









设计一个稳健的数据模型是软件工程中最关键的任务之一。实体关系图(ERD)是信息如何存储、检索和维护的蓝图。在这份蓝图的核心,正是规范化。许多从业者将规范化视为一个必须在实施前完成的僵化清单。然而,实际情况要复杂得多。在数据完整性和查询性能之间存在微妙的平衡,这需要深入的理解。
本指南探讨了ERD规范化的技术现实。它超越了教科书的定义,解决了在实际场景中严格遵守规则反而成为负担的情况。无论你是在构建事务性系统还是分析平台,了解何时停止规范化以及何时引入冗余,对于长期稳定性至关重要。
🔍 理解关系设计的核心原则
规范化不仅仅是整理数据;它关乎管理依赖关系。在关系模型中,每一列都必须与所在表的主键有明确的关系。当这种关系较弱或间接时,就会出现异常。这些异常表现为数据不一致、存储浪费以及复杂的更新逻辑。
规范化的首要目标包括:
- 数据完整性: 确保数据在整个系统中保持准确和一致。
- 存储效率: 消除相同数据的冗余副本。
- 可扩展性: 设计能够适应增长而无需结构性重写的模式。
- 可维护性: 降低更新信息所需的复杂性。
然而,实现这些目标通常需要付出代价。规范化每提升一个级别,通常都会增加表的数量以及获取关联数据所需查询的复杂性。理解这种权衡,是进行有效模式设计的第一步。
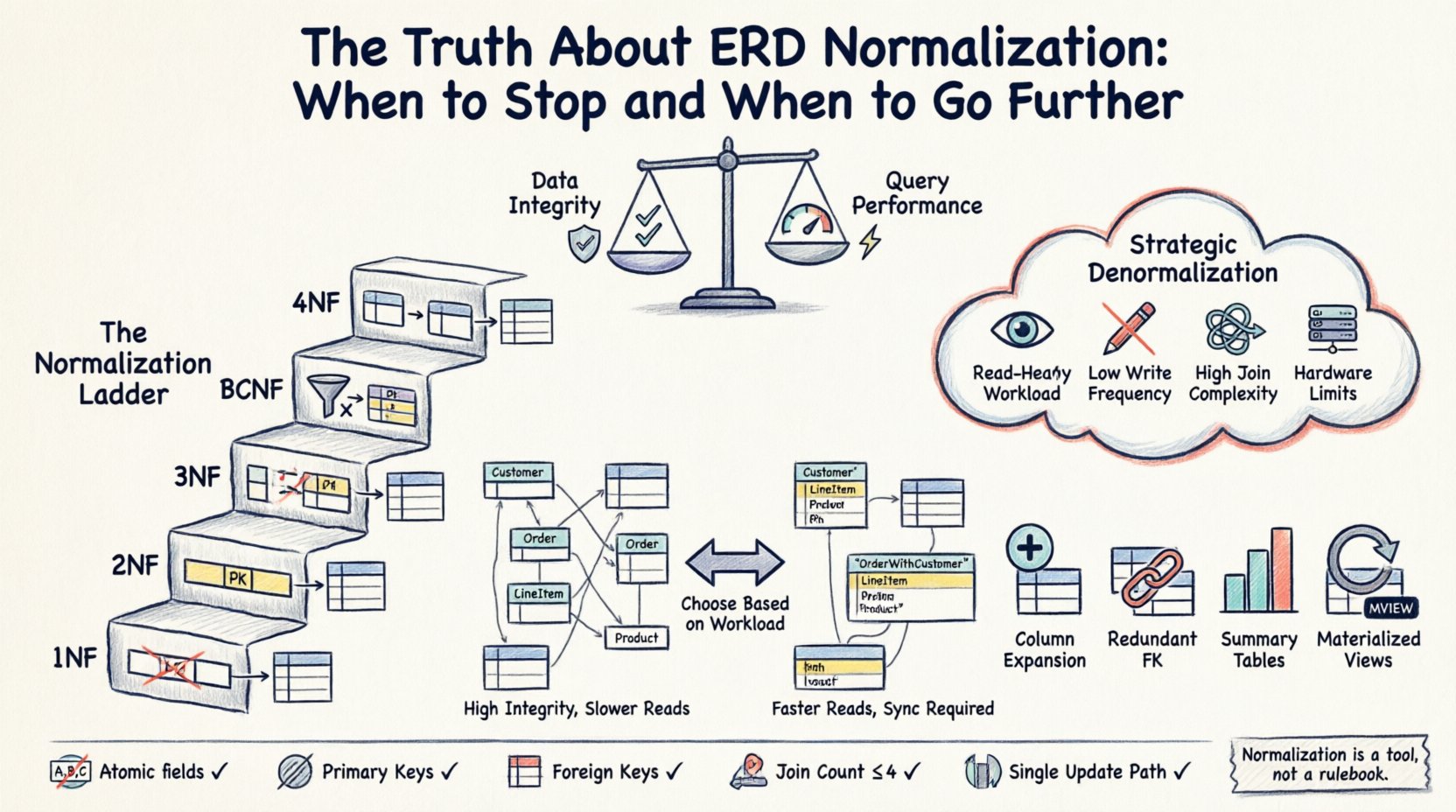
⚙️ 标准规范化的三大支柱(1NF、2NF、3NF)
在决定停止或继续之前,必须先理解基础。标准形式提供了一个结构优化的阶梯。
第一范式(1NF)
任何关系型数据库的基础是1NF。当一个表满足以下条件时,它就处于1NF:
- 所有列的值都是原子的(不可再分的)。
- 每一列只包含单一类型的数据。
- 行内没有重复的组或数组。
例如,将产品名称列表存储在单个列中违反了1NF。相反,每个产品应占据独立的一行。尽管现代系统通常能处理复杂数据类型,但严格遵守原子性可确保查询保持可预测性,索引策略也能按预期工作。
第二范式(2NF)
一旦一个表处于1NF,就必须满足2NF的要求。此形式专门适用于具有复合主键(由多个列组成的键)的表。当一个表满足以下条件时,它就处于2NF:
- 它已经处于1NF。
- 所有非键属性都必须完全依赖于整个主键,而不仅仅是其中一部分。
考虑一个订单明细表,其主键是订单ID和产品ID的组合。如果你在这个表中存储产品名称,就会产生部分依赖。产品名称仅依赖于产品ID,而不依赖于订单ID。为了解决这个问题,应将产品名称移到一个独立的“产品”表中。这可以减少更新异常;如果产品名称发生变化,只需在一个地方更新,而不是在成千上万的订单记录中分别修改。
第三范式(3NF)
3NF通常被认为是大多数操作性系统的最佳平衡点。当一个表满足以下条件时,它就处于3NF:
- 它处于第二范式。
- 不存在传递依赖。非主键属性必须仅依赖于主键。
当列A决定列B,且列B决定列C时,就会发生传递依赖。在数据库中,如果客户ID决定城市,而城市决定区域,将区域存储在客户表中就会产生传递依赖。如果该城市区域发生变化,就必须更新该城市中每个客户记录。通过规范化消除这种依赖,将区域数据移至单独位置,确保更新只需进行一次。
📉 严格规范化的性能代价
虽然第三范式减少了冗余,但最大化了表的数量。在规范化模式中,获取单个逻辑记录通常需要连接多个表。这一过程具有计算成本。
- 连接开销: 每次连接操作都需要数据库引擎匹配来自不同表的行。随着表越来越大,这种匹配过程会消耗CPU和内存。
- I/O操作: 分布在多个表中的数据需要更多的磁盘读取。如果数据未能高效缓存,读取延迟就会增加。
- 复杂性: 包含多个连接的复杂查询更难优化和维护。如果模式发生变化,它们也更容易出错。
对于写入负载较重的系统,规范化通常是正确的选择。它能防止数据重复,并确保对单一事实的更新能正确传播。然而,对于读取负载较重的系统,连接的开销可能成为瓶颈。
🚀 战略性反规范化:何时打破规则
反规范化是有意引入冗余以优化性能。这不是错误,而是在规范化成本超过其收益时做出的明确架构决策。
反规范化的触发条件
当出现以下情况时,应考虑放宽规范化规则:
- 读操作占主导地位: 如果你的应用程序是读取密集型的(例如,报告仪表板),减少连接可以显著降低延迟。
- 查询复杂度高: 如果用户需要从10个以上的表中获取数据才能查看单个页面,查询就会变慢且难以调试。
- 写入频率低: 如果数据很少被更新,冗余带来的不一致风险就会最小化。
- 存在硬件限制: 在磁盘I/O昂贵或受限的环境中,缓存冗余数据可以减少物理读取次数。
常见的反规范化策略
- 列扩展: 直接在表中存储派生值。例如,在订单表中添加“总价”列,该列由明细项计算得出,这样就不需要每次读取时都进行求和。
- 冗余外键: 在子表中添加父级ID,以避免在检索层级结构时进行连接操作。
- 汇总表: 在一个单独的表中预先计算聚合数据(计数、求和),该表通过定期更新或触发器进行维护。
- 物化视图: 将复杂查询的结果存储为一个物理表,并按计划刷新。
📊 对比:规范化 vs. 反规范化
为了直观展示权衡,可参考以下对比表格。
| 方面 | 高规范化(3NF+) | 反规范化设计 |
|---|---|---|
| 数据完整性 | 高 – 单一真实来源 | 较低 – 需要同步逻辑 |
| 存储使用 | 高效 – 无重复数据 | 低效 – 存在冗余数据 |
| 写入性能 | 快速 – 单行更新 | 较慢 – 多行更新 |
| 读取性能 | 较慢 – 需要连接操作 | 快速 – 直接访问 |
| 查询复杂度 | 高 – 需要大量连接 | 低 – 查询简单 |
| 维护成本 | 低 – 一次更新 | 高 – 需同步多个位置 |
该表格表明,并不存在通用的最佳实践。选择取决于应用程序的具体工作负载。
🛠️ 模式设计决策框架
为了确定您特定项目的规范化程度,可使用此决策框架。请根据项目需求评估每一项。
1. 分析工作负载模式
确定读取与写入的比例。如果您的系统是OLTP(在线事务处理),应优先考虑数据完整性和第三范式(3NF)。如果是OLAP(在线分析处理),则应优先考虑读取速度,并考虑反规范化。
2. 评估数据新鲜度需求
数据是否需要实时?如果进行反规范化,会在源数据更新与冗余数据中反映更改之间引入延迟。如果您的用户需要立即一致,严格规范化更安全。
3. 评估更新频率
查看主键。如果查找表(如国家列表)很少更改,将其数据反规范化到事务表中是安全的。如果查找表频繁更改,则应将其保持独立,以最小化同步错误。
4. 考虑硬件和缓存
现代数据库通常将数据缓存在内存中。如果您的工作集适合放在RAM中,连接操作的成本就会降低。在这种情况下,您可以承受稍微更规范化的模式,而不会牺牲性能。
🧠 高级规范化:BCNF与4NF
超过3NF之后,还有更高形式,如博伊斯-科德范式(BCNF)和第四范式(4NF)。它们用于处理特定的边缘情况。
博伊斯-科德范式(BCNF)
BCNF是3NF的更严格版本。它处理非主属性决定另一个非主属性的情况,即使主键是复合的也是如此。虽然理论上完美,但BCNF有时会导致依赖关系无法保留。实际上,3NF通常已足够,强制使用BCNF有时会使模式变得复杂,却未带来显著价值。
第四范式(4NF)
4NF处理多值依赖。当单行包含多个独立的值列表时就会发生这种情况。例如,学生表在同一行中存储多个兴趣爱好和多个课程。这在标准业务应用中很少见,但在特定的数据建模场景中很常见。
🚫 常见陷阱,应避免
即使对规范化有扎实的理解,也容易犯错。请避免以下常见错误:
- 过度规范化:为简单的关联创建数百个小型表。这会使应用程序逻辑难以理解,并减慢开发速度。
- 忽略索引:规范化模式需要连接操作。如果连接列未建立索引,无论模式设计如何,性能都会下降。
- 未监控地进行反规范化:在没有同步计划的情况下引入冗余,会导致数据随时间推移出现损坏。
- 硬编码逻辑:如果派生值应在数据库中计算,就不要在应用层进行计算。应将业务规则尽可能靠近数据。
✅ 模式验证清单
在部署新模式之前,请通过此验证清单进行检查。
- 原子性:所有字段都是原子的吗?
- 主键:每张表都有唯一的主键吗?
- 外键:关系是否通过外键强制执行?
- 冗余:是否存在明显重复的数据组?
- 连接数量:关键查询是否需要超过3-4次连接?
- 更新路径:是否可以在一个地方完成单个数据更改?
🔗 数据架构结论
规范化是一种工具,而不是一本规则手册。它存在的目的是保护您的数据免受不一致的影响,但不应阻碍应用程序的高效运行。关于ERD规范化的‘真相’是,它是一个光谱。您从高度规范化的结构开始以确保完整性,然后根据性能需求有选择地进行反规范化。
没有放之四海而皆准的解决方案。高频交易系统与内容管理系统看起来会非常不同。关键在于理解依赖关系和连接的底层机制。通过在存储成本与计算成本之间取得平衡,您可以构建既可靠又快速的系统。
在继续设计的过程中,请记住模式演进是不可避免的。为变化做好计划。为数据库迁移使用版本控制。在做出结构决策之前,始终在负载下测试您的查询。最好的模式是既能支持您的业务目标,又不会成为瓶颈的那个。