











Моделирование данных часто рассматривается как статическое упражнение по определению отношений и сущностей. Однако диаграмма сущностей и отношений (ERD) — это не просто чертеж для хранения; она напрямую определяет, насколько эффективно движок базы данных извлекает и обрабатывает информацию. Каждая линия, каждый установленный тип связи и каждый выбранный тип данных влияют на план выполнения ваших запросов. Понимание механизмов проектирования схемы позволяет создавать системы, которые плавно масштабируются под нагрузкой.
В этом руководстве рассматривается техническая связь между структурами ERD и производительностью запросов. Мы выйдем за рамки базовых определений, чтобы изучить, как конкретные решения при моделировании влияют на операции ввода-вывода, использование ЦП и механизмы блокировок в реляционной среде.
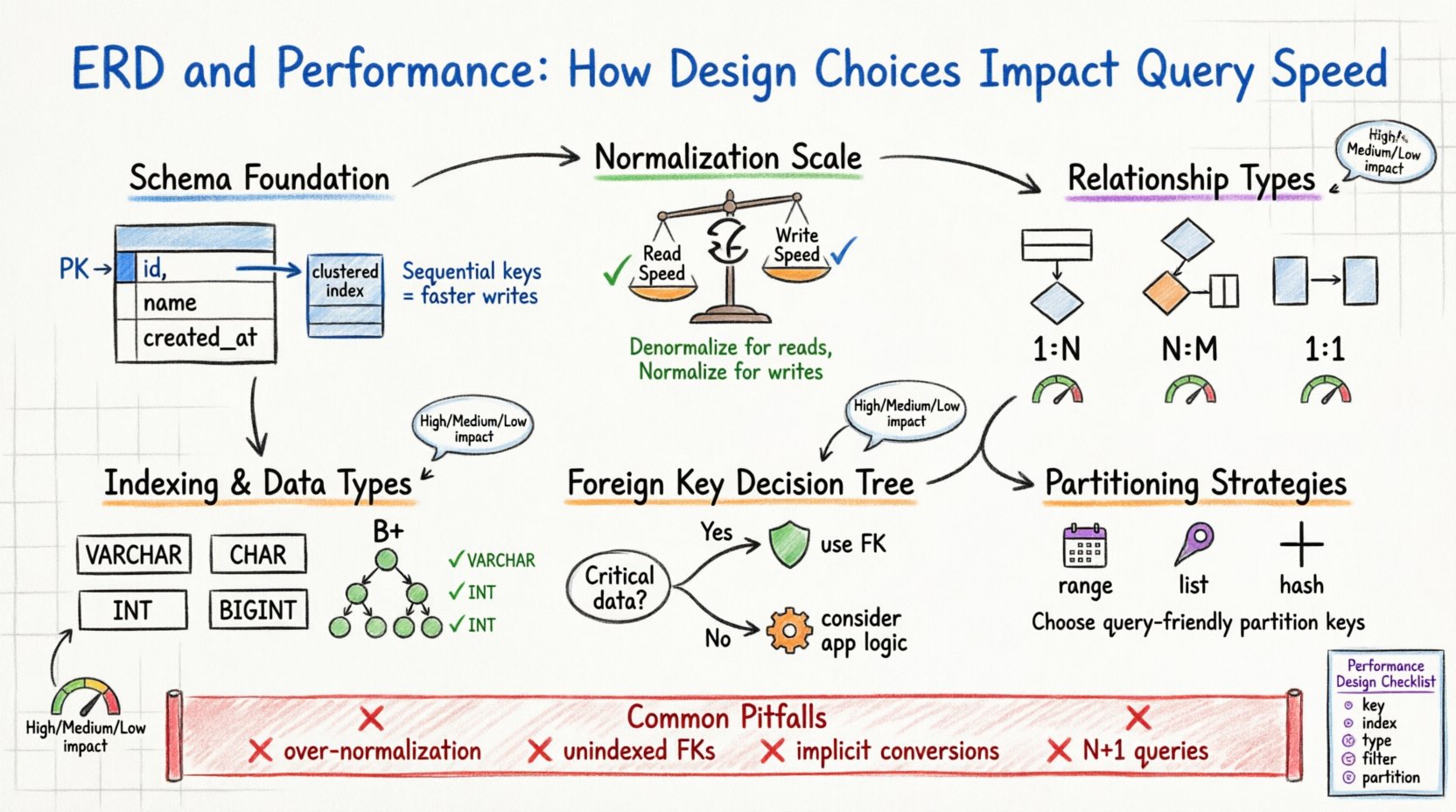
1. Основа: структура схемы и физическое хранение 🏗️
Логический дизайн, который вы создаете в ERD, в конечном итоге преобразуется в физические файлы на диске. Движок базы данных должен сопоставлять эти логические сущности с страницами, блоками и строками. Когда схема оптимизирована, движок минимизирует количество чтений с диска, необходимых для удовлетворения запроса. Если же схема не оптимизирована, движку может потребоваться выполнить полное сканирование таблицы, что является дорогостоящей операцией.
Обратите внимание на первичный ключ. Он служит уникальным идентификатором строки. Во многих системах хранения первичный ключ определяет физический порядок данных на диске (кластеризованный индекс). Выбор последовательного и короткого первичного ключа обеспечивает хранение данных непрерывно. Это снижает фрагментацию и позволяет быстрее выполнять диапазонные поиски. Напротив, случайный, длинный первичный ключ может вызвать разделение страниц при вставке, что ухудшает производительность записи и увеличивает объем хранимых данных.
Ключевые соображения при выборе первичных ключей
- Последовательность:Автоматически увеличивающиеся целые числа обычно предпочтительны для рабочих нагрузок с высокой интенсивностью записи.
- Размер:Меньшие ключи уменьшают размер вторичных индексов, поскольку они хранятся в виде указателей в этих индексах.
- Стабильность:Первичные ключи не должны изменяться. Обновление первичного ключа часто требует обновления всех связанных внешних ключей.
2. Нормализация против компромиссов производительности ⚖️
Нормализация — это процесс организации данных для уменьшения избыточности и повышения целостности. Хотя традиционно она связана с качеством данных, она оказывает глубокое влияние на производительность. Высоко нормализованная схема (например, третья нормальная форма) часто требует большего количества соединений для восстановления данных, тогда как денормализованная схема уменьшает количество соединений, но увеличивает объем хранилища и сложность обновления.
Решение нормализовать или денормализовать — это баланс между скоростью чтения и скоростью записи. В среде с высокой нагрузкой на чтение денормализация может значительно сократить время выполнения запросов за счет избежания сложных соединений. В среде с высокой нагрузкой на запись нормализация уменьшает количество строк, которые необходимо обновить в нескольких таблицах.
Анализ влияния нормализации
| Аспект | Высоко нормализованная | Денормализованная |
|---|---|---|
| Производительность чтения | Ниже (требует соединений) | Выше (доступ к одной таблице) |
| Производительность записи | Выше (меньшая избыточность) | Ниже (обновление нескольких копий) |
| Целостность данных | Высокая (единственный источник истины) | Ниже (риски несогласованности) |
| Использование хранилища | Ниже | Выше |
3. Внешние ключи и накладные расходы на целостность 🔗
Внешние ключи обеспечивают ссылочную целостность. Они гарантируют, что значение в одной таблице соответствует значению в другой. Хотя это предотвращает появление «сиротских» записей, это вводит накладные расходы во время выполнения. При вставке, обновлении или удалении строки база данных должна проверить ограничение внешнего ключа.
Эта проверка не бесплатна. Двигатель должен найти ссылочную строку и проверить её существование. Если ссылочная таблица большая и не имеет индекса по столбцу внешнего ключа, проверка превращается в полное сканирование таблицы. Более того, при удалении родительской записи движку необходимо проверить все дочерние записи, чтобы убедиться, что не осталось ссылок, что может привести к блокировке многих строк.
Когда использовать внешние ключи
- Критическая целостность данных: Если корректность данных имеет первостепенное значение (например, финансовые операции), используйте внешние ключи.
- Логика приложения: Если логика приложения сложная, передача ответственности за целостность базе данных упрощает код.
- Малые наборы данных: Накладные расходы незначительны на небольших таблицах.
Когда следует избегать внешних ключей
- Высокая пропускная способность записи: Удаление ограничений может снизить конкуренцию за блокировки.
- Аналитика в крупном масштабе: В хранилищах данных производительность часто важнее строгой целостности.
- Архитектурные уровни: В микросервисах поддержание внешних ключей через границы сервисов часто непрактично.
4. Стратегии индексации и типы столбцов 📑
Схема ERD определяет типы данных для каждого столбца. Выбор между VARCHAR и CHAR, или между INT и BIGINT, влияет на то, как данные хранятся и индексируются. Меньшие типы данных потребляют меньше памяти и места на диске, позволяя разместить больше данных в буферном пуле (ОЗУ).
Когда запрос фильтрует по столбцу, база данных полагается на индексы для быстрого поиска строк. Если проектирование схемы не соответствует паттернам запросов, индексы становятся бесполезными. Например, создание индекса по столбцу, который редко используется в предложениях WHERE, — это расточительство ресурсов.
Оптимизация типов столбцов
- Фиксированная длина против переменной длины: Используйте CHAR для данных фиксированной длины (например, коды стран), чтобы снизить фрагментацию. Используйте VARCHAR для данных переменной длины.
- Диапазоны целых чисел: Не используйте BIGINT, если достаточно INT. Меньшие целые числа помещаются больше строк на страницу.
- Представление логических значений: Используйте типы TINYINT(1) или BOOLEAN вместо хранения строк «Да»/«Нет».
5. Последствия кардинальности отношений 📊
Мощность связей (один к одному, один ко многим, многие ко многим) определяет, как данные связаны между собой. Каждый тип связи имеет различные характеристики производительности.
Один ко многим (1:М)
Это наиболее распространённая связь. В родительской таблице хранится одна запись, а в дочерней — множество. Производительность сильно зависит от индекса в столбце внешнего ключа в дочерней таблице. Без этого индекса поиск всех дочерних записей для родителя требует сканирования всей дочерней таблицы.
Многие ко многим (М:К)
Это требует наличия промежуточной таблицы (ассоциативного сущности). Это добавляет дополнительный уровень косвенной связи. Запросы, включающие связи М:К, обычно требуют трёх соединений: Таблица А, Промежуточная таблица, Таблица Б. Эта сложность увеличивает использование ЦП и потребление памяти.
Один к одному (1:1)
Часто используется для разделения большой таблицы на логические группы. Это может улучшить производительность, если часто запрашиваются только одни подмножества столбцов. Однако это добавляет стоимость соединения для получения полной записи.
6. Рассмотрение разделения и шардирования 🗃️
По мере роста данных одна таблица может стать слишком большой для эффективного управления. Разделение позволяет разделить большую таблицу на более мелкие и управляемые части на основе ключа (например, даты). Проектирование ERD должно учитывать это.
Если вы проектируете схему для системы, которая в конечном итоге будет шардирована (разделена между несколькими серверами), ключ разделения должен быть выбран тщательно. Ключ должен часто использоваться в запросах, чтобы механизм мог направлять запросы на правильный шард. Выбор ключа, который не используется в запросах, вынуждает систему агрегировать данные со всех шардов, что медленно.
Стратегии разделения
- Разделение по диапазону: Разделение по диапазонам дат или ID. Подходит для временных рядов.
- Разделение по списку: Разделение по конкретным значениям (например, коды регионов).
- Хэш-разделение: Распределяет данные равномерно, чтобы избежать «горячих точек».
7. Распространённые ошибки при проектировании 🚫
Даже опытные архитекторы могут ввести узкие места производительности из-за выбора архитектуры. Раннее распознавание этих паттернов предотвращает дорогостоящую рефакторизацию в будущем.
- Чрезмерная нормализация:Разделение данных на слишком много маленьких таблиц увеличивает сложность соединений и снижает эффективность кэширования.
- Пренебрежение селективностью:Индексация столбцов с низкой селективностью (например, пол или флаги статуса) часто даёт плохую производительность, потому что оптимизатор может игнорировать индекс и всё равно сканировать таблицу.
- Неявные преобразования:Проектирование столбца как строки, когда ожидаются числовые значения, вынуждает механизм преобразовывать типы во время запросов, что мешает использованию индексов.
- Паттерны запросов N+1:Проектирование связей, которые поощряют получение данных в циклах, а не с помощью пакетных соединений, может перегрузить сервер.
8. Защита от будущих изменений и эволюция 🛡️
Базы данных эволюционируют. Требования меняются, добавляются новые функции. Схема, эффективная сегодня, может стать узким местом завтра, если она не обладает гибкостью. ERD должен учитывать рост без необходимости полной переписи.
Рассмотрите возможность добавления столбцов, которые, вероятно, будут использоваться для фильтрации в будущем. Хотя это немного увеличит размер строки, это сэкономит затраты на изменение структуры таблицы позже, что может быть дорогостоящей операцией на больших наборах данных. Также учтите влияние добавления новых индексов. Каждый индекс потребляет ресурсы записи. Проектируйте схему так, чтобы минимизировать количество необходимых индексов.
Чек-лист проектирования для производительности
- Являются ли первичные ключи короткими и последовательными?
- Проиндексированы ли внешние ключи?
- Являются ли типы данных наименьшими возможными допустимыми типами?
- Покрываются ли частые фильтры индексами?
- Уровень нормализации соответствует рабочей нагрузке?
- Вы рассматривали разделение для больших таблиц?
- Есть ли столбцы, хранящие сложные JSON или текст, которые можно структурировать?
9. Роль плана выполнения 📋
В конечном счете, движок базы данных решает, как выполнить запрос, на основе схемы и статистики. ERD влияет на статистику, которую собирает движок. Например, столбец с распределением уникальных значений будет обрабатываться иначе, чем столбец со смещенными данными. Понимание того, как работает план выполнения, помогает понять, почему запрос медленный.
Если запрос выполняет полное сканирование таблицы, это часто указывает на отсутствие индекса или на проектирование, которое не поддерживает эффективную фильтрацию. Если выполняется много вложенных циклов, это указывает на сложные соединения, которые можно упростить. Согласовав ERD с ожидаемыми паттернами доступа, вы направляете движок к оптимальным планам выполнения.
10. Баланс целостности и скорости ⚖️
Нет идеальной схемы. Каждый выбор в проектировании предполагает компромисс. Цель — не устранить проблемы производительности, а управлять ими стратегически. В некоторых случаях принятие небольшого риска несогласованности данных (через проверки на уровне приложения вместо ограничений базы данных) является оправданным компромиссом для экстремальной пропускной способности записи.
Регулярно проверяйте ваш ERD по фактическим журналам запросов. Выявляйте самые медленные запросы и отслеживайте их до схемы. Этот обратный поток обеспечивает, что ваша проектировка развивается в согласии с потребностями вашего приложения.
Обзор областей влияния 📝
| Элемент проектирования | Влияние на производительность | Рекомендация |
|---|---|---|
| Тип первичного ключа | Высокое (хранилище и индексация) | Последовательно используйте целые числа или UUID. |
| Внешние ключи | Среднее (нагрузка на запись) | Индексируйте столбцы с внешними ключами; удалите, если целостность обеспечивается в другом месте. |
| Нормализация | Высокое (сложность соединений) | Денормализуйте таблицы с высокой нагрузкой на чтение. |
| Типы данных | Среднее (использование памяти) | Используйте наиболее конкретный тип, доступный в данный момент. |
| Мощность | Высокая (стоимость соединения) | Оптимизируйте промежуточные таблицы для отношений N:M. |
Рассматривая диаграмму сущность-связь как объект производительности, а не просто как логическую схему, вы можете создавать системы, которые являются надежными, масштабируемыми и эффективными. Решения, которые вы принимаете сейчас, определят поведение вашей приложения в течение многих лет вперед.