











堅牢なデータ構造を構築することは、信頼性の高いソフトウェアアプリケーションの基盤です。情報を保存するシステムを構築し始めると、設計図が必要になります。その設計図がエンティティ関係図(ERD)と呼ばれるものです。この視覚的な表現により、開発者やステークホルダーは、1行のコードも書かれる前からデータがどのようにつながっているかを理解できます。この計画段階がなければ、データベースはしばしばごちゃごちゃになり、遅くなり、保守が難しくなります。 🏗️
このガイドでは、ERD設計の基本原則をわかりやすく解説します。必須の構成要素、データ関係を規定するルール、スケーラブルなスキーマを構築するために必要な論理的なステップについて探求します。学生であろうと、初心者の開発者であろうと、プロダクトマネージャーであろうと、これらの概念を理解することで、データアーキテクチャが長期間にわたり安定した状態を保つことができます。
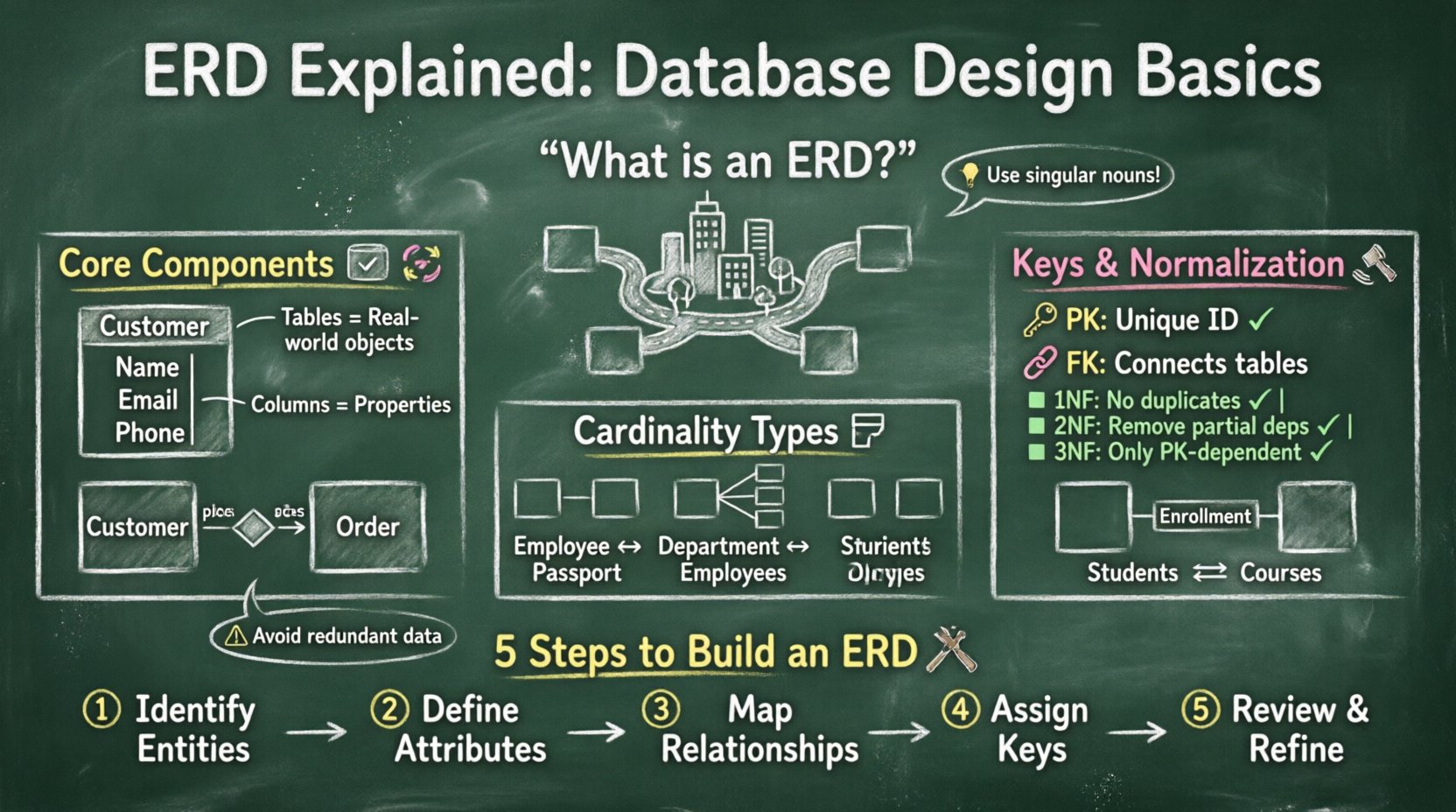
そもそもERDとは何か? 🤔
エンティティ関係図(ERD)は、データベースの構造を説明するために用いられる高レベルなモデルです。実世界の物体や概念を表すエンティティと、それらの間にある関係をマッピングします。まるでデータの地図だと思ってください。都市地図が地域をつなぐ道路を示すように、ERDはテーブルが特定のデータポイントをどのようにつなぐかを示します。
この図の主な目的は、データベースの論理構造を伝えることです。技術チームとビジネスアナリストの間で共通の言語として機能します。データフローを視覚化することで、重複データや欠落したリンクといった潜在的な問題を早期に発見できます。この予防的なアプローチにより、開発フェーズで大幅な時間を節約できます。
ERDを使用する主な利点には以下が含まれます:
- 明確さ:複雑なデータ構造を視覚化することで、理解が容易になります。
- 一貫性:すべてのチームメンバーがデータの定義について合意することを保証します。
- 効率性:不要な結合を減らすことで、クエリのパフォーマンスを最適化するのに役立ちます。
- ドキュメント化:将来の保守作業のための参考ガイドとして機能します。
データベーススキーマの核心となる構成要素 🔑
図を効果的に構築するには、基本構成要素を理解する必要があります。すべての図は、エンティティ、属性、関係性という3つの主要な要素に依存しています。これらをマスターすることで、あらゆるデータベースプロジェクトに必要な枠組みが得られます。
1. エンティティ:テーブル 📦
エンティティとは、ビジネス領域内の特定の物体、人物、または概念を表すものです。リレーショナルデータベースでは、エンティティはテーブルに対応します。各テーブルは、そのエンティティに関する固有の情報を格納します。たとえば、図書館システムでは「Book(本)」と「Member(会員)」は異なるエンティティです。
エンティティは図中で通常、長方形で表されます。個々のインスタンスを示すために、単数名詞を使用して名前を付けるべきです。エンティティを定義するということは、実質的にデータのカテゴリを定義しているのです。
- 強固なエンティティ: これらは独立して存在します。「Customer(顧客)」テーブルは他のテーブルがなくても存在します。
- 弱いエンティティ: これらは他のエンティティに依存して存在します。「Order Item(注文項目)」は、「Order(注文)」がなければ意味を持たないため、弱いエンティティである可能性があります。
2. 属性:カラム 📝
属性とは、エンティティを記述するための性質や特徴です。データベースのテーブルでは、これらがカラムになります。たとえば、「Customer(顧客)」エンティティには、Name(名前)、Email(メールアドレス)、Phone Number(電話番号)といった属性があるかもしれません。
属性はいくつかの種類に分類できます:
- 単純な属性:さらに分割できないもので、年齢や生年月日などが該当します。
- 複合属性: サブパーツに分割できる場合があり、たとえば住所(通り、都市、郵便番号)などがある。
- 複数値属性:複数の値を保持できる。たとえばスキルや電話番号など。
- 導出属性:他の属性から計算される。たとえば年齢(誕生日から導出)。
3. 関係:接続 🔄
関係は、エンティティが互いにどのように相互作用するかを定義する。これは設計において最も重要な部分であり、データがどのようにリンクされるかを決定する。図では、関係はダイヤモンドまたはエンティティをつなぐ線として示される。
たとえば、「顧客」が「注文」を行う。これは関係である。データベースは、注文が顧客に割り当てられる前に顧客が存在することを保証するルールを強制しなければならない。これにより、孤立したデータを防ぐことができる。
基数とモダリティの理解 📏
基数は、関連する2つのテーブルのレコード間の数的関係を定義する。この問いに答える:「エンティティAの何個のインスタンスがエンティティBの何個のインスタンスに関連しているか?」。これを理解することで、データの異常を防ぐことができる。
基数には主に3つのタイプがある:
- 1対1(1:1):テーブルAの1レコードが、テーブルBの正確に1レコードに関連する。
- 1対多(1:N):テーブルAの1レコードが、テーブルBの複数のレコードに関連する。
- 多対多(M:N):テーブルAの複数のレコードが、テーブルBの複数のレコードに関連する。
以下は、実際の例を用いてこれらの関係を説明した表である。
| 基数の種類 | 例のシナリオ | 実装方法 |
|---|---|---|
| 1対1(1:1) | 従業員とパスポート | 1つのテーブルに外部キーを設置 |
| 1対多(1:N) | 部署と従業員 | 「多」側のテーブルに外部キーを設置 |
| 多対多(M:N) | 学生と授業 | 中間結合テーブル |
モダリティは、さらに詳細な層を加えます。関係が必須かオプションかを指定します。たとえば、注文は顧客なしで存在できますか?通常はできません。これは必須の関係です。顧客が注文を持たないことは可能ですか?はい、これはオプションです。
キー:データ整合性の接着剤 🔗
キーは、レコードを一意に識別するか、テーブルをリンクするために使用される特定の属性です。これらは関係を強制し、データ整合性を維持する仕組みです。
プライマリキー
プライマリキー(PK)は、テーブル内の各レコードを一意に識別します。同じプライマリキー値を持つ2つの行は存在できません。nullは許可されません。一般的な選択肢には、自動増分の整数やUUIDがあります。これにより、すべてのデータが一意のアドレスを持つことが保証されます。
外部キー
外部キー(FK)は、あるテーブルのフィールドで、別のテーブルのプライマリキーを参照するものです。これにより、2つのテーブルのリンクが確立されます。外部キーを定義すると、データベース管理システムは参照整合性を強制します。つまり、親テーブルに存在しない外部キー値を持つレコードを追加することはできません。
複合キー
場合によっては、1つのカラムだけではレコードを一意に識別するには不十分です。複合キーは、2つ以上のカラムを組み合わせて一意の識別子を作成します。これは、多対多の関係における結合テーブルでよく発生します。
正規化:データの整理 🧹
正規化は、データの重複を減らし、整合性を向上させるためにデータを整理するプロセスです。大きなテーブルを、論理的に関連する小さなテーブルに分割します。これらのルールに従うことで、更新、挿入、削除の際に異常が発生するのを防ぐことができます。
いくつかの正規形がありますが、最もよく使われるものは最初の3つです:
- 第一正規形(1NF):同じテーブル内の重複するカラムを削除する。関連データに対して別々のテーブルを作成し、各行をプライマリキーで識別する。
- 第二正規形(2NF):1NFのすべての要件を満たす。テーブルの複数の行に適用されるデータのサブセットを削除し、別々のテーブルに配置する。
- 第三正規形(3NF):2NFのすべての要件を満たす。プライマリキーに依存しないカラムを削除する。
4NFや5NFなどのより高い正規形も存在しますが、多くのアプリケーションにおいて3NFに到達することが通常十分です。過剰な正規化は、多くの結合を必要とする複雑なクエリを引き起こし、パフォーマンスに影響を与える可能性があります。バランスが重要です。
ERDを作成する手順 🛠️
図の設計は体系的なプロセスです。図形を描き始めるのではなく、要件を理解することから始めます。信頼できるモデルを作成するには、以下の手順に従ってください。
ステップ1:エンティティを特定する
ビジネス要件を確認してください。記述の中から、物や人を表す名詞を探してください。要件に「すべてのユーザーのログインを追跡する」とある場合、エンティティは「ユーザー」または「ログイン」です。すべての可能性のあるエンティティをリストアップしてください。
ステップ2:属性を定義する
各エンティティについて、どの情報を保存する必要があるかを決定してください。エンティティを完全に記述するために必要な詳細は何ですか?「ユーザー」エンティティの場合、ユーザー名、パスワード、メールアドレスが必要になるかもしれません。
ステップ3:関係を決定する
エンティティの相互作用に基づいて、それらを接続してください。エンティティどうしがどのように関係しているかを尋ねてください。1人のユーザーが複数のログインを持つことはありますか?製品は1つのカテゴリに属しますか?線を引き、基数を定義してください。
ステップ4:キーを割り当てる
各エンティティのプライマリキーを特定してください。関係が存在する場所に外部キーを追加します。このステップで、概念図が実装可能な論理スキーマに変換されます。
ステップ5:見直しと改善
ステークホルダーと一緒にモデルを確認してください。欠落しているデータポイントや誤った関係がないかチェックしてください。設計が意図したクエリをサポートしていることを確認してください。ビジネスニーズをすべて満たすまで図を改善してください。
避けるべき一般的な落とし穴 ⚠️
経験豊富なデザイナーでさえミスを犯します。一般的な誤りに気づくことで、よりクリーンなシステムを構築できます。デザイン段階で注意すべき問題を以下に示します。
- 関係の欠落: テーブルをリンクすることを忘れると、情報が結合できないデータ・サイロが生じる可能性があります。
- 重複データ: 同じ情報を複数のテーブルに保存すると、ストレージ容量が増加し、一貫性の欠如のリスクが高まります。
- 誤った基数: 本来は多対多である関係を、一対多として設定すると、検証エラーが発生します。
- 名前衝突: 「Data1」や「TableA」のような曖昧な名前を使用すると、後でスキーマを理解するのが難しくなります。
- NULL許容性の無視: 列がNULL値を許容するかどうかを明示しないと、データ入力時に予期しないエラーが発生する可能性があります。
視覚的記法 🎨
異なるチームはERDを描く際に異なるスタイルを使用します。最も一般的な2つの基準はクロウズフット記法とチェン記法です。
- クロウズフット記法: 特定の終端を持つ線を使用して基数を示します。単線は「1」、分岐線は「多」を意味します。現代のツールで広く使用されています。
- チェン記法: 関係にはダイヤモンド、属性には楕円を使用します。より詳細ですが、複雑なシステムでは見づらくなりがちです。
記法にかかわらず、明確さが最も重要です。図はデータベース管理者だけでなく、プロジェクトに関与する誰にとっても読みやすいものでなければなりません。
コンセプトから物理的実装へ 🚀
論理設計が完了したら、物理データベースに変換する必要があります。これにはデータ型の選定やパフォーマンス最適化が含まれます。
この段階では、属性に適切なデータ型を選択します。たとえば、日付フィールドは文字列ではなくDate型を使用すべきです。価格フィールドは分数を扱うためにIntegerではなくDecimal型を使用すべきです。これらの選択はストレージサイズとクエリ速度に影響します。
インデックス作成も重要です。頻繁に検索される列、特に外部キーにインデックスを作成すると、検索速度が向上します。しかし、インデックスが多すぎると書き込み操作が遅くなる可能性があります。ワークロードに適したバランスを見つけてください。
計画の重要性はスピードより高い理由 ⏳
設計段階を飛ばしてすぐにコーディングを始めたくなるのはわかりますが、後からデータベース構造を変更するのはコストがかかります。データの削除や列の変更は、既存のアプリケーションを破壊する可能性があります。
十分に検討されたERDは契約の役割を果たします。データのやり取りのルールを定義します。計画に従えば開発がスムーズになります。図を更新せずに計画から逸脱すると、技術的負債が急速に蓄積されます。
計画段階に時間を投資することで、リファクタリングの必要性が減ります。システムが将来の成長に対応できることを保証します。スケーラブルな設計は、完全な再構築なしに新しい機能を対応できます。
データアーキテクチャについての最終的な考察 🏁
データベースを設計することは、論理と予見性の融合です。ビジネス領域を深く理解することが求められます。エンティティ関係図は、抽象的な要件と具体的なコードの間をつなぐツールです。
エンティティ、属性、関係性に注目することで、正確で効率的なデータ管理をサポートする構造を作り出します。正規化ルールを遵守することで整合性が保たれ、明確なキーが関係を維持します。
これは反復的なプロセスであることを思い出してください。要件が変化するにつれて、図もそれに応じて進化すべきです。初期設計と同様に、ドキュメントを最新の状態に保つことも非常に重要です。しっかりとした基盤があれば、アプリケーションは信頼性高く動作し、効果的にスケーリングできます。
小さなスタートから始め、大きな視点を持ち、データモデルにおいて常に明確さを最優先してください。このアプローチにより、時代の試練に耐えうる持続可能なシステムが生まれます。