











マイクロサービスアーキテクチャにおけるデータモデルの設計は、モノリシックなアプリケーションと比べて根本的な考え方の転換を必要とする。従来のシステムでは、1つのエンティティ関係図(ERD)がデータベース全体をカバーすることが多い。分散環境では、その単一の視点が複数の独立したスキーマに分断される。課題は、サービス同士を結合せずに一貫性を保つことにある。このガイドでは、スケーラビリティとレジリエンスを確保しつつ、分散データ管理の一般的な落とし穴を避けるための、効果的なデータモデル構造の方法を検討する。
サービスがデータを直接共有すると、互いの依存関係を引き継ぐことになる。この強い結合は、ある領域の変更が別の領域を破壊する脆弱なシステムを生み出す。目標は、チームが独立してデプロイできる境界を設けることである。これを達成するには、関係性、整合性モデル、統合パターンを慎重に計画する必要がある。
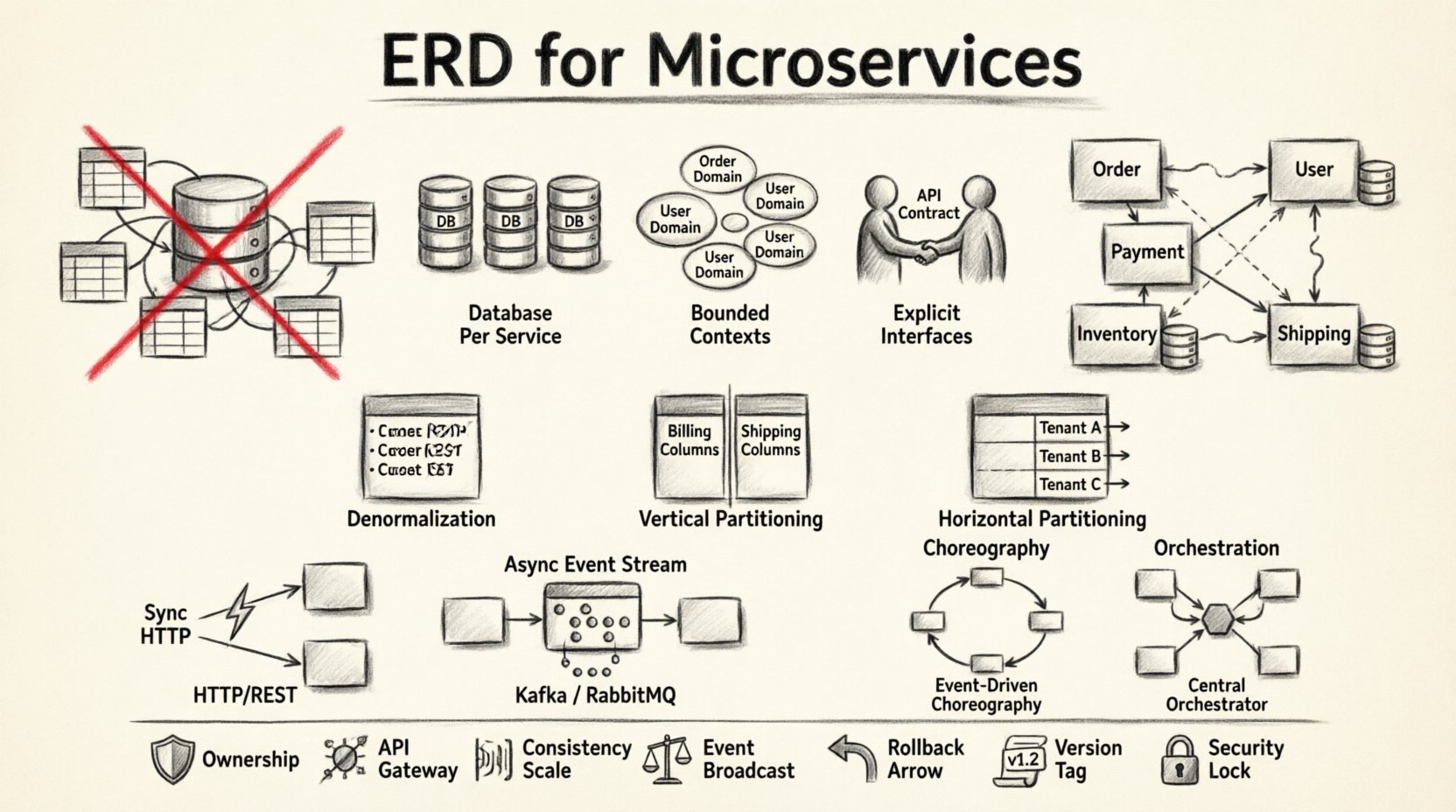
🧱 なぜ従来のERDは分散システムで機能しなくなるのか
標準的なERDは中央集権的な権限を前提としている。テーブル、カラム、外部キーを単一のトランザクション境界内にマッピングする。マイクロサービスはこの中央集権を拒否する。モノリシックなERDの考え方を分散システムに適用すると、分散型モノリスを生み出すリスクがある。これは、サービスが定義されたAPIではなく共有データベーステーブルに依存する場合に発生する。
これらの原則を無視すると、以下の問題が通常発生する:
- デプロイの結合:共有テーブルの変更には、複数のサービスで同時にデプロイが必要になる。
- トランザクション境界:ACIDトランザクションが複数のサービスにまたがり、遅延と障害ポイントが増加する。
- スキーマロック:1つのサービス内のデータベースロックが、別のサービスのリクエストを停止させることがある。
- 可視性の問題:グローバルなデータ状態を所有する単一のチームが存在しないため、データのスイロが生じる。
単一の図ではなく、サービス固有のスキーマの集合が必要となる。これらは明確に定義されたインターフェースを通じて通信する。このアプローチは、即時整合性よりも自律性を優先する。
🧬 分散データモデリングの核心原則
秩序を維持するためには、特定のアーキテクチャ原則に従う必要がある。これらのガイドラインは、チームがデータ所有権やアクセスパターンに関する意思決定を行うのを助ける。
1. サービスごとのデータベース
各マイクロサービスは自らのデータストアを所有すべきである。これにより、サービスの内部スキーマが他のサービスに見えないことが保証される。Service AがService Bのデータを必要とする場合、データベースを直接クエリするのではなく、APIを介して要求しなければならない。この隔離により、各ドメインの整合性が保護される。
- サービスは自らのスキーマ進化を管理する。
- チームは、自らの特定のニーズに最適なデータベース技術を選択できる(ポリグロット永続性)。
- 1つのデータベースでの障害が、全体のアプリケーションをクラッシュさせることはない。
2. 界限付きコンテキスト
データはビジネス機能と一致しなければならない。ドメイン駆動設計では、境界付きコンテキストはモデルの意味的境界を定義する。2つのサービスが「顧客」という用語を使用しても、そのコンテキスト内のデータは異なる。一方は連絡先情報を、他方は財務履歴を格納している。これらを1つのERDに統合すると、混乱と技術的負債が生じる。
3. 明確なインターフェース
サービス同士が互いのデータを直接見ることができないため、APIがデータ契約となる。APIの応答スキーマが、コンシューマーにとってのデータの現実を定義する。これにより、内部ストレージの実装と外部の利用が分離される。
📐 自立性を実現するためのスキーマ設計パターン
マイクロサービスのスキーマ設計には、従来外部キーで処理される関係を扱うための特定のパターンが必要となる。サービス間で関係を強制するためには、データベースレベルの制約に頼ることはできない。
非正規化
モノリスでは正規化が冗長性を減らす。マイクロサービスでは、非正規化がしばしば好まれる。重複データを格納することで、リモート呼び出しの必要性が減る。例えば、注文サービスは注文レコード内に顧客名と住所を格納する。これにより、注文を表示するたびにユーザーサービスに対して同期的に照会する必要がなくなる。
- 利点: 読み取り性能が向上し、ネットワークのホップ数が減る。
- リスク: ソースデータが変更された場合、データの整合性が保てない。更新はイベント経由で処理しなければならない。
垂直パーティショニング
大きなテーブルを小さな、焦点を絞ったセットに分割する。テーブルに請求情報と配送先住所が含まれている場合、これらを分離する。請求データはペイメントサービスに属する可能性があり、配送先住所は物流サービスに属する。これにより変更の影響範囲が小さくなり、アクセス制限によってセキュリティが向上する。
水平パーティショニング
テナントIDまたは地理的地域に基づいてデータを分割する。特定のサービスを他のサービスに影響を与えずにスケーリングするのに役立つ。高トラフィック地域向けにサービスをレプリケートできる一方で、他のサービスは軽量に保てる。
| パターン | 最適な使用ケース | 重要な考慮事項 |
|---|---|---|
| 非正規化 | 読み取り中心のワークロード | 同期ロジックが必要 |
| 垂直パーティショニング | 異なるドメイン | 明確なAPI境界 |
| 水平パーティショニング | 高スケーラビリティ/マルチテナント | ルーティングロジックの複雑さ |
🔄 関係性と整合性の扱い
マイクロサービスのデータモデリングで最も難しいのは、分散トランザクションなしで整合性を維持することである。強整合性と最終整合性のどちらを選ぶかが必要となる。
同期通信
サービス同士がHTTPまたはgRPC経由で直接呼び合える。これにより即時処理に対して強整合性が得られる。しかし、遅延が発生し、依存関係の連鎖が生じる。Service AがService Bを呼び、Service Bがダウンしている場合、Service Aも失敗する。
非同期通信
サービスはメッセージキューまたはイベントストリームを介して通信する。これにより、処理のタイミングが分離される。Service Aがイベントを発行し、Service Bが後にそれを消費する。これにより最終整合性がサポートされる。
- 長所: リジリエンス、スケーラビリティ、および緩い結合。
- 短所: データが一時的に整合性を失う。デバッグには複数のログを横断して追跡する必要がある。
🗓️ データ整合性のためのサガパターン
サガとは、ローカルトランザクションの連鎖である。各トランザクションはローカルデータベースを更新し、次のステップをトリガーするイベントを発行する。ステップが失敗した場合、サガは補償トランザクションを実行して以前の変更を元に戻す。
振付型 vs. 指揮型
サガは2つの方法で実装できる:
- 振付型: サービスはイベントを待機し、次に何をすべきかを決定する。中央のコントローラーは存在しない。柔軟性は高いが、可視化が難しい。
- 指揮型: 中央の調整者がサービスに何をすべきかを指示する。ワークフローの可視性と制御が向上するが、単一障害点が生じる。
サガのERDをモデル化する際には、状態変化を考慮しなければならない。サガに関与するすべてのサービスは、ロールバックを処理するためにその状態を保存する必要がある。つまり、スキーマは最終データだけでなく、トランザクションの状態もサポートしなければならない。
📝 スキーマの進化管理
スキーマの進化は避けられない。フィールドは変化し、型が変更され、制約が緩和される。分散システムでは、他のサービスが依存している間はデータベーススキーマを変更できない。バージョン管理を計画しなければならない。
後方互換性
常に後方互換性を維持する。新しいフィールドを追加する際は、古いフィールドをすぐに削除しないでください。コンシューマーが段階的に移行できるようにする。フィールド名を変更しなければならない場合は、移行期間中に古い名前を新しい名前にエイリアスする。
バージョン管理戦略
- URIバージョン管理: APIパスにバージョン番号を含める。
- ヘッダーによるバージョン管理: カスタムヘッダーを使用して、期待されるスキーマバージョンを指定する。
- コンテンツネゴシエーション: 標準のHTTPヘッダーを使用して、特定のメディアタイプを要求する。
ドキュメントはコードと同期させる必要がある。自動テストはAPI契約がスキーマと一致していることを検証すべきである。これにより、破壊的変更が本番環境に到達するのを防ぐ。
🛡️ 避けるべき一般的な落とし穴
しっかりとした計画があっても、チームはしばしば特定の問題に躓く。これらの落とし穴への認識は、堅牢なシステム設計に役立つ。
1. 共有データベースの罠
サービス間でテーブルを共有してはならない。これは隠れた結合を生む。支払いサービスが注文サービスのテーブルを読み取ると、内部構造についてあまりにも多くの情報を得ることになる。これにより、強い結合とデプロイの衝突が生じる。
2. 過剰な正規化
サービス間でデータを正規化しようとすると、過剰な結合とネットワーク呼び出しが発生する。ある程度の冗長性を受け入れる。遅く、結合が強いシステムよりも、重複データを持つほうが良い。
3. デュプリケート処理の無視
ネットワーク呼び出しが失敗する。メッセージが重複する。スキーマとAPIロジックは、エラーを引き起こさずに重複リクエストを処理できるようにしなければならない。リトライしても重複レコードが作成されないよう、エンドポイントをidempotent(冪等)に設計する。
4. 監視性の欠如
データが分散されている場合、トランザクションを追跡するために単一のデータベースをクエリすることはできません。分散トレーシングと集中型ログ記録が必要です。スキーマには、サービス境界を越えてリクエストを追跡できる相関IDを含めるべきです。
📋 治理チェックリスト
新しいサービスをデプロイする前に、以下のチェックリストを確認して、データモデルが適切であることを確認してください。
- 所有権:このデータに対して責任を持つ単一のサービスは存在しますか?
- インターフェース:データはAPI経由でのみ公開されていますか?
- 一貫性:一貫性モデルは文書化されていますか(強一貫性対最終一貫性)?
- イベント:状態の変更は、他のサービス向けにイベントとして公開されていますか?
- 補償:失敗したトランザクションに対するロールバックメカニズムはありますか?
- バージョン管理:将来の変更に対応するためにスキーマはバージョン管理されていますか?
- セキュリティ:機密データは静的および送信中において暗号化されていますか?
🔍 アーキテクチャの可視化
全体のシステムに対して単一のERDを描くことはできませんが、ハイレベルなマップを作成することはできます。このマップは特定のカラムではなく、サービスとそのデータ境界を示します。
- 各サービスに対してボックスを描いてください。
- ボックス内にデータドメインをラベル付けしてください(例:「ユーザープロフィールデータ」)。
- API呼び出しのための矢印を描き、データの流れを示してください。
- イベントストリームをリクエスト/レスポンスのフローとは別に示してください。
この視覚的補助は、ステークホルダーが技術的なスキーマの詳細に巻き込まれることなく、情報の流れを理解するのを助けます。アーキテクトやビジネスアナリストのコミュニケーションツールとして機能します。
🚀 結論
マイクロサービス向けのERDを設計することは、テーブル間の線を引くことではありません。ビジネス機能間の境界を定義することです。サービスごとのデータベースを採用し、最終一貫性を受け入れ、APIを厳密に管理することで、スケーラブルなシステムを構築できます。分散データの混沌は、規律と明確な契約によって管理可能です。自律性に注力し、結合を最小限に抑え、すべてのサービスがデータを完全に所有していることを確実にしてください。
データモデリングは反復的なプロセスであることを思い出してください。サービスが成長するにつれて、スキーマも進化する必要があります。これらの原則に基づいて定期的にアーキテクチャを見直し、健全で耐障害性の高いシステムを維持してください。