











堅牢なデータベースを構築するには、最初のテーブルが作成される前から準備が必要です。ビジネス上の問題を理解し、人間の言語を構造化されたデータ論理に変換することから始まります。このプロセスは「データモデリング」と呼ばれるもので、ステークホルダーが求めていることと、システムがどのようにデータを保存するかの間のギャップを埋めます。適切に構築されたエンティティ関係図(ERD)は、このインフラの設計図となります。明確な翻訳プロセスがなければ、プロジェクトはデータの重複、整合性の問題、後々に高コストな再設計を余儀なくされるリスクを抱えます。
このガイドでは、原始的な要件から完成したERDへと移行するための実践的なステップを詳しく説明します。論理、関係性、そしてデータモデルが長期間にわたって耐えうるようになるために必要な批判的思考に焦点を当てます。
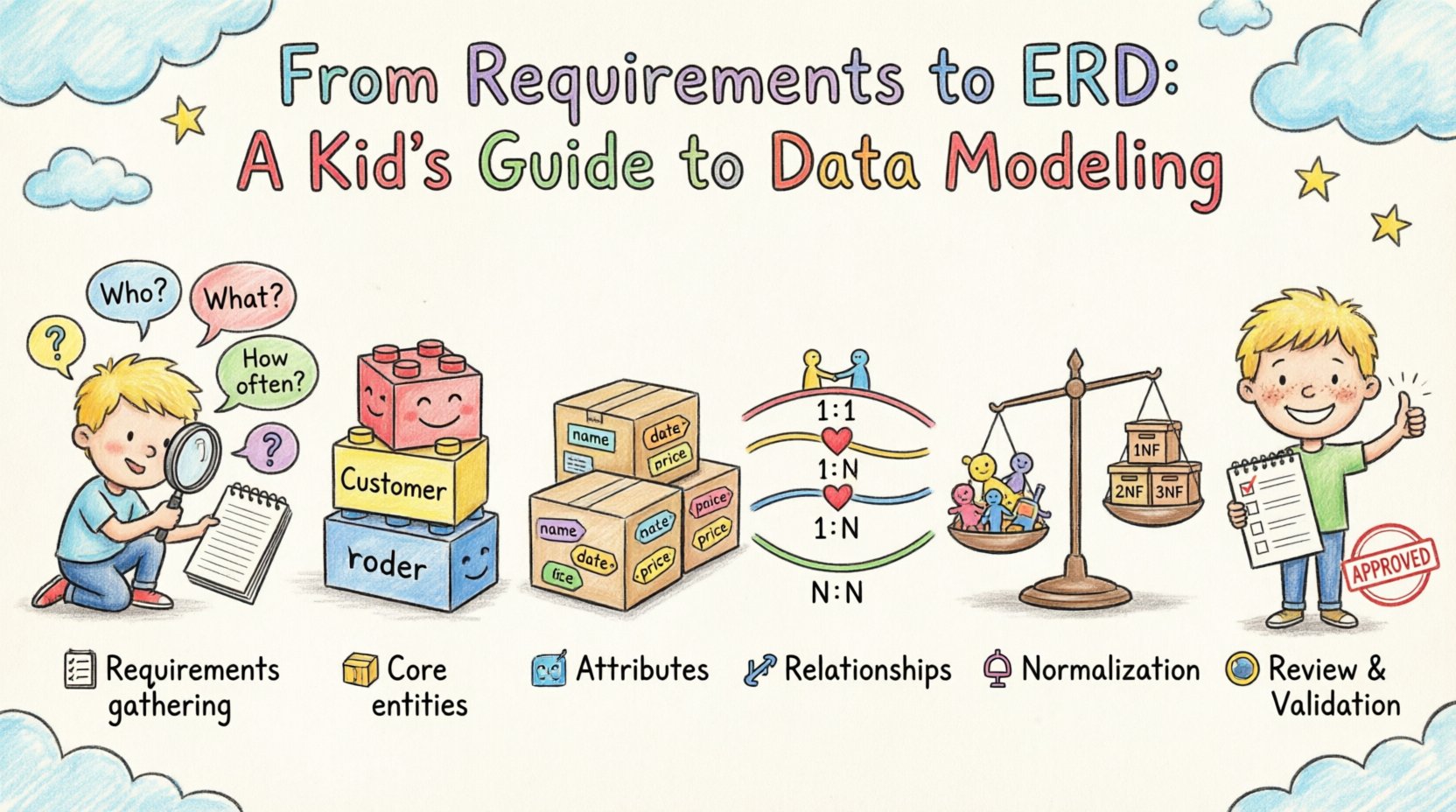
1. 入力の理解:要件の収集と分析 📋
あらゆるデータベース設計の基盤は要件にあります。これらの要件は、当初提示された際にはしばしば曖昧で、矛盾している、あるいは不完全な状態です。目的は「何」と「なぜ」を、まず「どうやって.
ビジネスプロセスの特定
まず、ワークフローを整理しましょう。ステークホルダーに日々の業務を説明してもらいます。情報の保存に関わる行動に注意を向けましょう。たとえば、物流マネージャーが次のように言うかもしれません。「どのパッケージがいつどこにあるかを追跡する必要がある。」この文には、パッケージ、その位置、タイムラインといった複数のデータポイントが含まれています。
- ステークホルダーへのヒアリング:マネージャーだけでなく、エンドユーザーとも会議をスケジュールしましょう。彼らは上位の要約では見逃されがちなエッジケースを明らかにすることが多いです。
- ルールの文書化:ビジネスルールを明確に記録しましょう。「顧客は同時に複数の有効なサブスクリプションを持つことはできません。」これは単なる機能ではなく、制約です。ビジネスルールを明確に記録しましょう。「顧客は同時に複数の有効なサブスクリプションを持つことはできません。」これは単なる機能ではなく、制約です。ビジネスルールを明確に記録しましょう。「顧客は同時に複数の有効なサブスクリプションを持つことはできません。」これは単なる機能ではなく、制約です。
- 既存システムのレビュー:古いシステムから移行する場合、レガシーデータを分析しましょう。実際に使われているフィールドは何か?どのフィールドが非推奨になったのか?
定性的要件と定量的要件
すべての要件が同等ではありません。データの性質とデータの量の違いを明確にしなければなりません。
- 定性的:意味と種類を定義します。日付は誕生日か取引日か?名前は1つの文字列か、名と姓に分かれるか?
- 定量的: 制限を定義する。1日あたりのレコード数はどれくらいか?保持期間はどのくらいか?
ここでの混乱は、劣ったスキーマ設計につながる。たとえば、電話番号をテキスト文字列として扱うとフォーマット用の文字を許可できるが、整数として扱うと必要な接頭辞が削除される可能性がある。意思決定は早期に文書化しなければならない。
2. コアとなるエンティティの特定 🏗️
要件が明確になったら、次のステップはエンティティを特定することである。エンティティとは、データを保存しなければならない現実世界の物体や概念を表す。ERDでは、これらは通常長方形で表される。
発見のための手法
エンティティを見つけるには、要件を名詞でスキャンする。しかし、すべての名詞がエンティティというわけではない。データの保存が必要で、固有の識別子を持つ名詞のみを絞り込む必要がある。
- 直接的な名詞: 顧客, 製品, 請求書これらは明らかに候補となる。
- 隠れた名詞: ときにはエンティティは動詞の中に隠れていることがある。「プロジェクトをチームに割り当てる。」 ここではプロジェクト とチーム がエンティティである。割り当て 割り当てには独自の属性(割り当て日時など)がある場合、関係性または別個のエンティティとなる可能性がある。
- 除外される名詞: 『システム, ユーザー(一般的な意味で)、または データはしばしば抽象的になりがちです。具体的にしましょう。それは登録ユーザー か、ゲスト?
エンティティのアイデンティティの定義
すべてのエンティティは、1つのインスタンスを他のインスタンスと区別する方法を持つ必要があります。これがプライマリキーです。概念段階では、このキーが自動増分番号かUUIDかを決める必要はありませんが、アイデンティティが必要であることを認識する必要があります。
- 自然キー:現実世界の属性が一意の識別を提供するか?(例:社会保障番号や車両識別番号など)。
- 代替キー:自然キーが存在しない、またはキーが頻繁に変化する場合は、システム生成のユニークIDが必要です。
エンティティ従業員を検討してください。従業員IDがキーなのか、それとも名前と部署の組み合わせが一意なのかどうかです。通常、名前の変更や重複名の問題を防ぐために、ユニークIDの方が安全です。
3. 属性とデータ型の定義 🏷️
属性はエンティティを説明する性質です。詳細を埋めます。エンティティが箱だとすれば、属性はその箱のラベルです。
属性の分類
属性は論理的にグループ化すべきです。一部は必須、一部は任意、一部は導出されるものです。
- 必須属性:エンティティが有効であるために存在しなければならないデータ。(例:注文日注文のためのもの)。
- 任意属性:存在する場合もあれば、存在しない場合もあるデータ。(例:補足メールアドレスユーザーのためのもの)。
- 導出属性: 他の属性から計算されたデータ。 (例:年齢 から導出される生年月日) 通常、更新の不整合を避けるために物理的に保存されませんが、モデルにおいて重要な役割を果たします。
データ型の選択
ERDは概念的なものですが、ストレージ型について考えることで将来のエラーを防げます。型の不一致はパフォーマンスの問題やデータ損失を引き起こします。
| 属性の概念 | 推奨される型 | 理由 |
|---|---|---|
| 名前、住所 | VARCHAR / テキスト | 可変長で、数値以外の文字を含む。 |
| 数値、価格 | 整数 / 小数 | 数学的演算、精度の要件。 |
| 日付、時刻 | 日付 / 日時 | 並べ替え、フィルタリング、期間計算が可能。 |
| イエス/ノーのフラグ | 論理型(Boolean) | 真偽の状態を明確に表現できる論理。 |
| 大規模な文書 | BLOB / ファイル参照 | バイナリデータを格納するか、外部ストレージへのリンクを保持する。 |
属性の正規化
エンティティ間の線を引く前に、属性が原子的であることを確認してください。属性は1つの値しか保持してはいけません。例えば「電話番号_1、電話番号_2、電話番号_3」のように1つのフィールドに複数の電話番号を保存しないでください。代わりに、連絡先情報 は にリンクされています顧客.
- なぜアトミックなのか? クエリを簡素化します。電話番号が連結されている場合、特定の電話番号を検索することは不可能です。
- 柔軟性: 顧客が2つ目の電話番号を取得した場合、別個のエンティティにより、スキーマを変更せずに無限に拡張できます。
4. 関係のマッピングと基数 🔗
エンティティはほとんどが孤立して存在するわけではなく、相互に作用します。ERDにおけるエンティティを結ぶ線は、関係を表しています。これらを正しく定義することが、モデル化プロセスで最も重要な部分です。
関係の種類
関係は、あるエンティティのインスタンスが別のエンティティのインスタンスとどのように関連しているかを説明します。
- 1対1(1:1):エンティティAの1つのインスタンスが、エンティティBの正確に1つのインスタンスに関連しています。例:従業員 から 従業員バッジ.
- 1対多(1:N):エンティティAの1つのインスタンスが、エンティティBの多数のインスタンスに関連していますが、BはAに対して1つだけ関連しています。例:著者 から 書籍.
- 多対多(M:N):Aの多数のインスタンスが、Bの多数のインスタンスに関連しています。例:学生 から クラス. 注意: 物理的な実装では、これ often 中間エンティティ(結合テーブル)が必要になる。
基数とモダリティ
基数は数を定義する(1、複数)。モダリティは必須性を定義する(必須、任意)。これらを可視化することは、データの整合性にとって不可欠である。
- ゼロまたは一つ: この関係は任意であり、一つまでしか許可されない。
- 一つでなければならない: この関係は必須であり、一つまでしか許可されない。
- ゼロまたは複数: この関係は任意であり、複数が許可される。
- 一つまたは複数: この関係は必須であり、複数が許可される。
以下の関係を検討する:注文 および 顧客 関係。顧客は少なくとも一つの注文をしなければならない(必須)。注文は一つの顧客に属しなければならない(必須)。これにより、データベース内の外部キー制約が定義される。
5. データ整合性と正規化の確保 ⚖️
図が描かれたら、論理的な整合性を確認する必要がある。この段階では、冗長性を排除し、安定性を確保するために正規化ルールを適用する。
第一正規形(1NF)
すべての列が原子値を含み、繰り返しグループがないことを確認する。すべての行は一意でなければならない。
- 確認: セルにリストは含まれているか? 単一のフィールドに複数の値は含まれているか?
- 修正: リストを別々の行または別々のテーブルに分割する。
第二正規形(2NF)
すべての属性が主キーに完全に依存していることを確認する。複合キーがある場合は、属性がそのキーの一部にのみ依存してはならない。
- 例: 以下のようなテーブルに格納されている場合:学生ID, コースID、および学生名、その学生名は、ただその学生IDに依存するだけであり、組み合わせではない。学生名を学生テーブルに移動する。
第三正規形(3NF)
推移的依存関係が存在しないことを確認する。非キー属性は、他の非キー属性に依存してはならない。
- 例:もし都市に依存する場合、郵便番号、および郵便番号が顧客テーブルにある場合、郵便番号および都市を場所 テーブル。これにより、数千もの顧客レコードにわたって都市名の更新が一貫性を持たなくなるのを防ぎます。
6. レビューと検証 🧐
モデルは、元の要件に対して検証されるまで完成したものとは言えません。これは、何かを見落としたり誤解したりしていないかを確認するための健全性チェックです。
ウォークスルー シナリオ
モデルがそれらをサポートしているかどうかを確認するために、特定のユースケースを検証します。次のような質問をします:
- 「顧客なしで注文を作成することは可能ですか?」 モデルがこれを許可しているが、ビジネスルールでは禁止されている場合、関係の基数が誤っているのです。
- 「注文中に存在する製品を削除することは可能ですか?」 答えが「いいえ」の場合、参照整合性制約(連鎖削除)が必要です。
- 「顧客が名前を変更した場合、どうなりますか?」 名前が注文テーブルにも保存されている場合、データの一貫性リスクがあります。名前は顧客テーブルにのみ保存すべきです。
ステークホルダーの承認
ERDをビジネスユーザーに提示してください。技術用語は理解できなくても、論理は理解できます。エンティティと関係がビジネスのメンタルモデルと一致しているか確認してもらいましょう。
- 視覚的確認: 図を用いて、データがどこに存在するかを示します。
- ギャップ分析: 属性リストに重要なデータポイントが欠けているかどうかを尋ねます。
- 将来対応: 将来の変更について議論します。ビジネスが新しい地域に展開する予定がある場合、モデルはそれをサポートしていますか?
翻訳における一般的な課題 🛑
経験豊富なモデラーでさえ、要件を翻訳する際に障害に直面します。これらの落とし穴を認識しておくことで、回避できます。
- 過剰モデリング:すべての将来のニーズを予測しようとすると、複雑で硬直したスキーマになります。現在の要件に合わせて設計する一方で、拡張の余地を残す(たとえば、適切な場合に柔軟なメタデータ用にJSONカラムを使用するなど)。
- 不足モデリング:制約を無視すると、データが乱雑になります。フィールドが必須の場合、モデルではオプションにしないでください。
- エンティティと関係を混同する: 時には、関係に多くの属性が付与されすぎて、それがエンティティそのものになってしまうことがあります。(例:登録 と 生徒 と コース には が ある可能性がある 成績 と 日付)。独自の履歴や属性が必要な場合は、エンティティとして扱ってください。
- 大文字小文字を無視する: 一部のシステムでは、「ニューヨーク」 と 「new york」 は異なります。標準化ルールを早期に決定してください。
- ハードウェア性能を前提とする: 完全性を損なう代償で速度を最適化してはいけません。誤ったデータよりも遅いクエリの方が良いです。
持続可能なモデルのためのベストプラクティス ✅
数年間にわたり健全なデータベースを維持するため、設計段階でこれらのガイドラインに従ってください。
- 一貫した命名規則: エンティティには単数名詞を使用する(例:カスタマー ではなく カスタマーズ)。カラムには小文字とアンダースコアを使用する(例:customer_id)。これにより曖昧さが減少します。
- ドキュメント: 図をコメントで説明する。関係が存在する理由を、単に「存在する」ということではなく、なぜ なぜ関係が存在するのかを説明する。単に「存在する」ということだけではなく、それが存在する それは存在する。これにより、将来の開発者がビジネスロジックを理解しやすくなる。
- バージョン管理: ERDをコードのように扱う。要件が変更されるたびにバージョンを保存する。これにより、設計決定が実行不可能であることが判明した場合に元に戻せる。
- 標準化: 可能な限り標準データ型を使用する。絶対に必要な場合を除き、カスタム型を避ける。
- セキュリティ上の考慮事項: 敏感データ(PII、金融情報など)を早期に特定する。モデルがカラムレベルでの暗号化またはマスキングを可能にするように確認する。
翻訳プロセスにおける最終的な考察 🎯
要件からERDへ移行することは線形的なプロセスではない。反復的である。関係を定義する過程で新たなエンティティを特定するだろう。正規化を進める中で属性を洗練していく。最初のドラフトで完璧を目指すのではなく、洗練可能な堅実な基盤を構築することが目的である。
強固なデータモデルは技術的負債を削減する。データ構造が新しい機能をサポートできず、システムを再構築しなければならない状況を防ぐ。ビジネスの論理に注目し、厳密な翻訳手法を適用することで、信頼性が高く、スケーラブルで保守可能なシステムを構築できる。
分析には時間をかけること。図面の洗練に費やす時間は、開発段階でのデバッグやリファクタリングに数週間を費やすことを防ぐ。ERDをビジネスと技術の間の契約として扱う。