











すべてのアプリケーションはアイデアから始まる。そのアイデアにはデータの保存が必要であり、その保存には設計図が必要となる。この設計図がエンティティ関係図(ERD)である。ERDは、システムが情報をどのように理解するかを規定する基盤となる文書である。しかし、小さな小屋の設計図は高層ビルには通用しない。同様に、プロトタイプ用に設計されたデータベーススキーマは、本番環境のトラフィックや複雑なビジネスロジックの重圧に耐えられないことが多い。
ERDの進化を理解することは、技術リーダーやデータベース管理者、ソフトウェアアーキテクトにとって不可欠である。柔軟性と整合性の間のバランスを取ることが求められる。ユーザー数が増えるにつれて、データの要件も変化する。初期のモデルを永久に維持することはできない。適応しなければならない。このガイドでは、データモデルのライフサイクル、最初のコードから企業規模のアーキテクチャまでを検討する。
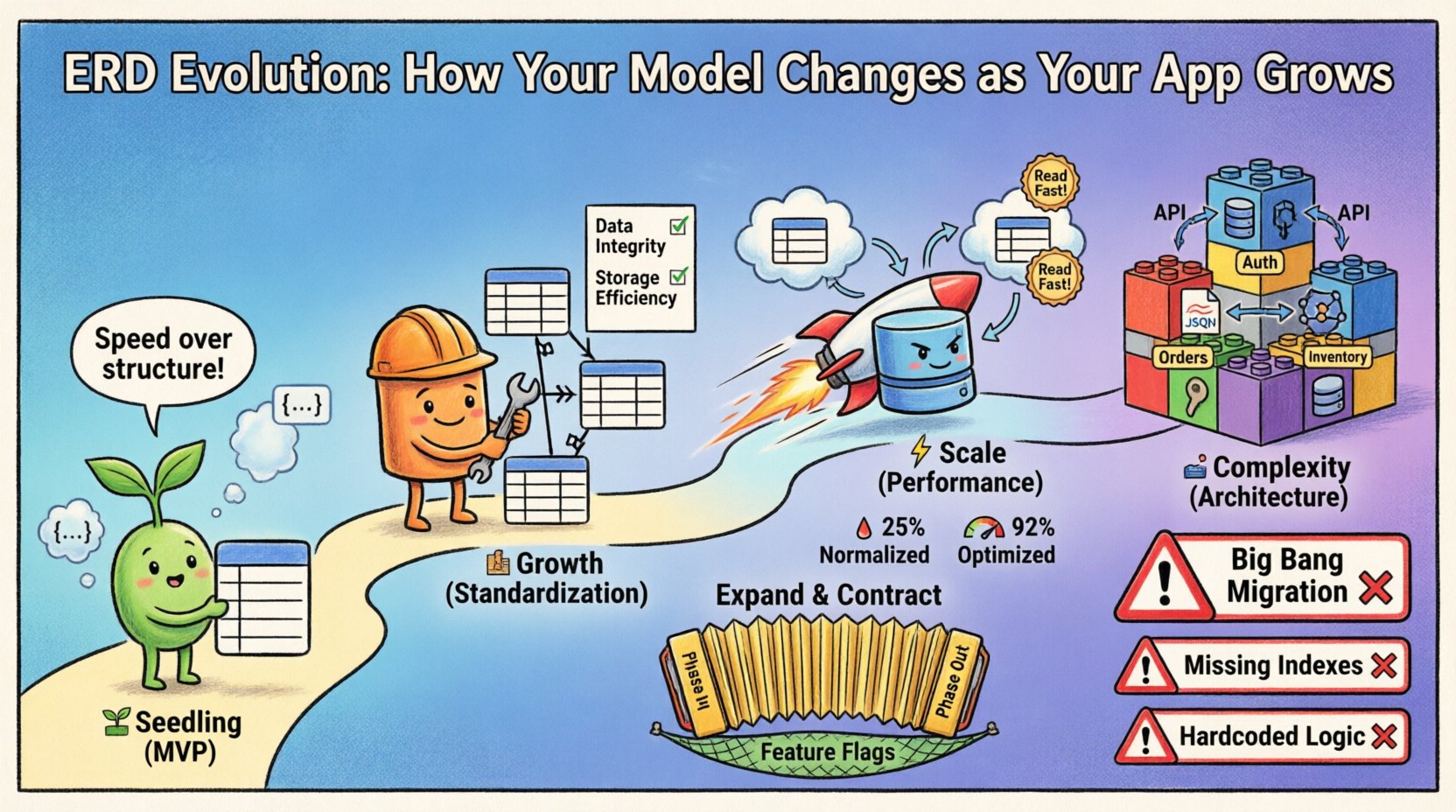
段階1:若木期(MVP) 🌱
当初はスピードが最も重要な指標となる。最小限の障害でコア仮説を検証することが目的である。この段階ではERDはしばしば流動的であり、長期的な予測ではなく、直近のニーズを反映している。
- 注力点:構造よりも機能性を優先する。
- 構造:フラットなスキーマが一般的である。関係は結合の複雑さを減らすためにしばしば非正規化される。
- 制約:外部キーが緩やかであるか、省略されて迅速な反復を可能にする。
- 変更:スキーマの変更は週に一度、場合によっては毎日行われる。
この段階では、エンティティが強く結合されている状態が見られるだろう。例えば、Userテーブルに、別々のProfileテーブルを設けず、プロフィール設定のJSONデータを含めることがある。これにより結合の必要が減り、ダッシュボードの読み取り操作が高速化される。しかし、これにより技術的負債が生じる。アプリケーションが成熟するにつれて、ネストされたデータをクエリする処理は遅くなり、保守が難しくなる。
初期段階のモデルの主な特徴
- 外部キー制約が最小限である。
- 柔軟なカラムタイプ(例:すべてにVARCHARを使用)。
- 単一のデータベースインスタンス。
- アプリケーションオブジェクトとデータベーステーブルの直接マッピング。
段階2:成長期(標準化) 🏗️
製品が一定の支持を得ると、初期の柔軟性が負担となる。データの重複は一貫性の欠如を招く。ユーザーが一つの場所でメールアドレスを更新しても、別の場所では更新しない場合、システムの信頼性が損なわれる。この段階では、正規化が優先される。
なぜ今、正規化するのか?
- データ整合性:参照整合性を強制することで、孤立レコードの発生を防ぐ。
- ストレージ効率:重複データを削除することでディスク容量を節約できる。
- 保守性:正規化されたテーブル内の単一のレコードを更新すると、論理的にすべての場所で更新されます。
- クエリの予測可能性:標準化された構造により、クエリの記述がエラーの少ないものになります。
この移行中に、ERDを再設計する必要があります。平坦なユーザーテーブルが、Users および UserDetailsに分割される可能性があります。これにより関係性が導入されます。これらが1対1、1対多、または多対多であるかどうかを明確にしなければなりません。
移行チェックリスト
- すべてのテーブル間で重複するフィールドを特定する。
- すべてのエンティティに対して主キーを定義する。
- 関係性を強制するために外部キー制約を実装する。
- 新しい結合のパフォーマンスへの影響を考慮して、既存のクエリを確認する。
- 移行中に後方互換性を考慮して計画する。
フェーズ3:スケーリング段階(パフォーマンス)⚡
数百万件のレコードが存在する場合、正規化された構造はボトルネックになることがあります。スケールすると結合は計算コストが高くなります。この段階でモデルが再び進化し、しばしば厳格な正規化からパフォーマンス向上のための戦略的非正規化へと移行します。
戦略的非正規化
これはMVP段階への後退ではありません。計算された意思決定です。大規模なテーブルでの高コストな結合を避けるために、意図的にデータを重複させます。
- 読み取り中心のワークロード: アプリケーションが主に読み取り中心の場合、スキーマ内にデータをキャッシュすることでデータベースの負荷を軽減できます。
- レポートテーブル: ダッシュボード用に事前に集計されたデータにより、リアルタイムでの合計計算を回避できます。
- パーティショニング: 日付や地域ごとにテーブルを分割するには、効率的なクエリを可能にするための特定のスキーマ設計が必要です。
比較:正規化 vs. 最適化
| 機能 | 正規化(フェーズ2) | 最適化(フェーズ3) |
|---|---|---|
| 整合性 | 高い(データベースによって強制) | アプリケーションロジックで管理 |
| 書き込み速度 | 高速 | 遅い(複数のテーブルを更新する必要がある) |
| 読み取り速度 | 遅い(結合が必要) | 高速(単一の検索) |
| ストレージ | 効率的 | 効率が悪い(冗長性) |
段階4:複雑性の段階(アーキテクチャ) 🏛️
企業レベルでは、単一のデータベースモデルはしばしば不十分である。システムはマイクロサービスに分割されるか、ポリグロット永続性を活用する。ERDはもはや単一の物理的図を表すものではなく、相互に通信するモデルの集合を表す。
マイクロサービスとデータ所有権
モノリシックアーキテクチャでは、注文テーブルは請求、配送、通知サービスによって共有される。分散システムでは、各サービスが自らのデータを所有する。これは関係性をモデル化する方法の変更を要する。
- 最終的整合性:サービス間でACIDトランザクションに頼ることはできない。ERDは状態の同期を考慮しなければならない。
- API契約:関係性は、外部キーではなくAPIの応答によって定義されることが多い。
- データ同期:異なるストア間でデータを整合性を持たせるためにツールが必要である(例:注文にはSQL、ログにはNoSQL)。
ポリグロット永続性
異なるデータには異なるストレージエンジンが必要である。ERDは非関係的コンセプトを含むように進化する。
- グラフデータ:ソーシャルネットワークやレコメンデーションエンジンでは、グラフモデルが関係データベーステーブルに取って代わる。
- ドキュメントストア:商品カタログのような柔軟なコンテンツでは、JSONドキュメントが厳格なカラムに代わる。
- キー値ストア: セッション管理およびキャッシュのため、複雑な行の代わりにシンプルなキー値ペアが使用される。
技術的詳細:正規化レベル 🔬
モデルを効果的に進化させるためには、従っているか破っているルールを理解する必要がある。正規化とは、データの重複を減らすためにデータを整理するプロセスである。
第一正規形(1NF)
- 原子値:各列には1つの値のみが含まれる。
- 繰り返しグループなし:次のような列を持てない。
color1,color2,color3. - 一意の識別子:各行は一意に識別可能でなければならない。
第二正規形(2NF)
- 1NFに準拠している必要がある。
- すべての非キー属性は、主キーに完全に依存している必要がある。
- 部分的依存関係を排除する(例:Vendor IDにのみ依存する場合、Vendor情報は別テーブルに移動する)。
第三正規形(3NF)
- 2NFに準拠している必要がある。
- 推移的依存関係が排除される。
- 列は他の非キー列に依存してはならない(例:
CityはStateに依存するのではなく、Zip Codeに依存する。CityとStateを移動する。CityおよびState~に場所テーブル。
ERDの進化における一般的な落とし穴 ⚠️
経験豊富なチームでさえ、モデルの再構築時にミスを犯すことがある。これらのパターンを認識することで、高コストなダウンタイムを回避できる。
1. 「ビッグバン」移行
一度のデプロイで全体のスキーマを変更しようとする。非常に高いリスクを伴う。移行スクリプトが失敗すれば、システムは破損する。
- 解決策: インクリメンタルな移行を使用する。カラムを追加し、データを埋め込み、ロジックを切り替え、その後古いカラムを削除する。
2. インデックスの影響を無視する
関係性の変更はクエリパターンを変える。新しい外部キー関係は、良好なパフォーマンスを発揮するために新しいインデックスを必要とする場合がある。
- 解決策: スキーマ変更の前後で、遅いクエリログを分析する。
- 解決策: インデックス作成をピーク時以外の時間帯に計画する。
3. アプリケーションロジックに制約をハードコードする
一部のチームは、データベースではなくコードでデータを検証することを好む。複数のサービスが同じストアに書き込む場合、データの破損を引き起こす。
- 解決策: アプリが分散していても、制約をデータベース層(NOT NULL、CHECK制約)に保持する。
移行戦略 🔄
ERDを進化させざるを得ない場合、ダウンタイムとデータ損失を最小限に抑える戦略が必要となる。
拡張と収縮パターン
これは安全なスキーマ進化の基準となる。
- 追加: スキーマに新しいカラムまたはテーブルを追加する。既存のロジックはまだ変更しない。
- 書き込み: アプリケーションを更新して、古い構造と新しい構造の両方に書き込むようにする。
- 読み込み: アプリケーションを更新して、新しい構造から読み込むようにする。
- バックフィル: 背景ジョブを実行して、古いデータで新しい構造を埋めます。
- 契約: 確認後、古いカラムとロジックを削除します。
機能フラグ
機能フラグを使用して、古いスキーマと新しいスキーマの間を切り替えます。これにより、ロールバックスクリプトをデプロイせずに、問題が発生した場合にすぐに元に戻すことができます。
ドキュメント化とバージョン管理 📝
ERDは一度きりの納品物ではありません。常に更新される文書です。モデルが進化するにつれて、ドキュメントもそれに合わせて更新しなければなりません。
スキーマのバージョン管理
- スキーマファイル(SQLスクリプト)をコードとして扱います。バージョン管理システムに保存してください。
- マイグレーションツールを使用して、時間の経過に伴う変更を追跡します。
- リリースにスキーマバージョンをタグ付けします(例:
v1.2.0-schema).
視覚的一貫性
- 命名規則を統一します(例:snake_case と camelCase の比較)。
- テーブル名がドメインを反映していることを確認します(例:
customerではなくt1). - ビジネスロジックの文脈を保持するために、スキーマにコメントを残します。
モデルの将来対応性の確保 🚀
未来を予測することはできませんが、柔軟性を構築することはできます。過剰設計は悪いですが、変化に備えた設計は賢明です。
拡張可能な設計パターン
- EAV(エンティティ-属性-値):非常に変動するデータに有用ですが、クエリのパフォーマンスを犠牲にします。
- JSONカラム:現代のデータベースはJSON型をサポートしています。これにより、テーブル構造を変更せずに柔軟な属性を保存できます。
- タグシステム:特定の属性をハードコードするのではなく、メタデータに多対多の関係を使用します。
監視と監査
- スキーマの変更を追跡する。誰が何を、いつ変更したか?
- データ成長の傾向をモニタリングする。テーブルのサイズが月に50%増加する場合、遅延が発生する前にパーティショニングを計画する。
- 制約違反に対してアラートを設定する。
適応性に関する結論 🔄
ERDの進化は、アプリケーションの成熟度の反映である。柔軟性から整合性へ、そしてパフォーマンスへと移行する。各段階には新たな課題が伴う。重要なのは、これらの変化を予測し、意図的に管理することである。
唯一の「完璧な」モデルは存在しない。現在の制約と成長トレンドに合ったモデルだけが存在する。正規化、非正規化、アーキテクチャパターンのトレードオフを理解することで、データレイヤーが数年先までビジネスを支えることを確実にできる。
- シンプルに始めよ。しかし、構造を計画せよ。
- 整合性のために正規化し、速度のために非正規化せよ。
- すべての変更を文書化せよ。
- 移行を徹底的にテストせよ。
あなたのデータは最も貴重な資産である。それを保持するモデルを、その価値に応じた丁寧な扱いをせよ。