




堅牢なデータモデルを設計することは、単なる学術的な演習ではない。それはアプリケーションの安定性を支える基盤なのである。エンティティ関係図(ERD)は、本番環境における情報の保存、リンク、取得の仕組みを示す設計図となる。システムがスケーリングする際、不良なモデル設計のコストは指数関数的に増大する。本ガイドでは、複雑なバックエンドアーキテクチャ内でのERDの実用的実装を検討し、データ整合性、スケーラビリティ、保守性に焦点を当てる。
開発者はしばしばアプリケーションロジックに注力し、データベースを二次的な問題と見なしがちである。しかし、スキーマはシステムが効率的に実行できる範囲を決定する。現実のシナリオを分析することで、特定のソフトウェアベンダーに依存せずに、データの正規化、関係の扱い、参照整合性の確保におけるトレードオフを理解できる。
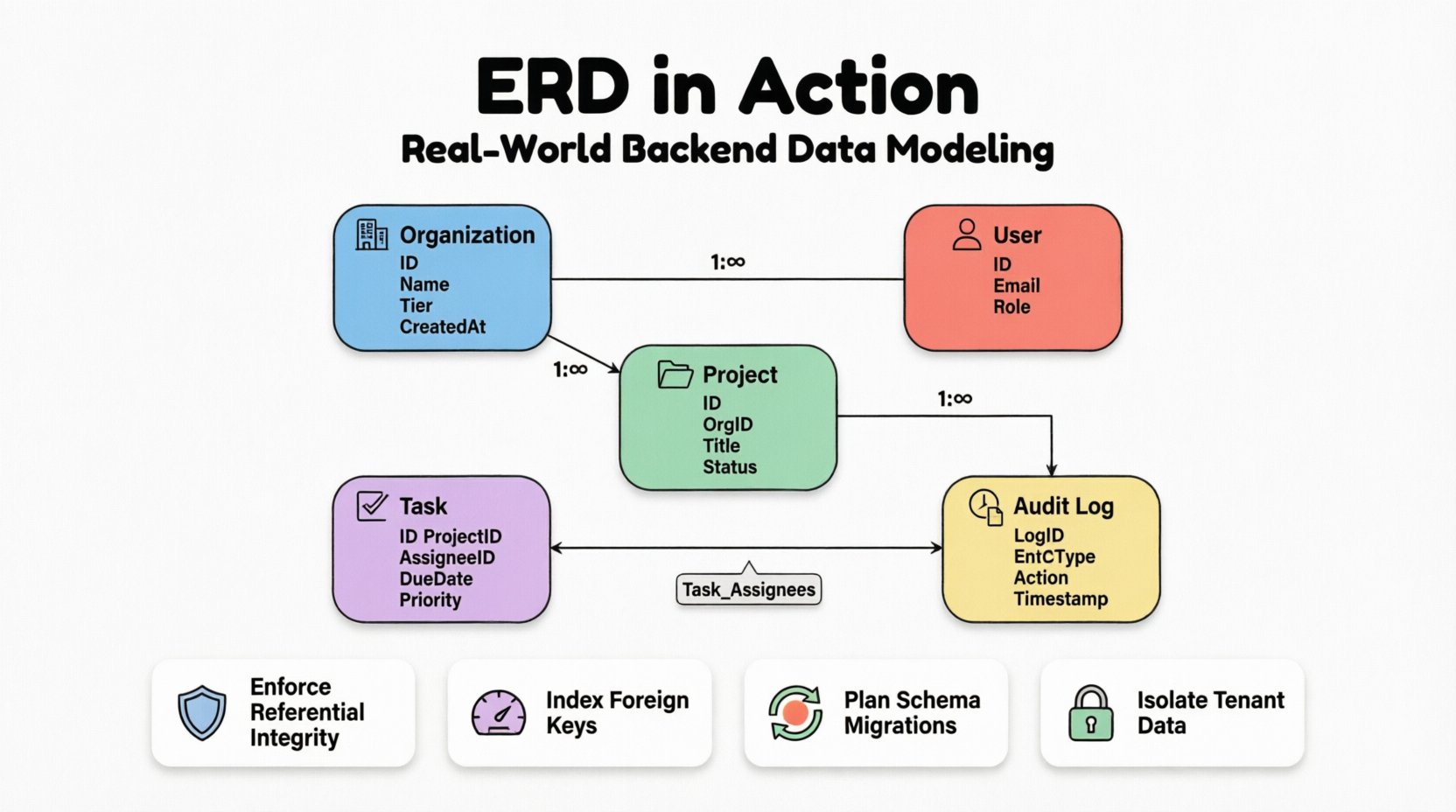
📋 業務シナリオ
複数のクライアント組織が共用するサービスプラットフォームを想定しよう。このシステムは、異なるクライアント組織間で厳密な隔離を維持しつつ、各組織内での内部的な柔軟性を許容しなければならない。主な要件は以下の通りである:
- マルチテナント:データは組織単位で分離され、セキュリティを確保しなければならない。
- 複雑なワークフロー:タスクは特定のプロジェクトに割り当てられ、追跡され、関連付けられなければならない。
- 監査ログ:レコードに対する重要な変更はすべて、コンプライアンスのためログに記録されなければならない。
- スケーラビリティ:スキーマは、クエリパフォーマンスが低下することなく、数百万件のレコードをサポートしなければならない。
課題は、これらのビジネスルールを、データ異常を防ぐ関係構造に変換することにある。よくある誤りは、過度に正規化された構造を作成し、過剰な結合を必要とさせること、または過度に非正規化された構造を作成し、データの重複や更新異常を引き起こすことである。
🔍 コアエンティティと属性
あらゆるERDの基盤はエンティティの定義にある。本ケーススタディでは、5つの主要なエンティティを特定する。各エンティティは、データベースに永続化されなければならない明確な概念を表す。これらのエンティティに関連する属性は、格納されるデータの粒度を定義する。
1. 組織エンティティ
これは階層の根幹である。他のすべてのレコードは、このエンティティにリンクされ、テナントの隔離を強制する。
- 組織ID:一意の識別子。
- 組織名:人間が読みやすいラベル。
- サブスクリプションTier:機能へのアクセスを決定する。
- 作成日時:監査用のタイムスタンプ。
2. ユーザーエンティティ
ユーザーは組織に所属するが、複数のプロジェクトのメンバーになることができる。認証情報は、セキュリティのベストプラクティスに従うために、ビジネスデータから分離されている。
- ユーザーID:一意の識別子。
- メールアドレス:認証および連絡に使用されます。
- パスワードハッシュ:資格情報のセキュアな保存先。
- 役割:権限を定義します(管理者、メンバー、閲覧者)。
3. プロジェクトエンティティ
プロジェクトは作業項目のコンテナです。組織が所有していますが、ユーザーが作業を行います。
- プロジェクトID:一意の識別子。
- 組織ID:親テナントにリンクする外部キー。
- タイトル:プロジェクトの短い名前。
- ステータス:有効、アーカイブ済み、または削除済み。
4. タスクエンティティ
作業の基本単位です。ユーザー、プロジェクト、ログをリンクするため、最も複雑な関係を必要とします。
- タスクID:一意の識別子。
- プロジェクトID:外部キー。
- 担当者ID:Userへの外部キー。
- 期日:時間制約。
- 優先度:列挙値。
5. オーディットログエンティティ
重要なエンティティに対するすべての変更を記録します。これにより追跡可能性が確保されます。
- ログID:一意の識別子。
- エンティティタイプ:影響を受けたテーブルはどれですか。
- レコードID:影響を受けた行はどれですか。
- 操作:作成、更新、削除。
- 実行者:ユーザーID。
- タイムスタンプ:操作の時刻。
🔗 関係性と基数のモデリング
関係性はエンティティ間の相互作用を定義します。プロダクションシステムでは、これらの関係性は外部キーによって強制されます。基数(1対1、1対多、多対多)は、データがどのように照会され、更新されるかを決定します。
組織からユーザー
これは1対多の関係です。1つの組織は複数のユーザーを持つことができますが、ユーザー記録はデータ隔離の目的で単一の組織に紐づけられます。テナント間でのデータ漏洩を防ぐために、organization_idはユーザーテーブル上の必須外部キーです。
組織からプロジェクト
同様に、これは1対多の関係です。プロジェクトは親組織なしでは存在できません。組織が削除された場合、カスケード動作を慎重に検討する必要があります。この場合、歴史的文脈を保持するために、ハード削除ではなくソフト削除を選択しています。
プロジェクトからタスク
もう一つの1対多の関係です。プロジェクトは複数のタスクを含み、タスクは正確に1つのプロジェクトに属します。これは標準的な構造的リンクです。
ユーザーからタスク(割当)
これは最も重要な関係です。ユーザーは複数のタスクに割り当てられ、タスクは複数のユーザーに割り当てられます(共同作業)。これには多対多 関係。
これを実装するため、結合テーブル(しばしば関連エンティティと呼ばれる)を導入します。このテーブルにより、多対多の関係が2つの1対多の関係に分割されます。
| テーブル名 | 目的 | キー |
|---|---|---|
| Task_Assignees | ユーザーとタスクをリンクする | Task_ID、User_ID |
| Organization_Tenants | 組織とユーザーをリンクする | Organization_ID、User_ID |
結合テーブルを使用することで、追加のメタデータを格納できます。たとえば、Task_Assigneesテーブルでは、ユーザーがその特定のタスクで果たした役割(例:リーダー、貢献者)を格納することができ、これはユーザーのグローバルな役割とは異なります。
⚖️ 制約とデータ整合性
アプリケーションレベルの検証だけでは不十分です。データベースの制約は、データ破損に対する最終防衛線となります。本番環境では、制約をスキーマレベルで定義すべきです。
参照整合性
外部キーは、子テーブルのレコードが存在しない親を参照できないことを保証します。たとえば、システムに存在しないユーザーにタスクを割り当てることはできません。
しかし、ON DELETE および ON UPDATE の動作は重要な決定事項です:
- CASCADE: 親が削除された場合、すべての子が削除されます。親なしでは意味を持たない孤立データ(例:削除された投稿のコメント)に使用します。
- RESTRICT: 子が存在する場合、削除を防止します。誤ったデータ損失を防ぐために使用します(例:有効な請求記録を持つ組織を削除する場合)。
- SET NULL: 親が削除された場合、子の外部キー列がNULLになります。関係がオプションの場合に使用します。
チェック制約
標準SQLはドメイン固有のルールを強制するためにチェック制約をサポートしています。例として:
- 期日: その
due_date列はcreated_at列より大きくなければならない。 - 優先度: その
priority列は許可された値の特定のリストに一致しなければならない(例:低、中、高)。 - 金額:財務関連のフィールドは非負でなければならない。
一意制約
必要に応じてデータの一意性を保証する。例えば、メールアドレスはシステム全体で一意でなければならない、またはユーザーのモデルに応じて特定の組織内でのみ一意である必要がある。複合一意制約により、ユーザーが特定のプロジェクトに一度だけ割り当てられる(重複割り当てを防ぐ)ことを保証できる。
🚀 パフォーマンスとインデックス戦略
クエリが遅い場合、良好に設計されたスキーマは無意味である。インデックスはデータを迅速に検索できる仕組みである。しかし、インデックスは書き込みパフォーマンスとストレージのコストを伴う。
クエリパターンの特定
インデックスを作成する前に、最も一般的な読み取り操作を分析する。本ケーススタディでは、一般的なクエリには以下が含まれる:
- 特定のユーザーに割り当てられたすべてのタスクを検索する。
- 組織内のすべてのプロジェクトを検索する。
- 特定のエンティティIDの監査ログを取得する。
インデックスの配置
外部キーはインデックス化の最も一般的な候補である。クエリが頻繁に organization_id でフィルタリングする場合、その列にインデックスを設けることが必須である。これがないと、データベースはフルテーブルスキャンを実行し、データが増えるにつれて著しくパフォーマンスが低下する。
複合インデックスは複数の列でフィルタリングするクエリに有用である。例えば、システムが頻繁に project_id および ステータス、(project_id, status) 上の複合インデックスは、2つの別々のインデックスよりも効率的です。
部分インデックス
データのサブセットのみが頻繁にクエリされる状況では、部分インデックスがスペースを節約します。たとえば、システムが「」をクエリする場合、アクティブタスクのみを対象とするインデックスは、行が「」である場合にのみ含まれるようになります。status = 'Active'、全テーブル上のインデックスよりもはるかに小さく、走査が速くなります。
🛠️ メンテナンスとスキーマの進化
ソフトウェア要件は変化します。データベーススキーマも例外ではありません。バージョンAからバージョンBに移行するには、ダウンタイムやデータ損失を避けるための慎重な計画が必要です。このプロセスは通常、マイグレーションスクリプトによって管理されます。
カラムの追加
新しいカラムを追加することは一般的に安全です。カラムがNULLを許容する場合、既存の行には影響しません。カラムにデフォルト値が必要な場合は、既存のすべてのデータに適用可能なデフォルト値を確保し、制約違反を避けるようにしてください。
カラムの削除
カラムを削除することはリスクがあります。まずカラムを非推奨(deprecated)としてマークするほうが良いです。これにより、アプリケーションコード内のカラムへの参照を削除した後に、データベースから物理的に削除できるようになります。この2段階アプローチにより、デプロイ期間中にアプリケーションエラーを防ぐことができます。
カラム名の変更
古いデータベースバージョンでは、複雑な回避策を用いない限り、カラム名の変更はほとんどサポートされていません。通常は、目的の名前を持つ新しいカラムを追加し、データを移行した後、古いカラムを削除するほうが良いです。これにより、移行中もスキーマが後方互換性を保つことができます。
🚧 ERD設計における一般的な落とし穴
経験豊富なアーキテクトですらミスを犯します。一般的な落とし穴を理解することで、設計段階でそれらを回避できます。
- 過剰正規化:データをあまりにも多くの小さなテーブルに分割すると、クエリが複雑かつ遅くなります。正規化とクエリパフォーマンスのニーズのバランスを取ることが重要です。
- 未正規化:同じデータを複数の場所に保存する(例:すべてのタスクログにユーザー名を繰り返し記録する)と、更新異常が発生します。ユーザー名が変更された場合、すべてのログエントリを更新しなければなりません。
- 循環依存:循環的な外部キー関係を作成すると、挿入や削除時にデッドロックが発生する可能性があります。依存関係グラフが有向非巡回グラフ(DAG)であることを確認してください。
- ソフトデリートの無視:レコードをハード削除すると履歴が失われます。監査のためにレコードを可視化しつつ、通常のビューからは非表示にするために、
deleted_atタイムスタンプカラムを実装することで、監査のためにレコードを可視化しつつ、標準ビューからは非表示にできます。 - 暗黙のデータ型:汎用型(例:
VARCHAR(255)すべてに使用するとスペースを無駄にします。代わりにINTID には、BOOLEANフラグには、適切な場面では文字列に特定の長さ制限を適用します。
✅ 本番用 ERD のベストプラクティス
システムの持続可能性と健全性を確保するため、以下のガイドラインに従ってください:
- 関係の文書化: ERD自体が文書です。実際のスキーマと常に最新の状態に保つようにしてください。自動化ツールを使用してデータベースから図を生成し、正確性を検証できます。
- 命名規則の標準化: 次の命名規則を使用してください:
snake_caseテーブルおよびカラムに使用します。外部キーには関係名を接頭辞として付ける(例:organization_idではなく、単にorg_idとすることで明確性が向上します。 - UUID と自動増分の選択: 分散システムでは、データベースをマージする際に衝突を防ぐために UUID を使用します。単一インスタンスシステムでは、自動増分の整数の方がよりコンパクトで高速です。
- 成長を見据えた設計: パーティショニングを考慮して設計してください。テーブルが数十億行に達すると予想される場合、
organization_id. - アクセスパターンのレビュー: スロークエリログを定期的に確認し、欠落しているインデックスや非効率な結合を特定してください。
🔄 スキーマのライフサイクル
ERDは静的な文書ではありません。製品とともに進化します。ライフサイクルは通常、以下の段階を経ます:
- 設計フェーズ: 要件に基づいて初期モデルを策定する。
- 実装フェーズ:スキーマを構築するためのマイグレーションスクリプトの作成。
- 検証フェーズ:パフォーマンスの仮定を検証するために負荷テストを実行する。
- 反復フェーズ:機能が追加されるにつれて、新しいフィールドや関係性を追加する。
- 最適化フェーズ:本番データに基づいてインデックスや制約を最適化する。
最適化フェーズ中に、初期の基数の仮定が間違っていたことに気づくかもしれません。たとえば、1対多の関係が実際には多対多であることが判明し、結合テーブルへのスキーマ変更が必要になるかもしれません。これは設計における柔軟性の重要性を浮き彫りにしています。
🛡️ スキーマ設計におけるセキュリティ上の考慮事項
データセキュリティはスキーマ設計と深く結びついています。行レベルセキュリティ(RLS)ポリシーは、通常、ERDの構造に依存して正しく機能します。もしorganization_idが適切にインデックス付けされず、強制されない場合、Organization Aのユーザーが誤ってOrganization Bのデータを照会してしまう可能性があります。
さらに、機密データは分離すべきです。システムが支払い情報を扱う場合、そのデータは一般的なユーザーのメタデータと混在するのではなく、より厳格なアクセス制御を持つ別々のスキーマやテーブルに配置すべきです。これにより、漏洩が発生した場合の被害範囲を制限できます。
📝 設計意思決定の要約
以下の表は、このケーススタディで行われた主要な意思決定とその根拠を要約しています。
| 意思決定 | オプションA | オプションB(選択済み) | 根拠 |
|---|---|---|---|
| マルチテナント | 別々のデータベース | 共有データベース、共有スキーマ | 運用負荷の低減;テナント間分析の管理が容易になる。 |
| 組織の削除 | ハード削除 | ソフトデリート | 履歴の監査ログを保持し、コンプライアンスのためにデータ損失を防ぎます。 |
| タスクの割り当て | 単一カラム | 結合テーブル | 複数の担当者を許可し、各割り当てごとに特定の役割を追跡します。 |
| 主キー | 自動増加 | UUIDs | 将来の分散アーキテクチャをサポートし、データのマージを容易にします。 |
本番用バックエンドを構築するには、コードを書くこと以上に、データの流れや構造について深い理解が必要です。ERDはこの旅を導く地図です。これらの原則に従うことで、ビジネスが成長するにつれてシステムが安定性、セキュリティ、スケーラビリティを保つことができます。
思い出してください。目的は最も複雑な図を描くことではなく、アプリケーションのニーズを最もよく満たしつつ、技術的負債を最小限に抑える図を作ることです。継続的な見直しと適応が、健全なデータエコシステムを維持する鍵です。