











データモデリングは、関係やエンティティを定義する静的な作業と見なされることが多い。しかし、エンティティ関係図(ERD)は単なるストレージ用の図面ではない。データベースエンジンが情報の取得や操作をどれだけ効率的に行うかを直接決定するものである。描かれた1本の線、定義された1つの関係、選択された1つのデータ型が、クエリの実行計画にまで波及する。スキーマ設計のメカニズムを理解することで、負荷がかかる状況でもスムーズにスケーリングできるシステムを構築できる。
このガイドでは、ERDの構造とクエリパフォーマンスの技術的関係を検討する。基本的な定義を越えて、特定のモデリングの決定がリレーショナル環境内でのI/O操作、CPU使用率、ロックメカニズムにどのように影響するかを検証する。
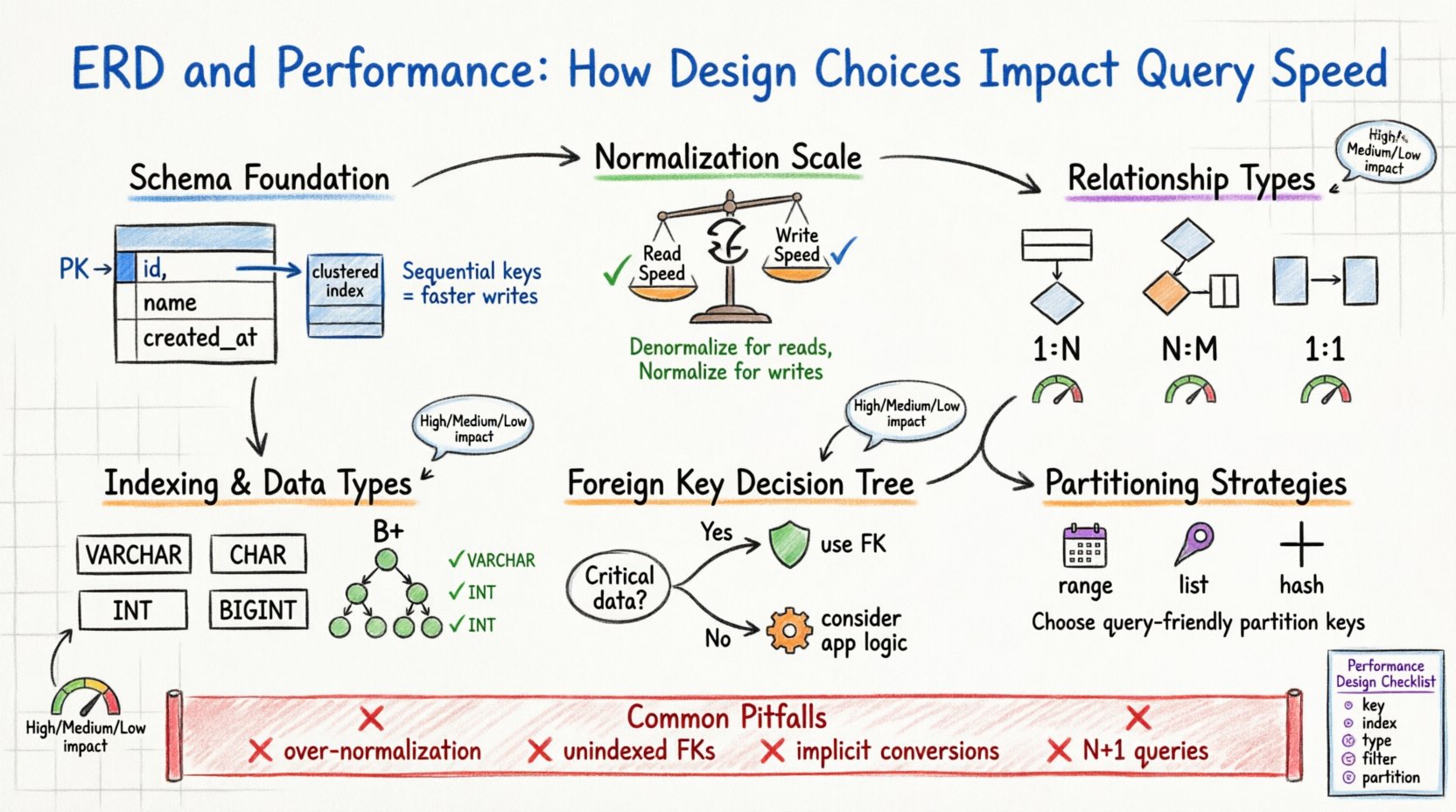
1. 基盤:スキーマ構造と物理的ストレージ 🏗️
ERDで作成する論理設計は、最終的にディスク上の物理ファイルに変換される。データベースエンジンは、これらの論理的エンティティをページ、ブロック、行にマッピングしなければならない。スキーマが最適化されていると、エンジンはリクエストを満たすために必要なディスク読み取り回数を最小限に抑えることができる。逆に最適化されていないと、エンジンはフルテーブルスキャンを強制され、これは高コストな操作となる。
プライマリキーを検討しよう。これは行の固有識別子として機能する。多くのストレージエンジンでは、プライマリキーがディスク上のデータの物理的順序を定義している(クラスタ化インデックス)。連続的で短いプライマリキーを選択することで、データが連続して格納される。これによりフラグメンテーションが減少し、範囲スキャンが高速化される。逆に、ランダムで長いプライマリキーは挿入時にページ分割を引き起こし、書き込みパフォーマンスを低下させ、ストレージのオーバーヘッドを増加させる。
プライマリキーの主な考慮点
- 連続性:書き込みが重いワークロードでは、自動増分整数が一般的に推奨される。
- サイズ:小さいキーは、セカンダリインデックスにポインタとして格納されるため、そのインデックスのサイズを小さくする。
- 安定性:プライマリキーは変更してはならない。プライマリキーを更新すると、関連するすべての外部キーを更新する必要があることが多い。
2. 正規化とパフォーマンスのトレードオフ ⚖️
正規化とは、冗長性を減らし、整合性を高めるためにデータを整理するプロセスである。伝統的にデータ品質に関連すると考えられていたが、パフォーマンスに大きな影響を与える。高度に正規化されたスキーマ(例:第三正規形)は、データを再構成するために多くの結合を必要とするが、逆に非正規化されたスキーマは結合を減らすが、ストレージと更新の複雑性を増加させる。
正規化するか非正規化するかの判断は、読み取り速度と書き込み速度のバランスである。読み取りが重い環境では、複雑な結合を回避することで非正規化によりクエリ時間を大幅に短縮できる。書き込みが重い環境では、正規化により複数のテーブルにまたがる行の更新回数を減らすことができる。
正規化の影響分析
| 側面 | 高度に正規化された | 非正規化された |
|---|---|---|
| 読み取りパフォーマンス | 低い(結合が必要) | 高い(単一テーブルアクセス) |
| 書き込みパフォーマンス | 高い(冗長性が少ない) | 低い(複数コピーの更新) |
| データ整合性 | 高い(唯一の真実のソース) | 低い(整合性の欠如のリスク) |
| ストレージ使用量 | 下位 | 上位 |
3. 外部キーと整合性のオーバーヘッド 🔗
外部キーは参照整合性を強制します。あるテーブルの値が別のテーブルの値と一致することを保証します。これにより孤立したレコードを防ぐことができますが、実行時のオーバーヘッドが発生します。行の挿入、更新、削除を行う際、データベースは外部キー制約を確認する必要があります。
このチェックは無料ではありません。エンジンは参照される行を特定し、存在を確認する必要があります。参照されるテーブルが大きく、外部キー列にインデックスがない場合、チェックはフルテーブルスキャンになります。さらに、親レコードを削除するには、エンジンがすべての子レコードを確認して参照が残っていないことを確認する必要があり、多くの行をロックする可能性があります。
外部キーを使用すべきタイミング
- 重要なデータ整合性: データの正確性が最重要である場合(例:金融取引)、外部キーを使用してください。
- アプリケーションロジック: アプリケーションロジックが複雑な場合、整合性をデータベースに委ねることでコードが簡素化されます。
- 小さなデータセット: 小さなテーブルではオーバーヘッドは無視できるほどです。
外部キーを避けるべきタイミング
- 高い書き込みスループット: 制約を削除することで、ロック競合を減らすことができます。
- 大規模な分析: データウェアハウスでは、パフォーマンスが厳格な整合性よりも優先されることが多いです。
- アーキテクチャのレイヤー: マイクロサービスでは、サービス境界を越えて外部キーを維持することはしばしば現実的ではありません。
4. インデックス戦略とカラムタイプ 📑
ERDは各カラムのデータ型を定義します。VARCHARとCHAR、またはINTとBIGINTの選択は、データの保存およびインデックス化に影響を与えます。より小さいデータ型は、メモリとディスクスペースをより少なく消費し、バッファプール(RAM)に多くのデータを収容できるようにします。
クエリがカラムでフィルタリングする際、データベースエンジンはインデックスに依存して行を迅速に検索します。スキーマ設計がクエリパターンと一致しない場合、インデックスは無意味になります。たとえば、WHERE句でほとんど使われないカラムにインデックスを作成するのはリソースの無駄です。
カラムタイプの最適化
- 固定長 vs. 変動長: 固定長データ(例:国コード)にはCHARを使用してフラグメンテーションを減らしてください。変動長データにはVARCHARを使用してください。
- 整数の範囲: INTで十分な場合はBIGINTを使用しないでください。小さな整数はページあたりの行数が多くなります。
- 論理値の表現: ‘Yes’/‘No’の文字列を保存するのではなく、TINYINT(1)またはBOOLEAN型を使用してください。
5. 関係の基数の影響 📊
関係の基数(1:1、1:N、N:M)は、データがどのようにリンクされるかを決定します。各関係タイプには異なるパフォーマンス特性があります。
1対多(1:N)
これは最も一般的な関係です。親テーブルは1つのレコードを保持し、子テーブルは複数のレコードを保持します。パフォーマンスは、子テーブルの外部キー列に設定されたインデックスに大きく依存します。このインデックスがなければ、親のすべての子を検索するには子テーブル全体をスキャンする必要があります。
多対多(N:M)
これには結合テーブル(関連エンティティ)が必要です。これにより、追加の間接層が加わります。N:M関係を含むクエリは通常、3つの結合(テーブルA、結合テーブル、テーブルB)を必要とします。この複雑さはCPU使用率とメモリ要件を増加させます。
1対1(1:1)
大きなテーブルを論理的なグループに分割するためによく使用されます。特定のカラムのサブセットのみが頻繁にクエリされる場合、パフォーマンスが向上する可能性があります。しかし、完全なレコードを取得するには結合のコストが追加されます。
6. パーティショニングとシャーディングの考慮事項 🗃️
データが増加すると、単一のテーブルは効率的に管理できなくなることがあります。パーティショニングにより、キー(例:日付)に基づいて大きなテーブルをより小さな管理可能な部分に分割できます。ERD設計はこれを予見する必要があります。
将来的にシャーディング(複数のサーバーに分割)されるシステムのスキーマを設計する場合、パーティショニングキーは慎重に選択する必要があります。キーはクエリで頻繁に使用されるべきであり、エンジンがリクエストを正しいシャードにルーティングできるようにするためです。クエリで使用されないキーを選択すると、システムはすべてのシャードからデータを集約しなければならず、これは遅い処理になります。
パーティショニング戦略
- 範囲パーティショニング:日付またはIDの範囲で分割する。時系列データに適している。
- リストパーティショニング:特定の値(例:地域コード)で分割する。
- ハッシュパーティショニング:データを均等に分散させ、ホットスポットを回避する。
7. 設計における一般的な落とし穴 🚫
経験豊富なアーキテクトですら、設計選択によってパフォーマンスのボトルネックを引き起こすことがあります。これらのパターンを早期に認識することで、後で高コストな再設計を防ぐことができます。
- 過剰正規化:データをあまりにも多くの小さなテーブルに分割すると、結合の複雑さが増し、キャッシュ効率が低下します。
- 選択性を無視する:選択性が低いカラム(例:性別やステータスフラグ)にインデックスを設定しても、通常はパフォーマンスが悪化します。なぜなら、オプティマイザがインデックスを無視してテーブルスキャンを行う可能性があるからです。
- 暗黙の変換:数値が期待される場合に文字列としてカラムを設計すると、クエリ中にエンジンが型変換を強制され、インデックスの使用が妨げられます。
- N+1クエリパターン:ループでデータを取得するよう促す関係の設計は、バッチ結合ではなく、サーバーを圧迫する可能性があります。
8. 未来への対応と進化 🛡️
データベースは進化します。要件は変化し、新しい機能が追加されます。柔軟性がなければ、今日パフォーマンスが良いスキーマでも、明日にはボトルネックになる可能性があります。ERDは完全な再設計なしに成長を許容できるようにするべきです。
将来フィルタリングに使用される可能性のあるカラムを追加することを検討してください。これにより行サイズがわずかに増加しますが、大きなデータセットでは構造変更が高コストになるため、後でのコストを回避できます。また、新しいインデックスを追加する影響も考慮してください。すべてのインデックスは書き込みリソースを消費します。必要なインデックスの数を最小限に抑えるようにスキーマを設計してください。
パフォーマンス向け設計チェックリスト
- プライマリキーは短く連続していますか?
- 外部キーはインデックスされていますか?
- データ型は可能な最小の有効な型になっていますか?
- 頻繁に使用されるフィルタはインデックスでカバーされていますか?
- 正規化レベルはワークロードに適していますか?
- 大規模なテーブルに対してパーティショニングを検討しましたか?
- 複雑なJSONやテキストを格納している列があり、構造化できるものがありますか?
9. 実行計画の役割 📋
最終的には、データベースエンジンがスキーマと統計情報に基づいてクエリの実行方法を決定します。ERDはエンジンが収集する統計情報に影響を与えます。たとえば、一意な値の分布を持つ列は、偏ったデータを持つ列とは異なる扱いを受けます。実行計画の仕組みを理解することで、クエリが遅くなる理由を正しく解釈できるようになります。
クエリがフルテーブルスキャンを実行している場合、インデックスが欠けているか、効率的なフィルタリングをサポートしない設計である可能性があります。多くのネストされたループを実行している場合は、簡略化できる可能性のある複雑な結合を示しています。ERDを想定されるアクセスパターンに合わせることで、エンジンが最適な実行計画に進むように導くことができます。
10. 完全性と速度のバランス ⚖️
完璧なスキーマは存在しません。すべての設計選択にはトレードオフが伴います。パフォーマンス上の問題を完全に排除することではなく、戦略的に管理することが目的です。場合によっては、データの整合性にわずかなリスクを許容すること(データベースの制約ではなくアプリケーションレベルでのチェックにより)が、極めて高い書き込みスループットを実現するための妥当なトレードオフとなります。
定期的に実際のクエリログと照らし合わせてERDを確認してください。最も遅いクエリを特定し、それらをスキーマに遡って追跡してください。このフィードバックループにより、設計がアプリケーションのニーズに合わせて適切に進化することを保証します。
影響領域の要約 📝
| 設計要素 | パフォーマンスへの影響 | 推奨事項 |
|---|---|---|
| プライマリキーの型 | 高(ストレージおよびインデックス) | 整数またはUUIDを一貫して使用する。 |
| 外部キー | 中(書き込みオーバーヘッド) | 外部キーの列にインデックスを設定する。整合性が他の場所で処理されている場合は削除する。 |
| 正規化 | 高(結合の複雑さ) | 読み込みが重いテーブルは非正規化する。 |
| データ型 | 中(メモリ使用量) | 利用可能な最も具体的な型を使用する。 |
| 基数 | 高 (結合コスト) | N:M関係の結合テーブルを最適化する。 |
エンティティ関係図を単なる論理図ではなく、パフォーマンス上のアーティファクトとして扱うことで、堅牢でスケーラブルかつ効率的なシステムを構築できます。今あなたが行う意思決定は、今後数年間、アプリケーションの挙動を決定します。