変化するとERDが変更されます。データベースの最適化が必要になったり、マイグレーションが適用されるとスキーマが変更されます。これらを同期させるのは難しい課題です。スキーマが変更されてもERDが更新されない場合、ドキュメントは陳腐化します。ERDが変更されてもマイグレーションスクリプトが作成されない場合、データベースは設計と整合性を失います。
新メンバーのオンボーディング
新規開発者はしばしばデータベース構造を理解するのに苦労します。ERDを提示することで、システムが概念的にどのように動作するかの文脈を提供できます。スキーマを提示することで、システムが技術的にどのように動作するかの文脈を提供できます。効果的なオンボーディングには両方が必要です。ERDは「」に答え、「これはどういう意味ですか?」そしてスキーマは「どうやってアクセスすればいいですか?」に答えます.
データモデリングにおける一般的な落とし穴 🚧
明確な定義があるにもかかわらず、多くのチームはERDとスキーマを同一視することによって罠にはまってしまいます。
- ERDを飛ばす:SQLスキーマスクリプトを直ちに書くと、構造的負債が生じる傾向があります。視覚的なモデルがないと、関係性が忘れられたり、一貫性のない実装が行われることがあります。
- 制約を無視する:ユニークなメールアドレスなどのルールを、アプリケーションコードにのみ依存して実装する(データベースの制約(UNIQUEインデックス)を用いない)のは危険です。スキーマはデータ整合性の最後の防衛線でなければなりません。
- 過剰設計:要件が明確になる前から、すべての可能な属性を含むあまり詳細なERDを作成すること。これにより、後で移行が困難なスキーマが生じる。
- ツールの断絶:コード生成をサポートしない設計ツールを使用する、またはリバースエンジニアリングをサポートしないデータベースツールを使用する。これにより、一方で変更が行われるが他方では行われない手動のギャップが生じる。
- 同等性を仮定する:完璧なERDがあれば完璧なデータベースが保証されると思い込むこと。スキーマはERDが予見できないハードウェアの制限、クエリパターン、並行処理の問題に影響を受ける。
時間の経過に伴う同期の維持 🔄
アプリケーションが成長するにつれて、データベースも進化する。機能が追加され、古い機能は非推奨になる。ERDとスキーマのリンクを維持することが、時間の経過とともに難しくなる。これはしばしばスキーマのずれ.
これを防ぐため、チームは厳格なワークフローを採用すべきである:
- 設計を最優先する:移行スクリプトを書く前に、常にERDを更新する。
- 生成を自動化する:ERDからSQL DDLを生成できるツールを使用する。これにより、スキーマが設計と一致することを保証する。
- リバースエンジニアリング:定期的にライブデータベース上でリバースエンジニアリングツールを実行し、ERDを更新する。これにより、設計プロセスを迂回して直接SQLクエリで行われた変更を検出できる。
- ドキュメント化: ERDがスキーマ移行スクリプトと同じリポジトリに格納されていることを確認する。これにより、単一の真実の源が作られる。
この規律により、データベースがブラックボックス化するのを防ぐ。ERDとスキーマが同期しているとき、システムは透明性を保ち、管理可能である。
クエリのパフォーマンスと最適化への影響 ⚡
スキーマがパフォーマンスに与える影響はERDよりも大きい。ERDは関係を示すが、スキーマがデータベースエンジンがデータにアクセスする方法を決定する。ERDは「Users」と「Posts」の論理的な結合を示すかもしれない。Users と Posts。スキーマが、「Posts」テーブルの「User_ID」にインデックスが存在するかどうかを決定する。User_ID において Posts テーブルに。
スキーマに適切なインデックスがなければ、単純なクエリがフルテーブルスキャンを引き起こす可能性があります。これは物理的な制約です。ERDは実行計画を示すことはできません。開発者はクエリが遅い理由を理解するためにスキーマを確認しなければなりません。インデックス、パーティショニング戦略、データ型を分析する必要があります。
さらに、スキーマはロックメカニズムを管理します。複数のユーザーが同じレコードを更新する場合、スキーマの分離レベルとロック戦略がお互いにブロッキングするかどうかを決定します。ERDは並行処理について何も語りません。これは高負荷システムにおいて重要な違いです。
ベストプラクティスによるギャップの埋め方 🏆
両モデルが目的を効果的に果たすために、以下の基準を採用することを検討してください:
- 標準的な命名規則を使用する: スキーマ内のテーブル名がERDのエンティティ名と一致していることを確認する。一貫性があることで認知負荷が軽減される。
- 制約を明示的に文書化する: ERDでは、関係に基数を注釈する。スキーマでは、列にその制約を注釈する。ルールを両方の場所で可視化する。
- 定期的に見直す: 生産環境のスキーマに対して四半期ごとにERDをレビューするスケジュールを組む。ずれや異常を確認する。
- 関心を分離する: ERDをビジネスアーティファクト、スキーマを技術的アーティファクトとして扱う。ビジネスロジックを物理的なスキーマ定義に混入してはならない。
- 移行を計画する: ERDが変更された場合、スキーマはマイグレーションスクリプトを経由して変更されなければならない。バージョン管理されたスクリプトなしに、本番環境でスキーマを直接変更してはならない。
データモデリングのヒューマン要素 👥
結局のところ、これらのモデルは機械のためではなく、人のためです。ERDはコミュニケーションのためです。製品マネージャーがSQLを知らなくても、データ構造を理解できるようにします。スキーマは機械のためです。アプリケーションがデータを効率的に取得できるようにします。
開発者がこの人間と機械の違いを理解すると、より良いシステムを設計できるようになります。ステークホルダー向けにERDを簡略化するタイミング、データベースエンジン向けにスキーマを詳細化するタイミングを把握できるのです。この二重性こそがデータベースアーキテクチャの本質です。
論理図と物理的実装の境界を尊重することで、チームはデータ破損やパフォーマンスのボトルネックといった一般的な落とし穴を回避できます。ERDはビジョンを提供し、スキーマは現実を提供します。両方が成功したシステムには不可欠です。
データアーキテクチャについての最終的な考察 🧠
エンティティ関係図(ERD)とデータベーススキーマの違いは、ソフトウェア工学の基盤となる柱です。これは思考から行動、アイデアから実行への移行を表しています。ERDはビジネスを動かす関係性と論理を捉え、スキーマはアプリケーションを動かす制約と構造を捉えます。
これらの二つのモデルの関係を習得することは、定義を暗記することではありません。データのライフサイクルを理解することです。図の変更がコードの変更を要すること、そしてコードの変更が図に反映されなければならないことを知ることです。このサイクルにより、システムが整合性を持ち、信頼性があり、スケーラブルな状態を保つことができます。
開発の道を進む中で、これらの二つのモデルを明確に区別してください。ERDは計画とコミュニケーションに、スキーマは構築と強制に使用してください。両者が一致したとき、時間と変化に耐えるシステムを構築できます。
思い出してください。目的はデータを保存することだけではなく、意味のある形で保存することです。その意味はERDの論理的な明確さと、スキーマの構造的な厳密さから生まれます。これらは一緒に、あなたのデータアーキテクチャの基盤を形成します。