











हर ऐप की शुरुआत एक विचार से होती है। उस विचार के लिए डेटा स्टोरेज की जरूरत होती है, और उस स्टोरेज के लिए एक नक्शा चाहिए। यह नक्शा ही एंटिटी-रिलेशनशिप डायग्राम (ERD) है। यह वह मूल दस्तावेज है जो निर्धारित करता है कि आपकी सिस्टम जानकारी को कैसे समझता है। हालांकि, एक छोटे झोंपड़ी के लिए बनाया गया नक्शा एक ऊंची इमारत के लिए काम नहीं आता। इसी तरह, एक प्रोटोटाइप के लिए डिज़ाइन किया गया डेटाबेस स्कीमा अक्सर उत्पादन ट्रैफिक और जटिल व्यावसायिक तर्क के बोझ के तहत विफल हो जाता है।
टेक्निकल लीड्स, डेटाबेस एडमिनिस्ट्रेटर्स और सॉफ्टवेयर आर्किटेक्ट्स के लिए ERD विकास को समझना महत्वपूर्ण है। इसमें लचीलेपन और अखंडता के बीच तनाव को संभालने की आवश्यकता होती है। जैसे-जैसे आपके उपयोगकर्ता आधार बढ़ता है, आपकी डेटा आवश्यकताएं बदलती हैं। आप बस शुरुआती मॉडल को हमेशा के लिए नहीं रख सकते। आपको इसे अनुकूलित करना होगा। यह गाइड डेटा मॉडल के जीवनचक्र का अध्ययन करता है, पहली कोड लाइन से लेकर एंटरप्राइज स्केल आर्किटेक्चर तक।
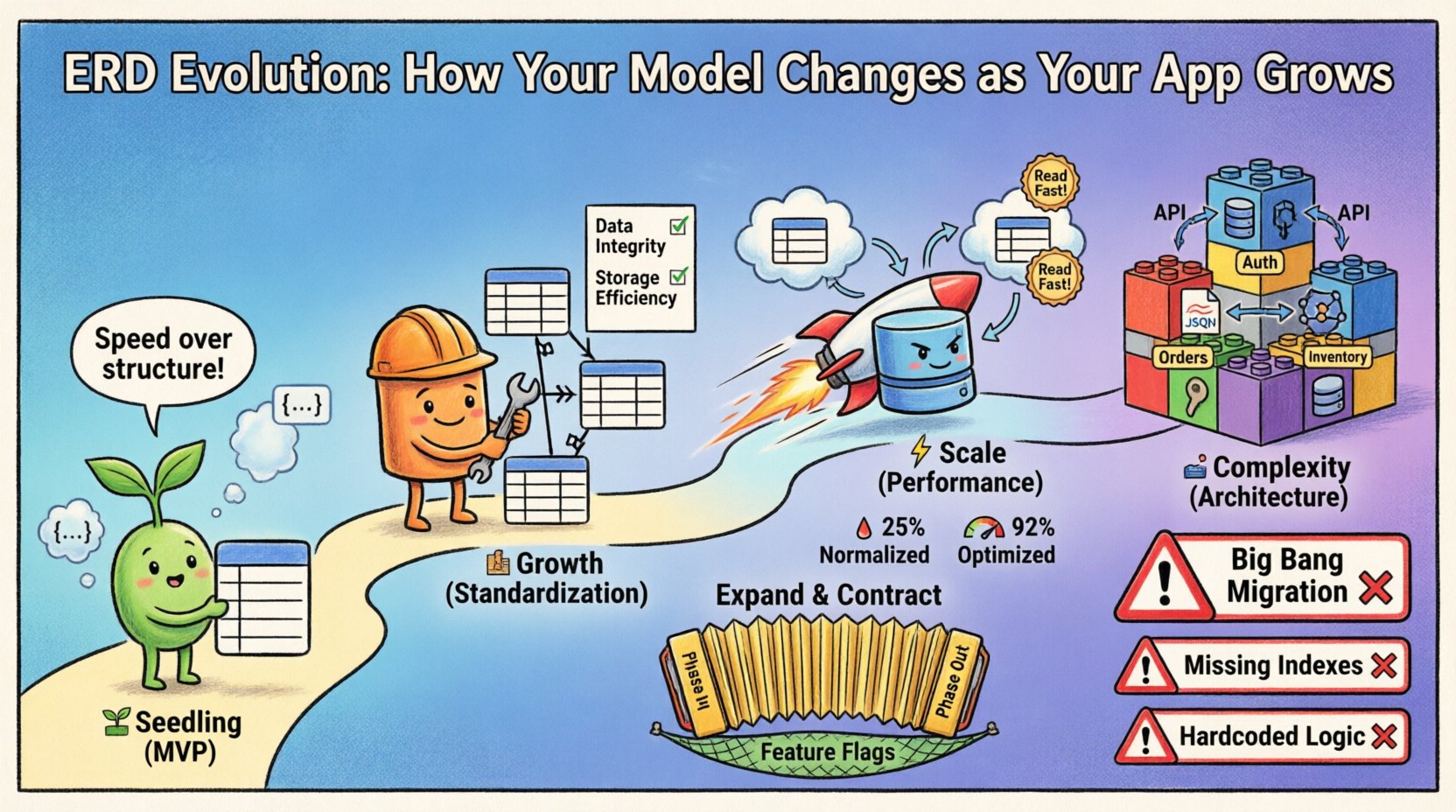
चरण 1: बीज के चरण (MVP) 🌱
शुरुआत में, गति मुख्य मापदंड होती है। लक्ष्य न्यूनतम बाधा के साथ मूल परिकल्पना की पुष्टि करना है। इस चरण में, ERD अक्सर तरल होता है, जो लंबे समय के अनुमानों के बजाय तुरंत आवश्यकताओं को दर्शाता है।
- फोकस:संरचना की बजाय कार्यक्षमता।
- संरचना:समतल स्कीमा आम हैं। संबंध अक्सर निरस्त किए जाते हैं ताकि जॉइन की जटिलता कम की जा सके।
- सीमाएं:विदेशी कुंजियां कभी-कभी ढीली हो सकती हैं या छोड़ दी जा सकती हैं ताकि तेजी से अनुकूलन किया जा सके।
- बदलाव:स्कीमा में संशोधन हफ्ते में एक बार होते हैं, कभी-कभी दैनिक रूप से।
इस चरण के दौरान, आप संयुक्त एंटिटी को देख सकते हैं। उदाहरण के लिए, एक उपयोगकर्ताताबला प्रोफाइल सेटिंग्स के एक JSON ब्लॉब को शामिल कर सकता है, एक अलग प्रोफाइलताबला। इससे जॉइन की आवश्यकता कम हो जाती है, जिससे डैशबोर्ड के लिए रीड ऑपरेशन तेज हो जाते हैं। हालांकि, इससे तकनीकी देनदारी बनती है। जैसे-जैसे ऐप परिपक्व होता है, उस नेस्टेड डेटा को प्रश्न करना धीमा और बनाए रखने में कठिन हो जाता है।
प्रारंभिक चरण के मॉडल की मुख्य विशेषताएं
- न्यूनतम विदेशी कुंजी सीमाएं।
- लचीले कॉलम प्रकार (उदाहरण के लिए, सब कुछ के लिए VARCHAR का उपयोग करना)।
- एकल डेटाबेस इंस्टेंस।
- एप्लीकेशन ऑब्जेक्ट्स और डेटाबेस टेबल के बीच सीधा मैपिंग।
चरण 2: वृद्धि चरण (मानकीकरण) 🏗️
जब उत्पाद को लोकप्रियता मिलती है, तो शुरुआती लचीलेपन एक दोष बन जाता है। डेटा दोहराव असंगति के कारण बनता है। यदि उपयोगकर्ता एक जगह अपना ईमेल पता अपडेट करता है लेकिन दूसरी जगह नहीं, तो सिस्टम विश्वास को तोड़ देता है। यह वह चरण है जब नॉर्मलाइजेशन को प्राथमिकता दी जाती है।
अब नॉर्मलाइज़ क्यों करें?
- डेटा अखंडता:संदर्भात्मक अखंडता को लागू करने से अनाथ रिकॉर्ड्स को रोका जा सकता है।
- स्टोरेज की दक्षता:आवश्यकता से अधिक डेटा हटाने से डिस्क स्पेस बचता है।
- रखरखावयोग्यता:एक सामान्यीकृत तालिका में एक एकल रिकॉर्ड के अपडेट करने से यह सभी जगह तार्किक रूप से अपडेट हो जाता है।
- प्रश्न पूर्वानुमाननीयता:मानकीकृत संरचनाएं प्रश्न लिखने को कम त्रुटिपूर्ण बनाती हैं।
इस संक्रमण के दौरान, आपको एरडी को पुनर्गठित करना होगा। एक समतल उपयोगकर्ता तालिका को विभाजित किया जा सकता है उपयोगकर्ता और उपयोगकर्ता विवरण। इससे संबंध उत्पन्न होते हैं। आपको यह निर्धारित करना होगा कि ये एक-एक, एक-बहुत या बहुत-बहुत हैं।
संक्रमण चेकलिस्ट
- तालिकाओं के बीच सभी दोहराए गए क्षेत्रों की पहचान करें।
- सभी संस्थाओं के लिए प्राथमिक कुंजियां परिभाषित करें।
- संबंधों को बल देने के लिए विदेशी कुंजी प्रतिबंधों को लागू करें।
- नए जॉइन्स के प्रदर्शन प्रभावों के लिए मौजूदा प्रश्नों की समीक्षा करें।
- स्थानांतरण के दौरान पीछे की ओर संगतता के लिए योजना बनाएं।
चरण 3: स्केल चरण (प्रदर्शन) ⚡
जब मिलियनों रिकॉर्ड मौजूद हों, तो सामान्यीकृत संरचना एक बाधा बन सकती है। स्केल पर जॉइन्स की गणना बहुत महंगी होती है। यहीं मॉडल फिर से विकसित होता है, अक्सर सख्त सामान्यीकरण से दूर होकर प्रदर्शन के लिए रणनीतिक असामान्यीकरण की ओर बढ़ता है।
रणनीतिक असामान्यीकरण
यह एमवीपी चरण में वापसी नहीं है। यह एक गणना की गई निर्णय है। आप जानबूझकर डेटा की प्रतिलिपि बनाते हैं ताकि बड़ी तालिकाओं पर महंगे जॉइन्स से बचा जा सके।
- पढ़ने-भारी कार्यभार: यदि आपका एप्लिकेशन अधिकांशतः पढ़ने वाला है, तो स्कीमा में डेटा कैश करने से डेटाबेस लोड कम हो जाता है।
- रिपोर्टिंग तालिकाएं:डैशबोर्ड के लिए पूर्व-समग्र डेटा के लिए तुरंत योग की गणना से बचा जाता है।
- विभाजन: तारीख या क्षेत्र के आधार पर तालिकाओं को विभाजित करने के लिए विशिष्ट स्कीमा डिजाइन की आवश्यकता होती है ताकि कुशल प्रश्न प्राप्त किए जा सकें।
तुलना: सामान्यीकृत बनाम अनुकूलित
| विशेषता | सामान्यीकृत (चरण 2) | अनुकूलित (चरण 3) |
|---|---|---|
| अखंडता | उच्च (डेटाबेस द्वारा बलपूर्वक लागू) | एप्लिकेशन लॉजिक द्वारा प्रबंधित |
| लेखन गति | तेज़ | धीमी (बहुत सारी टेबल्स को अपडेट करती है) |
| पढ़ने की गति | धीमी (जॉइन्स की आवश्यकता होती है) | तेज़ (एकल खोज) |
| स्टोरेज | कुशल | कम कुशल (आवर्धन) |
चरण 4: जटिलता चरण (आर्किटेक्चर) 🏛️
एंटरप्राइज स्तर पर, एक ही डेटाबेस मॉडल अक्सर पर्याप्त नहीं होता है। सिस्टम माइक्रोसर्विसेज में विभाजित हो सकता है या पॉलीग्लॉट पर्सिस्टेंस का उपयोग कर सकता है। एरडी अब एकल भौतिक आरेख का प्रतिनिधित्व नहीं करता है, बल्कि आपस में संचार करने वाले मॉडलों के संग्रह का प्रतिनिधित्व करता है।
माइक्रोसर्विसेज और डेटा स्वामित्व
एक मोनोलिथिक आर्किटेक्चर में, आदेश टेबल बिलिंग, शिपिंग और सूचना सेवाओं द्वारा साझा की जाती है। एक वितरित प्रणाली में, प्रत्येक सेवा अपने डेटा का स्वामित्व रखती है। इसके लिए आपको संबंधों के मॉडलिंग के तरीके में बदलाव की आवश्यकता होती है।
- अंततः सुसंगतता: आप सेवाओं के बीच एसीआईडी लेनदेन पर भरोसा नहीं कर सकते। एरडी को स्थिति समन्वय को ध्यान में रखना चाहिए।
- एपीआई कॉन्ट्रैक्ट्स: संबंध अक्सर विदेशी कुंजियों के बजाय एपीआई प्रतिक्रियाओं द्वारा परिभाषित किए जाते हैं।
- डेटा समन्वय: अलग-अलग स्टोर्स में डेटा को सुसंगत रखने के लिए उपकरणों की आवश्यकता होती है (उदाहरण के लिए, आदेशों के लिए SQL, लॉग्स के लिए नोस्क्ल)।
पॉलीग्लॉट पर्सिस्टेंस
अलग-अलग डेटा के लिए अलग-अलग स्टोरेज इंजन की आवश्यकता होती है। एरडी अन-रिलेशनल अवधारणाओं को शामिल करने के लिए विकसित होता है।
- ग्राफ डेटा: सोशल नेटवर्क या सुझाव इंजन के लिए, ग्राफ मॉडल संबंधित टेबल्स के स्थान पर आता है।
- दस्तावेज़ स्टोर्स: उच्च लचीलेपन वाली सामग्री जैसे उत्पाद कैटलॉग के लिए, JSON दस्तावेज़ कठोर कॉलम के स्थान पर आते हैं।
- की-वैल्यू स्टोर्स: सत्र प्रबंधन और कैशिंग के लिए, सरल कुंजी-मान युग्म जटिल पंक्तियों के स्थान पर आते हैं।
तकनीकी गहन अध्ययन: सामान्यीकरण स्तर 🔬
आपके मॉडल को प्रभावी ढंग से विकसित करने के लिए, आपको उन नियमों को समझना होगा जिनका आप पालन कर रहे हैं या उन्हें तोड़ रहे हैं। सामान्यीकरण डेटा को कम अतिरिक्तता के साथ व्यवस्थित करने की प्रक्रिया है।
पहला सामान्यीकरण रूप (1NF)
- परमाणु मान: प्रत्येक कॉलम में केवल एक मान होता है।
- पुनरावृत्ति समूह नहीं: आपके पास ऐसे कॉलम नहीं हो सकते जैसे
रंग1,रंग2,रंग3. - एकल पहचानकर्ता: प्रत्येक पंक्ति को एकल रूप से पहचाना जा सकना चाहिए।
दूसरा सामान्यीकरण रूप (2NF)
- 1NF में होना चाहिए।
- सभी गैर-कुंजी विशेषताओं को मुख्य कुंजी पर पूरी तरह निर्भर होना चाहिए।
- आंशिक निर्भरता को हटाता है (उदाहरण के लिए, यदि विक्रेता की जानकारी केवल विक्रेता ID पर निर्भर है, न कि आदेश ID पर, तो उसे अलग तालिका में स्थानांतरित करना)।
तीसरा सामान्यीकरण रूप (3NF)
- 2NF में होना चाहिए।
- स्थानांतरित निर्भरताएं हटा दी जाती हैं।
- एक कॉलम दूसरे गैर-कुंजी कॉलम पर निर्भर नहीं हो सकता (उदाहरण के लिए,
शहरपर निर्भर है, न किराज्य, केवलपिन कोड। ले जाएंशहरऔरराज्यएक के लिएस्थानतालिका।
ईआरडी विकास में सामान्य त्रुटियाँ ⚠️
यहाँ तक कि अनुभवी टीमें भी मॉडल को पुनर्गठित करते समय गलतियाँ करती हैं। इन पैटर्न को पहचानने से लागत वाले डाउनटाइम से बचा जा सकता है।
1. बिग बैंग माइग्रेशन
एक ही डेप्लॉयमेंट में पूरे स्कीमा को बदलने की कोशिश। इसमें उच्च जोखिम है। यदि माइग्रेशन स्क्रिप्ट विफल होती है, तो सिस्टम खराब हो जाता है।
- समाधान: आरंभिक माइग्रेशन का उपयोग करें। कॉलम जोड़ें, डेटा भरें, लॉजिक बदलें, फिर पुराने कॉलम हटाएं।
2. इंडेक्सिंग प्रभावों को नजरअंदाज करना
संबंधों में बदलाव करने से क्वेरी पैटर्न बदल जाते हैं। एक नया विदेशी कुंजी संबंध को अच्छे प्रदर्शन के लिए एक नया इंडेक्स की आवश्यकता हो सकती है।
- समाधान: स्कीमा बदलाव से पहले और बाद में धीमी क्वेरी लॉग का विश्लेषण करें।
- समाधान: शीर्ष घंटों के बाहर समय में इंडेक्स निर्माण की योजना बनाएं।
3. एप्लिकेशन लॉजिक में अनिवार्यताओं को कड़ाई से लिखना
कुछ टीमें कोड में डेटा के प्रमाणीकरण को डेटाबेस के बजाय प्राथमिकता देती हैं। यदि कई सेवाएं एक ही स्टोर में लिखती हैं, तो इससे डेटा क्षति हो सकती है।
- समाधान: यहां तक कि यदि एप्लिकेशन वितरित है, तो भी अनिवार्यताओं को डेटाबेस लेयर में रखें (NOT NULL, CHECK अनिवार्यताएं)।
माइग्रेशन रणनीतियाँ 🔄
जब आपको ईआरडी के विकास की आवश्यकता हो, तो आपको एक रणनीति की आवश्यकता होती है जो डाउनटाइम और डेटा हानि को न्यूनतम करे।
एक्सपैंड और कॉन्ट्रैक्ट पैटर्न
यह सुरक्षित स्कीमा विकास के लिए स्वर्ण मानक है।
- जोड़ें: स्कीमा में नए कॉलम या तालिका को जोड़ें। अभी अस्तित्व में मौजूद लॉजिक को बदलें नहीं।
- लिखें: एप्लिकेशन को नए और पुराने संरचनाओं दोनों में लिखने के लिए अपडेट करें।
- पढ़ें: एप्लिकेशन को नए संरचना से पढ़ने के लिए अपडेट करें।
- पूर्व भरें: पुराने डेटा के साथ नए संरचना को भरने के लिए एक बैकग्राउंड कार्य चलाएं।
- संविदा: एक बार सत्यापित करने के बाद, पुराने कॉलम और तर्क को हटा दें।
फीचर फ्लैग
पुराने स्कीमा और नए स्कीमा के बीच स्विच करने के लिए फीचर फ्लैग का उपयोग करें। इससे आप तुरंत वापस ले सकते हैं यदि समस्याएं उत्पन्न हों, बिना रोलबैक स्क्रिप्ट डेप्लॉय किए।
दस्तावेज़ीकरण और संस्करण प्रबंधन 📝
एक ईआरडी एक बार के डिलीवरेबल के रूप में नहीं है। यह एक जीवंत दस्तावेज़ है। जैसे मॉडल विकसित होता है, दस्तावेज़ीकरण को भी इसी गति से आगे बढ़ना चाहिए।
स्कीमा के लिए संस्करण नियंत्रण
- स्कीमा फ़ाइलों (SQL स्क्रिप्ट) को कोड के रूप में लें। उन्हें अपने संस्करण नियंत्रण प्रणाली में स्टोर करें।
- समय के साथ बदलावों को ट्रैक करने के लिए माइग्रेशन टूल का उपयोग करें।
- स्कीमा संस्करणों के साथ रिलीज़ को टैग करें (उदाहरण के लिए,
v1.2.0-स्कीमा).
दृश्य सुसंगतता
- नामकरण प्रथाओं को मानकीकृत करें (उदाहरण के लिए, snake_case बनाम camelCase)।
- यह सुनिश्चित करें कि तालिका नाम डोमेन का प्रतिनिधित्व करें (उदाहरण के लिए,
ग्राहकके बजायt1). - व्यावसायिक तर्क के संदर्भ के लिए स्कीमा में टिप्पणियाँ रखें।
आपके मॉडल को भविष्य के लिए सुरक्षित बनाना 🚀
आप भविष्य का अनुमान नहीं लगा सकते, लेकिन आप लचीलापन बना सकते हैं। ओवर-इंजीनियरिंग बुरी बात है, लेकिन बदलाव के लिए डिज़ाइन करना बुद्धिमानी है।
विस्तार्य डिज़ाइन पैटर्न
- ईएवी (एंटिटी-एट्रिब्यूट-वैल्यू): बहुत अधिक चर डेटा के लिए उपयोगी, हालांकि इससे प्रश्न प्रदर्शन की कमी होती है।
- JSON कॉलम: आधुनिक डेटाबेस JSON प्रकार का समर्थन करते हैं। इससे आप तालिका संरचना को बदले बिना लचीले लक्षण स्टोर कर सकते हैं।
- टैगिंग प्रणाली: विशिष्ट लक्षणों को हार्डकोड करने के बजाय मेटाडेटा के लिए बहु-से-बहु संबंध का उपयोग करें।
निगरानी और ऑडिट
- स्कीमा परिवर्तनों का ट्रैक रखें। किसने क्या और कब बदला?
- डेटा वृद्धि प्रवृत्तियों का मॉनिटर करें। यदि एक टेबल प्रति महीने 50% बढ़ती है, तो इसकी गति धीमी होने से पहले पार्टीशनिंग की योजना बनाएं।
- प्रतिबंध उल्लंघन के लिए चेतावनियां सेट करें।
अनुकूलता पर निष्कर्ष 🔄
एक एरडी के विकास का आवेश एप्लिकेशन की परिपक्वता का प्रतिबिंब है। यह लचीलापन से अखंडता और फिर प्रदर्शन की ओर बढ़ता है। प्रत्येक चरण नए चुनौतियों को लेकर आता है। मुख्य बात यह है कि इन परिवर्तनों की भविष्यवाणी करें और उन्हें जानबूझकर प्रबंधित करें।
एकमात्र “आदर्श” मॉडल नहीं है। केवल वह मॉडल है जो आपकी वर्तमान सीमाओं और वृद्धि के मार्ग के अनुरूप है। नॉर्मलाइजेशन, डीनॉर्मलाइजेशन और आर्किटेक्चरल पैटर्न के बीच व्यापार के बारे में समझने से आप यह सुनिश्चित कर सकते हैं कि आपकी डेटा परत आपके व्यवसाय को वर्षों तक समर्थन देगी।
- सरल शुरुआत करें, लेकिन संरचना के लिए योजना बनाएं।
- अखंडता के लिए नॉर्मलाइज़ करें, गति के लिए डीनॉर्मलाइज़ करें।
- हर परिवर्तन का दस्तावेज़ीकरण करें।
- माइग्रेशन का कड़ाई से परीक्षण करें।
आपका डेटा आपकी सबसे मूल्यवान संपत्ति है। उस मॉडल के साथ उसके योग्य देखभाल करें जो इसे रखता है।