











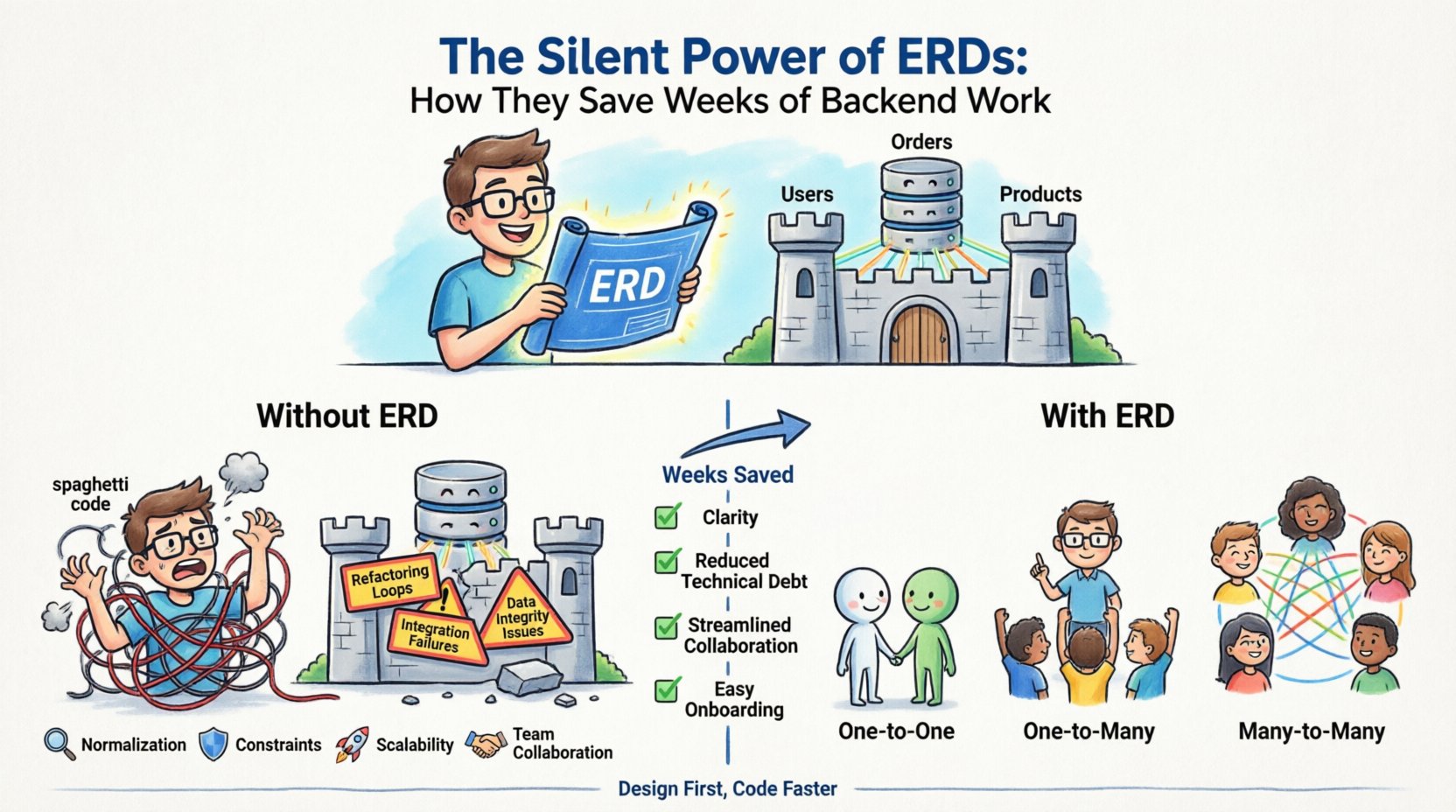
El desarrollo del backend a menudo se siente como construir una casa sin un plano. Comienzas poniendo ladrillos, agregando ventanas y estructurando paredes según la intuición. A veces funciona. A menudo no. Semanas después, te encuentras desmontando paredes para acomodar una puerta que olvidaste planificar. Esta es la realidad de programar sin una base sólidaDiagrama de Entidad-Relación (ERD). El ERD es el arquitecto silencioso de su infraestructura de datos, operando detrás de escena para prevenir fallas estructurales costosas. Cuando inviertes tiempo en diseñar tu modelo de datos antes de escribir una sola línea de código, obtienes claridad, reduces la deuda técnica y facilitas la colaboración entre equipos.
Esta guía explora el impacto tangible de los ERD en los flujos de trabajo del backend. Desglosaremos la mecánica de modelado de datos, los costos ocultos de omitir el diseño y las ventajas estratégicas de un esquema bien documentado. Al comprender estos principios, podrás pasar de una programación reactiva a una arquitectura proactiva.
¿Qué es exactamente un ERD? 📐
Un Diagrama de Entidad-Relación es una representación visual de la estructura lógica de una base de datos. Muestra cómo diferentes piezas de datos se relacionan entre sí. Piénsalo como un mapa para la memoria de tu aplicación. Sin este mapa, los desarrolladores navegan a ciegas, arriesgándose a colisiones entre puntos de datos que deberían permanecer separados.
En esencia, un ERD consta de tres componentes principales:
- Entidades: Estas representan los objetos o conceptos que estás rastreando. En una base de datos, estas se traducen en tablas. Ejemplos incluyenUsuarios, Pedidos, oProductos.
- Atributos: Estos son las propiedades específicas de una entidad. Se convierten en las columnas dentro de tus tablas. Para una entidad deUsuario entidad, los atributos podrían incluircorreo electrónico, hash_de_contraseña, ycreado_en.
- Relaciones: Estas definen cómo interactúan las entidades. Determinan la cardinalidad y conectividad entre tablas, como unUsuario que tiene muchosPedidos.
Aunque el concepto parece sencillo, la complejidad surge al gestionar el escalado. Un blog sencillo podría necesitar solo unas cuantas tablas. Un sistema empresarial requiere decenas, si no cientos, de entidades interconectadas. El diagrama ER actúa como la única fuente de verdad para todas estas interacciones.
El costo oculto de saltarse el diseño 💸
Muchos equipos de desarrollo se apresuran a codificar para cumplir plazos. Suponen que podrán refactorizar la base de datos después. Esta es una suposición peligrosa. Cambiar el esquema de una base de datos es significativamente más costoso que cambiar la lógica de la aplicación. Una vez que los datos se escriben, alterar su estructura requiere scripts de migración, posibles tiempos de inactividad y un manejo cuidadoso de los registros existentes.
Considere los siguientes escenarios en los que la ausencia de un diagrama ER genera fricción:
- Bucles de refactorización: Construyes una característica, te das cuenta de que la estructura de datos no la soporta y debes volver a escribir las consultas. Este ciclo se repite, consumiendo semanas del tiempo de sprint.
- Fallas de integración: Cuando los equipos de frontend y backend trabajan sin una definición de esquema compartida, las APIs a menudo fallan. El backend envía una estructura; el frontend espera otra.
- Problemas de integridad de datos: Sin restricciones definidas, los datos inválidos ingresan al sistema. Terminas limpiando registros huérfanos o arreglando estados inconsistentes manualmente.
- Retrasos en la incorporación: Los nuevos desarrolladores tienen dificultades para entender el sistema. Pasan días leyendo código en lugar de construir características porque el flujo de datos no está documentado.
Para cuando te das cuenta del problema, el costo se ha acumulado. La “solución” ahora requiere no solo cambios de código, sino también migración de datos, pruebas y verificación de despliegue.
Mapa de relaciones como un profesional 🔗
Comprender cómo se conectan los datos es el corazón del diseño de diagramas ER. Las relaciones determinan cómo se escriben las consultas y cómo se optimiza el rendimiento. Hay tres tipos principales de relaciones que debes definir claramente.
La tabla a continuación describe las diferencias entre estos tipos de relaciones:
| Tipo de relación | Definición | Escenario de ejemplo | Nota de implementación |
|---|---|---|---|
| Uno a uno (1:1) | Un único registro en la tabla A se relaciona con exactamente un registro en la tabla B. | Un perfil de usuario vinculado a una tabla de configuración de usuario. | A menudo implementado colocando la clave primaria de B en A. |
| Uno a muchos (1:N) | Un único registro en la tabla A se relaciona con múltiples registros en la tabla B. | Una categoría que contiene múltiples productos. | Colocación estándar de clave foránea en la tabla del lado “muchos”. |
| Muchos a muchos (M:N) | Varios registros en la tabla A se relacionan con varios registros en la tabla B. | Estudiantes inscritos en múltiples cursos. | Requiere una tabla de unión para resolver el enlace. |
Ignorar estas diferencias conduce a consultas ineficientes. Por ejemplo, almacenar una lista de identificadores de productos en una sola columna para una categoría viola los principios de normalización. Te obliga a analizar cadenas en lugar de usar uniones, lo que ralentiza el rendimiento a medida que crece los datos.
Normalización: Manteniendo los datos limpios 🧹
La normalización es el proceso de organizar los datos para reducir la redundancia y mejorar la integridad. Aunque los sistemas modernos a veces se desvían de la normalización estricta por rendimiento, comprender los principios sigue siendo esencial.
Las formas estándar de normalización incluyen:
- Primera Forma Normal (1FN):Garantiza atomicidad. Cada columna contiene solo un valor. No hay listas ni arreglos en una sola celda.
- Segunda Forma Normal (2FN):Se basa en la 1FN. Requiere que todos los atributos no clave dependan completamente de la clave principal. Sin dependencias parciales.
- Tercera Forma Normal (3FN):Se basa en la 2FN. Requiere que los atributos no clave dependan únicamente de la clave principal, y no de otros atributos no clave.
¿Por qué importa esto? Considera una Orden tabla. Si almacenas el Nombre del cliente en cada fila de orden, creas redundancia. Si el cliente cambia su nombre, debes actualizar miles de filas. Si omites una, tus datos se vuelven inconsistentes. Al mover el Nombre del cliente a una Clientes tabla y vincularlo mediante ID, aseguras una única fuente de verdad.
Sin embargo, la normalización no es una solución mágica. La sobre-normalización puede llevar a uniones complejas que afectan el rendimiento. El objetivo es el equilibrio. Debes comprender las compensaciones entre la eficiencia de almacenamiento y la velocidad de consulta.
Errores comunes en el diseño de esquemas 🚧
Incluso desarrolladores experimentados cometen errores al diseñar diagramas ER. Reconocer estas trampas comunes puede ahorrarte muchos problemas más adelante.
- Dependencias circulares: La entidad A necesita a la entidad B, y la entidad B necesita a la entidad A. Esto crea un bloqueo en la inicialización y dificulta la escritura de scripts de migración.
- Falta de restricciones:No definir claves foráneas, restricciones únicas o restricciones de verificación permite que datos inválidos pasen desapercibidos. La base de datos debe imponer reglas, no el código de la aplicación.
- Valores codificados:Almacenar códigos de estado como “activo” o “inactivo” como enteros sin una tabla de búsqueda hace que el sistema sea frágil. Si necesitas agregar “suspendido”, debes cambiar la lógica en todas partes.
- Ignorar eliminaciones suaves:Eliminar datos permanentemente elimina el historial. Diseñar para eliminaciones suaves (marcar un registro como eliminado en lugar de eliminarlo) preserva los registros de auditoría.
- Sobrediseño:Diseñar para un caso de uso que aún no existe. Construye para los requisitos actuales, pero asegúrate de que el esquema sea lo suficientemente flexible para manejar un crecimiento razonable.
Cada uno de estos errores añade capas de complejidad a tu base de código. Un ERD te ayuda a visualizar estos problemas antes de que se incrusten en producción.
Desde el diagrama hasta la implementación 🚀
Una vez que el ERD está finalizado, el siguiente paso es traducirlo en código. Este proceso, a menudo llamado migración de esquema, requiere disciplina.
Sigue estos pasos para asegurar una transición fluida:
- Control de versiones:Trata tu esquema de base de datos como código de aplicación. Cada cambio debe ser un archivo de migración almacenado en tu repositorio.
- Compatibilidad hacia atrás:Al agregar una columna, hazla nula primero. Rellena los datos existentes, luego aplica la restricción en una migración posterior. Esto evita tiempos de inactividad.
- Pruebas de migraciones:Ejecuta los scripts de migración en un entorno de pruebas idéntico al de producción. Verifica si hay regresiones de rendimiento.
- Plan de reversión:Siempre debes tener una forma de deshacer una migración si falla. La pérdida de datos es inaceptable.
Las herramientas de automatización pueden ayudar a generar SQL a partir de ERDs, pero la revisión manual es crucial. Los generadores automáticos a menudo omiten matices de lógica de negocio que un arquitecto humano detectaría.
Colaboración y comunicación 🤝
Un ERD no es solo para administradores de bases de datos. Sirve como herramienta de comunicación para todo el equipo. Los gerentes de producto, desarrolladores frontend y ingenieros de QA se benefician todos de entender la estructura de datos.
Cuando los interesados revisan el ERD, pueden identificar problemas potenciales temprano:
- Viabilidad de la funcionalidad:¿Puede la base de datos soportar la funcionalidad solicitada? Si no, ¿qué cambios son necesarios?
- Expectativas de rendimiento:¿Permite el diseño consultas eficientes a escala?
- Requisitos de seguridad:¿Se identifican y protegen los campos sensibles? ¿Es factible el control de acceso a nivel de datos?
Esta comprensión compartida reduce la fricción durante la planificación de sprints. En lugar de adivinar cómo fluye la información, el equipo discute sobre la base de un modelo visual. Los desacuerdos se resuelven con referencia al diagrama, no a la opinión.
Consideraciones de escalabilidad 📈
A medida que su aplicación crece, su modelo de datos debe evolucionar. Un diagrama ER le ayuda a anticipar estos cambios. Le permite visualizar cómo agregar una nueva entidad afecta las relaciones existentes.
Factores clave de escalabilidad a considerar durante el diseño:
- Estrategia de indexación:Identifique qué columnas se consultarán con frecuencia. Planee índices en estos campos para acelerar la recuperación.
- Particionamiento:¿Algunas tablas crecerán demasiado? Planee el particionamiento horizontal si es necesario.
- División de lectura/escritura:¿El diseño admite réplicas separadas para lectura y escritura? Asegúrese de que las claves foráneas no complejen la replicación.
- Capas de caché:¿Cómo interactúa el modelo de datos con los sistemas de caché? Los datos inmutables son más fáciles de cachear que los datos que cambian con frecuencia.
Pensar en la escalabilidad desde temprano evita la necesidad de una reescritura completa más adelante. Es más fácil agregar una nueva tabla que mover datos de un servidor a otro.
Reflexiones finales sobre la arquitectura de datos 🧠
El esfuerzo invertido en crear un diagrama ER detallado rinde dividendos a lo largo de todo el ciclo de vida del proyecto. Transforma el modelado de datos de una tarea reactiva en un activo estratégico. Al visualizar relaciones, aplicar restricciones y planificar el crecimiento, construye sistemas robustos y mantenibles.
No trate la base de datos como una consideración posterior. Es la base de su aplicación. Invierta en la fase de diseño, y ahorrará semanas de trabajo en el backend a largo plazo. El poder silencioso del diagrama ER reside en su capacidad para prevenir problemas antes de que ocurran.
Comience a mapear sus datos hoy. La claridad que obtenga será la diferencia entre una base de código caótica y un sistema optimizado.