


El diseño de bases de datos es la columna vertebral de cualquier aplicación de software robusta. Sin embargo, incluso los ingenieros con experiencia a menudo tropiezan al explicar la diferencia entre los planos visuales y la implementación física. La confusión generalmente radica entre el Diagrama Entidad-Relación (ERD) y el Esquema de Base de Datos. Aunque estos términos se usan frecuentemente de forma intercambiable en conversaciones informales, representan capas distintas del proceso de arquitectura de datos. Comprender la sutileza entre ellos no es meramente académica; determina cómo fluye la información, cómo se aplican las restricciones y cómo evoluciona el sistema con el tiempo.
En esta guía, analizaremos los constructos teóricos de modelado de datos frente a las realidades prácticas de los sistemas de gestión de bases de datos. Exploraremos cómo los conceptos abstractos se transforman en estructuras concretas, las implicaciones de esta transformación y por qué mantener una separación mental clara entre ambos es vital para la mantenibilidad a largo plazo. Ya sea que estés diseñando un nuevo sistema o refactorizando uno existente, la claridad aquí evita deudas técnicas costosas.
¿Qué es exactamente un ERD? 📐
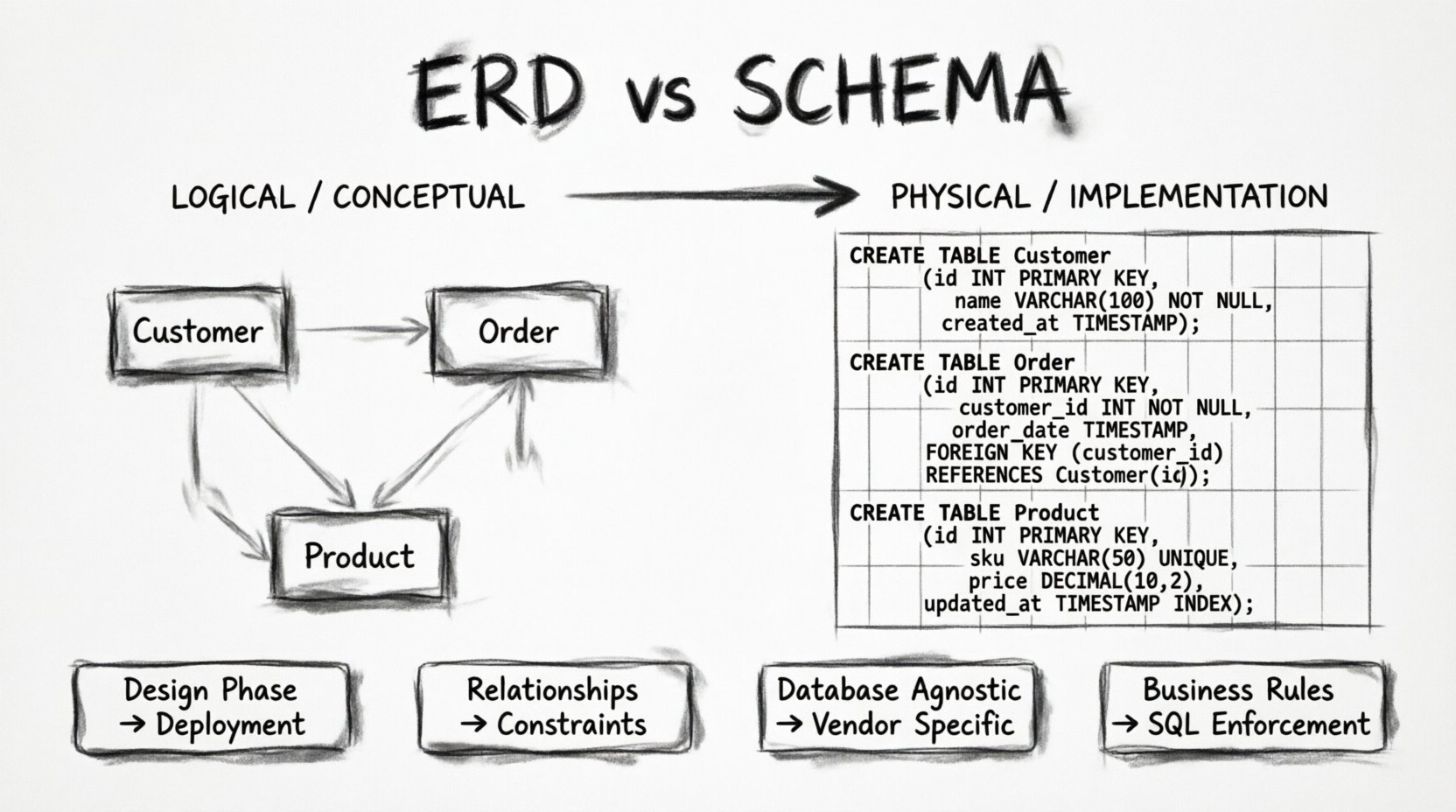
El Diagrama Entidad-Relación es una representación conceptual o lógica de los datos. Sirve como puente de comunicación entre los interesados del negocio, analistas y desarrolladores. Su propósito principal es visualizar cómo los elementos de datos se relacionan entre sí sin detenerse en los detalles específicos de un motor de base de datos determinado.
En esencia, un ERD se centra en tres componentes fundamentales:
- Entidades: Estas representan objetos o conceptos del mundo real. En un sistema de comercio minorista, una entidad podría serCliente, Producto, oPedido. Las entidades son los sustantivos de tu universo de datos.
- Atributos: Estos son las propiedades o características que describen una entidad. Para unCliente, los atributos podrían incluirNombre, Dirección de correo electrónico, oFecha de registro. Los atributos definen qué datos necesitamos almacenar sobre la entidad.
- Relaciones: Esto define cómo interactúan las entidades. ¿Un cliente realiza muchos pedidos? ¿Un producto pertenece a múltiples categorías? Las relaciones son los verbos que conectan los sustantivos.
La belleza de un ERD reside en su abstracción. No le importa si los datos finalmente vivirán en PostgreSQL, MySQL o una tienda de documentos NoSQL. Le importa la integridad de la información y el flujo lógico. Los estilos de notación varían, siendo la notación de Pico de Cuervo un estándar común para representar la cardinalidad (uno a uno, uno a muchos, muchos a muchos). Este lenguaje visual permite a los equipos validar la lógica del modelo de datos antes de escribir una sola línea de código.
Al crear un ERD, el enfoque está en la normalización. Esto implica organizar los datos para reducir la redundancia y mejorar la integridad de los datos. Analizamos cómo dividir tablas grandes en otras más pequeñas y relacionadas para asegurar que al actualizar una pieza de información en un lugar, esta se actualice en todos los sitios donde es relevante. El ERD es el mapa del territorio; muestra las carreteras y los puntos de referencia, pero no el material específico del pavimento.
Definir el Esquema de la Base de Datos 🏗️
Si el ERD es el mapa, el esquema es el territorio en sí. El esquema de la base de datos es la estructura física de la base de datos. Es el conjunto concreto de definiciones que indica al sistema de gestión de bases de datos (DBMS) exactamente cómo almacenar los datos. Mientras que el ERD habla en conceptos, el esquema habla en tipos de datos, restricciones y motores de almacenamiento.
Un esquema define los siguientes detalles técnicos:
- Tablas:La entidad del ERD se convierte en una tabla física. El esquema especifica el nombre de la tabla, que a menudo debe seguir convenciones de nomenclatura estrictas (por ejemplo, snake_case).
- Tipos de datos:Un atributo como Edad se convierte en un
INToSMALLINT. Un Correo electrónico se convierte en unVARCHARcon un límite de longitud específico. Un Marca de tiempo se convierte enTIMESTAMP CON ZONA HORARIA. Estas elecciones afectan el espacio de almacenamiento y el rendimiento de las consultas. - Restricciones: Aquí es donde se aplica la lógica del ERD. Las claves primarias (PK) garantizan la unicidad. Las claves foráneas (FK) garantizan la integridad referencial entre tablas.
NO NULOLas restricciones aseguran que los campos obligatorios estén completos. Las restricciones únicas evitan entradas duplicadas. - Índices: Aunque a menudo se omiten en los ERD de alto nivel, el esquema determina dónde se crean los índices. Los índices aceleran las operaciones de lectura pero ralentizan las escrituras. El esquema dicta la optimización física de la base de datos.
El esquema también es responsable de la seguridad y el control de acceso. Define quién puede leer o escribir en tablas específicas. Gestiona las transacciones, asegurando que los cambios de datos sean atómicos. Cuando un desarrollador escribe una sentencia CREATE TABLE la declaración, están definiendo el esquema. Esta es la capa de implementación con la que el código de la aplicación interactúa directamente.
Diferencias clave a simple vista 📊
Para aclarar la diferencia, ayuda ver las diferencias lado a lado. El ERD es abstracto y orientado al diseño, mientras que el esquema es concreto y orientado a la implementación.
| Característica | MDD (Diagrama de Entidad-Relación) | Esquema de Base de Datos |
|---|---|---|
| Naturaleza | Modelo Lógico / Conceptual | Modelo Físico |
| Enfoque | Relaciones y Flujo de Datos | Almacenamiento y Aplicación |
| Notación | Cajas, Líneas, Símbolos de Pico de Cuervo | Sentencias SQL, Scripts DDL |
| Dependencia | Independiente de Base de Datos | Específico de Base de Datos (Proveedor) |
| Restricciones | Implícitas (Reglas de Negocio) | Explícitas (PK, FK, Check) |
| Etapa | Fase de Diseño | Fase de Desarrollo / Implementación |
Esta tabla destaca que, aunque están relacionadas, operan en etapas diferentes del ciclo de vida del software. Confundir ambas a menudo lleva a los desarrolladores a intentar imponer restricciones físicas sobre un modelo lógico antes de que este esté completamente validado.
El Proceso de Traducción: Del Diagrama al Código 🔄
El camino desde el MDD hasta el esquema no siempre es una correspondencia directa 1:1. Esta capa de traducción es donde muchos proyectos encuentran fricción. El modelo lógico asume condiciones ideales, pero el modelo físico debe enfrentarse al rendimiento, los sistemas heredados y las capacidades específicas del motor.
Normalización frente al Rendimiento
Un MDD generalmente se normaliza hasta la Tercera Forma Normal (3FN). Esto minimiza la duplicación de datos. Sin embargo, al traducirlo a un esquema para una aplicación de alto tráfico, los desarrolladores a menudo desnormalizan. Esto significa duplicar intencionalmente datos para reducir el número de uniones necesarias durante una consulta. Por ejemplo, almacenar el Nombre del Cliente directamente en la tabla de Pedido tabla, incluso si viola las reglas estrictas de normalización, puede acelerar significativamente las consultas de informes. El MDD podría mostrar una relación, pero el esquema podría almacenar los datos de forma redundante para ganar velocidad.
Especificaciones de tipo de datos
Un ERD simplemente indica que un campo es un Fecha. El esquema debe decidir entre FECHA, FECHA_HORA, o HORA_DE_REGISTRO. Debe decidir sobre conjuntos de caracteres (UTF8, ASCII) y reglas de comparación. Estas decisiones afectan cómo la aplicación maneja la internacionalización y el ordenamiento. Un ERD genérico no puede capturar estas sutilezas.
Manejo de relaciones muchos a muchos
En un ERD, una relación muchos a muchos se representa como una línea con dos pies de cuervo. En el esquema físico, esto no puede existir directamente. Debe resolverse en dos relaciones uno a muchos mediante una tabla de unión (o tabla puente). El esquema debe definir la clave primaria de esta tabla de unión, que podría ser una clave compuesta o una clave artificial (UUID). Este cambio estructural es invisible en el diagrama de alto nivel, pero es crítico en la estructura de la base de datos.
Por qué la distinción importa para los desarrolladores 🛠️
Comprender la brecha entre estos dos conceptos no se trata solo de teoría; afecta el trabajo diario. Cuando surge un error en la integridad de los datos, saber si el problema radica en el diseño lógico o en la implementación física es el primer paso para resolverlo.
Depuración de la integridad de los datos
Si se presenta una situación en la que los datos se duplican inesperadamente, debes preguntarte: ¿el ERD está defectuoso, o falta una restricción en el esquema? La ausencia de una clave foránea en el esquema permite registros huérfanos que la lógica del ERD asumía imposibles. Por el contrario, si el ERD es demasiado rígido y no considera las eliminaciones suaves, el esquema podría imponer eliminaciones permanentes que rompen la lógica del negocio. Separar estas preocupaciones permite identificar con precisión la fuente del error.
Control de versiones y colaboración
Al gestionar una base de datos, el control de versiones es esencial. Sin embargo, los ERD y los esquemas evolucionan de manera diferente. El ERD cambia cuando cambian los requisitos del negocio. El esquema cambia cuando se necesita optimizar la base de datos o cuando se aplican migraciones. Mantenerlos sincronizados es un desafío. Si el esquema cambia sin actualizar el ERD, la documentación se vuelve obsoleta. Si el ERD cambia sin un script de migración, la base de datos permanece inconsistente con el diseño.
Integración de nuevos miembros del equipo
Los nuevos desarrolladores a menudo tienen dificultades para entender la estructura de la base de datos. Mostrarles un ERD les proporciona el contexto de cómo funciona el sistema desde un punto de vista conceptual. Mostrarles el esquema les proporciona el contexto de cómo funciona el sistema desde un punto de vista técnico. Una integración efectiva requiere ambos. El ERD responde “¿Qué significa esto?” y el esquema responde “¿Cómo accedo a él?”.
Errores comunes en el modelado de datos 🚧
A pesar de las definiciones claras, muchas equipos caen en trampas al tratar el ERD y el esquema como idénticos.
- Saltarse el ERD:Saltarse directamente a escribir scripts de esquema SQL a menudo conduce a una deuda estructural. Sin un modelo visual, las relaciones a menudo se olvidan o se implementan de forma inconsistente.
- Ignorar las restricciones:Confiar únicamente en el código de la aplicación para imponer reglas (como correos electrónicos únicos) en lugar de restricciones de la base de datos (índices UNIQUE) es arriesgado. El esquema debe ser la última línea de defensa para la integridad de los datos.
- Sobrediseño: Crear un diagrama ERD demasiado detallado con todos los atributos posibles antes de que los requisitos estén claros. Esto conduce a un esquema que es difícil de migrar más adelante.
- Desconexión de herramientas: Usar una herramienta de diseño que no admita generación de código, o usar una herramienta de base de datos que no admita ingeniería inversa. Esto crea una brecha manual donde los cambios se realizan en un lugar pero no en el otro.
- Asumiendo equivalencia: Creer que un diagrama ERD perfecto garantiza una base de datos perfecta. El esquema está sujeto a limitaciones de hardware, patrones de consulta y problemas de concurrencia que el diagrama ERD no puede prever.
Mantener la sincronización con el tiempo 🔄
A medida que una aplicación crece, la base de datos evoluciona. Se agregan funciones y se eliminan funciones antiguas. Mantener el vínculo entre el diagrama ERD y el esquema se vuelve más difícil con el tiempo. A menudo se denominadesviación de esquema.
Para combatir esto, los equipos deben adoptar un flujo de trabajo estricto:
- Diseño primero: Actualizar siempre el diagrama ERD antes de escribir los scripts de migración.
- Automatizar la generación: Usar herramientas que puedan generar DDL de SQL a partir del diagrama ERD. Esto garantiza que el esquema coincida con el diseño.
- Ingeniería inversa: Ejecutar periódicamente herramientas de ingeniería inversa en la base de datos en vivo para actualizar el diagrama ERD. Esto detecta cambios realizados mediante consultas SQL directas que evitan el proceso de diseño.
- Documentación: Asegurarse de que el diagrama ERD se almacene en el mismo repositorio que los scripts de migración de esquema. Esto crea una única fuente de verdad.
Esta disciplina evita que la base de datos se convierta en una caja negra. Cuando el diagrama ERD y el esquema están sincronizados, el sistema permanece transparente y manejable.
Impacto en el rendimiento de consultas y optimización ⚡
El esquema determina el rendimiento más que el diagrama ERD. Mientras que el diagrama ERD muestra relaciones, el esquema determina cómo el motor de base de datos accede a los datos. Un diagrama ERD podría mostrar una unión lógica entreUsuarios y Publicaciones. El esquema determina si existe un índice en el campoUser_ID en la tablaPublicaciones tabla.
Sin un índice adecuado en el esquema, una consulta sencilla puede desencadenar una escaneo completo de la tabla. Esta es una restricción física. El diagrama ER no puede mostrarte el plan de ejecución. Los desarrolladores deben revisar el esquema para entender por qué una consulta es lenta. Deben analizar los índices, la estrategia de partición y los tipos de datos.
Además, el esquema gestiona los mecanismos de bloqueo. Si múltiples usuarios actualizan el mismo registro, el nivel de aislamiento y la estrategia de bloqueo del esquema determinan si se bloquean mutuamente. El diagrama ER no dice nada sobre concurrencia. Esta es una distinción crucial para sistemas de alta carga.
Cerrando la brecha con las mejores prácticas 🏆
Para asegurar que ambos modelos cumplan su propósito de forma efectiva, considere adoptar estas normas:
- Utilice convenciones de nombres estándar:Asegúrese de que los nombres de las tablas en el esquema coincidan con los nombres de las entidades en el diagrama ER. La consistencia reduce la carga cognitiva.
- Documente las restricciones explícitamente:En el diagrama ER, anote las relaciones con su cardinalidad. En el esquema, anote las columnas con sus restricciones. Haga que las reglas sean visibles en ambos lugares.
- Revise regularmente:Programa revisiones trimestrales del diagrama ER frente al esquema de producción. Busque desviaciones y anomalías.
- Separe las responsabilidades:Trate el diagrama ER como un artefacto empresarial y el esquema como un artefacto técnico. No mezcle lógica empresarial en las definiciones del esquema físico.
- Planee la migración:Cuando cambie el diagrama ER, el esquema debe cambiar mediante un script de migración. Nunca modifique el esquema directamente en producción sin un script versionado.
El elemento humano de la modelización de datos 👥
En última instancia, estos modelos se crean para personas, no solo para máquinas. El diagrama ER es para la comunicación. Permite a un gerente de producto entender la estructura de los datos sin conocer SQL. El esquema es para la máquina. Permite a la aplicación recuperar datos de forma eficiente.
Cuando los desarrolladores entienden esta división entre humano y máquina, pueden diseñar mejores sistemas. Saben cuándo simplificar el diagrama ER para los interesados y cuándo detallar el esquema para el motor de base de datos. Esta dualidad es la esencia de la arquitectura de bases de datos.
Al respetar la frontera entre el diagrama lógico y la implementación física, los equipos evitan los problemas comunes de corrupción de datos y cuellos de botella de rendimiento. El diagrama ER proporciona la visión; el esquema proporciona la realidad. Ambos son necesarios para un sistema exitoso.
Reflexiones finales sobre la arquitectura de datos 🧠
La diferencia entre un diagrama de entidad-relación y un esquema de base de datos es un pilar fundamental de la ingeniería de software. Representa la transición del pensamiento a la acción, de la idea a la ejecución. Mientras que el diagrama ER captura las relaciones y la lógica que impulsan el negocio, el esquema captura las restricciones y las estructuras que impulsan la aplicación.
Dominar la relación entre estos dos modelos no se trata de memorizar definiciones. Se trata de comprender el ciclo de vida de los datos. Se trata de saber que un cambio en el diagrama requiere un cambio en el código, y que un cambio en el código debe reflejarse de nuevo en el diagrama. Este ciclo asegura que el sistema permanezca coherente, confiable y escalable.
A medida que avances en tu camino de desarrollo, mantén estos dos modelos separados. Utilice el diagrama ER para planificar y comunicar. Utilice el esquema para construir y hacer cumplir. Cuando los alinee, construirás sistemas que resisten la prueba del tiempo y del cambio.
Recuerde, el objetivo no es solo almacenar datos, sino almacenarlos de una manera que tenga sentido. Ese sentido proviene de la claridad lógica del diagrama ER y del rigor estructural del esquema. Juntos, forman la base de su arquitectura de datos.