











堅牢なデータベースを設計するには、データ構造の明確な地図が必要です。エンティティ関係図(ERD)は、その設計図として機能し、システム内のデータがどのようにつながっているかを可視化します。スケーラブルなソリューションを構築するためには、基本構成要素であるエンティティ、属性、関係を理解することが不可欠です。このガイドでは、これらの要素を詳しく解説し、データベースアーキテクチャの堅固な基盤を確保します。
🏗️ ERDとは何か?
ERDは、データベースの構造を視覚的に表現したものです。データ要素とそれらの相互接続関係を示します。建物の建築計画を想像してください。データベースが構造体であり、データが住民です。ERDは、抽象的なビジネス要件と具体的な技術的実装の間のギャップを埋めます。
主な利点には以下が含まれます:
- 明確性:ステークホルダーはコードを書かずにデータの流れを視覚化できます。
- 一貫性:システム全体でデータルールが一貫して適用されることを保証します。
- 効率性:設計上の欠陥を早期に発見することで、開発フェーズ中のエラーを削減します。
- コミュニケーション:開発者、アナリスト、ビジネスオーナーの間で共通の言語を提供します。
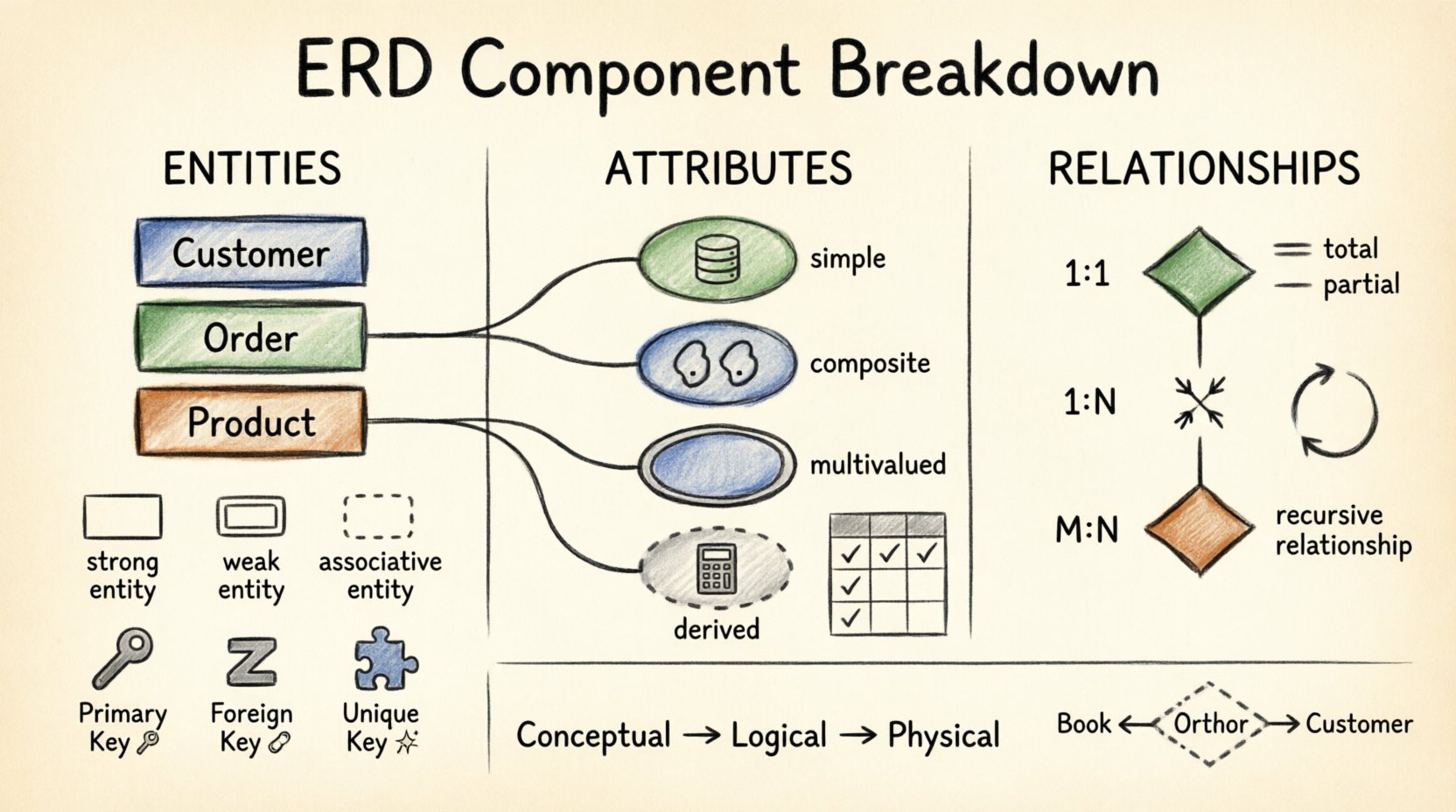
🔑 コンポーネント1:エンティティ
エンティティは、データベースに格納される必要がある現実世界のオブジェクトや概念を表します。これらはモデルの基本的な構成要素です。すべてのエンティティは明確に区別され、識別可能でなければなりません。
1.1 エンティティの定義
エンティティは通常、名詞であり、例えば顧客, 注文、または製品です。図では、通常長方形で表現されます。各エンティティは、類似したオブジェクトの集合を表します。
1.2 エンティティの種類
すべてのエンティティが同じように機能するわけではありません。それらを区別することで、複雑なシナリオのモデル化が可能になります。
- 強(通常)エンティティ: これらは独立して存在します。独自の主キーを持ち、他のエンティティに依存せずに存在できます。
- 弱エンティティ: これらはアイデンティティのために強エンティティに依存します。親エンティティがなければ存在できません。通常、二重の長方形で表現されます。
- 関連エンティティ: これらは、多対多の関係を2つの1対多の関係に分割することで解決します。両方の関連エンティティからの外部キーを含むブリッジテーブルとして機能します。
1.3 エンティティの識別
すべてのエンティティには一意の識別子が必要です。これがないと、2つのレコードを区別することが不可能になります。一般的な戦略には以下が含まれます:
- システム生成のID(例:UUID)を使用する。
- 自然キー(例:社会保障番号、ISBN)を使用する。
- 複合キー(複数の属性の組み合わせ)を使用する。
📝 コンポーネント2:属性
属性は、エンティティを説明するプロパティや特徴です。エンティティが人である場合、属性はその名前、年齢、住所です。通常、エンティティの長方形に接続された楕円で表されます。
2.1 属性の分類
属性は複雑さや機能において異なります。これらのカテゴリを理解することで、正規化やクエリ最適化が容易になります。
- 単純な属性:さらに分割できない原子的な値。例:年齢または色.
- 複合属性:他の属性にさらに分割できる。例:住所は以下に分割できる:通り名, 市区町村、および郵便番号.
- 多値属性:エンティティはこの属性に対して複数の値を持つことができます。例:電話番号または教育の学位これらの多くは二重の楕円で表されることが多い。
- 導出属性:他の属性から計算される。例:年齢は次のものから導出できる生年月日これらの情報は、スペースを節約するために通常、物理的に保存されない。
2.2 キー属性
特定の属性はデータの整合性において特定の役割を果たす。表は主なタイプを要約している:
| キーの種類 | 機能 | 例 |
|---|---|---|
| 主キー | テーブル内の各レコードを一意に識別する。 | 顧客ID |
| 外部キー | 主キーを介して、一つのテーブルを別のテーブルにリンクする。 | 注文ID(注文アイテム内) |
| 一意キー | 重複する値がないことを保証するが、NULLを許可する。 | 電子メールアドレス |
| 候補キー | 主キーとして機能できる可能性のある任意の属性。 | 社会保障番号、パスポート番号 |
2.3 NULL と NOT NULL
制約は、属性にデータが含まれる必要があるかどうかを定義する。NOT NULL制約はデータの存在を保証し、主キーにとって非常に重要である。NULL 値は欠損または不明なデータを示し、アプリケーションロジックで慎重な処理が必要です。
🔗 コンポーネント3:関係
関係は、エンティティが互いにどのように相互作用するかを定義します。データポイントを結ぶビジネスロジックを記述します。ERDでは、関係はエンティティの長方形を結ぶダイヤモンドとして表示されます。
3.1 極性
極性は、あるエンティティのインスタンスが、別のエンティティのインスタンスと関係を持つ数を指定します。これは関係モデリングにおいて最も重要な側面です。
- 1対1 (1:1):エンティティAの1つのインスタンスが、エンティティBの正確に1つのインスタンスに関連します。例:Personからパスポート.
- 1対多 (1:N):エンティティAの1つのインスタンスが、エンティティBの多数のインスタンスに関連します。例:部門から従業員.
- 多対多 (M:N):エンティティAの多数のインスタンスが、エンティティBの多数のインスタンスに関連します。例:学生からコース。これには、関連するエンティティを解決する必要があります。
3.2 参加制約
参加は、エンティティが関係に参加しなければならないかどうかを決定します。これはしばしば存在依存性と呼ばれます。
- 完全参加:エンティティのすべてのインスタンスが関係に参加しなければなりません。二重線で表されます。例:すべての注文は少なくとも1つの顧客.
- 部分参加:一部のインスタンスは参加しない可能性があります。単一の線で表されます。例:An 従業員にはまだ配偶者の記録がありません。
3.3 関係の種類
基数を超えて、関係はその性質によって分類できます。
| 種類 | 説明 | 例 |
|---|---|---|
| 識別的 | 弱いエンティティは、その識別に強いエンティティに依存します。 | 子は親に依存する |
| 非識別的 | 関係は存在しますが、子は独自の識別を持ちます。 | マネージャーが従業員を管理する |
| 再帰的 | エンティティが自分自身と関係する。 | 従業員が従業員を監督する |
📊 コンポーネント4:表記スタイル
論理は同じですが、視覚的表現は異なります。一般的なスタイルを知っていると、異なるチームが作成した図を読むのに役立ちます。
4.1 クラウズフット表記法
これは最も広く使われているスタイルです。線、円、クラウズフット(3本の線)などの記号を使って基数を表します。
- 1本の線:必須の1つ。
- 円:オプション(ゼロ)。
- クラウズフット: 多数。
4.2 チェン記法
ERDの創始者であるピーター・チェンにちなんで名付けられた。エンティティには長方形、関係には菱形、属性には楕円を使用する。より抽象的で、学術的な文脈でよく使われる。
4.3 UMLクラス図
統合モデル化言語(UML)の図は類似した概念を使用するが、オブジェクト指向プログラミングに特化している。可視性の指示子(+、-、#)とメソッドのリストを含む。
🛠️ コンポーネント5:正規化とERD
正規化とは、データの重複を減らし、整合性を高めるためにデータを整理するプロセスである。ERDはこのプロセスの視覚的出力である。
5.1 プロセス
- 第一正規形(1NF):原子的な値を確保する。繰り返しグループは存在しない。
- 第二正規形(2NF):部分的依存関係を排除する。すべての非キー属性は、完全な主キーに依存しなければならない。
- 第三正規形(3NF):推移的依存関係を排除する。非キー属性は、他の非キー属性に依存してはならない。
5.2 デザインへの影響
正規化はテーブルの数を増やす傾向がある。これによりデータの整合性は向上するが、クエリの複雑さが増すことがある。ERDはこのトレードオフを可視化し、情報を完全に取得するために結合が必要な場所を示す。
⚠️ 一般的な落とし穴
経験豊富なデザイナーですらミスをする。一般的な誤りへの意識は、将来の技術的負債を防ぐ。
- 曖昧な名前: 「データ」や「情報」といった用語を使うと、モデルが理解しにくくなる。代わりに「トランザクションログ.
- 基数の欠落:関係がオプションか必須かを定義しないと、データの整合性に問題が生じる。
- 循環依存:エンティティAがBに依存し、BがAに依存する。これにより、データベースエンジンが解決できない論理的なループが生じる。
- 過剰な正規化:あまりにも多くのテーブルを作成すると、クエリが遅くなることがあります。正規化とパフォーマンスのニーズのバランスを取ることが重要です。
- ビジネスルールを無視する:構造的に完璧に見える図であっても、実際のビジネス制約を反映していなければ失敗する可能性があります。
🚀 最良の実践方法
標準に従うことで、保守性と協働が保証されます。
6.1 名前付け規則
一貫性が鍵です。すべての名前に対して標準的なフォーマットを使用してください。
- 複数形 vs. 単数形: どちらか一方を選び、それを貫いてください。(例:Customer または Customers).
- アンダースコア: データベースのカラムには snake_case を使用してください。(例:customer_id).
- 意味のある接頭辞: テーブルの種類を示してください(例:tbl_ または dim_).
6.2 ドキュメント化
ERDは独立した成果物ではありません。文脈が必要です。
- 各属性を説明するデータ辞書を含めてください。
- 制約の背後にあるビジネスルールをドキュメント化してください。
- 図面のバージョン管理を行い、時間の経過に伴う変更を追跡する。
6.3 レビューのサイクル
同僚によるレビューなしに設計を最終化してはならない。
- 技術的レビュー:正規化とキーの整合性を確認する。
- ビジネスレビュー:モデルが現実世界のワークフローと一致していることを確認する。
- パフォーマンスレビュー:インデックス戦略と結合の複雑さを評価する。
🔍 実践例
オンライン書店を考えてみよう。主要なエンティティは書籍, 著者、および顧客.
- 書籍:属性にはISBN(主キー)、タイトル、価格が含まれる。
- 著者:属性には著者ID(主キー)と名前が含まれる。
- 関係:書籍は複数の著者を持つことができる(多対多)。著者は複数の書籍を執筆することができる。
- 解決策:関連エンティティ「書籍_著者」を作成し、ISBNと著者IDを含める。
この構造により、各書籍ごとに著者情報を重複させることなく、柔軟なデータ入力が可能になる。
📈 モデルの進化
データベース設計はほとんど常に静的ではない。ビジネス要件が変化するにつれて、ERDも進化しなければならない。
- 概念モデル:ステークホルダー向けの高レベルな視点。技術的な詳細を無視して、エンティティと関係性に焦点を当てる。
- 論理モデル:属性とキーを追加する。データ型と関係性を明確に定義する。
- 物理モデル:特定のデータベースエンジン向けに最適化される。インデックス、パーティショニング、ストレージの詳細を含む。
これらの段階間の移行には、データの整合性がライフサイクル全体にわたって維持されることを保証するために、慎重な検証が必要である。
🧩 レベルの高い概念
複雑なシステムでは、標準のERDに拡張が必要になることがある。
7.1 上位型と下位型
一般化と特殊化により継承が可能になる。車両エンティティは、自動車 および トラックこれにより、共通の属性についての冗長性が削減されるとともに、下位型に固有の属性を許可する。
7.2 集約
関係自体をエンティティとして扱う必要がある場合。たとえば、相談と医師との間の患者には、日付 および 診断.
7.3 三項関係
3つのエンティティを含む関係。可能ではあるが、リレーショナルデータベースでは実装がしばしば困難である。通常、2項関係に分解することが好まれる。
🔍 結論
エンティティ関係図の構成要素を習得することは、効果的なデータ管理の基盤である。明確にエンティティ、属性、関係を定義することで、堅牢かつ柔軟なシステムを構築できる。設計段階での細部への注意が、開発および保守段階で大きな成果をもたらす。定期的な見直しとベストプラクティスの遵守により、データベースが組織にとって信頼できる資産のままであることが保証される。
データ量が増えるにつれて、正確なモデリングの必要性が高まる。これらの基本概念を理解するための時間の投資は、データベースアーキテクチャにおける長期的成功を保証する。