











El modelado de datos a menudo se considera un ejercicio estático para definir relaciones y entidades. Sin embargo, un Diagrama de Relaciones de Entidades (ERD) no es meramente un plano para el almacenamiento; es un determinante directo de la eficiencia con la que un motor de base de datos recupera y manipula información. Cada línea trazada, cada relación definida y cada tipo de dato seleccionado repercute en el plan de ejecución de tus consultas. Comprender los mecanismos detrás del diseño de esquemas permite crear sistemas que escalan de forma adecuada bajo carga.
Esta guía explora la relación técnica entre las estructuras de ERD y el rendimiento de las consultas. Avanzaremos más allá de las definiciones básicas para examinar cómo decisiones específicas de modelado influyen en las operaciones de E/S, el uso de CPU y los mecanismos de bloqueo dentro de un entorno relacional.
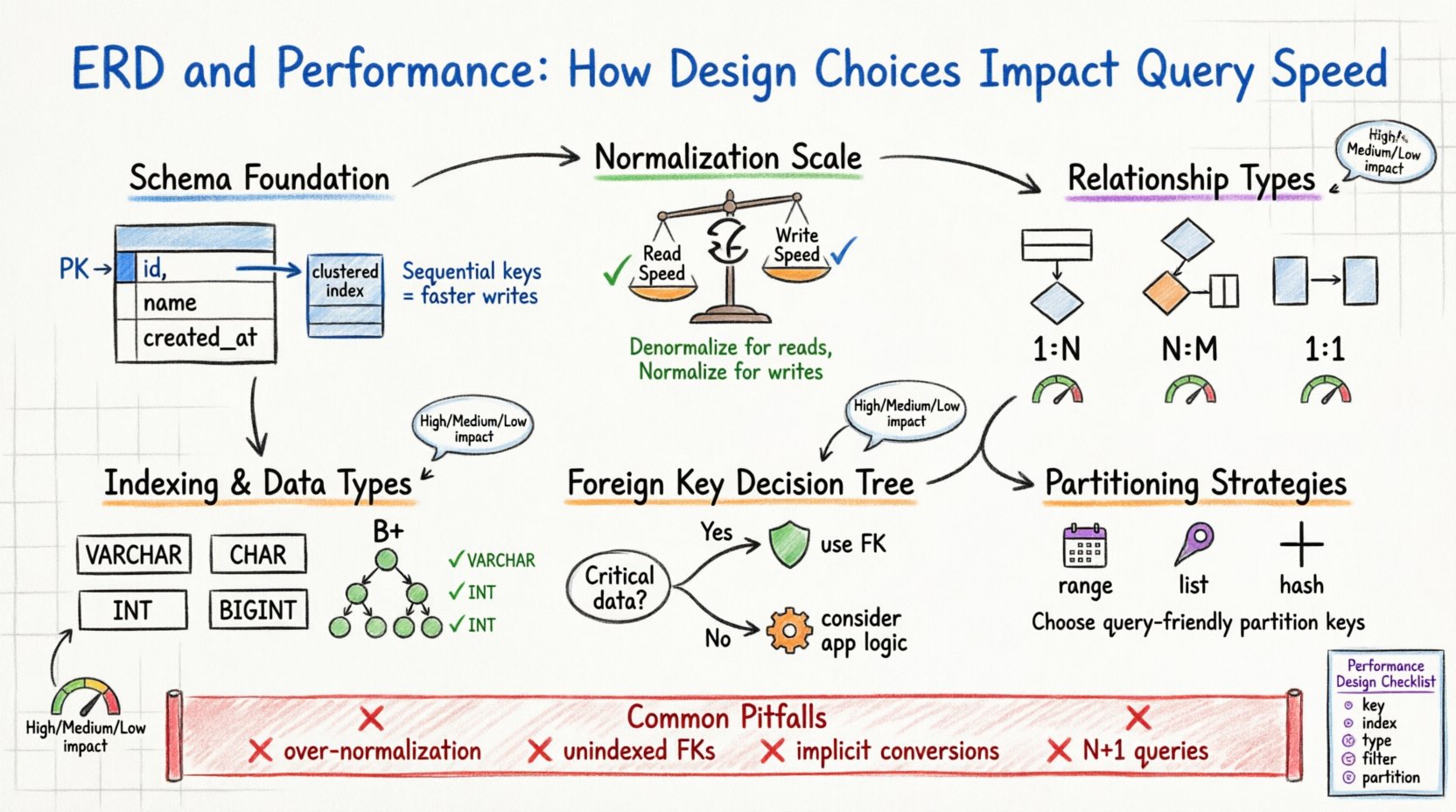
1. La base: estructura del esquema y almacenamiento físico 🏗️
El diseño lógico que creas en tu ERD finalmente se traduce en archivos físicos en un disco. El motor de base de datos debe mapear estas entidades lógicas a páginas, bloques y filas. Cuando el esquema está optimizado, el motor minimiza el número de lecturas de disco necesarias para satisfacer una solicitud. Cuando no lo está, el motor puede verse obligado a realizar escaneos completos de tablas, operaciones costosas.
Considera la clave primaria. Sirve como identificador único para una fila. En muchos motores de almacenamiento, la clave primaria define el orden físico de los datos en el disco (índice agrupado). Elegir una clave primaria secuencial y corta garantiza que los datos se almacenen de forma contigua. Esto reduce la fragmentación y permite escaneos de rango más rápidos. Por el contrario, una clave primaria aleatoria y larga puede provocar divisiones de páginas durante las inserciones, deteriorando el rendimiento de escritura y aumentando la sobrecarga de almacenamiento.
Consideraciones clave para las claves primarias
- Secuencialidad:Los enteros autoincrementales suelen preferirse en cargas de trabajo intensivas de escritura.
- Tamaño:Las claves más pequeñas reducen el tamaño de los índices secundarios, ya que se almacenan como punteros en esos índices.
- Estabilidad:Las claves primarias no deben cambiar. Actualizar una clave primaria suele requerir actualizar todas las claves foráneas asociadas.
2. Normalización frente a compromisos de rendimiento ⚖️
La normalización es el proceso de organizar los datos para reducir la redundancia y mejorar la integridad. Aunque tradicionalmente se asocia con la calidad de los datos, tiene efectos profundos en el rendimiento. Un esquema altamente normalizado (por ejemplo, Forma Normal Tercera) requiere a menudo más combinaciones para reconstruir los datos, mientras que un esquema denormalizado reduce las combinaciones pero aumenta el almacenamiento y la complejidad de actualización.
La decisión de normalizar o denormalizar es un equilibrio entre la velocidad de lectura y la velocidad de escritura. En un entorno con carga intensiva de lectura, la denormalización puede reducir significativamente el tiempo de consulta al evitar combinaciones complejas. En un entorno con carga intensiva de escritura, la normalización reduce el número de filas que deben actualizarse en múltiples tablas.
Análisis de impacto de la normalización
| Aspecto | Altamente normalizado | Denormalizado |
|---|---|---|
| Rendimiento de lectura | Más bajo (requiere combinaciones) | Más alto (acceso a una sola tabla) |
| Rendimiento de escritura | Más alto (menos redundancia) | Más bajo (actualización de múltiples copias) |
| Integridad de los datos | Alta (fuente única de verdad) | Más baja (riesgo de inconsistencia) |
| Uso de almacenamiento | Inferior | Superior |
3. Claves foráneas y sobrecarga de integridad 🔗
Las claves foráneas garantizan la integridad referencial. Aseguran que un valor en una tabla coincida con un valor en otra. Aunque esto evita registros huérfanos, introduce una sobrecarga en tiempo de ejecución. Cuando insertas, actualizas o eliminas una fila, la base de datos debe verificar la restricción de clave foránea.
Esta verificación no es gratuita. El motor debe localizar la fila referenciada y verificar su existencia. Si la tabla referenciada es grande y carece de un índice en la columna de clave foránea, la verificación se convierte en una escaneo completo de la tabla. Además, eliminar un registro padre requiere que el motor verifique todos los registros secundarios para asegurarse de que no queden referencias, lo que podría bloquear muchas filas.
Cuándo usar claves foráneas
- Integridad crítica de los datos: Si la corrección de los datos es fundamental (por ejemplo, transacciones financieras), usa claves foráneas.
- Lógica de la aplicación: Si la lógica de la aplicación es compleja, transferir la integridad a la base de datos simplifica el código.
- Conjuntos de datos pequeños: La sobrecarga es despreciable en tablas pequeñas.
Cuándo evitar claves foráneas
- Alto rendimiento de escritura: Eliminar las restricciones puede reducir la contención de bloqueos.
- Análisis a gran escala: En el almacenamiento de datos, el rendimiento a menudo supera la integridad estricta.
- Capas arquitectónicas: En microservicios, mantener claves foráneas a través de los límites de los servicios suele ser impráctico.
4. Estrategias de indexación y tipos de columnas 📑
Un diagrama ER define los tipos de datos para cada columna. La elección entre VARCHAR y CHAR, o entre INT y BIGINT, afecta cómo se almacenan y indexan los datos. Los tipos de datos más pequeños consumen menos memoria y espacio en disco, permitiendo que más datos quepan en el grupo de búferes (RAM).
Cuando una consulta filtra una columna, el motor de la base de datos depende de los índices para encontrar filas rápidamente. Si el diseño del esquema no coincide con los patrones de consulta, los índices se vuelven inútiles. Por ejemplo, crear un índice en una columna que rara vez se utiliza en cláusulas WHERE es un desperdicio de recursos.
Optimización de tipos de columna
- Longitud fija frente a longitud variable: Usa CHAR para datos de longitud fija (por ejemplo, códigos de país) para reducir la fragmentación. Usa VARCHAR para datos de longitud variable.
- Rangos enteros: No uses BIGINT si INT es suficiente. Los enteros más pequeños permiten más filas por página.
- Representación booleana: Usa tipos TINYINT(1) o BOOLEAN en lugar de almacenar cadenas ‘Sí’/’No’.
5. Implicaciones de la cardinalidad de las relaciones 📊
La cardinalidad de las relaciones (uno a uno, uno a muchos, muchos a muchos) determina cómo se enlazan los datos. Cada tipo de relación tiene características de rendimiento diferentes.
Uno a muchos (1:N)
Esta es la relación más común. Una tabla padre almacena un registro, y la tabla hija almacena muchos. El rendimiento depende en gran medida del índice en la columna de clave foránea de la tabla hija. Sin este índice, encontrar todos los hijos de un padre requiere escanear toda la tabla hija.
Muchos a muchos (N:M)
Esto requiere una tabla de unión (entidad asociativa). Esto añade una capa adicional de indirección. Las consultas que involucran relaciones N:M generalmente requieren tres uniones: Tabla A, Tabla de unión, Tabla B. Esta complejidad aumenta el uso de CPU y los requisitos de memoria.
Uno a uno (1:1)
A menudo se utiliza para dividir una tabla grande en grupos lógicos. Esto puede mejorar el rendimiento si solo se consulta con frecuencia un subconjunto de columnas. Sin embargo, añade el costo de una unión para recuperar el registro completo.
6. Consideraciones sobre particionado y fragmentación 🗃️
A medida que los datos crecen, una sola tabla puede volverse demasiado grande para gestionarse de forma eficiente. El particionado permite dividir una tabla grande en piezas más pequeñas y manejables basadas en una clave (por ejemplo, fecha). El diseño del ERD debe anticipar esto.
Si diseñas un esquema para un sistema que eventualmente será fragmentado (dividido entre múltiples servidores), la clave de partición debe elegirse con cuidado. La clave debe usarse con frecuencia en las consultas para permitir que el motor enrute las solicitudes al fragmento correcto. Elegir una clave que no se use en consultas obliga al sistema a agrupar datos de todos los fragmentos, lo cual es lento.
Estrategias de particionado
- Particionado por rango: Dividir por rangos de fecha o ID. Ideal para datos de series temporales.
- Particionado por lista: Dividir por valores específicos (por ejemplo, códigos de región).
- Particionado por hash: Distribuye los datos de forma uniforme para evitar puntos calientes.
7. Errores comunes en el diseño 🚫
Incluso arquitectos experimentados pueden introducir cuellos de botella de rendimiento mediante decisiones de diseño. Reconocer estos patrones temprano evita una reingeniería costosa más adelante.
- Sobrenormalización:Dividir los datos en demasiadas tablas pequeñas aumenta la complejidad de las uniones y reduce la eficiencia de la caché.
- Ignorar la selectividad:Indexar columnas con baja selectividad (por ejemplo, género o marcas de estado) suele dar un mal rendimiento porque el optimizador podría ignorar el índice y escanear la tabla de todos modos.
- Conversiones implícitas:Diseñar una columna como cadena cuando se esperan valores numéricos obliga al motor a convertir tipos durante las consultas, impidiendo el uso del índice.
- Patrones de consultas N+1:Diseñar relaciones que fomenten la recuperación de datos en bucles en lugar de uniones por lotes puede sobrecargar el servidor.
8. Preparación para el futuro y evolución 🛡️
Las bases de datos evolucionan. Los requisitos cambian y se añaden nuevas funcionalidades. Un esquema que es eficiente hoy podría convertirse en un cuello de botella mañana si carece de flexibilidad. El ERD debe permitir el crecimiento sin requerir una reescritura completa.
Considera añadir columnas que probablemente se usen para filtrar en el futuro. Aunque esto aumenta ligeramente el tamaño de fila, ahorra el costo de modificar la estructura de la tabla más adelante, lo cual puede ser una operación costosa en conjuntos de datos grandes. Asimismo, considera el impacto de añadir nuevos índices. Cada índice consume recursos de escritura. Diseña el esquema para minimizar el número de índices necesarios.
Lista de verificación de diseño para el rendimiento
- ¿Son las claves primarias cortas y secuenciales?
- ¿Las claves foráneas están indexadas?
- ¿Los tipos de datos son el tipo válido más pequeño posible?
- ¿Los filtros frecuentes están cubiertos por índices?
- ¿El nivel de normalización es adecuado para la carga de trabajo?
- ¿Has considerado la partición para tablas grandes?
- ¿Hay alguna columna que almacene JSON complejo o texto que podría estructurarse?
9. El papel del plan de ejecución 📋
En última instancia, el motor de base de datos decide cómo ejecutar una consulta basándose en el esquema y las estadísticas. El diagrama ER influye en las estadísticas que el motor recopila. Por ejemplo, una columna con una distribución de valores distintos se manejará de forma diferente que una con datos sesgados. Comprender cómo funciona el plan de ejecución te ayuda a interpretar por qué una consulta es lenta.
Si una consulta realiza una escaneo completo de la tabla, a menudo indica la falta de un índice o un diseño que no apoya un filtrado eficiente. Si realiza muchos bucles anidados, sugiere joins complejos que podrían simplificarse. Al alinear el diagrama ER con los patrones de acceso esperados, guías al motor hacia planes de ejecución óptimos.
10. Equilibrando integridad y velocidad ⚖️
No existe un esquema perfecto. Cada elección de diseño implica una compensación. El objetivo no es eliminar los problemas de rendimiento, sino gestionarlos de forma estratégica. En algunos casos, aceptar un pequeño riesgo de inconsistencia de datos (mediante comprobaciones a nivel de aplicación en lugar de restricciones de base de datos) es una compensación válida para un rendimiento extremo en escritura.
Revisa periódicamente tu diagrama ER frente a los registros de consultas reales. Identifica las consultas más lentas y rastrea su origen hasta el esquema. Este bucle de retroalimentación asegura que tu diseño evolucione en sincronía con las necesidades de tu aplicación.
Resumen de las áreas de impacto 📝
| Elemento de diseño | Impacto en el rendimiento | Recomendación |
|---|---|---|
| Tipo de clave primaria | Alto (almacenamiento e indexación) | Utiliza enteros o UUIDs de forma consistente. |
| Claves foráneas | Medio (sobrecarga de escritura) | Indexa las columnas de claves foráneas; elimínalas si la integridad se maneja en otro lugar. |
| Normalización | Alto (complejidad de joins) | Denormaliza las tablas con alta carga de lectura. |
| Tipos de datos | Medio (uso de memoria) | Utiliza el tipo más específico disponible. |
| Cardinalidad | Alto (Costo de unión) | Optimiza las tablas de unión para relaciones N:M. |
Al tratar el Diagrama de Relaciones de Entidades como un artefacto de rendimiento, y no solo como un mapa lógico, puedes construir sistemas que sean robustos, escalables y eficientes. Las decisiones que tomes ahora determinarán el comportamiento de tu aplicación durante muchos años.