











堅牢なデータベースを設計することは、あらゆるソフトウェアアプリケーションの基盤です。構造的な計画がなければ、データは散らばり、検索が難しくなり、エラーが発生しやすくなります。エンティティ関係図(ERD)は、この構造の設計図として機能します。データエンティティがどのように相互作用するかを可視化することで、コードが1行も書かれる前から整合性を確保できます。このガイドでは、最初のERDを作成するプロセスを、核心的な概念、表記法、実践的なステップに焦点を当てて紹介します。
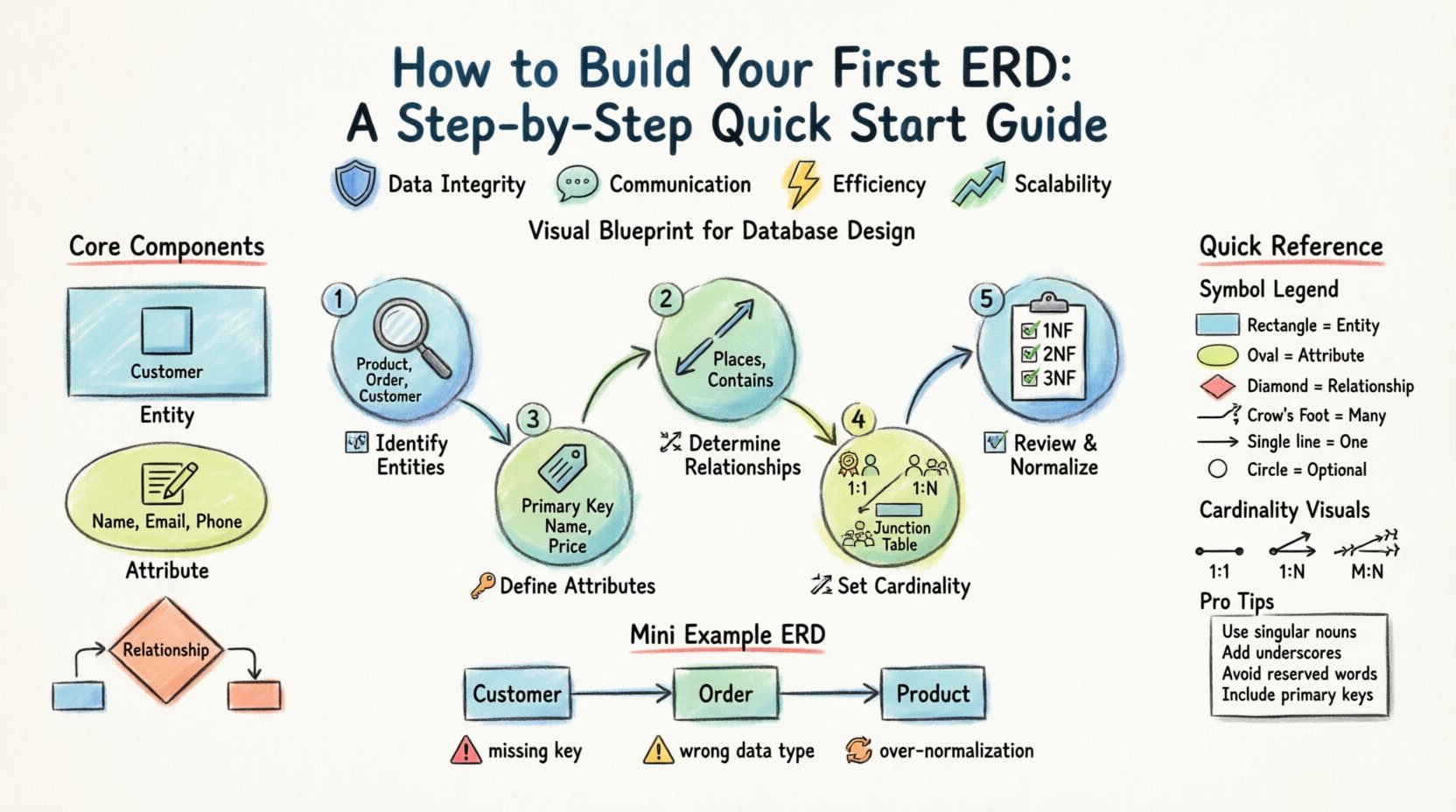
エンティティ関係図の理解 📊
ERDは、データベーススキーマの視覚的表現です。エンティティ、その属性、およびそれらの間の関係を明示します。これはデータの地図と考えてください。道路地図がA地点からB地点へ移動するのを助けるように、ERDはデータベース管理システムがテーブル間の関係を把握するのを助けます。
なぜこれが重要なのか?
- データ整合性: システム全体でデータが一貫性と正確性を保つことを保証します。
- コミュニケーション: 開発者、データベース管理者、ステークホルダー間で共通の言語を提供します。
- 効率性: 冗長性を早期に特定できるため、実装フェーズでの時間を節約できます。
- スケーラビリティ: よく設計されたスキーマは、データベースを完全に再設計せずに拡張可能にします。
ERDの核心的な構成要素
線やボックスを描く前に、構成要素を理解する必要があります。すべての図は、この3つの基本要素に依存しています。
- エンティティ: データが格納される対象となる現実世界のオブジェクトまたは概念です。例として 顧客, 注文、または 製品.
- 属性: エンティティの特定の性質や特徴です。たとえば 顧客 について、属性には 氏名, メールアドレス、および電話番号.
- 関係: 2つ以上のエンティティ間の関連。これは、1つのエンティティ内のデータが別のエンティティ内のデータとどのように関連するかを定義する。
一般的なERD記号と表記法 🛠️
これらのコンポーネントを視覚的に表現する方法はいくつかあります。最も一般的な2つのスタイルはチェン記法とクロウズフット記法です。チェン記法では長方形とダイヤモンドを使用するのに対し、クロウズフット記法では長方形と特定の端を持つ線を使用します。ほとんどの現代のデータベースモデリングツールは、クロウズフット記法のバリエーションを利用しています。
| 記号 | 意味 | 使用例 |
|---|---|---|
| 長方形 | エンティティを表す | ラベルが付いたボックス学生 |
| 楕円 | 属性を表す | 接続された楕円学生ラベルがID |
| ダイヤモンド | 関係を表す | 接続するダイヤモンド学生およびコース |
| クロウズフット付きの線 | 「多数」(M)を示す | 1人の学生が多数のコースを受講できる |
| 単一のタック付きの線 | 「1つ」を示す(1) | コースには1人のインストラクターがいる |
| 円 | 任意参加を示す | 学生にはまだ割り当てられたIDがない可能性がある |
初めてのERD作成のためのステップバイステップガイド 🚀
ERDを構築することは論理的なプロセスです。最終的なコードを知らなくても構いません。ビジネス要件を理解する必要があります。堅固な基盤を作成するには、以下のステップに従ってください。
ステップ1:エンティティを特定する 📦
最初のタスクは、システム内のすべての異なるオブジェクトをリストアップすることです。ビジネス要件書を確認するか、ステークホルダーにインタビューして名詞を見つけてください。これらの名詞が通常、エンティティになります。
- 名詞を検索する: ライブラリシステムを構築している場合、Book(本)、Member(会員)、Loan(貸出)、Fine(罰金)などの単語を探してください。
- 関係のない項目を除外する: すべての名詞がエンティティというわけではありません。たとえば処理 または 確認 は通常、行動であり、エンティティではありません。
- 粒度を細かく保つ: 複数の概念を1つのボックスにまとめないでください。たとえばCustomerAddress(顧客住所) エンティティは、複数の住所を追跡する必要がある場合、最終的に顧客 とAddress(住所) に分割する必要があるかもしれません。
例のリスト:
- 製品
- 仕入先
- 注文
- 顧客
ステップ2:属性を定義する 🏷️
エンティティが特定されたら、それらについて保存する必要がある情報の内容を決定しなければなりません。属性は、最終的に作成するデータベーステーブルの列です。
- プライマリキー:すべてのエンティティには一意の識別子が必要です。通常はIDフィールド(例:
CustomerID,ProductID)です。すべてのレコードで一意である必要があります。 - 記述属性:これらはエンティティを記述します。たとえばProductについては、Name, Price、およびStockQuantity.
- 外部キー:これらは後で関係性のステップで特定されますが、データが他のテーブルにリンクする場所をメモしておいてください。
ベストプラクティス:計算された値を属性として保存しないようにしましょう(例:TotalPrice)。実行時に計算することで、データの不整合を防ぎましょう。
ステップ3:関係性を決定する 🔗
今、エンティティをつなぎます。このステップでデータの相互作用の仕組みを定義します。たとえば、「1人の顧客が複数の注文を持つことができるか?」や「1つの注文が複数の顧客に属することができるか?」といった質問をします。
- 関連を特定する:要件の中の動詞を探してください。場所, 含まれる, 供給する.
- 方向を定義する:関係が単方向か双方向かを確認する。
- 推移性を確認する:関係が直接的であることを確認する。AがBに関係し、BがCに関係する場合、AがCに直接リンクする必要があるかを確認する。
ステップ4:基数と参加制約を設定する 📏
基数は、あるエンティティのインスタンスが、別のエンティティのインスタンスと関係する数を定義する。これは外部キー制約を定義する上で重要である。
基数の種類
- 1対1 (1:1):エンティティAの1つのインスタンスが、エンティティBの正確に1つのインスタンスに関係する。例:1人の従業員が1枚の従業員バッジを持つ。
- 1対多 (1:N):エンティティAの1つのインスタンスが、エンティティBの多数のインスタンスに関係する。例:1人のマネージャーが多数の従業員を監督する。
- 多対多 (M:N):エンティティAの多数のインスタンスが、エンティティBの多数のインスタンスに関係する。例:多数の学生が多数の授業に登録する。
参加制約
- 必須:エンティティは関係に参加しなければならない。すべての注文には顧客が存在しなければならない。
- 任意:エンティティが参加しなくてもよい。顧客が店頭での支払いのみの場合、配送先住所を持たないこともある。
多対多に関する注意:ほとんどのリレーショナルデータベースは、多対多関係を直接格納できない。結合テーブル(またはブリッジテーブル)を作成することで解決しなければならない。学生と授業の場合、StudentIDとCourseIDをリンクするテーブルを「登録」という名前のテーブルを作成する。
ステップ5:見直しと正規化 🧹
接続を描いた後は、図の構造上の欠陥がないか確認する。正規化とは、データの重複を減らし、整合性を高めるためにデータを整理するプロセスである。
- 第一正規形 (1NF):すべての列が原子値を含むことを確認する。1つのセルにリストや配列を含めない。
- 第二正規形 (2NF): すべての非キー属性が主キーに完全に依存していることを確認する。部分的依存関係を削除する。
- 第三正規形 (3NF): 推移的依存関係が存在しないことを確認する。他の非キー属性に依存する属性を削除する。
ほとんどのアプリケーションでは3NFを超える必要はありませんが、設計がこれらのルールに従っていることを確認することで、データの異常を防ぐことができます。
避けるべき一般的な落とし穴 ⚠️
経験豊富なデザイナーでさえミスを犯します。一般的な誤りに気づいておくことで、後で大きなリファクタリングを回避できます。
- 主キーの欠落: 一意の識別子のないテーブルを作成してはいけません。これにより、レコードの更新や削除がほぼ不可能になります。
- 不適切なデータ型: 属性がデータと一致していることを確認する。日付をテキストとして保存してはいけません。セントが必要な場合は、価格を整数として保存してはいけません。
- 過剰な正規化: 正規化は良いことですが、テーブルが多すぎるとクエリが遅くなり、複雑になります。整合性とパフォーマンスのバランスを取る必要があります。
- 大文字小文字の区別を無視する: システムが大文字小文字を区別するかどうかを早期に決定する。[email protected] は、[email protected].
- ハードコードされた値: 例えば
1や2といった参照テーブルなしで保存しないでください。ステータスとして有効, 無効, 保留中.
命名規則のベストプラクティス 📝
命名の一貫性により、ERDおよびその結果として得られるデータベースが、関係するすべての人にとって読みやすくなります。混乱を招く名前は、コード内の混乱を引き起こします。
- 単数名詞を使用する: テーブル名は単数形で (例:Customer ではなく Customers).
- アンダースコアを使用する: 読みやすくするために単語の間にアンダースコアを使用する (例:
customer_nameではなくcustomername). - 予約語を避ける: 以下のキーワードを変更せずにテーブル名として使用しないでください:Order, User、または Group は、SQL構文と衝突する可能性があるため、変更せずにテーブル名として使用しないでください。
- 明確に記述する: 明確な名前を使用する。
cust_idは問題ないが、customer_idの方が明確さを考慮すると良いです。 - 接頭辞を統一する: 特定のスキーマを使用する場合、プレフィックスを維持してください(例:
tbl_またはref_).
データフローの可視化 🔄
図が完成したら、データがシステム内でどのように移動するかを可視化しましょう。これにより、アプリケーションの論理を理解しやすくなります。
- 挿入: 新しいデータは主エンティティにどのように入力されますか?(例:新しい顧客レコード)
- 更新: データはどのように更新されますか?(例:住所の変更)
- 削除: レコードが削除されたときに関連データはどうなりますか?(例:カスケード削除 vs. 制限)
- 照会: データをどのように取得しますか?(例:OrderテーブルとCustomerテーブルを結合する)
図面作成のためのツール 🖥️
紙に描くこともできますが、デジタルツールにはバージョン管理や自動SQL生成などの利点があります。ツールを選択する際は、標準的なERD表記をサポートする機能があるか確認してください。
- 共同作業: 複数のユーザーが同時に図を編集できますか?
- エクスポートオプション: SQLスクリプト、PNG、またはPDFにエクスポートできますか?
- 検証: ツールは正規化ルールや循環依存関係をチェックしますか?
- 統合: 既存のワークフローまたはプロジェクト管理ツールと統合できますか?
よくある質問 ❓
ここでは、データベース設計を始める初心者がよく質問する一般的な質問に対する回答を紹介します。
1. ERDを作成する前にSQLを知っている必要はありますか?
いいえ。ERDは設計ツールです。SQLを書かずに論理構造を作成できます。図面は、最終的に書く必要があるSQLを理解するのに役立ちます。
2. ERDは後で変更できますか?
はい、ただし最小限に抑えるべきです。データベースにデータが入った後にERDを変更すると、費用がかかり、リスクも高くなります。設計をデプロイの前に完成させるのが最も良いです。
3. ロジカルERDと物理ERDの違いは何ですか?
- ロジカルERD: 特定のデータベースソフトウェアの詳細を気にせずに、エンティティと関係性に焦点を当てる。
- 物理ERD: 特定のデータベース管理システムに必要な特定のデータ型、インデックス、制約を含む。
4. 何枚のテーブルが多すぎると言えるでしょうか?
固定された数はありません。複雑さに依存します。しかし、簡単なアプリケーションのためにあまりにも多くのテーブルを作成していると、過剰に正規化している可能性があります。
5. 非関係データを含めるべきでしょうか?
標準的なERDは関係データ用です。ドキュメントストアやグラフデータベースを設計している場合、概念はわずかに異なります。このガイドは関係モデルに焦点を当てています。
最終的な考察 🎯
初めてのERDを作成するには、忍耐と細部への注意が必要です。単に図形を描くことではなく、現実世界の論理を構造化された形式にモデル化することです。上記で示した手順に従うことで、データベースがスケーラブルで効率的かつ保守しやすいことを保証できます。
まずは小さな規模から始めましょう。最初に簡単なシステムをマッピングしましょう。エンティティと関係性を識別する練習を重ねましょう。経験を積むにつれて、複雑なシステムの設計が直感的になることに気づくでしょう。良いデータベース設計はユーザーには見えないものですが、アプリケーションの成功には不可欠です。
正規化の段階には時間をかけましょう。これはプロセスの中で最も技術的な部分ですが、データの品質向上につながります。ここですでに説明した記号や規則を使用して、図を明確に保ちましょう。しっかりとしたERDを手に入れたら、実装に進む準備が整います。