











データベースを設計することは、コードを入力することよりも、関係性を理解することに重点がある。スクリプトの1行も書かれる前に、視覚的な基盤を築く必要がある。この基盤が、通称ERDと呼ばれるエンティティ関係図である。このステップを飛ばすことは、図面なしで高層ビルを建設するのと同じである。構造は一時的には立つかもしれないが、データが増えるにつれて、亀裂が明らかになる。 🧱
このガイドでは、データベースアーキテクチャの初期段階を解説する。堅牢なスキーマを作成するために必要な概念モデルと論理モデルに焦点を当てる。顧客情報の管理、在庫管理、複雑な取引データの扱いのいずれであっても、原則は同じである。特定のツールや独自のソフトウェアに依存せずに、エンティティ、属性、関係、および基数について探求する。目標は、スケーラブルで効率的かつ保守しやすいシステムを構築することである。 🚀
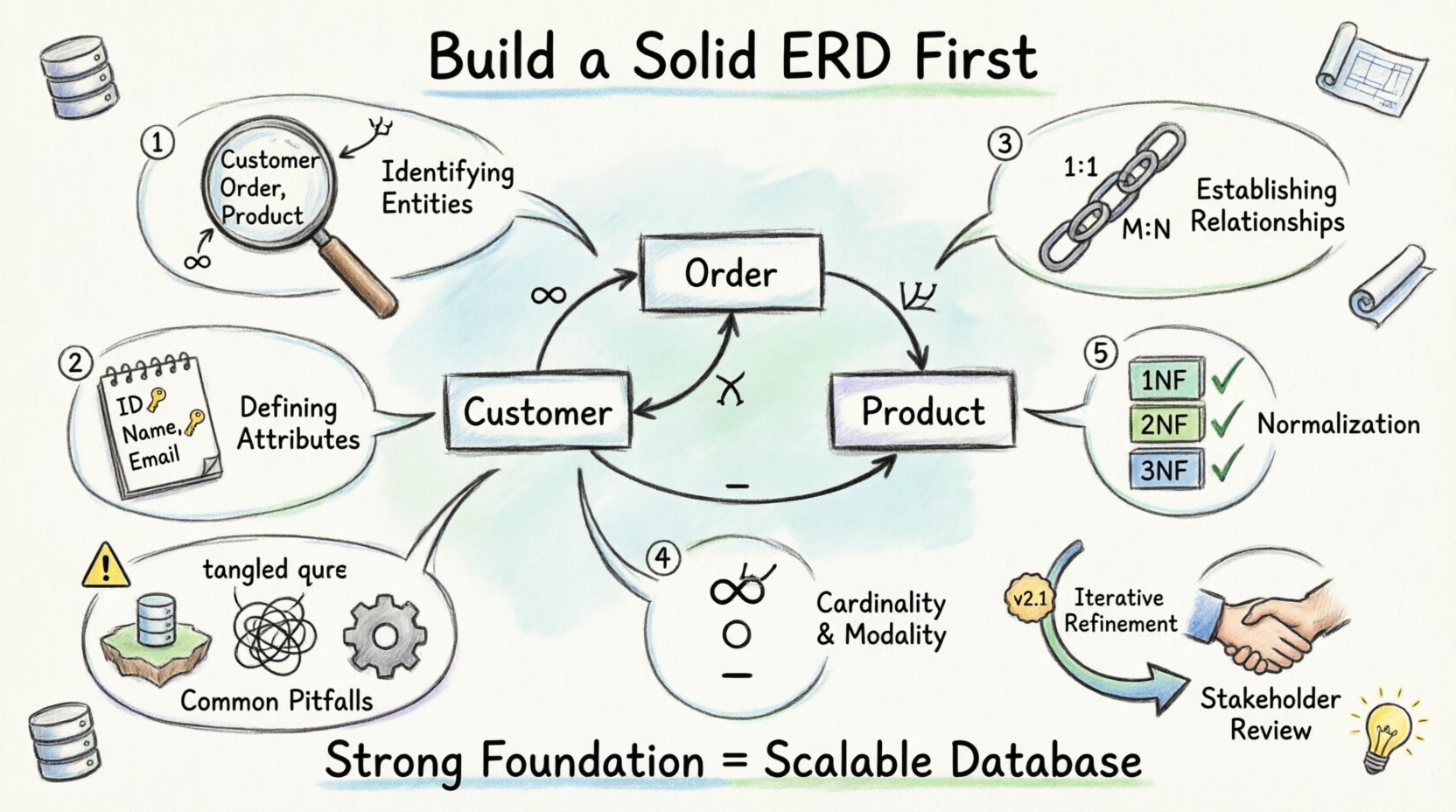
エンティティ関係図の理解 📐
ERDは、システム内のデータ構造を視覚的に表現したものです。保存が必要な「もの」(エンティティ)と、それらが互いにどのように関係するかを明示します。これはデータベースエンジンの地図と考えてください。物理的にディスク上にどのようにデータが保存されるかを定義するものではなく、アプリケーションのためにデータが論理的にどのように整理されるかを示すものです。
なぜここから始めるのか? 🤔
しっかりとした図を最初に作成することで、いくつかの一般的な問題を防ぐことができる:
- データの重複:同じ情報を複数の場所に保存すると、一貫性の欠如が生じる。
- 整合性エラー:関係が明確に定義されるため、孤立したレコードを防ぐことができる。
- スケーラビリティ:論理モデルは、ビジネスが拡大しても完全に再構築せずに適応できる。
- コミュニケーション:ステークホルダーは開発が始まる前に構造を確認でき、要件が満たされていることを保証できる。
ERDがなければ、開発者は関係性を推測せざるを得ない。その結果、後で複雑な結合が発生し、パフォーマンスのボトルネックが生じる。しっかり定義された図は、プロジェクトチーム全体の唯一の真実の情報源となる。 🤝
ステップ1:エンティティの特定 🏢
あらゆるデータベースの構成要素はエンティティである。エンティティとは、データが収集される対象となる明確な物体、概念、または人物を表す。図の文脈では、要件の中で特定する名詞がこれに当たる。
現実世界のエンティティ vs. 論理的エンティティ
ビジネスプロセスを分析する際には、物理的な物体と論理的な概念を区別しなければならない。たとえば、「製品」は論理的エンティティである。倉庫にある特定の「ウィジェット」は物理的なインスタンスである。データベースは論理的エンティティを保存し、ユニークな識別子を使ってインスタンスを追跡する。
候補となるエンティティの特定
エンティティを見つけるには、ビジネスルールと機能要件を確認する。次のようなものを探す:
- 名詞:要件文書をスキャンし、大文字で書かれた名詞を探す。
- コア機能:どのような操作が行われるのか?誰が関与しているのか?
- 規制上の要件:コンプライアンスのために保持しなければならないデータは何か?
代表的な例には以下がある:
- 顧客: 誰が購入または相互作用していますか?
- 注文: 取引記録。
- 製品: 売られているアイテム。
- 従業員: システムを管理するのは誰ですか?
- 場所: 送付物はどこに送られますか?
エンティティの命名規則
一貫性が読みやすさの鍵です。図全体で単数、複数、または一貫した命名規則を使用してください。業界標準でない限り、省略語は避けてください。たとえば、「Cust」ではなく「Customer」を使用してください。
| 側面 | 推奨 | 例 |
|---|---|---|
| ケース | PascalCase または snake_case | CustomerRecord または customer_record |
| 複数形 | テーブルでは単数を使用する | 使用する顧客、ではなく顧客たち |
| 明確さ | 一般的な名前を避ける | 使用する請求書、ではなく文書 |
ステップ2:属性の定義 📝
エンティティが特定されると、それらについて保存される情報の内容を定義する必要があります。これらの詳細は属性と呼ばれます。属性はエンティティの特徴を記述します。
属性の種類
属性は、その役割や挙動に基づいていくつかのカテゴリに分類されます:
- 記述的属性:名前、住所、電話番号などの基本的な事実。
- キー属性:一意の識別子。すべてのエンティティは、他のものと区別できるために少なくとも1つのキーが必要です。
- 複合属性:より小さな部分に分割できるデータ(例:住所は通り、市区、郵便番号に分けることができる)。
- 導出属性:他のデータから計算された値(例:誕生日から導かれる年齢)。
- 多値属性:複数の値を保持できるフィールド(例:1人の人の電話番号)。
プライマリキー:アンカー 🔑
プライマリキー(PK)は最も重要な属性です。テーブル内のすべてのレコードに対して一意でなければなりません。これにより、2つの行が同一になることを防ぎます。プライマリキーは通常、システムによって自動的に生成され、自動増分の整数やUUIDなどが使われます。
キーを選択する際の考慮事項:
- 安定性:値は時間の経過とともに変化してはいけません。名前を使うのはリスクが高いですが、IDを使うほうが安全です。
- 一意性:重複は許されません。
- NULL不可:キーがなければレコードは存在できません。
ステップ3:関係の確立 🔗
エンティティは孤立して存在することはめったにありません。顧客が注文を出す。従業員がプロジェクトに従事する。これらのつながりが関係です。関係を定義することが、ERDの真の力の所在です。
関係の種類
エンティティがどのように相互作用するかを説明するために、3つの標準的な基数が使われます:
- 1対1(1:1):エンティティAの1つのインスタンスが、エンティティBのちょうど1つのインスタンスと関係を持つ。
- 1対多(1:N):エンティティAの1つのインスタンスが、エンティティBの複数のインスタンスと関係を持つ。
- 多対多(M:N):エンティティAの多数のインスタンスが、エンティティBの多数のインスタンスに関連する。
多対多関係の処理
リレーショナルモデルでは、直接的な多対多関係は物理的にサポートされていない。代わりに関連エンティティ(ブリッジテーブルまたはジョインテーブルとも呼ばれる)を使用して解決しなければならない。この新しいエンティティにより、M:N関係が2つの1対多関係に分割される。
たとえば、生徒は複数の授業を受講でき、授業には複数の生徒が所属することができる。直接リンクするのではなく、登録エンティティを作成する。このテーブルには、生徒IDと授業IDが格納され、登録に関する特定のデータ(成績など)も含まれる。
ステップ4:基数とモダリティ 🔢
基数は関係の数を定義する。モダリティはオプション性(関係が必須か任意か)を定義する。これらの詳細はデータの整合性を保証する。
基数の表記法
視覚的な表記は開発者が制約を理解するのを助ける。一般的な記号には以下がある:
- 1つ:単一の線またはダッシュ(-)。
- 多数:カラスの足の記号(∞)または三本の突起。
- 任意:円(○)で、ゼロを許容することを示す。
- 必須:実線で、少なくとも1つが必要であることを示す。
参加制約
参加の理解はアプリケーションロジックにとって不可欠である。以下のシナリオを検討する:
- 完全参加:すべての顧客は注文を持つ必要がある。(必須)
- 部分参加:注文はは配送先住所を持つ可能性がある。(任意)
誤ったモダリティはデータベースエラーを引き起こす。システムが必須関係を要求しているのに、データベースがNULLを許容している場合、データが欠落したときにアプリケーションロジックが破綻する。
ステップ5:正規化の文脈 🔄
ERDは論理モデルではあるが、正規化の原則と整合性を持たなければならない。正規化は重複を減らし、データの整合性を向上させる。これは属性をテーブルに整理することで、依存関係を最小限に抑えることを意味する。
第一正規形(1NF)
原子的な値を確保する。フィールドには項目のリストを含めてはならない。たとえば、「趣味」フィールドに「読書、ハイキング、コーディング」といった内容を含えるのではなく、別途「趣味」テーブルを作成する。
第二正規形(2NF)
部分的依存関係を排除する。すべての非キー属性は、主キーの一部ではなく、全体に依存しなければならない。これは通常、テーブルに複合キーがある場合に適用される。
第三正規形(3NF)
推移的依存関係を排除する。非キー属性は他の非キー属性に依存してはならない。たとえば、「従業員」テーブルにおいて「オフィスID」に基づいて「都市」を保存している場合、「オフィスID」と「都市」を別々に「オフィス」テーブルに分離するべきである。
ERDはこれらの依存関係を可視化するのに役立つ。繰り返しを示唆するような属性のグループ化が見られる場合は、SQLを記述する前にERDの調整が必要である。 ⚙️
避けるべき一般的な落とし穴 ⚠️
経験豊富なデザイナーですら初期段階でミスを犯すことがある。これらの落とし穴を早期に認識することで、開発段階での時間を大幅に節約できる。
| 落とし穴 | 結果 | 解決策 |
|---|---|---|
| 関係の欠落 | データが孤立した島になる | すべての接続に関する要件を再確認する |
| 過剰な正規化 | クエリが複雑になりすぎる | 整合性と読み取りパフォーマンスのバランスを取る |
| データ型を無視する | ストレージの非効率性とエラー | 型(日付、数値、テキスト)を早期に定義する |
| ハードコードされた値 | システムが硬直化する | 静的データには参照テーブルを使用する |
| 弱いキー | レコードの追跡が困難になる | キーが一意かつ安定していることを確認する |
ドキュメント作成とレビュー 📄
ERDは一度だけ描くものではありません。プロジェクトと共に進化する動的な文書です。初期設計が完了したら、必ず見直しを行う必要があります。
ステークホルダーの検証
図をビジネスアナリストや専門家に提示してください。開発者が見落としがちな、欠落しているビジネスルールを発見できます。たとえば、「30日を過ぎた refund は処理できない」というルールは技術的な図には現れにくいものの、論理的に非常に重要です。
技術的実現可能性
データベース管理者と設計を検討してください。想定されるデータ量に対して、提案されたスキーマが適切に動作するかを評価できます。定義された関係に基づいて、インデックス戦略やパーティショニング計画の提案も可能です。
反復プロセス 🔄
データベース設計はほとんど線形ではありません。新たな要件が生まれ、ビジネスプロセスが変化します。ERDはこれらの変化を反映するために常に更新される必要があります。
スキーマのバージョン管理
コードと同様に、データベーススキーマもバージョン管理するべきです。これにより、チームは変更履歴を時間の経過とともに追跡できます。変更によってシステムが破損した場合、以前のERDと対応するスクリプトに戻すことができます。
変更管理
ERDを変更する際は、既存データへの影響を考慮してください。既存テーブルに必須フィールドを追加するとレポートが破損する可能性があります。新しい関係を追加する場合、データ移行が必要になることがあります。設計の更新と同時に、必ず移行戦略を計画してください。
ツール vs. ペンと紙 🖊️
ERDを作成するための多くのソフトウェアソリューションは存在しますが、初期の思考プロセスは制約のない状態で行うのが最適です。ホワイトボードやペンと紙を使うことで、迅速な反復が可能になります。フォーマットやソフトウェアの制限を気にせずに、消したり、書き直したり、構造を再編できます。
論理構造が合意されたら、それを正式な図作成ツールに変換できます。これにより、ソフトウェアの制限によって概念モデルが歪められるのを防げます。ツールはモデルを支援すべきであり、モデルを支配すべきではありません。
設計に関する最終的な考察 🌟
データベースの構築は論理的な厳格な作業です。最初のステップである、しっかりとしたERDの作成が、プロジェクト全体の方向性を決定します。コードを書く前にデータの関係性について考えるよう強制します。この先見性により、技術的負債が削減され、変化に強いシステムが構築されます。
明確さに注力してください。標準的な命名規則を使用してください。キーを厳密に定義してください。ステークホルダーと検証してください。図をビジネスニーズと技術的実装の間の契約として扱ってください。これらのステップを踏むことで、データの重みを支えるのに十分な強固な基盤を確保できます。 🏗️