











एक विश्वसनीय डेटाबेस डिज़ाइन करने के लिए डेटा संरचनाओं का स्पष्ट नक्शा आवश्यक है। एक एंटिटी-रिलेशनशिप डायग्राम (ERD) इस ब्लूप्रिंट के रूप में कार्य करता है, जो एक प्रणाली के भीतर डेटा के कैसे जुड़ने का दृश्य प्रस्तुत करता है। स्केलेबल समाधान बनाने के लिए मूल घटकों—एंटिटी, गुण और संबंधों को समझना आवश्यक है। यह मार्गदर्शिका इन तत्वों का गहन अध्ययन करती है, जिससे डेटाबेस आर्किटेक्चर के लिए एक मजबूत आधार सुनिश्चित होता है।
🏗️ एक ERD क्या है?
एक ERD डेटाबेस की संरचना का दृश्य प्रतिनिधित्व है। यह डेटा तत्वों और उनके बीच के जुड़ाव को चिह्नित करता है। इसे एक इमारत के आर्किटेक्चरल योजना के रूप में सोचें, जहां डेटाबेस संरचना है और डेटा निवासी हैं। यह अमूर्त व्यापार आवश्यकताओं और वास्तविक तकनीकी कार्यान्वयन के बीच के अंतर को पार करता है।
मुख्य लाभ शामिल हैं:
- स्पष्टता:हितधारक कोड लिखे बिना डेटा प्रवाह को देखने में सक्षम होते हैं।
- सुसंगतता:यह सुनिश्चित करता है कि पूरी प्रणाली में डेटा नियम समान रूप से लागू हों।
- कार्यक्षमता:डिज़ाइन की कमियों को जल्दी पकड़कर विकास चरण के दौरान त्रुटियों को कम करता है।
- संचार:डेवलपर्स, विश्लेषकों और व्यापार मालिकों के लिए एक सामान्य भाषा प्रदान करता है।
🔑 घटक 1: एंटिटी
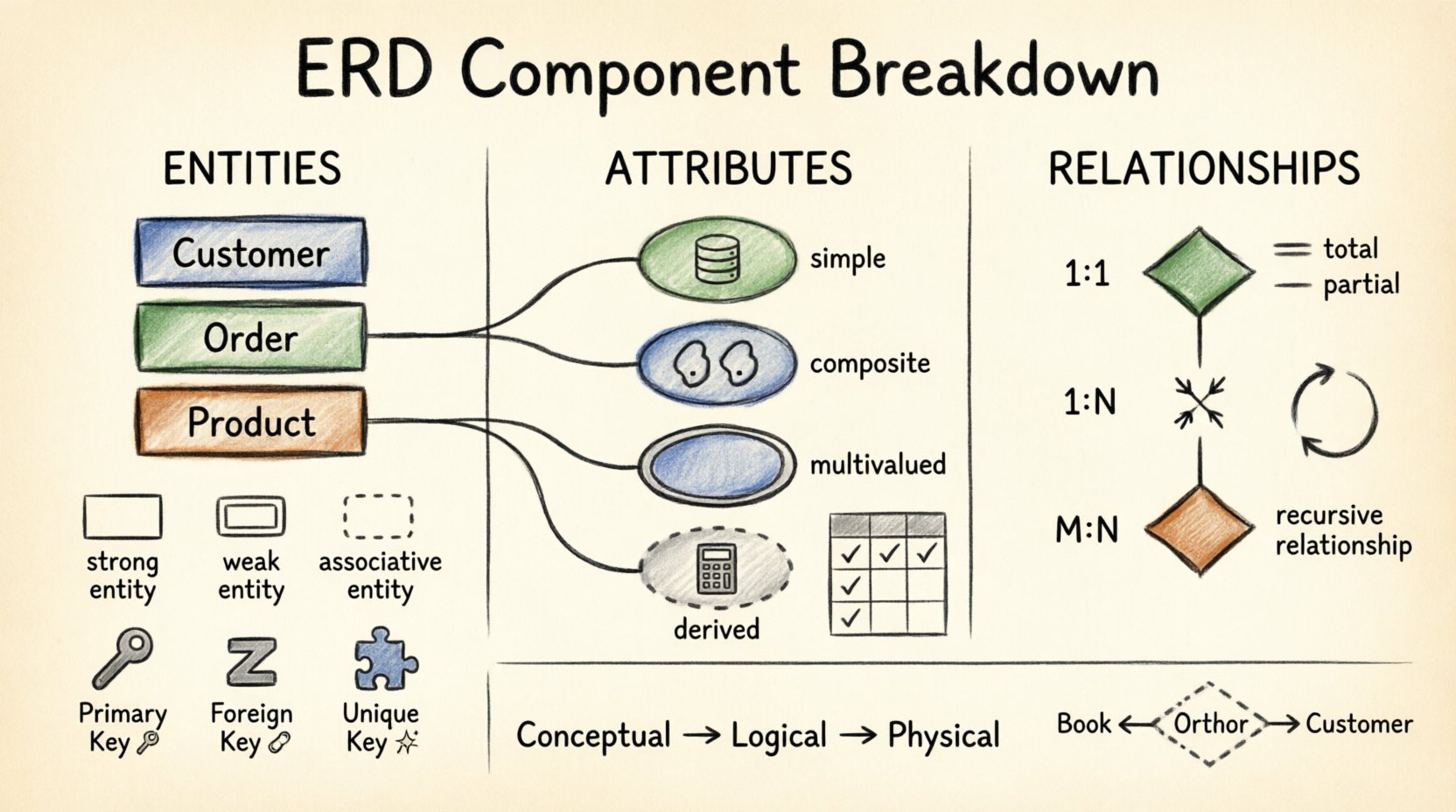
एंटिटी वास्तविक दुनिया की वस्तुओं या अवधारणाओं का प्रतिनिधित्व करती हैं जिन्हें डेटाबेस में संग्रहीत करने की आवश्यकता होती है। वे मॉडल के मूल निर्माण तत्व हैं। प्रत्येक एंटिटी को अलग और पहचानने योग्य होना चाहिए।
1.1 एंटिटी को परिभाषित करना
एक एंटिटी आमतौर पर एक संज्ञा होती है, जैसेग्राहक, आदेश, याउत्पाद। आरेख में, उन्हें आमतौर पर आयत के रूप में दर्शाया जाता है। प्रत्येक एंटिटी समान वस्तुओं के संग्रह का प्रतिनिधित्व करती है।
1.2 एंटिटी के प्रकार
सभी एंटिटी एक ही तरीके से काम नहीं करती हैं। उनके बीच अंतर करना जटिल परिदृश्यों के मॉडलिंग में मदद करता है।
- स्ट्रॉंग (नियमित) एंटिटी: ये स्वतंत्र रूप से अस्तित्व में हैं। उनके अपने प्राथमिक कुंजी होती है और उनके अस्तित्व के लिए किसी अन्य एंटिटी पर निर्भर नहीं होती हैं।
- दुर्बल एंटिटी: इनका पहचान के लिए एक स्ट्रॉंग एंटिटी पर निर्भरता होती है। वे माता-पिता एंटिटी के बिना अस्तित्व में नहीं आ सकती हैं। उन्हें आमतौर पर डबल आयत के रूप में दर्शाया जाता है।
- संयोजक एंटिटी: ये बहु-से-बहु संबंधों को दो एक-से-बहु संबंधों में तोड़कर हल करते हैं। वे दोनों संबंधित एकताओं से विदेशी कुंजियों वाली ब्रिज तालिका के रूप में कार्य करते हैं।
1.3 प्रतिनिधित्व की पहचान
प्रत्येक प्रतिनिधित्व को एक अद्वितीय पहचानकर्ता होना चाहिए। इसके बिना, दो रिकॉर्डों के बीच अंतर करना असंभव हो जाता है। आम रणनीतियाँ इस प्रकार हैं:
- एक प्रणाली-उत्पन्न आईडी का उपयोग करना (उदाहरण के लिए, UUID).
- एक प्राकृतिक कुंजी का उपयोग करना (उदाहरण के लिए, सामाजिक सुरक्षा संख्या, ISBN).
- एक संयुक्त कुंजी का उपयोग करना (बहुत अभिलक्षणों के संयोजन के रूप में)।
📝 घटक 2: गुण
गुण वे गुण होते हैं या विशेषताएँ जो किसी प्रतिनिधित्व का वर्णन करती हैं। यदि प्रतिनिधित्व एक व्यक्ति है, तो गुण उनका नाम, उम्र और पता होते हैं। इन्हें आमतौर पर प्रतिनिधित्व आयत से जुड़े गोलाकार आकृतियों द्वारा दर्शाया जाता है।
2.1 गुणों का वर्गीकरण
गुणों में जटिलता और कार्य के मामले में भिन्नता होती है। इन श्रेणियों को समझना नॉर्मलाइजेशन और प्रश्न अनुकूलन में मदद करता है।
- सरल गुण:परमाणु मान जो आगे विभाजित नहीं किए जा सकते। उदाहरण:उम्र या रंग.
- संयुक्त गुण: अन्य गुणों में विभाजित किया जा सकता है। उदाहरण:पता को विभाजित किया जा सकता हैसड़क, शहर, और पिन कोड.
- बहु-मूल्य गुण: एक प्रतिनिधित्व के इस गुण के लिए एक से अधिक मान हो सकते हैं। उदाहरण:फ़ोन नंबर या शैक्षिक डिग्रियाँ. इन्हें अक्सर डबल ओवल द्वारा दर्शाया जाता है।
- व्युत्पन्न गुण: अन्य गुणों से गणना की गई है। उदाहरण: उम्र से व्युत्पन्न किया जा सकता हैजन्म तिथि. इन्हें आमतौर पर स्थान बचाने के लिए भौतिक रूप से संग्रहीत नहीं किया जाता है।
2.2 मुख्य गुण
कुछ गुण डेटा अखंडता में विशिष्ट भूमिका निभाते हैं। एक तालिका मुख्य प्रकारों का सारांश प्रस्तुत करती है:
| की प्रकार | कार्य | उदाहरण |
|---|---|---|
| प्राथमिक की | तालिका में प्रत्येक रिकॉर्ड की विशिष्ट पहचान करता है। | ग्राहकआईडी |
| विदेशी की | प्राथमिक की के माध्यम से एक तालिका को दूसरी तालिका से जोड़ता है। | आदेशआईडी (आदेशवस्तुओं में) |
| एकल की | कोई दोहराव वाले मान नहीं होने देता है, लेकिन NULL की अनुमति देता है। | ईमेल पता |
| उम्मीदवार की | कोई भी गुण जो प्राथमिक की के रूप में कार्य कर सकता है। | एसएसएन, पासपोर्ट संख्या |
2.3 नॉल बनाम नॉट नॉल
सीमांकन निर्धारित करते हैं कि क्या एक गुण में डेटा होना आवश्यक है। एक नॉट नॉल सीमांकन डेटा उपस्थिति सुनिश्चित करता है, जो प्राथमिक की के लिए महत्वपूर्ण है। नॉल मान अनुपलब्ध या अज्ञात डेटा को इंगित करते हैं, जिसके लिए एप्लिकेशन लॉजिक में सावधानीपूर्वक निपटारा करने की आवश्यकता होती है।
🔗 घटक 3: संबंध
संबंध निर्धारित करते हैं कि एकता कैसे एक दूसरे के साथ बातचीत करती हैं। वे डेटा बिंदुओं को जोड़ने वाले व्यावसायिक तर्क का वर्णन करते हैं। एक एरडी में, संबंध एकता के आयतों को जोड़ने वाले हीरे के रूप में दिखाए जाते हैं।
3.1 कार्डिनैलिटी
कार्डिनैलिटी एक एकता के उन उदाहरणों की संख्या निर्दिष्ट करती है जो दूसरी एकता के उदाहरणों से संबंधित होते हैं। यह संबंध मॉडलिंग का सबसे महत्वपूर्ण पहलू है।
- एक-से-एक (1:1): एकता A का एक उदाहरण एकता B के ठीक एक उदाहरण से संबंधित होता है। उदाहरण: व्यक्ति से पासपोर्ट.
- एक-से-बहुत (1:N): एकता A का एक उदाहरण एकता B के कई उदाहरणों से संबंधित होता है। उदाहरण: विभाग से कर्मचारी.
- बहुत-से-बहुत (M:N): एकता A के कई उदाहरण एकता B के कई उदाहरणों से संबंधित होते हैं। उदाहरण: छात्र से पाठ्यक्रम. इसके लिए एक सह-संबंधित एकता की आवश्यकता होती है।
3.2 भागीदारी सीमाएँ
भागीदारी निर्धारित करती है कि क्या एक एकता किसी संबंध में शामिल होना आवश्यक है। इसे अक्सर अस्तित्व निर्भरता कहा जाता है।
- पूर्ण भागीदारी: किसी एकता का प्रत्येक उदाहरण संबंध में भाग लेना चाहिए। इसे डबल लाइन द्वारा दर्शाया जाता है। उदाहरण: प्रत्येक आदेश कम से कम एक के साथ होना चाहिए ग्राहक.
- आंशिक भागीदारी: कुछ उदाहरण भागीदारी नहीं कर सकते हैं। एक रेखा द्वारा दर्शाया जाता है। उदाहरण: एक कर्मचारी के पास अभी एक पति/पत्नी रिकॉर्ड नहीं है।
3.3 संबंध प्रकार
कार्डिनैलिटी से आगे, संबंधों को उनकी प्रकृति के आधार पर वर्गीकृत किया जा सकता है।
| प्रकार | विवरण | उदाहरण |
|---|---|---|
| पहचानकर्ता | दुर्बल संस्था अपनी पहचान के लिए मजबूत संस्था पर निर्भर होती है। | बच्चा माता-पिता पर निर्भर है |
| गैर-पहचानकर्ता | संबंध मौजूद है, लेकिन बच्चे के पास अपनी स्वतंत्र पहचान है। | प्रबंधक कर्मचारी का प्रबंधन करता है |
| पुनरावृत्तिक | एक संस्था स्वयं से संबंधित होती है। | कर्मचारी कर्मचारी के निरीक्षण करता है |
📊 घटक 4: नोटेशन शैलियाँ
जब तक तर्क एक ही रहता है, दृश्य प्रस्तुतीकरण भिन्न होता है। सामान्य शैलियों को जानना अलग-अलग टीमों द्वारा बनाए गए आरेखों को पढ़ने में मदद करता है।
4.1 क्राउ के पंख नोटेशन
यह सबसे अधिक उपयोग की जाने वाली शैली है। इसमें कार्डिनैलिटी को दर्शाने के लिए रेखा, वृत्त और क्राउ का पंख (तीन रेखाएँ) जैसे प्रतीकों का उपयोग किया जाता है।
- एक रेखा:अनिवार्य एक।
- वृत्त:वैकल्पिक (शून्य)।
- क्राउ का पंख: कई।
4.2 चेन नोटेशन
पीटर चेन के नाम पर रखा गया, जिन्होंने ईआरडी का निर्माण किया। इसमें प्राथमिकता के लिए आयत, संबंधों के लिए हीरे और गुणों के लिए अंडाकार का उपयोग किया जाता है। यह अधिक अमूर्त है और अक्सर शैक्षणिक संदर्भों में उपयोग किया जाता है।
4.3 यूएमएल क्लास डायग्राम
एकीकृत मॉडलिंग भाषा आरेख समान अवधारणाओं का उपयोग करते हैं, लेकिन ऑब्जेक्ट-ओरिएंटेड प्रोग्रामिंग के लिए अनुकूलित हैं। इनमें दृश्यता संकेतक (+, -, #) और विधियों की सूची शामिल है।
🛠️ घटक 5: सामान्यीकरण और ईआरडी
सामान्यीकरण डेटा को व्यवस्थित करने की प्रक्रिया है जिससे अतिरिक्तता कम होती है और अखंडता में सुधार होता है। ईआरडी इस प्रक्रिया का दृश्य निर्गम है।
5.1 प्रक्रिया
- पहला सामान्य रूप (1NF): परमाणु मान सुनिश्चित करें। कोई भी दोहराए जाने वाले समूह नहीं।
- दूसरा सामान्य रूप (2NF): आंशिक निर्भरता हटाएं। सभी गैर-कुंजी विशेषताओं को पूर्ण मुख्य कुंजी पर निर्भर होना चाहिए।
- तीसरा सामान्य रूप (3NF): स्थानांतरित निर्भरता हटाएं। गैर-कुंजी विशेषताओं को अन्य गैर-कुंजी विशेषताओं पर निर्भर नहीं होना चाहिए।
5.2 डिजाइन पर प्रभाव
सामान्यीकरण अक्सर तालिकाओं की संख्या बढ़ाता है। यह डेटा अखंडता में सुधार करता है, लेकिन प्रश्नों को जटिल बना सकता है। ईआरडी इस विकल्प को दृश्य रूप से दिखाता है, जहां जॉइन की आवश्यकता होती है पूरी जानकारी प्राप्त करने के लिए।
⚠️ सामान्य त्रुटियाँ
यहां तक कि अनुभवी डिजाइनर भी गलतियां करते हैं। सामान्य त्रुटियों के बारे में जागरूकता भविष्य के तकनीकी ऋण को रोकती है।
- अस्पष्ट नाम: जैसे शब्दों का उपयोग करना डेटा या जानकारी मॉडल को समझने में कठिनाई होती है। जैसे विशिष्ट संज्ञाओं का उपयोग करें लॉग लेनदेन.
- कार्डिनैलिटी का अभाव: यह भूल जाना कि किसी संबंध को वैकल्पिक या अनिवार्य बनाया गया है, डेटा अखंडता की समस्याओं का कारण बनता है।
- चक्रीय निर्भरता: एंटिटी ए बी पर निर्भर है, और बी ए पर निर्भर है। इससे एक तार्किक लूप बनता है जिसे डेटाबेस इंजन समाधान नहीं कर सकते।
- अत्यधिक सामान्यीकरण: बहुत सारे टेबल बनाने से प्रश्न पूछने में धीमा हो सकता है। सामान्यीकरण को प्रदर्शन की आवश्यकताओं के साथ संतुलित करें।
- व्यापार नियमों को नजरअंदाज करना: एक आरेख जो संरचनात्मक रूप से पूर्ण लगता है, वह तब विफल हो सकता है यदि वह वास्तविक व्यापार सीमाओं को दर्शाता नहीं है।
🚀 बेस्ट प्रैक्टिसेज
मानकों का पालन करने से रखरखाव और सहयोग सुनिश्चित होता है।
6.1 नामकरण प्रणाली
सुसंगतता महत्वपूर्ण है। सभी नामों के लिए एक मानक प्रारूप का उपयोग करें।
- बहुवचन बनाम एकवचन: एक चुनें और उस पर टिके रहें। (उदाहरण के लिए, ग्राहक बनाम ग्राहक).
- अंडरस्कोर: उपयोग करें स्नेक_केस डेटाबेस कॉलम के लिए (उदाहरण के लिए, ग्राहक_आईडी).
- अर्थपूर्ण पूर्वपद: टेबल प्रकार को इंगित करें (उदाहरण के लिए, टेबल_ या डिम_).
6.2 दस्तावेजीकरण
एक ईआरडी एक स्वतंत्र उत्पाद नहीं है। इसे संदर्भ की आवश्यकता होती है।
- प्रत्येक गुण को समझाने वाला डेटा शब्दकोश शामिल करें।
- सीमाओं के पीछे व्यापार नियमों को दस्तावेजीकृत करें।
- आरेखों को संस्करण नियंत्रण करें ताकि समय के साथ परिवर्तनों को ट्रैक किया जा सके।
6.3 समीक्षा चक्र
सहकर्मी समीक्षा के बिना कभी डिज़ाइन को अंतिम नहीं बनाएं।
- तकनीकी समीक्षा: सामान्यीकरण और कुंजी अखंडता के लिए जांच करें।
- व्यावसायिक समीक्षा: सुनिश्चित करें कि मॉडल वास्तविक दुनिया के कार्यप्रवाह के अनुरूप हो।
- प्रदर्शन समीक्षा: इंडेक्सिंग रणनीतियों और जॉइन की जटिलता का आकलन करें।
🔍 व्यावहारिक उदाहरण
एक ऑनलाइन पुस्तकालय के बारे में सोचें। मुख्य संस्थाएं होंगी पुस्तक, लेखक:, और ग्राहक.
- पुस्तक: गुण शामिल हैं ISBN (प्राथमिक कुंजी), शीर्षक, और मूल्य।
- लेखक: गुण शामिल हैं लेखक क्रमांक (प्राथमिक कुंजी) और नाम।
- संबंध: एक पुस्तक के कई लेखक हो सकते हैं (बहुत-से-से-बहुत)। एक लेखक कई पुस्तकें लिख सकता है।
- निर्णय: एक सहयोगी संस्था बनाएं पुस्तक_लेखक जिसमें ISBN और लेखक क्रमांक शामिल हैं।
इस संरचना के कारण प्रत्येक पुस्तक के लिए लेखक की जानकारी की दोहराव किए बिना लचीले डेटा दर्ज करने की अनुमति मिलती है।
📈 मॉडल का विकास
डेटाबेस डिज़ाइन अपने आप बहुत कम निरंतर होते हैं। जैसे ही व्यावसायिक आवश्यकताएं बदलती हैं, एरडी को विकसित होना चाहिए।
- अवधारणात्मक मॉडल: रुचि रखने वाले लोगों के लिए उच्च स्तरीय दृश्य। तकनीकी विवरणों के बिना एकताओं और संबंधों पर ध्यान केंद्रित करता है।
- तार्किक मॉडल: विशेषताओं और कुंजियों को जोड़ता है। डेटा प्रकारों और संबंधों को सटीक रूप से परिभाषित करता है।
- भौतिक मॉडल: एक विशिष्ट डेटाबेस इंजन के लिए अनुकूलित। सूचकांकों, विभाजन और भंडारण विवरण शामिल हैं।
इन चरणों के बीच संक्रमण के लिए ध्यान से मान्यता प्राप्त करने की आवश्यकता होती है ताकि जीवनचक्र के दौरान डेटा अखंडता बनी रहे।
🧩 उन्नत अवधारणाएँ
जटिल प्रणालियों के लिए, मानक एरडी को विस्तार की आवश्यकता हो सकती है।
7.1 सुपरप्रकार और उपप्रकार
सामान्यीकरण और विशिष्टीकरण विरासत की अनुमति देते हैं। एक वाहन एकता को विशिष्ट रूप से कार और ट्रक। इससे सामान्य विशेषताओं के लिए अतिरेक कम होता है, जबकि उपप्रकारों के लिए अद्वितीय विशेषताओं की अनुमति देता है।
7.2 संग्रहण
जब संबंध को एक एकता के रूप में व्यवहार करने की आवश्यकता होती है। उदाहरण के लिए, एक परामर्श एक डॉक्टर और एक रोगी के लिए अपनी विशेषताएँ होती हैं जैसे तारीख और निदान.
7.3 त्रिकोणीय संबंध
तीन संस्थाओं वाले संबंध। संभव है, लेकिन वे अक्सर संबंधात्मक डेटाबेस में लागू करने में कठिन होते हैं। द्विआधारी संबंधों में विघटन को आमतौर पर प्राथमिकता दी जाती है।
🔍 निष्कर्ष
एक एंटिटी-रिलेशनशिप डायग्राम के घटकों को समझना प्रभावी डेटा प्रबंधन के लिए मूलभूत है। स्पष्ट रूप से एंटिटी, गुण और संबंधों को परिभाषित करके टीमें ऐसे प्रणालियां बना सकती हैं जो दोनों तरीकों से मजबूत और लचीली हों। डिजाइन चरण के दौरान विवरण पर ध्यान देने से विकास और रखरखाव चरणों में लाभ मिलता है। नियमित समीक्षा और बेस्ट प्रैक्टिस का पालन करने से यह सुनिश्चित होता है कि डेटाबेस संगठन के लिए एक विश्वसनीय संपत्ति बनी रहे।
जैसे-जैसे डेटा के आयतन में वृद्धि होती है, सटीक मॉडलिंग की आवश्यकता बढ़ती है। इन मूल अवधारणाओं को समझने में समय निवेश करने से डेटाबेस आर्किटेक्चर में लंबे समय तक सफलता सुनिश्चित होती है।