











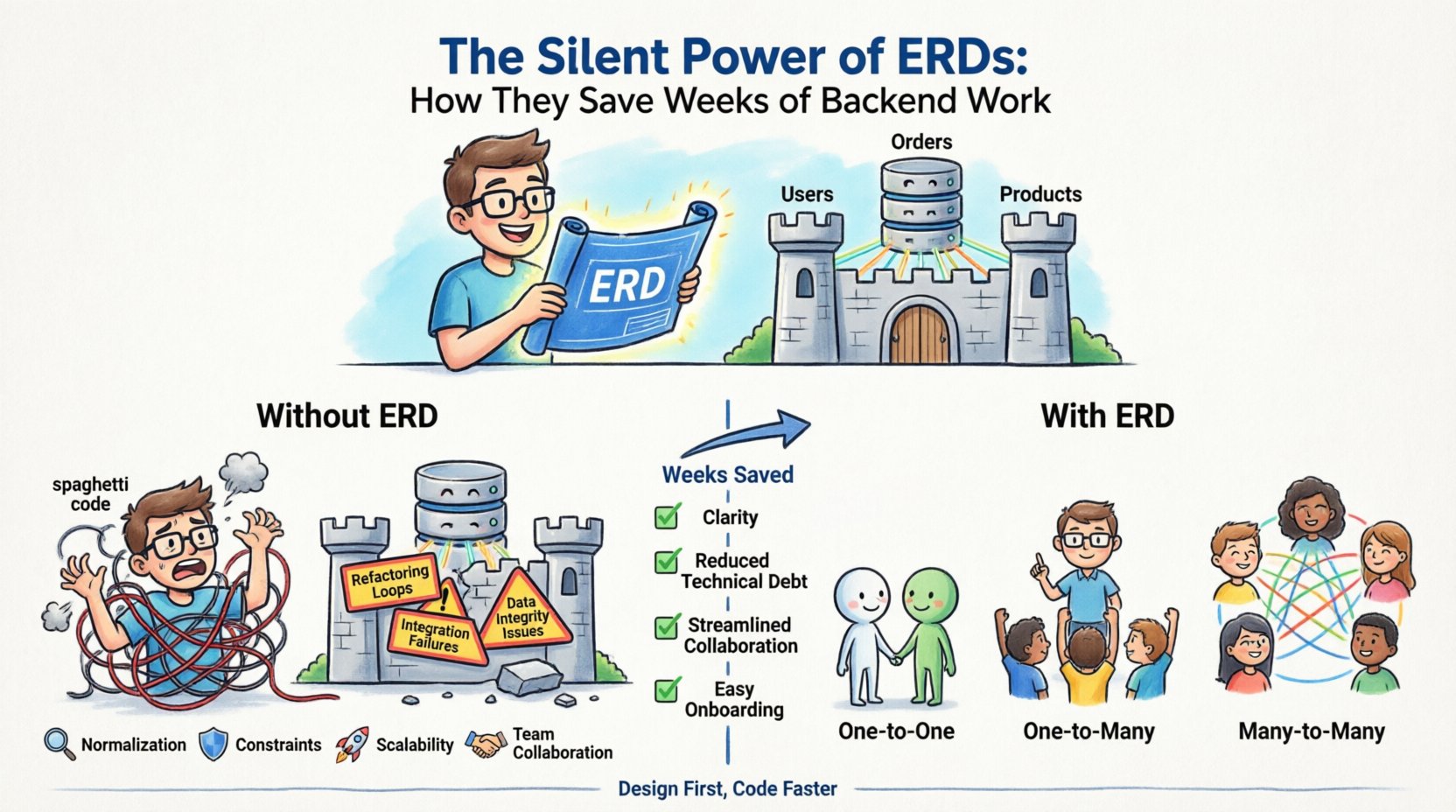
バックエンド開発は、図面のない家を建てるようなものです。直感に従ってブロックを積み、窓を設置し、壁を組み立て始めます。ときにはうまくいきますが、多くの場合、うまくいきません。数週間後、計画を忘れていたドアを設置するために、壁を壊さなければならないことに気づきます。これが、しっかりとした設計がない状態でのコーディングの現実です。エンティティ関係図(ERD)ERDは、データインフラの静かな設計者であり、コストのかかる構造的失敗を防ぐために、裏で働き続けています。コードを1行も書く前にデータモデルの設計に時間を割くことで、明確な理解が得られ、技術的負債が減り、チーム間の連携がスムーズになります。
このガイドでは、ERDがバックエンドワークフローに与える具体的な影響を検証します。データモデリングのメカニズム、設計を省略する際の隠れたコスト、そして十分に文書化されたスキーマの戦略的利点について詳しく説明します。これらの原則を理解することで、反応型のコーディングから予防的なアーキテクチャへと移行できます。
そもそもERDとは何か? 📐
エンティティ関係図(ERD)は、データベースの論理構造を視覚的に表現したものです。異なるデータの間の関係を明確にします。アプリケーションの記憶領域の地図と考えてください。この地図がなければ、開発者は目隠しで進むことになり、本来分離すべきデータポイント同士が衝突するリスクがあります。
本質的には、ERDは3つの主要な構成要素で構成されています:
- エンティティ: これらは、追跡している対象や概念を表します。データベースでは、これらはテーブルに相当します。例として、ユーザー, 注文、または製品.
- 属性: これらはエンティティの特定の属性を指します。テーブル内の列になります。たとえば、ユーザー エンティティの場合、属性にはメールアドレス, パスワードハッシュ、および作成日時.
- 関係: これらはエンティティどうしの相互作用を定義します。テーブル間の基数と接続性を決定し、たとえばユーザーが多数の注文.
概念は単純に思えるが、スケールを管理する際に複雑さが生じる。シンプルなブログであれば数個のテーブルで済むかもしれない。企業向けシステムでは、数十、あるいは数百もの相互接続されたエンティティが必要になる。ERDはこれらのすべての相互作用についての唯一の真実の源となる。
設計を飛ばす背後の隠れたコスト 💸
多くの開発チームは締切を守るためにコード作成に急ぐ。彼らは後でデータベースをリファクタリングできると仮定している。これは危険な仮定である。データベーススキーマを変更することは、アプリケーションロジックを変更するよりもはるかにコストがかかる。データが書き込まれた後は、その構造を変更するにはマイグレーションスクリプトが必要となり、ダウンタイムの可能性があり、既存のレコードを慎重に扱う必要がある。
ERDが存在しないことで摩擦を引き起こす以下の状況を検討してみよう:
- リファクタリングのループ: 機能を構築し、データ構造がそれをサポートしていないことに気づき、クエリを再書き直さなければならない。このサイクルが繰り返され、スプリント時間の何週間もを消費する。
- 統合失敗: フロントエンドとバックエンドのチームが共有されたスキーマ定義なしで作業すると、APIはしばしば破綻する。バックエンドは一つの構造を送信するが、フロントエンドは別の構造を期待している。
- データ整合性の問題: 定義された制約がないと、無効なデータがシステムに入り込む。結果として、孤立したレコードの掃除や、一貫性のない状態の手動での修正を余儀なくされる。
- オンボーディングの遅延: 新しい開発者はシステムを理解するのに苦労する。データフローが文書化されていないため、機能の開発ではなく、コードを読むことに数日を費やすことになる。
問題に気づいた頃には、コストは複数に膨らんでいる。今や「修正」にはコードの変更だけでなく、データ移行、テスト、デプロイ検証が必要となる。
プロのように関係をマッピングする 🔗
データがどのようにつながっているかを理解することは、ERD設計の核となる。関係性はクエリの書き方やパフォーマンスの最適化に影響する。明確に定義しなければならない関係性は3つの主要なタイプがある。
以下の表は、これらの関係性タイプの違いを概説している。
| 関係性の種類 | 定義 | 例のシナリオ | 実装の注意点 |
|---|---|---|---|
| 1対1(1:1) | Table Aの1つのレコードが、Table Bの正確に1つのレコードと関連する。 | ユーザー設定テーブルにリンクされたユーザーのプロフィール。 | 通常、Bの主キーをAに配置することで実装される。 |
| 1対多(1:N) | Table Aの1つのレコードが、Table Bの複数のレコードと関連する。 | 複数の製品を含むカテゴリ。 | 「多」側のテーブルに標準的な外部キーを配置する。 |
| 多対多(M:N) | テーブルAの複数のレコードが、テーブルBの複数のレコードに関連している。 | 複数の授業に登録された学生。 | リンクを解決するために、中間テーブルが必要である。 |
これらの違いを無視すると、非効率なクエリが発生する。たとえば、カテゴリの単一のカラムに製品IDのリストを保存すると、正規化の原則に違反する。これにより、結合ではなく文字列の解析を強いることになり、データが増えるにつれてパフォーマンスが低下する。
正規化:データをきれいに保つ 🧹
正規化とは、データの重複を減らし、整合性を高めるためにデータを整理するプロセスである。現代のシステムではパフォーマンスのため、厳格な正規化から逸脱することがあるが、その原則を理解することは依然として不可欠である。
正規化の標準的な形態には以下が含まれる:
- 第一正規形(1NF):原子性を保証する。各カラムには1つの値のみが含まれる。1つのセルにリストや配列は存在しない。
- 第二正規形(2NF):1NFに基づく。すべての非キー属性が主キーに完全に依存している必要がある。部分的依存は許されない。
- 第三正規形(3NF):2NFに基づく。非キー属性は主キーのみに依存し、他の非キー属性に依存してはならない。
なぜこれが重要なのか? 以下を考えてみよう:注文テーブル。注文行ごとに顧客名を保存すると、重複が生じる。顧客が名前を変更した場合、数千の行を更新しなければならない。1つでも見落とすと、データが整合性を失う。顧客名を顧客テーブルに移動し、IDでリンクすることで、唯一の真実の情報源を確保できる。
しかし、正規化が万能というわけではない。過剰な正規化は、パフォーマンスを損なう複雑な結合を引き起こす可能性がある。目標はバランスである。ストレージ効率とクエリ速度のトレードオフを理解する必要がある。
スキーマ設計における一般的な落とし穴 🚧
経験豊富な開発者ですら、ERDを設計する際にミスを犯すことがある。これらの一般的な罠を認識することで、後で大きな苦労を避けることができる。
- 循環依存:エンティティAがエンティティBを必要とし、エンティティBがエンティティAを必要とする。これにより初期化時にデッドロックが発生し、マイグレーションスクリプトの作成が難しくなる。
- 制約の欠如:外部キー、一意制約、チェック制約を定義しないと、無効なデータが見過ごされてしまう。データベースがルールを強制すべきであり、アプリケーションコードではない。
- ハードコードされた値:「active」や「inactive」などのステータスコードを、照合テーブルなしに整数として保存すると、システムが脆弱になります。もし「suspended」を追加する必要がある場合、ロジックをすべての場所で変更しなければなりません。
- ソフトデリートを無視する:データを永続的に削除すると、履歴が失われます。ソフトデリート(削除ではなく、レコードに削除済みとしてマークする)を設計することで、監査トレールを保持できます。
- 過剰設計:まだ存在しないユースケースのために設計すること。現在の要件に合わせて構築するが、妥当な成長に対応できるだけの柔軟性を持つようにする。
これらの落とし穴はすべて、コードベースに複雑性を追加します。ERDは、これらの問題が本番環境に組み込まれる前に可視化するのに役立ちます。
図から実装へ 🚀
ERDが最終確定したら、次にその図をコードに変換する段階です。このプロセスはしばしばスキーマ移行と呼ばれており、厳密な管理が必要です。
スムーズな移行を確実にするために、以下のステップに従ってください:
- バージョン管理:データベーススキーマをアプリケーションコードと同じように扱ってください。すべての変更は、リポジトリに保存されるマイグレーションファイルとして扱うべきです。
- 後方互換性:カラムを追加する際は、まずnull許容にしてください。既存データを埋め込んだ後、次のマイグレーションで制約を強制します。これによりダウンタイムを防げます。
- マイグレーションのテスト:本番環境と同一のステージング環境でマイグレーションスクリプトを実行してください。パフォーマンスの低下がないか確認してください。
- ロールバック計画:マイグレーションが失敗した場合に、いつでも元に戻せる手段を常に用意してください。データ損失は許されません。
自動化ツールはERDからSQLを生成するのを支援できますが、手動でのレビューは不可欠です。自動生成ツールは、人間のアーキテクトが見逃さないビジネスロジックの微細な点をしばしば見逃します。
協働とコミュニケーション 🤝
ERDはデータベース管理者だけのものではありません。チーム全体のコミュニケーションツールとして機能します。プロダクトマネージャー、フロントエンド開発者、QAエンジニアはすべて、データ構造を理解することで恩恵を受けます。
ステークホルダーがERDをレビューすることで、早期に潜在的な問題を発見できます:
- 機能の実現可能性:データベースは要求された機能をサポートできますか?サポートできない場合、どのような変更が必要ですか?
- パフォーマンスの期待:設計はスケーリングされた状態でも効率的なクエリを可能にしますか?
- セキュリティ要件:機密情報が特定され、保護されていますか?データレベルでのアクセス制御は可能ですか?
この共有された理解により、スプリント計画の段階での摩擦が軽減されます。データの流れを推測するのではなく、視覚的なモデルに基づいてチームが議論します。意見の相違は、図を参照して解決されるため、主観的な議論に陥りにくくなります。
スケーラビリティの考慮事項 📈
アプリケーションが成長するにつれて、データモデルも進化しなければなりません。ERDはこれらの変化を予測するのに役立ちます。新しいエンティティを追加すると既存の関係にどのような影響があるかを可視化できるようになります。
設計段階で考慮すべき重要なスケーラビリティ要因:
- インデックス戦略:頻繁にクエリされるカラムを特定してください。これらのフィールドにインデックスを計画することで、取得を高速化できます。
- パーティショニング:特定のテーブルが大きくなりすぎないか?必要に応じて水平パーティショニングを計画してください。
- 読み取り/書き込みの分離:設計が読み取り用と書き込み用のレプリカを別々にサポートしていますか?外部キーがレプリケーションを複雑にしないように確認してください。
- キャッシュレイヤー:データモデルはキャッシュシステムとどのように連携しますか?変更頻度の高いデータよりも、変更されないデータの方がキャッシュしやすいです。
スケーリングについて早期に考えることで、後で完全な再構築が必要になることを防げます。サーバー間でデータを移動するよりも、新しいテーブルを追加する方が簡単です。
データアーキテクチャについての最終的な考察 🧠
詳細なERDを作成するために費やした努力は、プロジェクトのライフサイクルを通じて大きな利益をもたらします。データモデリングを反応的な作業から戦略的資産へと変革します。関係の可視化、制約の強制、成長の計画を通じて、堅牢で保守可能なシステムを構築できます。
データベースを後回しにしないでください。それはあなたのアプリケーションの基盤です。設計段階に投資すれば、長期的には何週間分ものバックエンド作業を節約できます。ERDの静かな力は、問題が発生する前にそれを防ぐ能力にあります。
今日からデータのマッピングを始めましょう。得られる明確さは、混沌としたコードベースとスムーズなシステムとの違いを生み出します。