











数百万のユーザーを処理できるシステムを構築するには、単に高性能なハードウェアや効率的なコード以上のものが必要です。その基盤は、データ構造そのものにあります。エンティティ関係図(ERD)は単なる文書化の成果物ではなく、アプリケーションの持続可能性を示す設計図です。成長を想定して設計する際、アーキテクトたちは将来の負荷、関係の複雑さ、データ整合性の必要性を予測します。適切に構築されたスキーマは、最初のコミットが行われる前から技術的負債が蓄積されるのを防ぎます。
このガイドでは、スケーラブルな環境向けにエンティティ関係図の設計をどう進めるかを検討します。理論的基盤、実践的な妥協点、および一貫性を損なわずに高スループットシステムを支える構造パターンについて説明します。
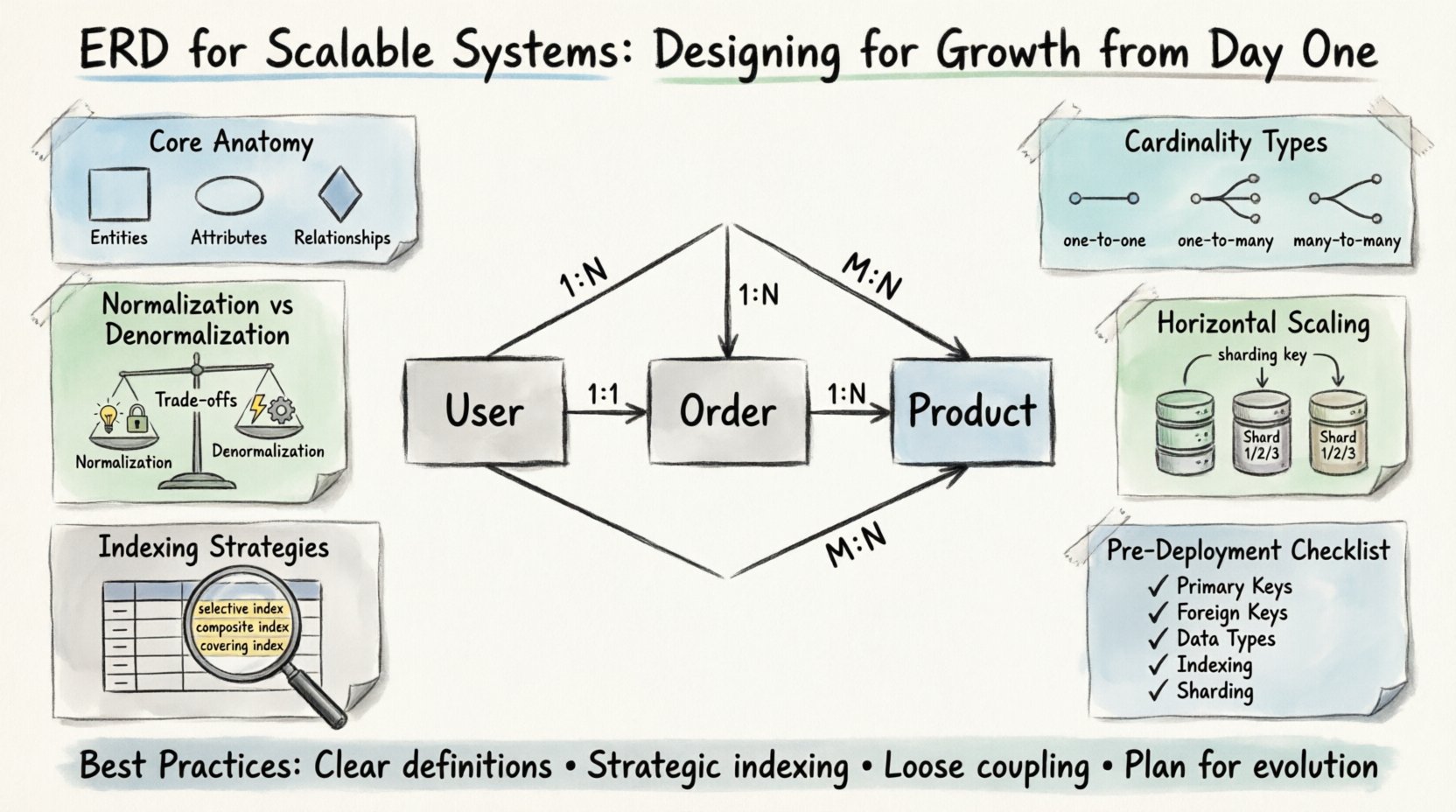
🧩 スケーラブルなERDの核心的な構造
スケーラビリティを検討する前に、基本的な構成要素を理解する必要があります。すべての図はエンティティ、属性、関係から構成されます。スケーラブルな文脈では、これらの要素を正確に定義することで、後々のボトルネックを回避できます。
- エンティティ: これらはビジネスドメインの核心となるオブジェクトを表します。例として、ユーザー、注文、製品があります。急成長するシステムでは、エンティティは独立してスケーリングできるほど細かく、かつ論理的な境界を保つために十分に一貫性を持つ必要があります。
- 属性: これらはエンティティを説明する性質です。データ型はここが非常に重要です。適切な型を選択することで、ストレージ効率とクエリパフォーマンスに影響します。たとえば、IDに専用の整数型を使用することは、インデックス作成の観点から文字列よりも優れています。
- 関係: これらはエンティティどうしの相互作用を定義します。基数は早期に定義すべき最も重要な要素です。1対多の関係を多対多と誤解すると、不要な結合が発生し、深刻なパフォーマンス低下を招く可能性があります。
📐 基数と制約の理解
基数は、あるエンティティのインスタンスが、別のエンティティのインスタンスと関係を持つことができる数を規定します。スケーラブルなシステムでは、基数の選択がデータのパーティショニング方法を左右することがよくあります。
- 1対1(1:1):パフォーマンス最適化のためにほとんど使用されません。大きなエンティティを分割してロック競合を減らすことを意味することが多いです。データアクセスパターンが厳密に異なる場合にのみ使用してください。
- 1対多(1:N): 最も一般的な関係です。ユーザーは複数の注文を持ちます。この構造は外部キー側での効率的なインデックス化を可能にし、関連レコードの高速取得を実現します。
- 多対多(M:N): 結合テーブルが必要です。柔軟性はありますが、データ量が増えるにつれてパフォーマンスのボトルネックになることがあります。読み取り頻度が高い場合は、非正規化や物化ビューを検討してください。
制約を定義する際には、その適用に伴うオーバーヘッドを考慮してください。分散システムでは、シャード間で厳格な外部キー制約を適用すると遅延が発生する可能性があります。このような状況では、システムのスループットを維持しつつデータ整合性を保つために、アプリケーションレベルでの検証が必要になることがあります。
⚖️ 正規化とパフォーマンスのトレードオフ
正規化は冗長性を減らし、データ整合性を向上させます。しかし、高性能システムでは、厳格な正規化ルールから逸脱する必要があることがよくあります。各レイヤーを理解することで、情報に基づいた意思決定が可能になります。
- 第1正規形(1NF): 原子値。各セルが単一の値を含むことを保証します。関係データベースの整合性にとって不可欠です。
- 第2正規形(2NF): 部分的依存がない。すべての非キー属性は、主キー全体に依存しなければなりません。更新異常を減らすのに役立ちます。
- 第3正規形(3NF): 推移的依存がない。非キー属性は、他の非キー属性に依存してはならない。これはほとんどのトランザクションシステムの標準的な目標です。
3NFは一貫性にとって理想的ですが、しばしば複雑な結合を必要とします。読み込みが重いシステムでは、複数のテーブルを結合するとデータベースエンジンに負荷がかかります。非正規化は結合の必要性を減らすためにデータを複製するものです。書き込みの複雑さは増しますが、読み込み速度は著しく向上します。
📊 正規化と非正規化の比較
| 機能 | 正規化 (3NF) | 非正規化 |
|---|---|---|
| データ整合性 | 高い (単一の真実のソース) | 低い (同期ロジックが必要) |
| 書き込みパフォーマンス | 速い (書き込まれるデータが少ない) | 遅い (重複する書き込み) |
| 読み込みパフォーマンス | 遅い (結合が必要) | 速い (直接アクセス) |
| ストレージ使用量 | 効率的 | 高い (冗長性) |
| 使用ケース | トランザクション系システム (OLTP) | レポート作成および分析 (OLAP) |
🚀 水平スケーリングのための設計
データ量が増えるにつれて、単一のデータベースノードがボトルネックになります。水平スケーリングは、負荷を分散させるためにより多くのノードを追加することを意味します。ERDはこのアーキテクチャを初期段階からサポートしている必要があります。
- シャーディングキー:シャード間でデータを均等に分割できる列を特定してください。この列は、データにアクセスするすべてのクエリに含まれている必要があります。すべてのシャードをスキャンする必要があるクエリの場合、パフォーマンスが低下します。
- シャード間の外部キー:異なるシャードに存在するテーブルを結合することは計算コストが高くなります。設計段階でシャード間の関係を最小限に抑えるようにしてください。関係が必要な場合は、参照データをキャッシュすることを検討してください。
- グローバルID:自動インクリメントカウンターに依存しない一意の識別子を使用してください。これらは競合を引き起こす可能性があるためです。UUIDや分散型IDジェネレータが推奨されます。
シャーディングを想定したモデル設計の際には、データの分布を検討してください。1つのシャードが他のシャードよりも著しく多くのトラフィックを受け取る状況がホットスポットと呼ばれます。シャーディングキーが最も頻繁に使用されるクエリフィルタと一致していることを確認するために、アクセスパターンを分析してください。
📑 大規模データセット向けのインデックス戦略
インデックスはクエリパフォーマンスにとって不可欠ですが、コストも伴います。すべてのインデックスはストレージを消費し、書き込み操作を遅くします。インデックス戦略を戦略的に立てることが重要です。
- 選択的インデックス: データを大幅に絞り込む列にインデックスを作成する。低基数(例:性別)の列は、通常、プライマリインデックスの適切な候補ではない。
- 複合インデックス: クエリパターンに一致する順序で複数の列を組み合わせる。左端のプレフィックスルールが適用され、インデックスが効果的に使用されるためには、インデックスの最初の列がクエリと一致している必要がある。
- カバーインデックス: クエリで必要なすべての列をインデックス自体に含める。これにより、データベースはテーブルデータにアクセスせずにクエリを満たすことができ、これを「カバー」と呼ばれる操作という。
- 部分インデックス: テーブルの行のサブセットのみにインデックスを付ける。これはソフトデリートや特定のステータスフラグに有用であり、インデックス構造のサイズを削減する。
クエリ実行計画を定期的に確認する。統計情報が古ければ、紙面上では良いように見えるインデックスもクエリ最適化子によって無視されることがある。定期的なメンテナンスにより、データベースエンジンが最適な決定を下すことを保証する。
🔄 機械の進化とスキーマの移行
システムは静的ではない。要件は変化し、データモデルも進化しなければならない。ダウンタイムなしでバージョンAからバージョンBに移行することは、重要なスキルである。
- 追加変更: 列やテーブルを追加することは一般的に安全である。既存のクエリを破壊しない。これは新しい機能を導入する際の推奨される方法である。
- 名前の変更操作: 列の名前を変更することはリスクが高い。アプリケーションコードの更新が必要になる。古い名前と新しい名前を両方サポートする非推奨期間を計画する。
- 制約の追加: 既存のデータに制約(例:NOT NULL)を追加すると、データが存在する場合に失敗する可能性がある。まずデータを検証し、別ステップで制約を追加する。
- 後方互換性: 新しいスキーマバージョンが既存のクライアントを破壊しないようにする。スキーマが準備できたら、機能フラグを使って新しいロジックを切り替える。
🚫 避けるべき一般的な落とし穴
経験豊富なデザイナーでも問題に直面することがある。これらのパターンを早期に認識することで、大幅なエンジニアリング時間の節約が可能になる。
- 過度な結合: 関係のないエンティティ間で厳密な同期を強いる関係を作成すること。モジュールを緩く結合することで、独立したデプロイを可能にする。
- 過剰設計: あり得ないシナリオのために設計すること。トラフィックの90%を生み出す80%のユースケースに注力する。シンプルさは保守性を高める。
- ソフトデリートを無視すること: ハードデリートはデータを永続的に削除する。監査ログや回復のために、物理的な削除ではなく、ステータスフラグ(例:is_deleted)を使用する。
- N+1クエリ問題: データの取得方法を予測しないこと。過剰なデータベースのラウンドトリップを避けるために、データアクセス層でエイジングロードやバッチ取得を計画する。
✅ デプロイ前の設計チェックリスト
スキーマを最終決定する前に、この検証リストを確認して、スケーラビリティの準備ができていることを確認する。
- ☐ プライマリキー:すべてのテーブルに一意でインデックス付きのプライマリキーが設定されていますか?
- ☐ 外部キー:関係性は正しく定義されていますか?カーディナリティは正確ですか?
- ☐ データ型:IDや金額には数値型が使用されていますか?日付型は統一されていますか?
- ☐ NULL許容性:必須フィールドはすべて NOT NULL としてマークされていますか?
- ☐ インデックス化:高トラフィックのクエリ対象カラムはインデックス化されていますか?
- ☐ シャーディング:水平スケーリングを想定する場合、実行可能なシャーディングキーがありますか?
- ☐ 制約:ビジネスロジックのために制約が必要ですか?それともアプリケーション層で処理できますか?
- ☐ ドキュメント:ERDは最終実装を反映して更新されていますか?
🛡️ 分散環境におけるデータ整合性
分散環境では、ACID特性(原子性、整合性、分離性、耐久性)をノード間で保証することが難しくなります。ERDに与える影響を理解することは不可欠です。
- 最終的整合性:レプリカ間で一時的に整合性が保たれない可能性を受け入れてください。アプリケーションをこの状態をスムーズに処理できるように設計してください。
- 冪等性:操作が副作用なしに再試行できることを保証してください。ネットワーク障害時に書き込みは成功するが確認応答が失われる場合に、これが非常に重要です。
- 衝突解決: 同じレコードに対する同時更新の処理方法を定義する。タイムスタンプやベクタークロックを使用すると、最新のバージョンを特定するのに役立つ。
これらの考慮事項をエンティティ関係図に組み込むことで、今日機能するだけでなく、明日にも耐えうる堅牢なシステムを構築できます。本番環境でスキーマを変更するコストは、初期に正しく設計するコストと比べて指数関数的に高くなります。
🔍 最良の実践方法の要約
要するに、成功したスケーリングは、データモデリングに対する厳格なアプローチに依存します。明確な定義、適切な正規化、戦略的なインデックス化に注力してください。データ整合性を損なう短絡的な手法を避けましょう。システムの進化に伴い、図を定期的に見直してください。静的なERDは負債であり、進化し続けるモデルこそが資産です。
設計フェーズに時間を投資してください。保守コストの削減とシステム信頼性の向上という恩恵が得られます。ユーザーは図を見ることはありませんが、その図が支えるシステムのパフォーマンスは感じ取るでしょう。