









Создание надежной модели данных — одна из самых важных задач в инженерии программного обеспечения. Диаграмма сущность-связь (ERD) служит чертежом для хранения, извлечения и поддержания информации. В центре этого чертежа находится нормализация. Многие специалисты подходят к нормализации как к жесткому чек-листу, который необходимо выполнить перед началом реализации. Однако реальность гораздо сложнее. Существует тонкий баланс между целостностью данных и производительностью запросов, который требует глубокого понимания.
Это руководство исследует технические реалии нормализации ERD. Оно выходит за рамки учебных определений, чтобы рассмотреть практические сценарии, в которых строгое следование правилам становится угрозой. Независимо от того, создаете ли вы транзакционную систему или аналитическую платформу, знание того, когда остановиться на нормализации и когда ввести избыточность, является ключевым для долгосрочной стабильности.
🔍 Понимание основных принципов реляционного проектирования
Нормализация — это не просто организация данных; это управление зависимостями. В реляционной модели каждый столбец должен иметь четкую связь с первичным ключом своей таблицы. Когда эта связь слабая или косвенная, возникают аномалии. Эти аномалии проявляются в несогласованности данных, потраченном хранилище и сложной логике обновления.
Основные цели нормализации включают:
- Целостность данных: Обеспечение точности и согласованности данных во всей системе.
- Эффективность хранения: Устранение избыточных копий одних и тех же данных.
- Масштабируемость: Проектирование схем, которые могут адаптироваться к росту без переписывания структуры.
- Поддерживаемость: Снижение сложности, необходимой для обновления информации.
Однако достижение этих целей часто сопряжено с затратами. Каждый уровень нормализации, как правило, увеличивает количество таблиц и сложность запросов, необходимых для извлечения объединенных данных. Понимание этого компромисса — первый шаг к эффективному проектированию схемы.
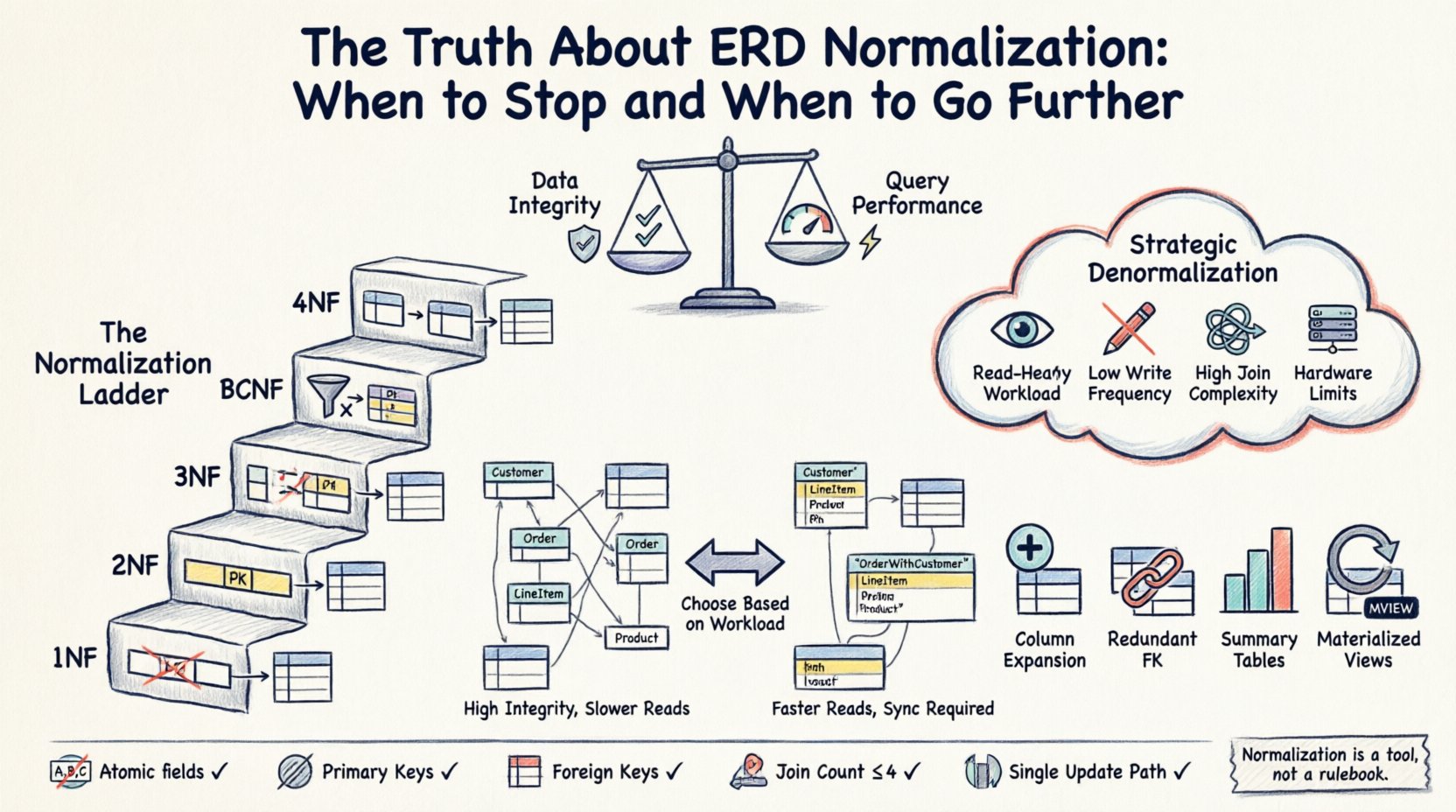
⚙️ Три основы стандартной нормализации (1НФ, 2НФ, 3НФ)
Прежде чем решить, остановиться или пойти дальше, необходимо понимать базовый уровень. Стандартные формы представляют собой ступени структурной доработки.
Первое нормальное состояние (1НФ)
Основа любой реляционной базы данных — это 1НФ. Таблица находится в 1НФ, если она соответствует следующим критериям:
- Все значения столбцов атомарны (неделимы).
- Каждый столбец содержит значения одного типа.
- В строке нет повторяющихся групп или массивов.
Например, хранение списка названий продуктов в одном столбце нарушает 1НФ. Вместо этого каждому продукту должно соответствовать отдельное поле. Хотя современные системы часто работают с сложными типами данных, строгое соблюдение атомарности гарантирует, что запросы будут предсказуемыми, а стратегии индексации будут работать так, как задумано.
Второе нормальное состояние (2НФ)
Как только таблица находится в 1НФ, она должна соответствовать требованиям 2НФ. Эта форма применяется специально к таблицам с составными первичными ключами (ключами, состоящими из нескольких столбцов). Таблица находится в 2НФ, если:
- Она уже находится в 1НФ.
- Все атрибуты, не являющиеся ключевыми, полностью зависят от всего первичного ключа, а не только от его части.
Рассмотрим таблицу деталей заказа, где ключ — это комбинация ID заказа и ID продукта. Если вы храните название продукта в этой таблице, у вас возникает частичная зависимость. Название продукта зависит только от ID продукта, а не от ID заказа. Чтобы исправить это, вы перемещаете название продукта в отдельную таблицу «Продукты». Это уменьшает аномалии обновления; если название продукта изменится, вы обновите его в одном месте, а не в тысячах записей заказов.
Третье нормальное состояние (3НФ)
3НФ часто считается оптимальным уровнем для большинства операционных систем. Таблица находится в 3НФ, если:
- Он находится в 2НФ.
- Нет транзитивных зависимостей. Неключевые атрибуты должны зависеть только от первичного ключа.
Транзитивная зависимость возникает, когда столбец А определяет столбец В, а столбец В определяет столбец С. В базе данных, если ID клиента определяет город, а город определяет регион, хранение региона в таблице клиентов создает транзитивную зависимость. Если регион изменится для этого города, необходимо обновить каждую запись клиента в этом городе. Нормализация этого устраняет зависимость, перемещая данные региона в отдельное место, что гарантирует, что обновления происходят только один раз.
📉 Стоимость производительности строгой нормализации
Хотя 3НФ минимизирует избыточность, она максимизирует количество таблиц. В нормализованной схеме получение одного логического записей часто требует объединения нескольких таблиц. Этот процесс имеет вычислительную стоимость.
- Накладные расходы на соединение: Каждая операция соединения требует от базы данных сопоставлять строки из разных таблиц. По мере роста размеров таблиц этот процесс потребляет ЦП и память.
- Операции ввода-вывода: Данные, распределенные по многим таблицам, требуют большего количества чтений с диска. Если данные не кэшируются эффективно, задержка чтения увеличивается.
- Сложность: Сложные запросы с большим количеством соединений труднее оптимизировать и поддерживать. Они также чаще ломаются при изменении схемы.
Для систем с высокой нагрузкой на запись нормализация обычно является правильным выбором. Она предотвращает дублирование данных и гарантирует, что обновление одного факта корректно распространяется. Однако для систем с высокой нагрузкой на чтение стоимость соединений может стать узким местом.
🚀 Стратегическая денормализация: когда нарушать правила
Денормализация — это сознательное введение избыточности для оптимизации производительности. Это не ошибка; это сознательное архитектурное решение, принимаемое тогда, когда стоимость нормализации превышает её преимущества.
Причины денормализации
Вы должны рассмотреть возможность ослабления правил нормализации, когда:
- Операции чтения доминируют: Если ваше приложение ориентировано на чтение (например, панель отчетов), сокращение соединений может значительно снизить задержку.
- Сложность запросов высока: Если пользователям требуется данные из 10 и более таблиц для просмотра одной страницы, запрос становится медленным и трудным для отладки.
- Частота записи низкая: Если данные редко обновляются, риск несогласованности из-за избыточности минимизируется.
- Существуют ограничения по оборудованию: В средах, где ввод-вывод на диск дорог или ограничен, кэширование избыточных данных может снизить количество физических чтений.
Распространённые стратегии денормализации
- Расширение столбцов: Хранение производного значения непосредственно в таблице. Например, добавление столбца «Общая цена» в таблицу заказов, рассчитанного из строк заказов, чтобы не нужно было суммировать их при каждом чтении.
- Избыточные внешние ключи: Добавление идентификатора родителя в таблицу дочерних элементов, чтобы избежать соединения при получении иерархии.
- Таблицы сводок: Предварительное вычисление агрегатов (счетчиков, сумм) в отдельной таблице, которая обновляется периодически или с помощью триггеров.
- Материализованные представления:Хранение результата сложного запроса в виде физической таблицы, которая обновляется по расписанию.
📊 Сравнение: Нормализация против денормализации
Чтобы визуализировать компромиссы, рассмотрите следующую сравнительную таблицу.
| Аспект | Высокая нормализация (3НФ+) | Денормализованный дизайн |
|---|---|---|
| Целостность данных | Высокая – единый источник истины | Ниже – требуется логика синхронизации |
| Использование хранилища | Эффективное – без дубликатов | Неэффективное – избыточные данные |
| Производительность записи | Быстрое – обновление одной строки | Медленное – обновление нескольких строк |
| Производительность чтения | Медленное – требуется выполнение соединений | Быстрое – прямой доступ |
| Сложность запроса | Высокая – требуется много соединений | Низкая – простые запросы |
| Уровень усилий по обслуживанию | Низкий – обновление один раз | Высокий – синхронизация в нескольких местах |
Эта таблица показывает, что нет универсальной лучшей практики. Выбор полностью зависит от конкретной рабочей нагрузки приложения.
🛠️ Рамочная модель для проектирования схемы
Чтобы определить правильный уровень нормализации для вашего конкретного проекта, используйте эту рамочную модель. Оцените каждый пункт с учетом требований вашего проекта.
1. Проанализируйте паттерн рабочей нагрузки
Определите соотношение чтений к записям. Если ваша система является OLTP (обработка онлайн-транзакций), уделяйте приоритет целостности и 3НФ. Если это OLAP (аналитическая обработка онлайн), уделяйте приоритет скорости чтения и рассмотрите денормализацию.
2. Оцените требования к свежести данных
Данные должны быть в режиме реального времени? Если вы денормализуете данные, между обновлением источника и отражением изменений в избыточных данных возникнет задержка. Если пользователям нужна немедленная согласованность, строгая нормализация будет безопаснее.
3. Оцените частоту обновлений
Посмотрите на первичные ключи. Если таблица справочника (например, список стран) редко изменяется, денормализация её данных в транзакционные таблицы безопасна. Если таблица справочника часто изменяется, оставьте её отдельно, чтобы минимизировать ошибки синхронизации.
4. Учитывайте аппаратные средства и кэширование
Современные базы данных часто кэшируют данные в оперативной памяти. Если ваш рабочий набор помещается в ОЗУ, стоимость операций соединения уменьшается. В этом случае вы можете позволить себе немного более нормализованную схему, не жертвуя производительностью.
🧠 Расширенная нормализация: BCNF и 4NF
Помимо 3НФ существуют более высокие формы, такие как форма Бойса-Кодда (BCNF) и четвёртая нормальная форма (4NF). Они решают конкретные крайние случаи.
Форма Бойса-Кодда (BCNF)
BCNF — более строгая версия 3НФ. Она решает случаи, когда непримарный атрибут определяет другой непримарный атрибут, даже если первичный ключ составной. Хотя теоретически идеальна, BCNF иногда приводит к потере сохранения зависимостей. На практике 3НФ часто достаточно, а принудительное применение BCNF может усложнить схему без значительной выгоды.
Четвёртая нормальная форма (4NF)
4NF решает многозначные зависимости. Это происходит, когда одна строка содержит несколько независимых списков значений. Например, таблица студентов, хранящая несколько хобби и несколько занятий в одной строке. Это редкость в стандартных бизнес-приложениях, но распространено в специализированных сценариях моделирования данных.
🚫 Распространённые ошибки, которых следует избегать
Даже при хорошем понимании нормализации легко допустить ошибки. Избегайте этих распространённых ошибок:
- Чрезмерная нормализация:Создание сотен маленьких таблиц для простых связей. Это делает логику приложения трудночитаемой и замедляет разработку.
- Пренебрежение индексами:Нормализованная схема требует соединений. Если столбцы соединения не проиндексированы, производительность будет снижаться независимо от дизайна схемы.
- Денормализация без контроля:Введение избыточности без плана синхронизации приводит к повреждению данных со временем.
- Жёсткое кодирование логики:Не вычисляйте производные значения в слое приложения, если они должны находиться в базе данных. Держите бизнес-правила близко к данным.
✅ Чек-лист для проверки схемы
Перед развертыванием новой схемы пройдите по этому чек-листу проверки.
- Атомарность: Все ли поля атомарны?
- Первичные ключи: Каждая таблица имеет уникальный первичный ключ?
- Внешние ключи: Ограничения отношений осуществляются с помощью внешних ключей?
- Избыточность: Есть ли очевидные повторяющиеся группы данных?
- Количество соединений: Требуют ли критические запросы более чем 3–4 соединений?
- Путь обновления: Можно ли внести изменение одного элемента данных в одном месте?
🔗 Заключение по архитектуре данных
Нормализация — это инструмент, а не свод правил. Она существует для защиты ваших данных от несогласованности, но не должна мешать вашему приложению эффективно работать. «Правда» о нормализации ERD заключается в том, что это спектр. Вы начинаете с сильно нормализованной структуры для обеспечения целостности, а затем постепенно денормализуете её в зависимости от потребностей производительности.
Нет универсального решения. Система высокочастотной торговли будет сильно отличаться от системы управления контентом. Ключевым является понимание основных механизмов зависимостей и соединений. Сбалансировав стоимость хранения данных и стоимость вычислений, вы сможете создавать системы, которые будут надежными и быстрыми.
При дальнейшем проектировании помните, что эволюция схемы неизбежна. Планируйте изменения. Используйте версионирование для миграций базы данных. И всегда тестируйте свои запросы под нагрузкой, прежде чем принимать решение о структуре. Лучшая схема — та, которая поддерживает ваши бизнес-цели, не становясь узким местом.