











ソフトウェア開発の道を歩み始めるとき、多くの場合、白紙から始まります。要件の作成、アーキテクチャの図示、またはデータベーススキーマの計画を行う際、アイデアを視覚的に表現することは非常に重要です。このプロセスにおける最も基本的なツールの一つが、Entity Relationship Diagram(ERD)と呼ばれるもので、これはデータの格納と取得のための設計図です。このガイドでは、特定のツールではなく、原則に焦点を当てながら、基礎から強固なERDを作成する手順を丁寧に説明します。
なぜエンティティ関係図(ERD)が重要なのか 🔍
1つのボックスや線を描く前に、図の目的を理解することが不可欠です。ERDは単なる絵ではなく、データの保存と取得のための設計図です。データの構造や、さまざまな情報の間の関係を明確に定義します。明確な計画がなければ、データベースは混乱し、重複や一貫性の欠如、保守の困難さが生じます。
-
明確さ: 複雑なデータ関係を、ステークホルダーが理解できる視覚的な形式に変換します。
-
コミュニケーション: 開発者、データベース管理者、ビジネスアナリストの間で共通の言語として機能します。
-
検証: コードを書く前に論理的な誤りを発見できるようにします。
-
ドキュメント化: システムのデータアーキテクチャの歴史的記録を提供します。
ERDの核心的な構成要素 📦
図を構築するには、その構成要素を理解する必要があります。すべての図は、3つの主要な要素で構成されています:エンティティ、属性、関係。
1. エンティティ 🏢
エンティティとは、システム内に存在する明確なオブジェクトや概念を表します。データベースの文脈では、通常はテーブルに対応します。エンティティは具体的なもの(例:)顧客 または 製品、あるいは抽象的なもの(例:)注文 または サブスクリプション.
-
識別子: すべてのエンティティには、他のものと区別できる独自の方法が必要です。これを通常、プライマリキーと呼びます。
-
名前: 明確さのために単数名詞を使用してください(例:)本 ではなく 本).
-
複数形:一貫性を保つために、図内のエンティティ名を複数形にしないでください。
2. 属性 🏷️
属性はエンティティの特性を記述します。それらは、そのエンティティについて保存される情報の内容を定義します。たとえば、顧客エンティティには、名前, メールアドレス、および電話番号.
-
データ型:属性には、テキスト、数値、日付、論理値などの特定の型があります。
-
制約:一部の属性は必須(NULL不可)ですが、他の属性は空値を許可します。
-
キー:主キー(一意のID)と外部キー(別のエンティティへのリンク)を区別してください。
3. 関係 🔗
関係はエンティティどうしがどのように相互作用するかを定義します。データポイント間の関連を記述します。関係は2つのエンティティを結びつけ、それらが互いにどのように影響し合うかを示します。
-
方向:関係は片方向または双方向であることができますが、データベースではしばしば有向リンクとして保存されます。
-
基数:これは数値的な関係(例:1対多)を定義します。
-
参加:関係が必須かオプションかを決定します。
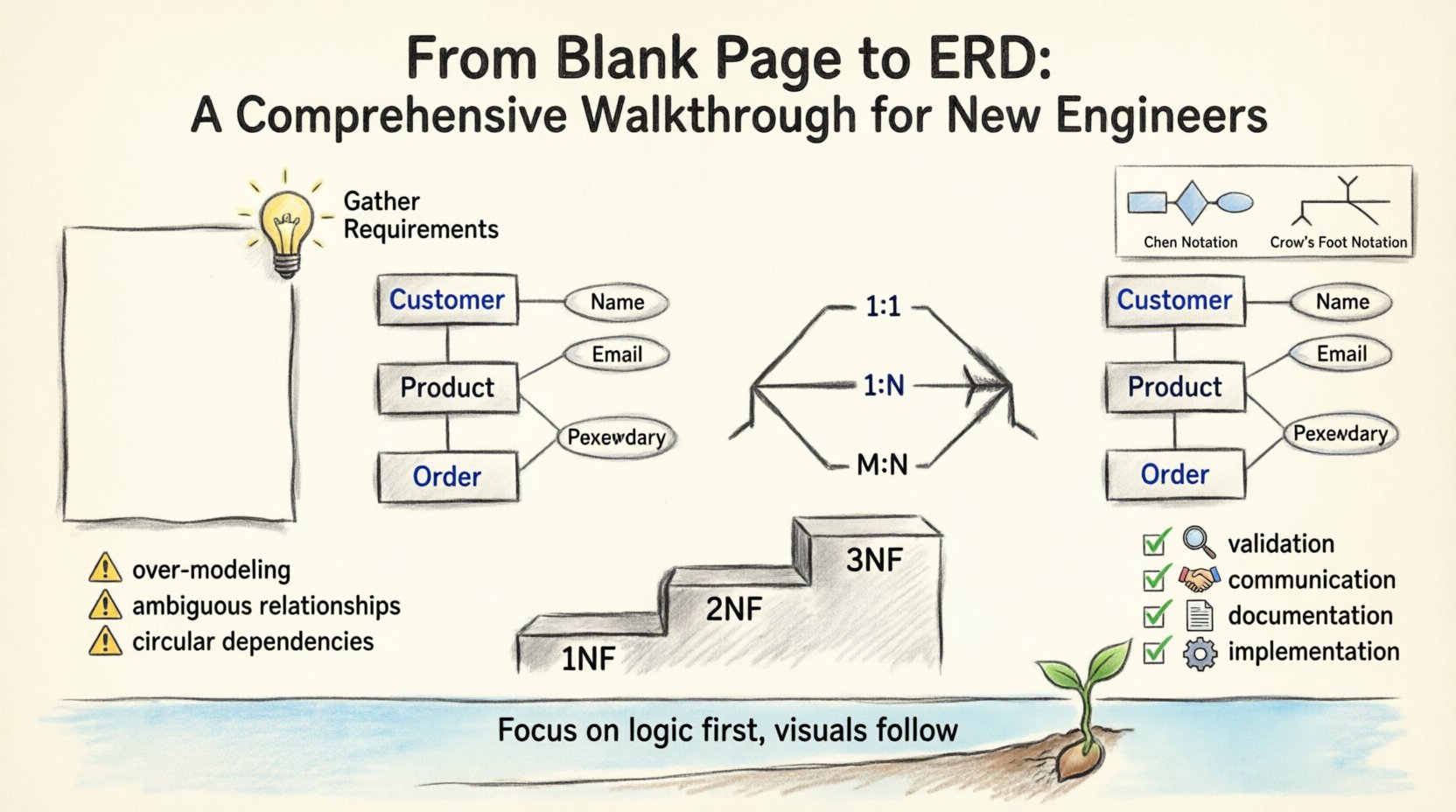
基数の理解 ⚖️
基数はERDにおいて最も重要な要素です。あるエンティティのインスタンスが別のエンティティと何個関係を持つかを規定します。基数を誤解することは、データベース設計上の欠陥の主な原因です。
|
タイプ |
説明 |
例 |
|---|---|---|
|
1対1 (1:1) |
エンティティAの単一のインスタンスが、エンティティBの正確に1つのインスタンスに関連する。 |
1つ従業員は1つ持つIDカード. |
|
1対多 (1:N) |
エンティティAの単一のインスタンスが、エンティティBの複数のインスタンスに関連する。 |
1つ顧客は多数の注文. |
|
多対多 (M:N) |
エンティティAの複数のインスタンスが、エンティティBの複数のインスタンスに関連する。 |
多数の学生は多数の授業. |
データベースを設計する際、多対多の関係は通常、中間テーブルを導入することで解決される。この中間テーブルは、接合テーブルまたは関連テーブルと呼ばれることが多い。これにより、M:Nの関係が2つの1:Nの関係に分解される。
表記スタイル 🎨
ERDを視覚的に表現する方法はいくつかある。根本的な論理は同じだが、記号は変わる。
チェン表記
-
エンティティ:長方形で表される。
-
関係:ダイヤモンドで表される。
-
属性:エンティティに接続された楕円で表される。
このスタイルは初心者にとって非常に明確だが、現代のデータベース実装ツールではあまり一般的ではない。
クロウズフット表記法
-
エンティティ:長方形で表される。
-
関係:エンティティを結ぶ線で表される。
-
基数:線の端に記号で示される(例:「多数」を表すクロウズフット)。
これはリレーショナルデータベース設計の業界標準である。コンパクトで読みやすく、そのためである。
ステップバイステップの作成プロセス 🛠️
ERDを作成することは一度きりの出来事ではない。プロジェクトが成長するにつれて進化するプロセスである。しっかりとした基盤を確保するためには、以下のステップに従ってください。
ステップ1:要件を収集する 📝
図を描く前に、関係者と話し合いましょう。どのようなデータを収集する必要があるかを理解します。次のような質問をしましょう:
-
どのような情報を追跡しなければならないか?
-
データ保持に関して、規制上の制約はあるか?
-
ユーザーはこのデータをどのように検索または絞り込むつもりか?
-
このデータからどのようなレポートが生成されるか?
ステップ2:エンティティを特定する 🎯
要件を検討し、異なる対象を表す名詞をすべてリストアップする。図書館システムの場合、これらは書籍, 著者, 会員、および貸出記録ストレージが必要ない一般的な用語を除外してください。
ステップ3:属性を定義する 🔑
各エンティティについて、必要な詳細をリストアップしてください。過剰なモデル化に注意してください。あるフィールドが他のフィールドから導出できる場合は、ソースのみを保存してください。たとえば、生年月日 ではなく 年齢.
ステップ4:関係性を確立する 🔄
エンティティ間の接続を示すために線を引きます。次のように尋ねてください:
-
会員は本を借りるか?
-
本は複数の著者を持つか?
-
著者は、彼らが書いた本とは独立しているか?
各線に基数をマークしてください。すべての関係性がビジネスロジックに必要であることを確認してください。
ステップ5:データを正規化する 🔍
正規化は冗長性を減らし、データの整合性を向上させます。属性とテーブルの整理を含みます。
-
第一正規形(1NF):重複する列を排除し、原子的な値を保証してください。
-
第二正規形(2NF):部分的依存関係を排除してください(すべての属性が主キー全体に依存していることを確認してください)。
-
第三正規形(3NF):推移的依存関係を排除してください(属性が主キーのみに依存していることを確認してください)。
避けるべき一般的な落とし穴 ⚠️
経験豊富なエンジニアでさえミスを犯します。一般的な誤りに気づいておくことで、後の時間の節約になります。
1. 過剰なモデル化
完璧さのためにあまりにも多くのテーブルを作成すると、システムが硬直化します。シンプルなスタートを心がけましょう。テーブルがほとんど使われない場合は、必要ない可能性があります。
2. 不明確な関係性
基数のマークがない線を残さないでください。曖昧さは実装時に混乱を招きます。常に関係性がオプションか必須かを明確に指定してください。
3. データ型を無視する
図は構造に注目していますが、データ型も意識してください。電話番号を数値ではなくテキストとして保存すると、後で検証の問題が発生する可能性があります。
4. 円環依存
エンティティAがBに依存し、BがAに依存する状況を避けること。これによりデータ挿入時にデッドロックが発生し、クエリが複雑化する。
5. 名前の不整合
図全体で一貫した命名規則を使用する。もし「UserID」という名前を1か所で使用するなら、別の場所で「User_ID」に切り替えてはならない。
保守性のためのベストプラクティス 🛡️
図は動的な文書である。システムの進化に応じて常に更新されなければならない。関連性を保つためのヒントを以下に示す。
-
バージョン管理:図をコードのように扱う。変更の履歴を追跡できるように、バージョンを保存する。
-
ドキュメント:線だけでは明確でない複雑な関係性やビジネスルールを説明するために、メモを追加する。
-
レビューのサイクル:チームと定期的なレビューをスケジュールし、設計が現在の要件と一致していることを確認する。
-
コードとのリンク:可能な限り、図を実際のデータベーススキーマやマイグレーションスクリプトとリンクする。
複雑なシナリオの扱い 🧭
時として、標準的な図だけでは不十分である。特殊なケースに直面することがある。
再帰的関係
これは、エンティティが自分自身と関係するときに発生する。よくある例は「Employee」エンティティで、1人の従業員が別の従業員を管理する場合である。図では、同じ長方形に戻る線のように見える。
継承とサブタイプ化
エンティティが共通の属性を共有しているが、特定の違いがある場合、一般化を使用する。例えば、「Vehicle」は「Car」と「Truck。これは、実装に応じて特別な記号や別々のテーブルを使用して表現できる。
弱いエンティティ
弱いエンティティは、その存在のために他のエンティティに依存する。親エンティティが存在しない限り、一意に識別することはできない。図では、しばしば二重の長方形や特定の線のスタイルで示される。
図から実装へ 🚀
ERDが最終化されると、データベーススキーマの信頼できる唯一の情報源となる。翻訳プロセスには以下の内容が含まれる:
-
エンティティをテーブルにマッピングする: 各エンティティはテーブルになる。
-
属性を列にマッピングする: 各属性は、明確に定義されたデータ型を持つ列になる。
-
キーのマッピング: 主キーは一意の識別子になる;外部キーは参照になる。
-
関係のマッピング: 1対多の関係は、通常「多」側のテーブルに外部キーが生成される。
この段階では細部への注意が求められる。図の小さな誤りがデータベースの破損につながる可能性がある。本番環境にデプロイする前に、生成されたスキーマを図と照合して常に検証すること。
作業のレビュー 👁️
最終化する前に、図の自己監査を行う。
|
チェックリスト項目 |
合格/不合格 |
|---|---|
|
すべてのエンティティが単数名詞になっているか? |
☐ |
|
すべての関係が基数でラベル付けされているか? |
☐ |
|
循環依存関係は存在しないか? |
☐ |
|
すべてのテーブルに主キーが定義されているか? |
☐ |
|
外部キーがテーブル間で一貫しているか? |
☐ |
データ設計に関する最終的な考察 🌱
ERDを設計することは、練習を重ねるほど向上するスキルである。理論的知識と実践的応用のバランスが求められる。すべての状況に当てはまる唯一の「完璧な」図は存在しない。最も良い図とは、ビジネスニーズを正確に反映しつつ、将来の変化に柔軟に対応できるように設計されたものである。
まず論理に注目し、視覚的な表現はその後に来る。初期段階では時間をかけて取り組むこと。紙の上で線を動かすのは、本番環境のテーブルを変更するよりもはるかに簡単である。これらの構造化されたステップに従い、一般的な落とし穴を避けることで、あらゆるデータ駆動型アプリケーションの堅固な基盤を築くことができる。
思い出してください。目的は単に図を描くことではなく、情報のための明確で効率的かつ保守可能な構造を作ることです。エンジニアリングのキャリアを積むにつれて、データの関係を視覚化する能力が、あなたが持つことができる最も価値のあるスキルの一つであることに気づくでしょう。
学び続け、磨き続け、常に複雑さよりも明確さを最優先にすること。