











Проектирование моделей данных в архитектуре микросервисов требует фундаментального изменения мышления по сравнению с монолитными приложениями. В традиционной системе один диаграмма сущность-связь (ERD) часто охватывает всю базу данных. В распределенной среде этот единый взгляд распадается на несколько независимых схем. Проблема заключается в поддержании согласованности без привязки сервисов друг к другу. Этот гид исследует, как эффективно структурировать модели данных, обеспечивая масштабируемость и отказоустойчивость, избегая распространённых ловушек управления распределёнными данными.
Когда сервисы напрямую делятся данными, они наследуют зависимости друг друга. Такая тесная связь приводит к хрупким системам, где изменение в одной области нарушает другую. Цель — создать границы, позволяющие командам независимо развертывать свои решения. Достижение этого требует тщательного планирования отношений, моделей согласованности и шаблонов интеграции.
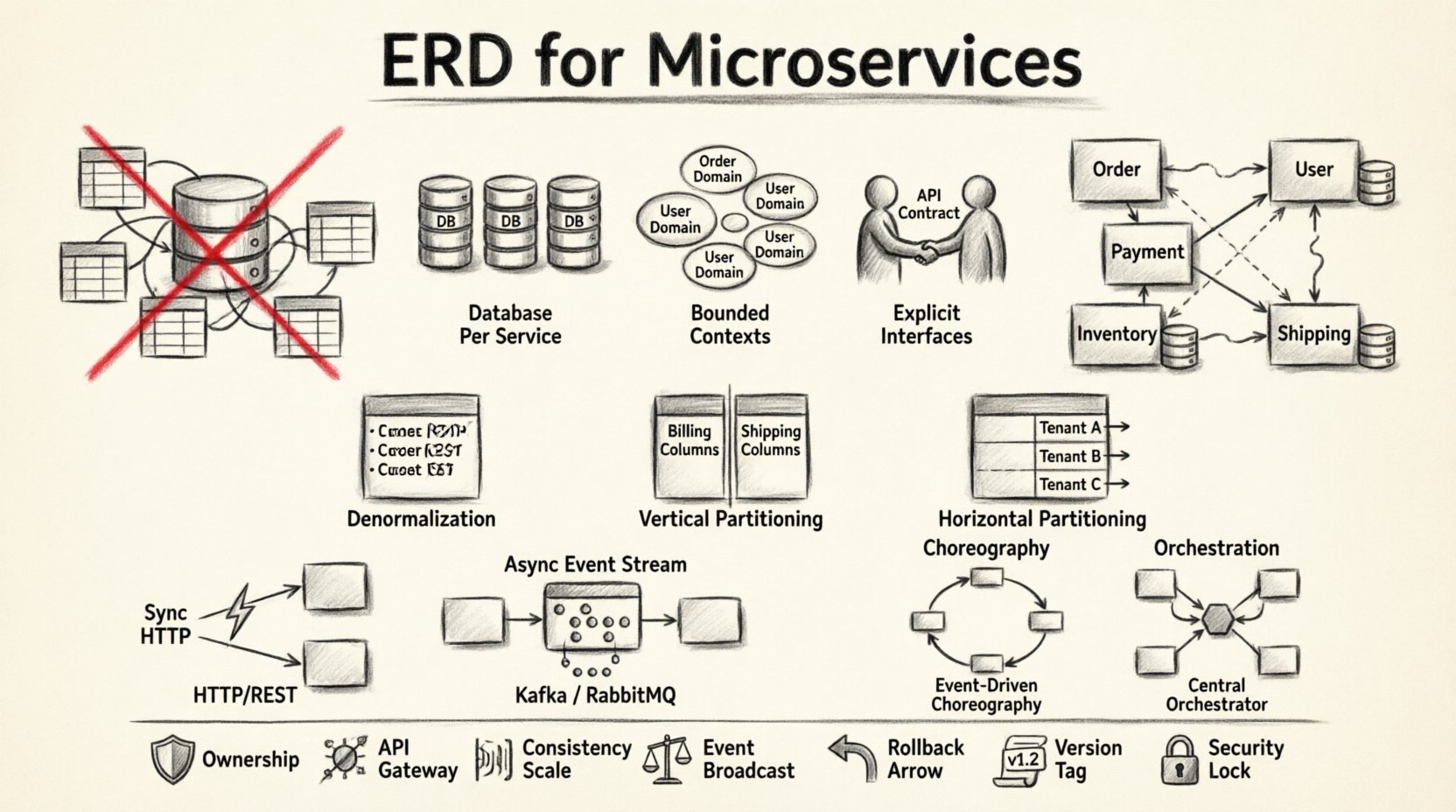
🧱 Почему традиционные ERD ломаются в распределённых системах
Стандартная ERD предполагает централизованное управление. Она отображает таблицы, столбцы и внешние ключи в рамках одного транзакционного контекста. Микросервисы отвергают такую централизацию. Когда вы применяете мышление, основанное на монолитной ERD, к распределённой системе, вы рискуете создать распределённый монолит. Это происходит, когда сервисы полагаются на общие таблицы базы данных вместо определённых API.
Следующие проблемы обычно возникают при игнорировании этих принципов:
- Связанность развертывания:Изменения в общей таблице требуют одновременного развертывания в нескольких сервисах.
- Границы транзакций:Транзакции ACID охватывают несколько сервисов, увеличивая задержку и точки отказа.
- Блокировка схемы:Блокировки базы данных в одном сервисе могут останавливать запросы в другом сервисе.
- Проблемы видимости:Нет единой команды, ответственной за глобальное состояние данных, что приводит к изоляции данных.
Вместо одного диаграммы вам нужно собрать набор схем, специфичных для сервисов, которые общаются через чётко определённые интерфейсы. Такой подход ставит автономность выше немедленной согласованности.
🧬 Основные принципы моделирования распределённых данных
Чтобы сохранить порядок, необходимо придерживаться определённых архитектурных принципов. Эти рекомендации помогают командам принимать решения по вопросам владения данными и шаблонам доступа.
1. База данных на сервис
Каждый микросервис должен владеть своей базой данных. Это гарантирует, что внутренняя схема сервиса не видна другим. Если сервис А нуждается в данных сервиса Б, он должен запрашивать их через API, а не напрямую обращаться к базе данных. Такая изоляция защищает целостность каждого домена.
- Сервисы управляют собственным развитием схемы.
- Команды могут выбирать лучшую технологию базы данных для своих конкретных потребностей (полиглотное хранение).
- Сбой в одной базе данных не приводит к полному сбою приложения.
2. Ограниченные контексты
Данные должны соответствовать бизнес-возможностям. В проектировании, ориентированном на домен, ограниченный контекст определяет семантические границы модели. Два сервиса могут использовать термин «Клиент», но данные в этих контекстах различаются. Один может хранить контактную информацию, а другой — финансовую историю. Объединение этих данных в одну ERD создаёт путаницу и технический долг.
3. Явные интерфейсы
Поскольку сервисы не могут напрямую видеть данные друг друга, API становится контрактом по данным. Схема ответа API определяет реальность данных для потребителя. Это развязывает внутреннюю реализацию хранения данных с внешним использованием.
📐 Шаблоны проектирования схем для независимости
Проектирование схем для микросервисов включает специфические шаблоны для обработки отношений, которые традиционно управляются внешними ключами. Вы не можете полагаться на ограничения на уровне базы данных для обеспечения связей между сервисами.
Денормализация
В монолите нормализация уменьшает избыточность. В микросервисах чаще предпочитают денормализацию. Хранение дублирующихся данных уменьшает необходимость в удалённых вызовах. Например, сервис заказов может хранить имя и адрес клиента в записи заказа. Это позволяет избежать синхронного поиска в сервисе пользователей каждый раз, когда отображается заказ.
- Выгода: Более высокая производительность чтения и меньшее количество сетевых переходов.
- Риск: Несогласованность данных, если исходные данные изменяются. Вам необходимо обрабатывать обновления через события.
Вертикальное партиционирование
Разделите большие таблицы на более мелкие, специализированные наборы. Если таблица содержит как сведения об оплате, так и адреса доставки, разделите эти аспекты. Данные об оплате могут принадлежать сервису платежей, а адреса доставки — сервису логистики. Это уменьшает площадь поверхности изменений и повышает безопасность за счёт ограничения доступа.
Горизонтальное партиционирование
Разделите данные по идентификатору клиента или географическому региону. Это полезно для масштабирования отдельных сервисов без влияния на другие. Позволяет копировать сервисы для регионов с высокой нагрузкой, оставляя другие легковесными.
| Шаблон | Лучший сценарий использования | Ключевое соображение |
|---|---|---|
| Денормализация | Работа с высокой нагрузкой на чтение | Требует логики синхронизации |
| Вертикальное партиционирование | Отличные домены | Чёткие границы API |
| Горизонтальное партиционирование | Высокая масштабируемость / Многоклиентность | Сложность логики маршрутизации |
🔄 Обработка отношений и согласованности
Самая сложная часть моделирования данных микросервисов — поддержание согласованности без распределённых транзакций. Вам нужно выбрать между сильной согласованностью и конечной согласованностью.
Синхронная коммуникация
Сервисы могут напрямую вызывать друг друга через HTTP или gRPC. Это обеспечивает сильную согласованность для немедленных операций. Однако это вводит задержку и создаёт цепочку зависимостей. Если сервис А вызывает сервис В, а сервис В недоступен, сервис А также завершится неудачно.
Асинхронная коммуникация
Сервисы общаются через очереди сообщений или потоки событий. Это разделяет временные рамки операций. Сервис А публикует событие, а сервис В позже его потребляет. Это поддерживает конечную согласованность.
- Плюсы: Устойчивость, масштабируемость и слабая связанность.
- Минусы: Данные временно не согласованы. Отладка требует отслеживания по нескольким журналам.
🗓️ Паттерн Саги для обеспечения целостности данных
Сага — это последовательность локальных транзакций. Каждая транзакция обновляет локальную базу данных и публикует событие для запуска следующего шага. Если шаг завершается неудачно, сага выполняет компенсирующие транзакции для отмены предыдущих изменений.
Хореография против оркестрации
Саги могут быть реализованы двумя способами:
- Хореография:Сервисы слушают события и решают, что делать дальше. Нет центрального контроллера. Это гибко, но сложнее визуализировать.
- Оркестрация: Центральный координатор указывает сервисам, что делать. Это обеспечивает лучшую видимость и контроль над рабочим процессом, но вводит точку отказа.
При моделировании ERD для саг необходимо учитывать изменения состояния. Каждый сервис, участвующий в саге, должен хранить своё состояние для обработки откатов. Это означает, что ваша схема должна поддерживать транзакционные состояния, а не только конечные данные.
📝 Управление эволюцией схемы
Эволюция схемы неизбежна. Поля меняются, типы изменяются, ограничения ослабляются. В распределённой системе вы не можете изменить схему базы данных, пока другие сервисы на неё зависят. Вам необходимо планировать версионирование.
Обратная совместимость
Всегда поддерживайте обратную совместимость. При добавлении нового поля не удаляйте старое сразу. Дайте потребителям возможность постепенно перейти. Если необходимо изменить имя поля, временно создайте псевдоним старого имени на новое во время переходного периода.
Стратегии версионирования
- Версионирование по URI: Включайте номера версий в путь API.
- Версионирование по заголовкам: Используйте пользовательские заголовки для указания ожидаемой версии схемы.
- Согласование содержимого: Используйте стандартные HTTP-заголовки для запроса конкретных типов содержимого.
Документация должна быть синхронизирована с кодом. Автоматизированные тесты должны проверять, что контракт API соответствует схеме. Это предотвращает попадание разрушающих изменений в продакшн.
🛡️ Распространённые ошибки, которые следует избегать
Даже при наличии хорошего плана команды часто сталкиваются с конкретными проблемами. Осознание этих ошибок помогает создавать надёжную систему.
1. Ловушка общих баз данных
Не делите таблицы между сервисами. Это создаёт скрытую зависимость. Если сервис оплаты читает таблицу сервиса заказов, он знает слишком много о внутренней структуре. Это приводит к тесной связности и конфликтам при развертывании.
2. Избыточная нормализация
Попытка нормализовать данные между сервисами приводит к чрезмерному количеству соединений и сетевых вызовов. Примите некоторую избыточность. Лучше иметь дублирующиеся данные, чем медленную, сильно связанную систему.
3. Пренебрежение идемпотентностью
Сетевые вызовы могут завершиться неудачно. Сообщения могут дублироваться. Ваша схема и логика API должны обрабатывать дублирующиеся запросы без возникновения ошибок. Проектируйте ваши конечные точки как идемпотентные, чтобы повторная отправка запроса не приводила к созданию дублирующих записей.
4. Отсутствие наблюдаемости
Когда данные распределены, вы не можете запросить единственный базу данных для отслеживания транзакции. Вам необходима распределенная трассировка и централизованный журнал. Ваша схема должна включать идентификаторы корреляции для отслеживания запросов через границы служб.
📋 Чек-лист управления
Перед развертыванием новой службы ознакомьтесь со следующим чек-листом, чтобы убедиться, что ваша модель данных надежна.
- Ответственность: Есть ли одна служба, ответственная за эти данные?
- Интерфейс: Данные доступны только через API?
- Согласованность: Документирована ли модель согласованности (сильная против временной)?
- События: Изменения состояния публикуются как события для других служб?
- Компенсация: Существует ли механизм отката для неудачных транзакций?
- Версионирование: Схема версионируется для обработки будущих изменений?
- Безопасность: Чувствительные данные зашифрованы на хранении и в процессе передачи?
🔍 Визуализация архитектуры
Хотя вы не можете нарисовать единую диаграмму ERD для всей системы, вы можете создать карту высокого уровня. Эта карта показывает службы и их границы данных, а не конкретные столбцы.
- Нарисуйте прямоугольники для каждой службы.
- Обозначьте область данных внутри прямоугольника (например, «Данные профиля пользователя»).
- Нарисуйте стрелки для вызовов API, указывающие на поток данных.
- Отдельно обозначьте потоки событий от потоков запросов/ответов.
Этот визуальный помощник помогает заинтересованным сторонам понять поток информации, не вдаваясь в технические детали схемы. Он служит инструментом коммуникации для архитекторов и бизнес-аналитиков.
🚀 Заключение
Проектирование диаграмм ERD для микросервисов — это не рисование линий между таблицами. Это определение границ между бизнес-возможностями. Принимая базу данных на каждую службу, допуская временную согласованность и строго управляя API, вы можете создавать масштабируемые системы. Хаос распределённых данных управляем при дисциплине и чётких контрактах. Сосредоточьтесь на автономии, минимизируйте связность и убедитесь, что каждая служба полностью владеет своими данными.
Помните, что моделирование данных — это итеративный процесс. По мере роста служб ваша схема будет нуждаться в эволюции. Регулярно проверяйте свою архитектуру на соответствие этим принципам, чтобы поддерживать здоровую, устойчивую систему.