











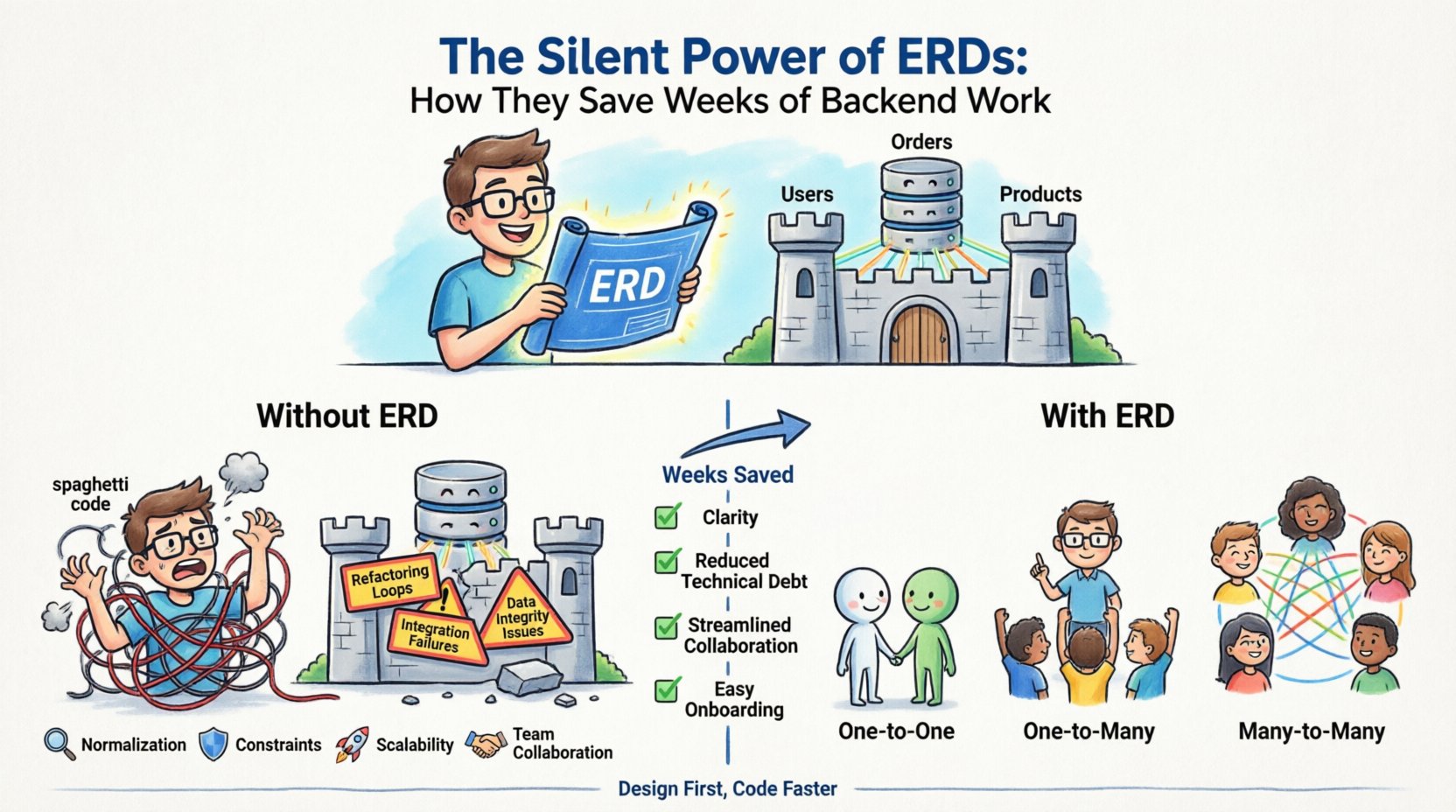
Разработка бэкенда часто ощущается как строительство дома без чертежа. Вы начинаете класть кирпичи, добавлять окна и возводить стены, опираясь на интуицию. Иногда это работает. Часто — нет. Через несколько недель вы обнаруживаете, что разбираете стены, чтобы вписать дверь, которую забыли предусмотреть. Именно такова реальность программирования без надежногодиаграммы сущностей и отношений (ERD). ERD — это молчаливый архитектор вашей информационной инфраструктуры, работающий за кулисами, чтобы предотвратить дорогостоящие структурные сбои. Когда вы тратите время на проектирование модели данных до написания первого строчки кода, вы получаете ясность, снижаете технический долг и упрощаете взаимодействие между командами.
В этом руководстве рассматривается ощутимое влияние ERD на рабочие процессы бэкенда. Мы разберем механику моделирования данных, скрытые затраты на пропуск проектирования и стратегические преимущества хорошо документированной схемы. Освоив эти принципы, вы сможете перейти от реактивной разработки к проактивному проектированию архитектуры.
Что такое ERD? 📐
Диаграмма сущностей и отношений — это визуальное представление логической структуры базы данных. Она показывает, как различные фрагменты данных взаимосвязаны между собой. Представьте её как карту памяти вашего приложения. Без этой карты разработчики двигаются вслепую, рискуя столкнуться между данными, которые должны оставаться раздельными.
В основе ERD лежат три основных компонента:
- Сущности: Они представляют объекты или понятия, которые вы отслеживаете. В базе данных они транслируются в таблицы. Примеры включаютПользователи, Заказы, илиТовары.
- Атрибуты: Это конкретные свойства сущности. Они становятся столбцами в ваших таблицах. Для сущностиПользователь атрибуты могут включатьэлектронная почта, хэш пароля, идата создания.
- Связи: Они определяют, как сущности взаимодействуют между собой. Они задают кардинальность и связность между таблицами, например, что одинПользователь может иметь многоЗаказы.
Хотя концепция кажется простой, сложность возникает при управлении масштабом. Простой блог может потребовать лишь нескольких таблиц. Корпоративная система требует десятков, а то и сотен взаимосвязанных сущностей. Диаграмма ERD выступает единственным источником истины для всех этих взаимодействий.
Скрытая стоимость пропуска проектирования 💸
Многие команды разработки спешат писать код, чтобы успеть к срокам. Они полагают, что позже можно будет рефакторить базу данных. Это опасное предположение. Изменение схемы базы данных значительно дороже, чем изменение логики приложения. Как только данные записаны, изменение их структуры требует скриптов миграции, возможного простоя и тщательного обращения с существующими записями.
Рассмотрим следующие сценарии, при которых отсутствие диаграммы ERD вызывает трудности:
- Циклы рефакторинга: Вы реализуете функцию, понимаете, что структура данных не поддерживает её, и вынуждены переписывать запросы. Этот цикл повторяется, поглощая недели времени в спринте.
- Сбои интеграции: Когда команды фронтенда и бэкенда работают без общего определения схемы, API часто выходят из строя. Бэкенд отправляет одну структуру; фронтенд ожидает другую.
- Проблемы целостности данных: Без определённых ограничений в систему попадают недопустимые данные. В конечном итоге вы вынуждены вручную очищать заброшенные записи или исправлять несогласованные состояния.
- Задержки при настройке новых сотрудников: Новые разработчики испытывают трудности с пониманием системы. Они тратят дни на чтение кода вместо создания функций, потому что поток данных не документирован.
К тому времени, как вы заметите проблему, её стоимость уже накопилась. Теперь «исправление» требует не только изменений кода, но и миграции данных, тестирования и проверки развертывания.
Создание связей, как профессионал 🔗
Понимание того, как данные связаны между собой, — это суть проектирования диаграммы ERD. Связи определяют, как пишутся запросы, и как оптимизируется производительность. Существует три основных типа связей, которые необходимо чётко определить.
В таблице ниже описаны различия между этими типами связей:
| Тип связи | Определение | Пример сценария | Примечание по реализации |
|---|---|---|---|
| Один к одному (1:1) | Одна запись в таблице A связана ровно с одной записью в таблице B. | Профиль пользователя, связанный с таблицей настроек пользователя. | Часто реализуется путём размещения первичного ключа B в A. |
| Один ко многим (1:N) | Одна запись в таблице A связана с несколькими записями в таблице B. | Категория, содержащая несколько продуктов. | Стандартное размещение внешнего ключа в таблице «многие». |
| Многие ко многим (M:N) | Несколько записей в таблице A связаны с несколькими записями в таблице B. | Студенты, зачисленные на несколько курсов. | Требуется промежуточная таблица для разрешения связи. |
Пренебрежение этими различиями приводит к неэффективным запросам. Например, хранение списка идентификаторов продуктов в одном столбце для категории нарушает принципы нормализации. Это вынуждает вас разбирать строки вместо использования соединений, что замедляет производительность по мере роста данных.
Нормализация: поддержание данных в чистоте 🧹
Нормализация — это процесс организации данных для уменьшения избыточности и повышения целостности. Хотя современные системы иногда отклоняются от строгой нормализации ради производительности, понимание принципов остается необходимым.
Стандартные формы нормализации включают:
- Первое нормальное состояние (1NF):Обеспечивает атомарность. Каждый столбец содержит только одно значение. В одной ячейке нет списков или массивов.
- Второе нормальное состояние (2NF):Основано на 1NF. Требует, чтобы все неключевые атрибуты полностью зависели от первичного ключа. Нет частичных зависимостей.
- Третье нормальное состояние (3NF):Основано на 2NF. Требует, чтобы неключевые атрибуты зависели только от первичного ключа, а не от других неключевых атрибутов.
Почему это важно? Рассмотрим таблицу Order таблицу. Если вы храните Customer Name в каждой строке заказа, вы создаете избыточность. Если клиент меняет свое имя, вам нужно обновить тысячи строк. Если вы пропустите одну, ваши данные станут несогласованными. Перемещая Customer Name в таблицу Customers и связывая через ID, вы обеспечиваете единый источник истины.
Однако нормализация — не панацея. Избыточная нормализация может привести к сложным соединениям, которые снижают производительность. Цель — баланс. Вам необходимо понимать компромиссы между эффективностью хранения и скоростью запросов.
Распространённые ошибки при проектировании схемы 🚧
Даже опытные разработчики допускают ошибки при проектировании ERD. Признание этих распространённых ловушек может спасти вас от серьёзных проблем в будущем.
- Циклические зависимости: Сущность A нуждается в сущности B, а сущность B нуждается в сущности A. Это создаёт взаимоблокировку при инициализации и затрудняет написание скриптов миграции.
- Отсутствующие ограничения: Пренебрежение определением внешних ключей, уникальных ограничений или проверочных ограничений позволяет некорректным данным проскользнуть мимо. База данных должна обеспечивать соблюдение правил, а не код приложения.
- Жестко закодированные значения:Хранение кодов состояния, таких как «active» или «inactive», в виде целых чисел без таблицы сопоставления делает систему хрупкой. Если вам нужно добавить «suspended», вы должны изменить логику повсюду.
- Пренебрежение мягким удалением:Постоянное удаление данных удаляет историю. Проектирование с учетом мягкого удаления (пометка записи как удаленной, а не ее удаление) сохраняет следы аудита.
- Чрезмерная сложность:Проектирование для использования, которое еще не существует. Создавайте для текущих требований, но убедитесь, что схема достаточно гибкая, чтобы справиться с разумным ростом.
Каждая из этих ловушек добавляет слои сложности в ваш код. Диаграмма ERD помогает визуализировать эти проблемы до того, как они станут частью рабочей среды.
От диаграммы к реализации 🚀
Как только ERD будет завершена, следующим шагом является перевод ее в код. Этот процесс, часто называемый миграцией схемы, требует дисциплины.
Следуйте этим шагам, чтобы обеспечить плавный переход:
- Контроль версий:Воспринимайте схему базы данных как код приложения. Каждое изменение должно быть файлом миграции, хранящимся в вашем репозитории.
- Совместимость с предыдущими версиями: При добавлении столбца сначала сделайте его допускающим null. Заполните существующие данные, а затем в последующей миграции установите ограничение. Это предотвращает простои.
- Тестирование миграций: Запускайте скрипты миграции в среде тестирования, идентичной продакшну. Проверьте наличие регрессий производительности.
- Планы отката: Всегда должен быть способ отменить миграцию, если она не удалась. Потеря данных неприемлема.
Автоматизированные инструменты могут помочь в генерации SQL из ERD, но ручной контроль критически важен. Автоматические генераторы часто упускают нюансы бизнес-логики, которые заметит человек-архитектор.
Совместная работа и коммуникация 🤝
ERD — это не только для администраторов баз данных. Это инструмент коммуникации для всей команды. Менеджеры продуктов, разработчики фронтенда и инженеры по тестированию все выигрывают от понимания структуры данных.
Когда заинтересованные стороны просматривают ERD, они могут выявить потенциальные проблемы на ранней стадии:
- Возможность реализации функции: Может ли база данных поддерживать запрашиваемую функцию? Если нет, какие изменения необходимы?
- Ожидания производительности: Разработка позволяет эффективный запрос при масштабировании?
- Требования к безопасности: Выделены ли чувствительные поля и защищены ли они? Возможен ли контроль доступа на уровне данных?
Это общее понимание снижает напряженность во время планирования спринтов. Вместо догадок о том, как данные перемещаются, команда обсуждает это на основе визуальной модели. Разногласия разрешаются с опорой на диаграмму, а не на мнение.
Рассмотрение масштабируемости 📈
По мере роста вашего приложения ваша модель данных должна эволюционировать. Диаграмма отношений сущностей помогает вам предвидеть эти изменения. Она позволяет визуализировать, как добавление новой сущности влияет на существующие отношения.
Ключевые факторы масштабируемости, которые следует учитывать при проектировании:
- Стратегия индексации:Определите, какие столбцы будут часто запрашиваться. Планируйте индексы для этих полей, чтобы ускорить извлечение данных.
- Разделение:Будут ли определенные таблицы слишком большими? При необходимости планируйте горизонтальное разделение.
- Разделение чтения и записи:Поддерживает ли дизайн отдельные реплики для чтения и записи? Убедитесь, что внешние ключи не усложняют репликацию.
- Уровни кэширования:Как модель данных взаимодействует с системами кэширования? Неизменяемые данные легче кэшировать, чем часто изменяющиеся.
Раннее планирование масштабирования предотвращает необходимость полной переписи позже. Легче добавить новую таблицу, чем переносить данные с одного сервера на другой.
Заключительные мысли о архитектуре данных 🧠
Вложения усилий на создание подробной диаграммы отношений сущностей окупаются на протяжении всего жизненного цикла проекта. Это превращает моделирование данных из реактивной рутины в стратегический актив. Визуализируя отношения, обеспечивая ограничения и планируя рост, вы создаете надежные и поддерживаемые системы.
Не рассматривайте базу данных как после мысленное дополнение. Это фундамент вашего приложения. Вложитесь в этап проектирования, и в долгосрочной перспективе вы сэкономите недели работы на бэкенде. Тихая сила диаграммы отношений сущностей заключается в её способности предотвращать проблемы до того, как они вообще возникнут.
Начните создавать карту своих данных уже сегодня. Четкость, которую вы получите, станет разницей между хаотичным кодом и оптимизированной системой.