











设计一个健壮的数据库需要清晰的数据结构图。实体-关系图(ERD)就是这一蓝图,它可视化了数据在系统中的连接方式。理解核心组件——实体、属性和关系——对于构建可扩展的解决方案至关重要。本指南深入探讨这些元素,确保为数据库架构奠定坚实的基础。
🏗️ 什么是ERD?
ERD是数据库结构的视觉化表示。它概述了数据元素及其相互连接。可以将其视为建筑的建筑设计图,其中数据库是建筑结构,数据则是居住者。它弥合了抽象业务需求与具体技术实现之间的差距。
主要优势包括:
- 清晰性:利益相关者可以在不编写代码的情况下可视化数据流。
- 一致性:确保数据规则在整个系统中一致应用。
- 效率:通过早期发现设计缺陷,减少开发阶段的错误。
- 沟通:为开发人员、分析师和业务所有者提供一种通用语言。
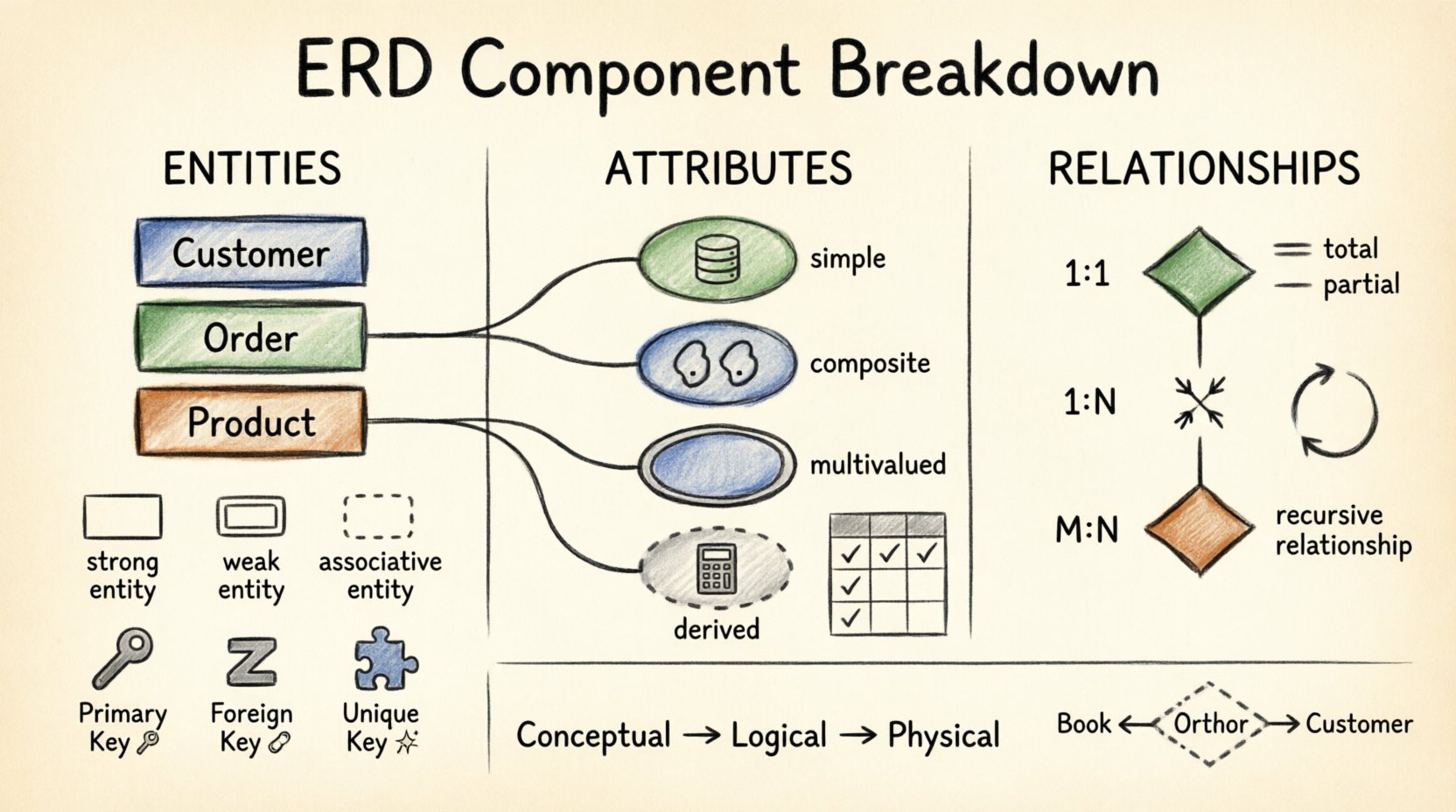
🔑 组件1:实体
实体代表需要存储在数据库中的现实世界对象或概念。它们是模型的基本构建块。每个实体都应该是独特且可识别的。
1.1 定义实体
实体通常是一个名词,例如客户, 订单,或产品。在图中,它们通常以矩形表示。每个实体代表一组相似的对象。
1.2 实体的类型
并非所有实体都以相同方式运作。区分它们有助于建模复杂场景。
- 强(常规)实体: 它们独立存在。它们拥有自己的主键,不依赖于其他实体而存在。
- 弱实体: 它们的身份依赖于一个强实体。没有父实体,它们无法存在。它们通常用双线矩形表示。
- 关联实体: 这些通过将多对多关系拆分为两个一对多关系来解决。它们充当一个桥接表,包含两个相关实体的外键。
1.3 实体识别
每个实体都必须有一个唯一标识符。如果没有这个标识符,区分两个记录就变得不可能。常见的策略包括:
- 使用系统生成的ID(例如,UUID)。
- 使用自然键(例如,社会保障号码、ISBN)。
- 使用复合键(多个属性的组合)。
📝 组件2:属性
属性是描述实体的属性或特征。如果一个实体是人,那么属性就是他们的姓名、年龄和地址。它们通常用连接到实体矩形的椭圆来表示。
2.1 属性分类
属性在复杂性和功能上各不相同。理解这些类别有助于规范化和查询优化。
- 简单属性:无法进一步划分的原子值。例如:年龄或颜色.
- 复合属性:可以进一步划分为其他属性。例如:地址可以拆分为街道, 城市,以及邮政编码.
- 多值属性:一个实体可以为该属性拥有多个值。例如:电话号码或教育学位这些通常用双椭圆表示。
- 派生属性:由其他属性计算得出。例如:年龄可由以下属性推导得出:出生日期这些通常不会物理存储以节省空间。
2.2 关键属性
某些属性在数据完整性中扮演特定角色。下表总结了关键类型:
| 键类型 | 功能 | 示例 |
|---|---|---|
| 主键 | 唯一标识表中的每条记录。 | 客户ID |
| 外键 | 通过主键将一个表链接到另一个表。 | 订单ID(在订单项中) |
| 唯一键 | 确保无重复值,但允许为空。 | 电子邮件地址 |
| 候选键 | 任何可能充当主键的属性。 | 身份证号,护照号码 |
2.3 空值与非空值
约束定义了属性是否必须包含数据。一个非空约束确保数据存在,这对主键至关重要。空值 值表示缺失或未知的数据,需要在应用逻辑中谨慎处理。
🔗 组件 3:关系
关系定义了实体之间如何相互作用。它们描述了连接数据点的业务逻辑。在ERD中,关系以连接实体矩形的菱形表示。
3.1 基数
基数指一个实体的实例与另一个实体的实例之间的关联数量。这是关系建模中最关键的方面。
- 一对一(1:1): 实体A的一个实例恰好与实体B的一个实例相关联。示例:人员 到 护照.
- 一对多(1:N): 实体A的一个实例与实体B的多个实例相关联。示例:部门 到 员工.
- 多对多(M:N): 实体A的多个实例与实体B的多个实例相关联。示例:学生 到 课程。这需要一个关联实体来解决。
3.2 参与约束
参与性决定了实体是否必须参与某个关系。它通常被称为存在依赖。
- 完全参与: 实体的每个实例都必须参与该关系。用双线表示。示例:每个订单 至少必须有一个 客户.
- 部分参与: 某些实例可能不参与。用单条线表示。例如:一个员工可能还没有配偶记录。
3.3 关系类型
除了基数之外,关系还可以根据其性质进行分类。
| 类型 | 描述 | 示例 |
|---|---|---|
| 标识性 | 弱实体依赖于强实体来确定其身份。 | 子实体依赖于父实体 |
| 非标识性 | 关系存在,但子实体拥有自己的身份。 | 经理管理员工 |
| 递归 | 一个实体与自身相关。 | 员工监督员工 |
📊 组件4:符号风格
虽然逻辑保持不变,但视觉表示方式有所不同。了解常见的风格有助于阅读不同团队创建的图表。
4.1 鸢尾符号表示法
这是使用最广泛的一种风格。它使用线条、圆圈和鸢尾符号(三条线)等符号来表示基数。
- 一条线:必选一个。
- 圆圈:可选(零个)。
- 鸢尾符号: 很多。
4.2 陈氏记法
以实体关系图的创建者彼得·陈命名。它用矩形表示实体,菱形表示关系,椭圆表示属性。这种记法更为抽象,常用于学术场合。
4.3 UML 类图
统一建模语言图使用类似的概念,但专为面向对象编程设计。它们包含可见性标识符(+、-、#)和方法列表。
🛠️ 组件 5:规范化与实体关系图
规范化是组织数据以减少冗余并提高完整性的过程。实体关系图是这一过程的可视化输出。
5.1 过程
- 第一范式(1NF): 确保值为原子性。不允许重复组。
- 第二范式(2NF): 消除部分依赖。所有非键属性必须依赖于整个主键。
- 第三范式(3NF): 消除传递依赖。非键属性不应依赖于其他非键属性。
5.2 对设计的影响
规范化通常会增加表的数量。虽然这提高了数据完整性,但可能使查询变得复杂。实体关系图有助于可视化这种权衡,显示在何处需要连接操作才能获取完整信息。
⚠️ 常见陷阱
即使经验丰富的设计师也会犯错。意识到常见错误可以防止未来的技术债务。
- 名称模糊: 使用诸如 数据 或 信息 这样的术语会使模型难以理解。应使用具体的名词,如 事务日志.
- 缺失基数: 忘记定义关系是可选还是必选,会导致数据完整性问题。
- 循环依赖: 实体 A 依赖于 B,而 B 又依赖于 A。这会形成一个数据库引擎无法解决的逻辑循环。
- 过度规范化: 创建过多的表会使查询变慢。应平衡规范化与性能需求。
- 忽视业务规则: 一个在结构上看起来完美的图表,如果未能反映实际的业务约束,仍可能失败。
🚀 最佳实践
遵循标准可确保可维护性和协作性。
6.1 命名规范
一致性是关键。所有名称都应使用标准格式。
- 复数与单数: 选择一种并坚持使用。(例如,Customer 与 Customers).
- 下划线: 使用 snake_case 作为数据库列名(例如,customer_id).
- 有意义的前缀: 标明表类型(例如,tbl_ 或 dim_).
6.2 文档化
ERD 不是一个独立的产物,它需要上下文。
- 包含一个数据字典,解释每个属性。
- 记录约束背后的业务规则。
- 对图表进行版本控制,以跟踪随时间的变化。
6.3 审查周期
在没有同行评审的情况下,绝不要最终确定设计。
- 技术评审: 检查规范化和键的完整性。
- 业务评审: 确保模型与现实世界的流程相匹配。
- 性能评审: 评估索引策略和连接复杂性。
🔍 实际示例
考虑一个在线书店。核心实体将是图书, 作者:,以及客户.
- 图书: 属性包括ISBN(主键)、书名和价格。
- 作者: 属性包括作者ID(主键)和姓名。
- 关系: 一本书可以有多个作者(多对多)。一位作者可以撰写多本书。
- 解决方案: 创建一个关联实体图书_作者 包含ISBN和作者ID。
这种结构允许灵活的数据输入,而无需为每本书重复输入作者信息。
📈 模型的演变
数据库设计很少是静态的。随着业务需求的变化,ERD必须随之演变。
- 概念模型: 面向利益相关者的高层次视图。关注实体和关系,而不涉及技术细节。
- 逻辑模型: 添加属性和键。精确地定义数据类型和关系。
- 物理模型: 针对特定数据库引擎进行优化。包含索引、分区和存储细节。
这些阶段之间的转换需要仔细验证,以确保在整个生命周期中数据完整性得到保持。
🧩 高级概念
对于复杂系统,标准的ERD可能需要扩展。
7.1 超类型和子类型
泛化和特化允许继承。一个车辆实体可以被特化为汽车和卡车。这减少了公共属性的冗余,同时允许子类型拥有独特的属性。
7.2 聚合
当一个关系本身需要被当作实体处理时。例如,一个会诊在医生和患者具有其自身的属性,如日期和诊断.
7.3 三元关系
涉及三个实体的关系。虽然可能实现,但在关系型数据库中通常难以实施。通常更倾向于将其分解为二元关系。
🔍 结论
掌握实体-关系图的各个组成部分是有效数据管理的基础。通过明确定义实体、属性和关系,团队可以构建出既稳健又灵活的系统。在设计阶段注重细节,将在开发和维护阶段带来回报。定期审查并遵循最佳实践,可确保数据库始终是组织的可靠资产。
随着数据量的增长,精确建模的需求也随之增加。投入时间理解这些核心概念,能够确保数据库架构的长期成功。