











किसी भी विश्वसनीय सॉफ्टवेयर सिस्टम की आधारशिला को मजबूत डेटा संरचना डिज़ाइन करना है। एक एंटिटी रिलेशनशिप डायग्राम (ERD) डेटा के संग्रह, जोड़े और प्राप्ति के तरीके के लिए ब्लूप्रिंट के रूप में कार्य करता है। जब इस ब्लूप्रिंट में कमी होती है, तो परिणाम पूरे एप्लिकेशन में फैलते हैं, जिससे प्रदर्शन, डेटा अखंडता और विकास गति प्रभावित होती है। बहुत सी टीमें अपने स्कीमा डिज़ाइन के अनुमोदन के बिना ही इम्प्लीमेंटेशन में जल्दी कर देती हैं, जिससे बाद में ठीक करने में महंगा बनता है।
यह गाइड डेटाबेस मॉडलिंग में पाई जाने वाली सात महत्वपूर्ण गलतियों का विश्लेषण करता है। प्रत्येक बिंदु विशिष्ट तकनीकी प्रभाव को विस्तार से बताता है और इन त्रुटियों से बचने के लिए कार्यान्वयन योग्य दिशानिर्देश प्रदान करता है। नॉर्मलाइजेशन, सीमाओं और संबंध मैपिंग के तकनीकी तत्वों को समझकर आप ऐसे सिस्टम बना सकते हैं जो स्थिरता के बिना स्केल हो सकते हैं।
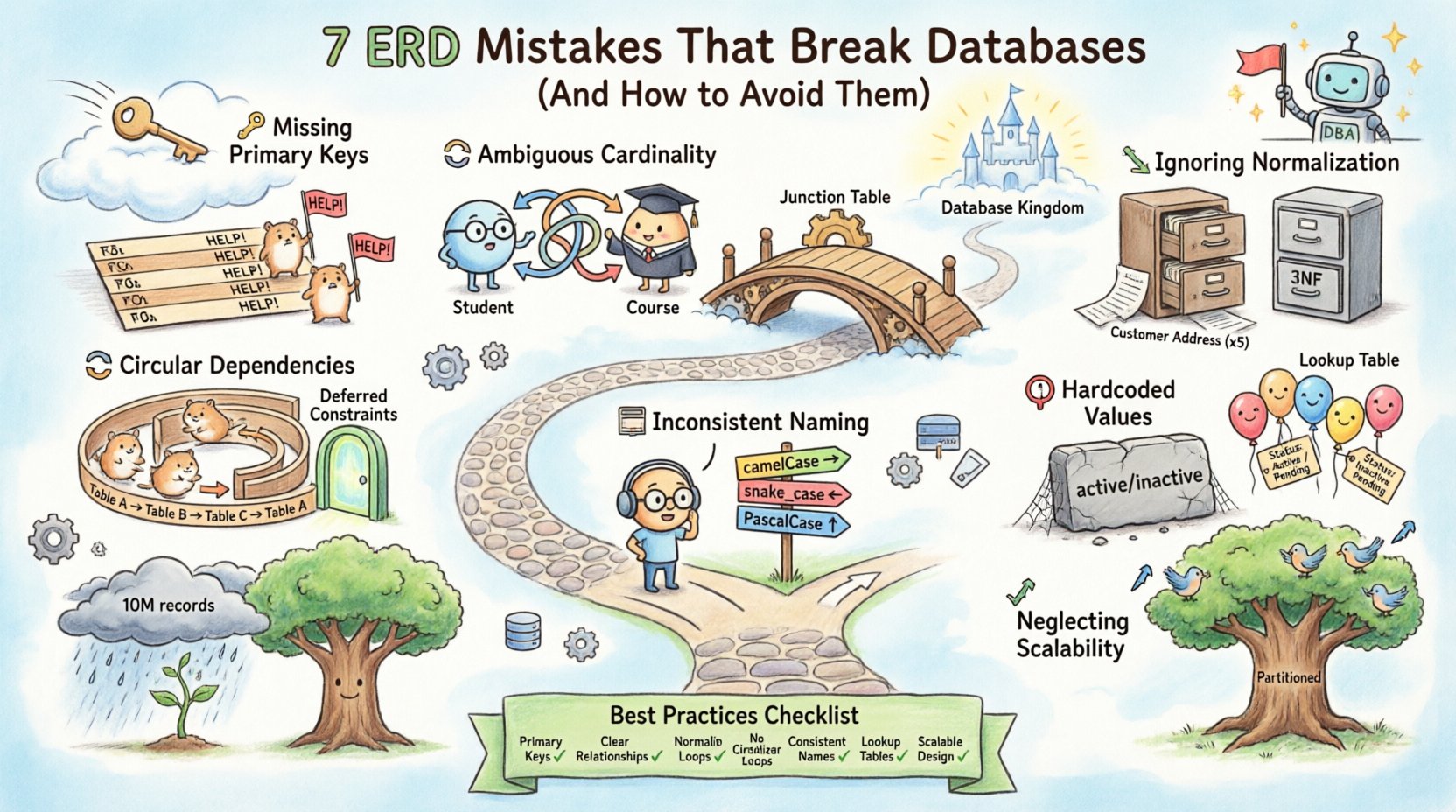
1. अनुपस्थित या कमजोर प्राथमिक की 🔑
एक प्राथमिक की एक टेबल के भीतर एक रिकॉर्ड के लिए एकमात्र पहचानकर्ता है। यह वह आधार है जो सुनिश्चित करता है कि प्रत्येक पंक्ति अद्वितीय और प्राप्त करने योग्य हो। प्राथमिक की के बिना छोड़ना या उसका खराब डिज़ाइन करना डेटाबेस आर्किटेक्चर में सबसे मूलभूत त्रुटियों में से एक है।
तकनीकी परिणाम
- डेटा दोहराव: एक अद्वितीय सीमा के बिना, डेटाबेस डुप्लीकेट रिकॉर्ड को रोक नहीं सकता है। इससे असंगत रिपोर्टिंग और डेटा अखंडता की समस्याएं उत्पन्न होती हैं।
- जॉइन प्रदर्शन: विदेशी की संबंध प्राथमिक की के लिए कुशल इंडेक्सिंग पर निर्भर करते हैं। अनुपस्थित या इंडेक्स नहीं किए गए प्राथमिक की के कारण जॉइन के दौरान पूरी टेबल स्कैन करना पड़ता है, जिससे क्वेरी निष्पादन बहुत धीमा हो जाता है।
- अपडेट की जटिलता: यदि आपको किसी रिकॉर्ड को अपडेट करना है, तो सिस्टम को अद्वितीय कॉलम के बजाय गैर-अद्वितीय कॉलम पर निर्भर रहना होगा। यदि बहुत सारी पंक्तियाँ खोज क्राइटेरिया के अनुरूप हैं, तो अपडेट अनचाहे डेटा पर लागू हो सकता है।
इससे बचने के लिए सर्वोत्तम प्रथाएं
- हर टेबल के लिए हमेशा एक प्राथमिक की परिभाषित करें, भले ही यह बेकार लगे।
- व्यावसायिक तर्क में बदलाव के कारण स्कीमा प्रभावित होने से बचने के लिए प्राकृतिक की (जैसे ईमेल पते या फोन नंबर) के बजाय सरोगेट की (ऑटो-इंक्रीमेंटिंग पूर्णांक या UUIDs) को प्राथमिकता दें।
- यह सुनिश्चित करें कि प्राथमिक की कॉलम नॉन-नलेबल हो।
- केवल तभी कंपोजिट की का उपयोग करें जब एकल कॉलम द्वारा पंक्ति की अद्वितीय पहचान नहीं की जा सकती हो, जैसे कि बहु-से-बहु संबंध वाली टेबल में।
2. अस्पष्ट संबंध गणना 🔄
गणना दो टेबलों में रिकॉर्ड्स के बीच संख्यात्मक संबंध को परिभाषित करती है। सामान्य प्रकार एक-से-एक, एक-से-बहुत और बहु-से-बहु हैं। डायग्राम में इन संबंधों का गलत प्रतिनिधित्व करने से भौतिक डेटाबेस में संरचनात्मक असंगतता उत्पन्न होती है।
आम त्रुटियाँ
- एक-से-बहु मानना: जब बहु-से-बहु संबंध होता है, तो डिज़ाइनर अक्सर एक-से-बहु संबंध को डिफॉल्ट मान लेते हैं। उदाहरण के लिए, एक छात्र बहुत से कोर्स में दाखिला ले सकता है, और एक कोर्स में बहुत से छात्र हो सकते हैं। इसे एक-से-बहु के रूप में मॉडल करने के लिए छात्र डेटा को कई कोर्स पंक्तियों में दोहराना पड़ता है।
- अनलेबल लाइनें:ERD लाइनों में गणना को दर्शाना चाहिए (जैसे क्राउज़ फुट नोटेशन)। उन्हें अनलेबल छोड़ने से डेवलपर्स को अनिश्चितता होती है कि डेटा कैसे संबंधित है।
- नलेबिलिटी को नजरअंदाज करना: यदि संबंध वैकल्पिक है, तो एक-से-एक संबंध में विदेशी की कॉलम में नल मान्य हो सकते हैं। इस सीमा को मॉडल न करने से अनाथ रिकॉर्ड बनते हैं।
सही तरीका
- दोनों संबंधित टेबलों से विदेशी की को रखने वाली जंक्शन टेबल (सहसंबंध टेबल) का उपयोग करके बहु-से-बहु संबंधों को स्पष्ट रूप से मैप करें।
- डायग्राम लाइनों पर गणना को स्पष्ट रूप से दर्ज करें।
- डायग्राम की तर्क को लागू करने के लिए डेटाबेस सीमाओं (जैसे विदेशी की पर यूनिक सीमा) का उपयोग करें।
| संबंध प्रकार | कार्यान्वयन रणनीति | आम त्रुटि |
|---|---|---|
| एक से एक | एक तालिका में विदेशी कुंजी जिसमें यूनिक सीमा हो | दोनों तालिकाओं में अनावश्यक रूप से विदेशी कुंजी जोड़ना |
| एक से बहुत | “बहुत” तालिका में विदेशी कुंजी | माता-पिता के डेटा को बच्चे की तालिका में संग्रहीत करना (अनियमितता) |
| बहुत से बहुत | मध्यवर्ती संयोजन तालिका | एकल कोमा-अलग कॉलम में कई पहचान संख्याओं को संग्रहीत करना |
3. नॉर्मलाइजेशन मानकों के अनदेखा करना 📉
नॉर्मलाइजेशन डेटा को व्यवस्थित करने की प्रक्रिया है जिससे अतिरिक्तता कम होती है और अखंडता में सुधार होता है। जबकि कुछ आधुनिक प्रणालियाँ पढ़ने के प्रदर्शन के लिए अनियमितता को अपनाती हैं, डिजाइन चरण के दौरान नॉर्मलाइजेशन को पूरी तरह से छोड़ देने से महत्वपूर्ण रखरखाव के बोझ का निर्माण होता है।
कमजोर नॉर्मलाइजेशन के जोखिम
- अपडेट विचित्रताएँ: यदि एक ग्राहक का पता पांच अलग-अलग आदेश तालिकाओं में संग्रहीत है, तो उनके पते को अपडेट करने के लिए पांच अलग-अलग अपडेट की आवश्यकता होती है। यदि एक अपडेट विफल होता है, तो डेटा असंगत हो जाता है।
- प्रविष्टि विचित्रताएँ: आप एक नई उत्पाद श्रेणी जोड़ नहीं पाएंगे बिना एक उत्पाद रिकॉर्ड जोड़े, जिससे डमी डेटा के निर्माण के लिए मजबूर किया जाएगा।
- हटाने की विचित्रताएँ: एक रिकॉर्ड को हटाने से अन्य एकाधिकारों से संबंधित महत्वपूर्ण डेटा को अनजाने में हटा दिया जा सकता है।
कार्यान्वयन दिशानिर्देश
- आधारभूत स्तर के रूप में तृतीय नॉर्मल रूप (3NF) की ओर ध्यान केंद्रित करें। इससे यह सुनिश्चित होता है कि कॉलम केवल मुख्य कुंजी पर निर्भर करते हैं।
- स्थानांतरित निर्भरता की पहचान करें जहां एक गैर-कुंजी कॉलम दूसरे गैर-कुंजी कॉलम पर निर्भर होता है।
- अलग-अलग एकाधिकारों को अलग करें। यदि एक तालिका में “आदेशों” और “ग्राहकों” दोनों के बारे में जानकारी है, तो उन्हें अलग करें।
- केवल प्रश्न प्रदर्शन के प्रोफाइलिंग के बाद ही अनियमितता करें। अखंडता के नुकसान के बदले तेजी के लिए पूर्व-अनुकूलन न करें।
4. चक्रीय निर्भरताओं का निर्माण 🔁
चक्रीय निर्भरताएँ तब होती हैं जब तालिकाएँ एक लूप में एक-दूसरे को संदर्भित करती हैं जिससे प्रारंभीकरण रोका जाता है या प्रश्नों में अनंत पुनरावृत्ति होती है। जबकि पुनरावर्ती संबंध (जैसे संगठनात्मक चार्ट जहां एक कर्मचारी के प्रबंधक होते हैं) वैध हैं, नियंत्रण बिना चक्रीय विदेशी कुंजियाँ डेटाबेस को तोड़ सकती हैं।
इसके प्रणालियों को तोड़ने के कारण
- प्रारंभीकरण त्रुटियाँ: डेप्लॉयमेंट के दौरान, यदि एक सर्कुलर रेफरेंस है (उदाहरण के लिए, टेबल A बी को रेफर करता है, और बी ए को रेफर करता है) तो डेटाबेस इंजन फॉरेन की कंस्ट्रेंट के निर्माण को अस्वीकार कर सकता है, बशर्ते कि डिफर्ड कंस्ट्रेंट्स के साथ इसका निपटारा किया जाए।
- क्वेरी स्टैक ओवरफ्लोज़: रिकर्सिव क्वेरीज़ जो इन लूप्स को बिना एक ब्रेकिंग कंडीशन के पार करती हैं, सभी उपलब्ध मेमोरी का उपयोग कर सकती हैं।
- रेफेरेंशियल इंटीग्रिटी उल्लंघन: यदि चाइल्ड टेबल को साफ नहीं किया गया है, तो पैरेंट टेबल को हटाने में विफलता हो सकती है, लेकिन चाइल्ड को साफ करने में विफलता हो सकती है क्योंकि अन्य डिपेंडेंसीज़ के कारण।
हल कैसे करें
- उपयोग करें डिफर्ड कंस्ट्रेंट्स यदि आपका डेटाबेस इन्हें सपोर्ट करता है, तो डेटाबेस को सभी डेटा लोड होने के बाद संबंधों की जांच करने की अनुमति देता है।
- सेल्फ-रेफरेंसिंग टेबल के लिए (जैसे कैटेगरी), सुनिश्चित करें कि फॉरेन की नलेबल है ताकि रूट नोड्स की अनुमति मिल सके।
- स्कीमा को डिज़ाइन करें ताकि प्रत्येक स्तर पर भौतिक फॉरेन की लूप को जबरदस्ती न डाला जाए, बल्कि एक लॉजिकल हायरार्की की अनुमति दी जाए।
- हटाने के कैस्केड को सुरक्षित ढंग से प्रबंधित करने के लिए सॉफ्ट डिलीट को लागू करें।
5. असंगत नामकरण प्रथाएं 📝
नाम मानवों और मशीनों के बीच का इंटरफेस हैं। टेबल और कॉलम के नामों में असंगत नामकरण स्कीमा को समझने, बनाए रखने और प्रश्न पूछने में कठिन बना देता है। यह अक्सर एक साझा स्टाइल गाइड के अभाव से उत्पन्न होता है।
विशिष्ट समस्याएं
- मिश्रित केस: मिश्रण
कैमलकेस,स्नेककेस, औरपैस्कलकेसडेटा को प्रश्न करने वाले डेवलपर्स को भ्रमित करता है। - आरक्षित कीवर्ड्स: नामों के रूप में उपयोग करना जैसे
ऑर्डर,ग्रुप, यायूजरबिना एस्केप किए होने से SQL क्वेरी में सिंटैक्स त्रुटियाँ हो सकती हैं। - संक्षिप्त रूप: उपयोग करते हुए
उपयोगकर्ता_आईडीबनामउपयोगकर्ता_आईडीबनामउपयोगकर्ता_आईडीअलग-अलग तालिकाओं में इससे स्पष्टता कम हो जाती है। - विस्तृतता बनाम संक्षिप्तता: कुछ कॉलम अत्यधिक लंबे हैं, जबकि अन्य क्रिप्टिक संक्षिप्त रूप हैं।
मानक स्थापित करना
- एक संगत केसिंग रणनीति अपनाएं (उदाहरण के लिए,
स्नेक_केसSQL तालिकाओं के लिए व्यापक रूप से सिफारिश की जाती है।) - व्यापार अर्थ को दर्शाने वाले वर्णनात्मक नामों का उपयोग करें, आंतरिक कार्यान्वयन विवरणों के बजाय।
- आरक्षित कीवर्ड्स का पूरी तरह से बचना। यदि अनिवार्य हो, तो उन्हें डेटाबेस इंजन के अनुसार उद्धरण या कोष्ठकों में लपेटें।
- एकल और बहुवचन तालिका नामों को मानकीकृत करें। एक चुनें और उस पर टिके रहें (उदाहरण के लिए,
उपयोगकर्ताबनामउपयोगकर्ता). - परामर्शित तालिका के नाम के साथ विदेशी कुंजी कॉलम को प्रीफिक्स करें (उदाहरण के लिए,
उपयोगकर्ता_आईडीसंबंधों को स्पष्ट करने के लिए।)
6. स्कीमा में मानों को हार्डकोड करना 🛑
डिजाइनर कभी-कभी विशिष्ट व्यावसायिक मानों को डेटाबेस संरचना में सीधे एम्बेड कर देते हैं, जैसे कि विशिष्ट स्थिति कोड जैसे सक्रिय या निष्क्रिय एक सामान्य स्थिति फ़ील्ड के उपयोग या मुद्रा प्रकारों को कड़ी तरीके से कोड करने के बजाय।
लचीलापन पर प्रभाव
- स्कीमा बदलाव: यदि एक नया स्थिति की आवश्यकता हो, तो आपको टेबल संरचना में बदलाव करना या एक नया कॉलम जोड़ना पड़ सकता है, जिससे डिप्लॉयमेंट के दौरान बाधा उत्पन्न हो सकती है।
- डेटा सत्यापन: एप्लिकेशन कोड अक्सर इन मानों की सत्यापन करता है, लेकिन डेटाबेस स्कीमा को सीमाओं या सेट के माध्यम से सीमित मानों को बल देना चाहिए।
- स्थानीयकरण समस्याएं: ऐसे पाठ मानों को कड़ी तरीके से कोड करना जैसे
USDयाअंग्रेजीवैश्विक विस्तार को मुश्किल बनाता है।
स्केलेबिलिटी के लिए पुनर्गठन
- उपयोग करेंलुकअप टेबल किसी भी मानों के सेट के लिए जो बदल सकते हैं या बढ़ सकते हैं (जैसे स्थिति, मुद्रा, देश)।
- लागू करेंचेक सीमाएं केवल मान्य मानों के दर्ज होने की गारंटी करने के लिए, लेकिन उन मानों के परिभाषा को एप्लिकेशन या अलग संरचना टेबल में रखें।
- एन्यूम का उपयोग केवल तभी करें जब डेटाबेस सिस्टम उन्हें मजबूती से समर्थन करे और सेट वास्तव में निश्चित हो।
- संरचना डेटा को लेनदेन डेटा से अलग करें।
7. भविष्य की स्केलेबिलिटी के बारे में ध्यान न देना 📈
बहुत सारे एरडी वर्तमान डेटासेट के आकार के लिए डिज़ाइन किए जाते हैं, बढ़ोतरी के बारे में विचार नहीं करते। 1,000 रिकॉर्ड के लिए काम करने वाला स्कीमा लॉकिंग, इंडेक्सिंग या पार्टीशनिंग की समस्याओं के कारण 10 मिलियन रिकॉर्ड पर भारी विफलता का कारण बन सकता है।
स्केलेबिलिटी की खामियां
- बड़े पाठ क्षेत्र: मुख्य टेबल में विशाल ब्लॉब या लंबे पाठ स्ट्रिंग को स्टोर करना इंडेक्स को बढ़ा सकता है और पढ़ने की गति को धीमा कर सकता है।
- पार्टीशनिंग की चाबी की कमी: यदि स्कीमा यह ध्यान नहीं रखता कि डेटा को कैसे शेड या पार्टीशन किया जाएगा (जैसे तारीख या क्षेत्र के आधार पर), तो भविष्य में क्षैतिज स्केलिंग एक महत्वपूर्ण पुनर्गठन बन जाती है।
- अनुपस्थित इंडेक्स: भविष्य में फ़िल्टरिंग या वर्गीकरण के लिए किन कॉलम का उपयोग किया जाएगा, इसकी भविष्यवाणी न करने से प्रदर्शन की सीमा उत्पन्न होती है।
- लेखन-भारी पैटर्न: एक रीड्स के लिए अनुकूलित डिज़ाइन विदेशी कुंजियों पर लॉकिंग मैकेनिज्म के कारण उच्च मात्रा में लेखन पर फंस सकता है।
वृद्धि के लिए डिज़ाइन करना
- समीक्षा करें पढ़ने/लिखने का अनुपात आपके एप्लिकेशन का। यदि यह लेखन-भारी है, तो लॉकिंग का कारण बनने वाली विदेशी कुंजी सीमांकन को कम करें।
- डिज़ाइन करें पार्टीशनिंग कुंजियाँ अपने मुख्य स्कीमा में। सुनिश्चित करें कि प्रत्येक टेबल में एक कॉलम है जिसका उपयोग डेटा को तार्किक रूप से विभाजित करने के लिए किया जा सके।
- भारी टेक्स्ट डेटा को अलग टेबल में अलग करें (1:1 संबंध) ताकि मुख्य इंडेक्स हल्का रहे।
- योजना बनाएं सॉफ्ट डिलीट्स कठोर डिलीट्स के बजाय डेटा इतिहास को बरकरार रखने के लिए बिना वर्तमान प्रश्न प्रदर्शन को प्रभावित किए।
सर्वोत्तम व्यवहार का सारांश 📋
अपने डेटाबेस को स्थिर और रखरखाव योग्य बनाए रखने के लिए, डेप्लॉयमेंट से पहले निम्नलिखित चेकलिस्ट के खिलाफ अपने एंटिटी रिलेशनशिप डायग्राम की समीक्षा करें।
- कुंजियाँ: प्रत्येक टेबल में प्राथमिक कुंजी है। विदेशी कुंजियाँ सूचीबद्ध हैं।
- संबंध: कार्डिनैलिटी स्पष्ट रूप से परिभाषित है। बहुत-से-बहुत के लिए जंक्शन टेबल का उपयोग किया जाता है।
- नॉर्मलाइजेशन: डेटा अतिरेक 3NF मानकों के अनुसार न्यूनतम किया गया है।
- निर्भरता: निर्धारित अनुमतियों के बिना कोई वृत्ताकार विदेशी कुंजी लूप नहीं है।
- नामकरण: संगत केसिंग और वर्णनात्मक नाम पूरे में उपयोग किए गए हैं।
- मान: स्कीमा संरचना में कोई हार्डकोडेड व्यापार तर्क नहीं है।
- स्केल: स्कीमा भविष्य के लोड के लिए पार्टीशनिंग और इंडेक्सिंग रणनीतियों को ध्यान में रखता है।
डेटा मॉडलिंग पर अंतिम विचार 🧠
एक डेटाबेस बनाना केवल लिखने के बारे में नहीं हैटेबल बनाएंकथन। यह अपनी व्यापार प्रक्रियाओं की वास्तविकता को एक तार्किक संरचना में मॉडल करने के बारे में है जिसे मशीन कम समय में प्रोसेस कर सकती है। स्कीमा त्रुटि को ठीक करने की लागत विकास चक्र में जितनी देरी से पाया जाता है, उतनी ही अधिक बढ़ती है।
इन सात आम त्रुटियों से बचकर आप तकनीकी देनदारी को कम करते हैं और जटिल प्रश्नों और उच्च आयतन लेनदेन का समर्थन करने वाला आधार बनाते हैं। अपने आरेखों में स्पष्टता, अखंडता और लचीलापन को प्राथमिकता दें। एक अच्छी तरह से डिज़ाइन किया गया ईआरडी अंतिम उपयोगकर्ता के लिए अदृश्य होता है, लेकिन प्रणाली की लंबी अवधि के लिए आवश्यक होता है।
ताज़ा आंखों से या सहकर्मी समीक्षा प्रक्रिया के साथ अपने स्कीमा की समीक्षा करने का समय लें। जांचें कि किसी संबंध का अस्तित्व क्यों है और भार के तहत यह कैसे व्यवहार करेगा। इस सावधानी का लाभ भविष्य में प्रणाली की विश्वसनीयता और डेवलपर उत्पादकता में दिखाई देता है।