








堅牢なデータモデルを設計することは、ソフトウェア工学における最も重要なタスクの一つである。エンティティ関係図(ERD)は、情報がどのように格納され、取得され、維持されるかの設計図として機能する。この設計図の中心には正規化がある。多くの実務者が正規化を、実装に移る前に完了しなければならない厳格なチェックリストのように扱うが、現実にははるかに複雑である。データの整合性とクエリのパフォーマンスの間には繊細なバランスがあり、深い理解が求められる。
このガイドは、ERD正規化の技術的現実を検討する。教科書的な定義を越えて、ルールへの厳格な従いが負担となる実際の状況に焦点を当てる。トランザクションシステムを構築している場合でも、分析プラットフォームを構築している場合でも、正規化をどこで止めるか、冗長性をどこで導入するかを理解することは、長期的な安定性にとって不可欠である。
🔍 関係データ設計の核心原則を理解する
正規化とは、単にデータを整理することにとどまらない。それは依存関係を管理することである。関係モデルでは、すべての列がそのテーブルの主キーと明確な関係を持つ必要がある。この関係が弱いか、間接的であると、異常が発生する。これらの異常は、データの不整合、無駄なストレージ、複雑な更新ロジックとして現れる。
正規化の主な目的には以下が含まれる:
- データ整合性:システム全体でデータが正確かつ一貫性を保つことを保証すること。
- ストレージ効率:同じデータの重複コピーを排除すること。
- スケーラビリティ:構造の再書き換えなしに成長に対応できるスキーマを設計すること。
- 保守性:情報の更新に必要な複雑さを軽減すること。
しかし、これらの目的を達成するにはしばしばコストが伴う。正規化の各段階は、通常、テーブルの数を増やし、結合されたデータを取得するために必要なクエリの複雑さを高める。このトレードオフを理解することが、効果的なスキーマ設計の第一歩である。
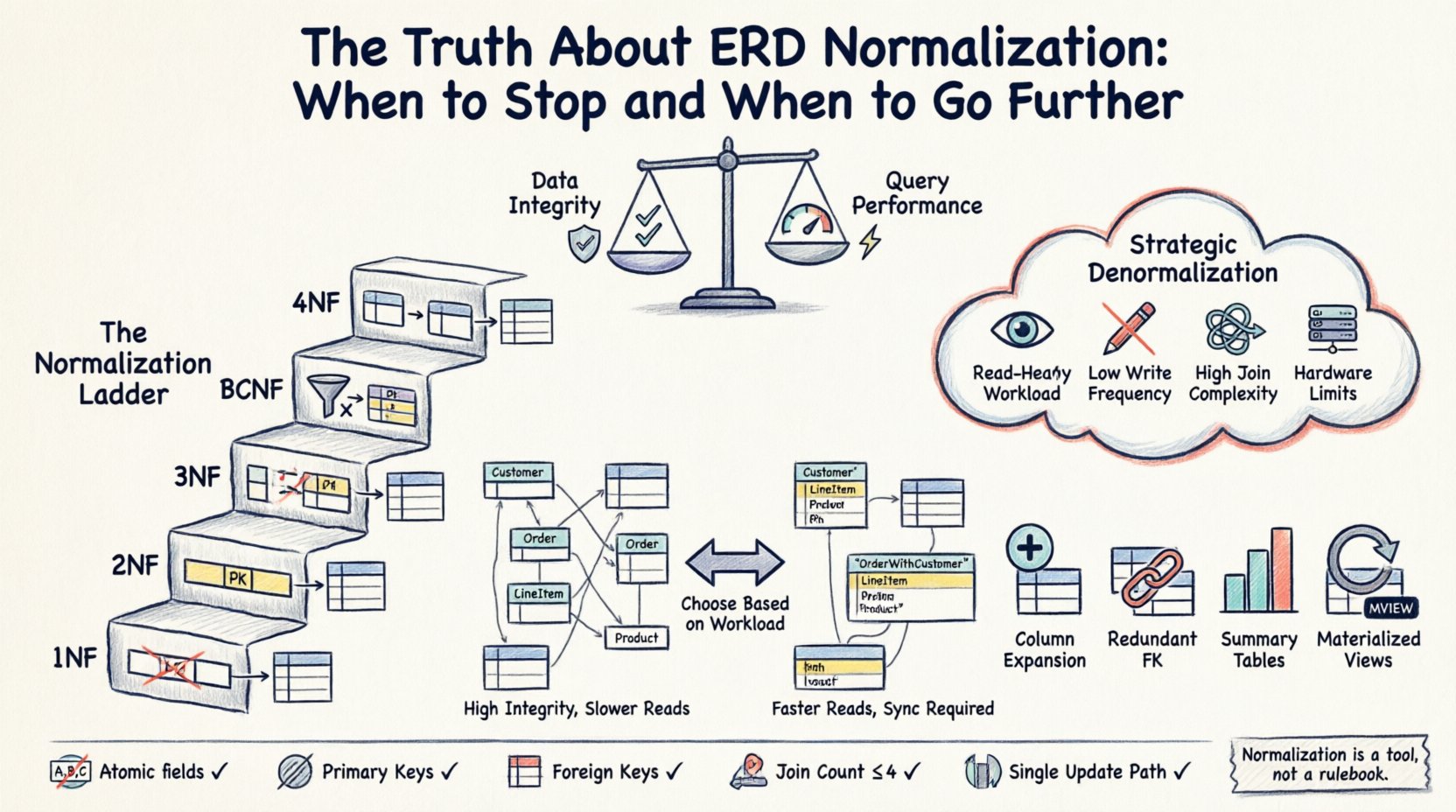
⚙️ 標準正規化の三本柱(1NF、2NF、3NF)
停止するか、さらに進むかを決める前に、基準を理解する必要がある。標準形は、構造の洗練を段階的に示すものである。
第一正規形(1NF)
あらゆる関係データベースの基盤は1NFである。テーブルが以下の基準を満たす場合、1NFにあるとされる:
- すべての列の値は原子的(分割不能)である。
- 各列は単一の型の値を含む。
- 行内に繰り返しグループや配列がない。
たとえば、単一の列に製品名のリストを格納すると、1NFに違反する。代わりに、各製品はそれぞれ独自の行を占めるべきである。現代のシステムは複雑なデータ型を扱うことが多くても、原子性への厳格な従いにより、クエリが予測可能になり、インデックス戦略が意図した通りに機能することが保証される。
第二正規形(2NF)
テーブルが1NFにあれば、2NFの要件を満たさなければならない。この形は、複合主キー(複数の列から構成されるキー)を持つテーブルに特に適用される。テーブルが2NFにあるのは、以下の条件を満たす場合である:
- すでに1NFにある。
- すべてのキー以外の属性は、主キー全体に完全に依存しており、その一部だけに依存するわけではない。
注文詳細テーブルを例に挙げよう。このテーブルのキーは注文IDと製品IDの組み合わせである。このテーブルに製品名を格納すると、部分的依存が生じる。製品名は製品IDにのみ依存しており、注文IDには依存しない。これを修正するには、製品名を別途の製品テーブルに移動する。これにより、更新異常が減少する。製品名が変更された場合、数千もの注文記録にわたって更新するのではなく、一つの場所で更新すればよい。
第三正規形(3NF)
3NFは、多くの運用システムにおいて最適なポイントとされる。テーブルが3NFにあるのは、以下の条件を満たす場合である:
- それは2NFにあります。
- 推移的依存関係は存在しません。非キー属性は主キーのみに依存しなければなりません。
推移的依存関係とは、列Aが列Bを決定し、列Bが列Cを決定する場合に発生します。データベースにおいて、顧客IDが都市を決定し、都市が地域を決定する場合、地域を顧客テーブルに格納すると推移的依存関係が生じます。その都市の地域が変更された場合、その都市に属するすべての顧客レコードを更新しなければなりません。これを正規化することで、地域データを別々の場所に移動させ、更新が一度だけ行われることを保証できます。
📉 極めて厳格な正規化のパフォーマンスコスト
3NFは冗長性を最小限に抑えますが、テーブル数を最大化します。正規化されたスキーマでは、単一の論理的レコードを取得する場合、複数のテーブルを結合する必要があることがよくあります。このプロセスには計算コストが伴います。
- 結合のオーバーヘッド:すべての結合操作では、データベースエンジンが異なるテーブルからの行を一致させる必要があります。テーブルが大きくなるにつれて、この一致プロセスはCPUとメモリを消費します。
- I/O操作:多数のテーブルに分散されたデータは、より多くのディスク読み取りを必要とします。データが効率的にキャッシュされない場合、読み取り遅延が増加します。
- 複雑さ:多数の結合を含む複雑なクエリは、最適化や保守が難しくなります。スキーマの変更があった場合、破綻しやすくなります。
書き込み負荷の高いシステムでは、正規化は通常適切な選択です。データの重複を防ぎ、単一の事実の更新が正しく伝搬されることを保証します。しかし、読み込み負荷の高いシステムでは、結合のコストがボトルネックになることがあります。
🚀 戦略的非正規化:ルールを破るタイミング
非正規化とは、パフォーマンスを最適化するために意図的に冗長性を導入することです。これは誤りではなく、正規化のコストがその利点を上回る場合に、意図的に選択されるアーキテクチャ上の意思決定です。
非正規化のトリガー
以下の状況では、正規化ルールを緩和することを検討すべきです:
- 読み込み操作が主導する:アプリケーションが読み込み中心の場合(例:レポートダッシュボード)、結合を減らすことで遅延を著しく低下させることができます。
- クエリの複雑さが高い:ユーザーが1ページを表示するために10個以上のテーブルからデータを必要とする場合、クエリは遅くなり、デバッグも難しくなります。
- 書き込み頻度が低い:データがほとんど更新されない場合、冗長性による不整合のリスクは最小限に抑えられます。
- ハードウェア制約がある:ディスクI/Oが高コストまたは限られている環境では、冗長データをキャッシュすることで物理的読み取りを減らすことができます。
一般的な非正規化戦略
- 列の拡張:導出値をテーブルに直接格納すること。例えば、明細項目から計算された「合計金額」列を注文テーブルに追加することで、毎回読み込み時に合計する必要がなくなります。
- 冗長な外部キー:階層を取得する際に結合を避けるために、子テーブルに親IDを追加すること。
- 要約テーブル: 定期的またはトリガー経由で更新される別テーブルに、集計(カウント、合計)を事前に計算する。
- マテリアライズドビュー:複雑なクエリの結果をスケジュールに従って更新される物理テーブルとして保存する。
📊 比較:正規化 vs. 非正規化
利点と欠点を可視化するため、以下の比較表を検討してください。
| 側面 | 高正規化(3NF+) | 非正規化設計 |
|---|---|---|
| データ整合性 | 高い – 単一の真実のソース | 低い – 同期ロジックが必要 |
| ストレージ使用量 | 効率的 – 重複なし | 非効率的 – 冗長なデータ |
| 書き込みパフォーマンス | 高速 – 単一の行の更新 | 遅い – 複数行の更新 |
| 読み取りパフォーマンス | 遅い – ジョインが必要 | 高速 – 直接アクセス |
| クエリの複雑さ | 高い – 複数のジョインが必要 | 低い – 簡単なクエリ |
| 保守作業の負担 | 低い – 一度の更新で済む | 高い – 複数箇所の同期が必要 |
この表は、万能のベストプラクティスは存在しないことを強調している。選択はアプリケーションの特定のワークロードに完全に依存する。
🛠️ スキーマ設計の意思決定フレームワーク
特定のプロジェクトに適した正規化のレベルを決定するため、この意思決定フレームワークを使用してください。各ポイントをプロジェクトの要件に基づいて評価してください。
1. ワークロードパターンを分析する
読み取りと書き込みの比率を特定してください。システムがOLTP(オンライン取引処理)の場合、整合性と3NFを優先してください。OLAP(オンライン分析処理)の場合、読み取り速度を優先し、正規化の解除を検討してください。
2. データの新鮮度要件を評価する
データはリアルタイムで必要ですか?正規化の解除を行うと、元データの更新と冗長データ内の反映変更の間に遅延が生じます。ユーザーが即時の一貫性を必要とする場合、厳格な正規化の方が安全です。
3. 更新頻度を評価する
主キーを確認してください。参照テーブル(国リストなど)の変更がまれな場合、そのデータをトランザクションテーブルに正規化の解除して格納しても安全です。一方、参照テーブルの変更が頻繁な場合は、別々に保持して同期エラーを最小限に抑えるべきです。
4. ハードウェアとキャッシュを考慮する
現代のデータベースはしばしばメモリにデータをキャッシュします。作業セットがRAMに収まる場合、結合のコストは低下します。この場合、パフォーマンスを損なわずにややより正規化されたスキーマを採用できます。
🧠 高度な正規化:BCNFと4NF
3NFを超えると、ボイス・コッド正規形(BCNF)や第四正規形(4NF)といったより高い形式があります。これらは特定の境界ケースに対処します。
ボイス・コッド正規形(BCNF)
BCNFは3NFのより厳格なバージョンです。主キーが複合である場合でも、非主属性が他の非主属性を決定するケースを扱います。理論的には完璧ですが、依存関係の保持が失われる場合があります。実際には3NFが十分なことが多く、BCNFを強制するとスキーマを複雑化するだけで、大きな価値は得られません。
第四正規形(4NF)
4NFは多値依存性を取り扱います。これは、1行に複数の独立した値のリストが含まれる場合に発生します。たとえば、学生テーブルに複数の趣味と複数の授業を同じ行に格納する場合です。これは標準的なビジネスアプリケーションでは稀ですが、専門的なデータモデリングの場面では一般的です。
🚫 避けるべき一般的な落とし穴
正規化について十分な理解があっても、間違えるのは簡単です。以下の一般的な誤りを避けてください:
- 過剰な正規化:単純な関係に数百もの小さなテーブルを作成する。これによりアプリケーションのロジックが分かりにくくなり、開発が遅くなる。
- インデックスを無視する:正規化されたスキーマでは結合が必要です。結合カラムにインデックスがなければ、スキーマ設計に関わらずパフォーマンスが低下します。
- 監視なしに正規化の解除を行う:同期を維持する計画なしに冗長性を導入すると、時間とともにデータの破損が発生します。
- ロジックをハードコードする:導出値はデータベースにすべきなのに、アプリケーション層で計算しないでください。ビジネスルールはデータに近い場所に保つべきです。
✅ スキーマ検証のチェックリスト
新しいスキーマをデプロイする前に、この検証チェックリストを実行してください。
- 原子性:すべてのフィールドが原子的ですか?
- 主キー:すべてのテーブルに一意の主キーがありますか?
- 外部キー:関係は外部キーによって強制されていますか?
- 冗長性:明確な繰り返しデータグループはありますか?
- 結合数:重要なクエリは3~4回以上の結合を必要としますか?
- 更新パス:単一のデータ変更を1か所で行えますか?
🔗 データアーキテクチャに関する結論
正規化はルールブックではなくツールです。データの不整合から守るためのものですが、アプリケーションの効率的な動作を妨えてはいけません。ERDの正規化に関する「真実」は、それがスケールであるということです。整合性を確保するために高度に正規化された構造から始め、パフォーマンスのニーズに基づいて選択的に非正規化します。
万能の解決策はありません。高頻度取引システムはコンテンツ管理システムとは大きく異なります。重要なのは、依存関係と結合の背後にあるメカニズムを理解することです。ストレージコストと計算コストのバランスを取ることで、信頼性と高速性を両立したシステムを構築できます。
設計を進める中で、スキーマの進化は避けられないことを思い出してください。変更を予測して計画しましょう。データベースのマイグレーションにはバージョン管理を使用してください。構造的な決定を下す前に、常に負荷下でのクエリテストを行いましょう。最適なスキーマとは、ビジネス目標を支援しつつ、ボトルネックにならないものなのです。