











Каждое приложение начинается с идеи. Эта идея требует хранения данных, а хранение данных требует чертежа. Этот чертеж — диаграмма сущностей и отношений (ERD). Это основной документ, определяющий, как ваша система понимает информацию. Однако чертеж для небольшого сарая не подходит для небоскреба. Аналогично, схема базы данных, разработанная для прототипа, часто не выдерживает нагрузки производственного трафика и сложной бизнес-логики.
Понимание эволюции ERD критически важно для технических руководителей, администраторов баз данных и архитекторов программного обеспечения. Это требует баланса между гибкостью и целостностью. По мере роста пользовательской базы ваши требования к данным меняются. Вы не можете просто навсегда оставлять исходную модель. Ее необходимо адаптировать. В этом руководстве рассматривается жизненный цикл модели данных — от первого фрагмента кода до архитектуры масштаба предприятия.
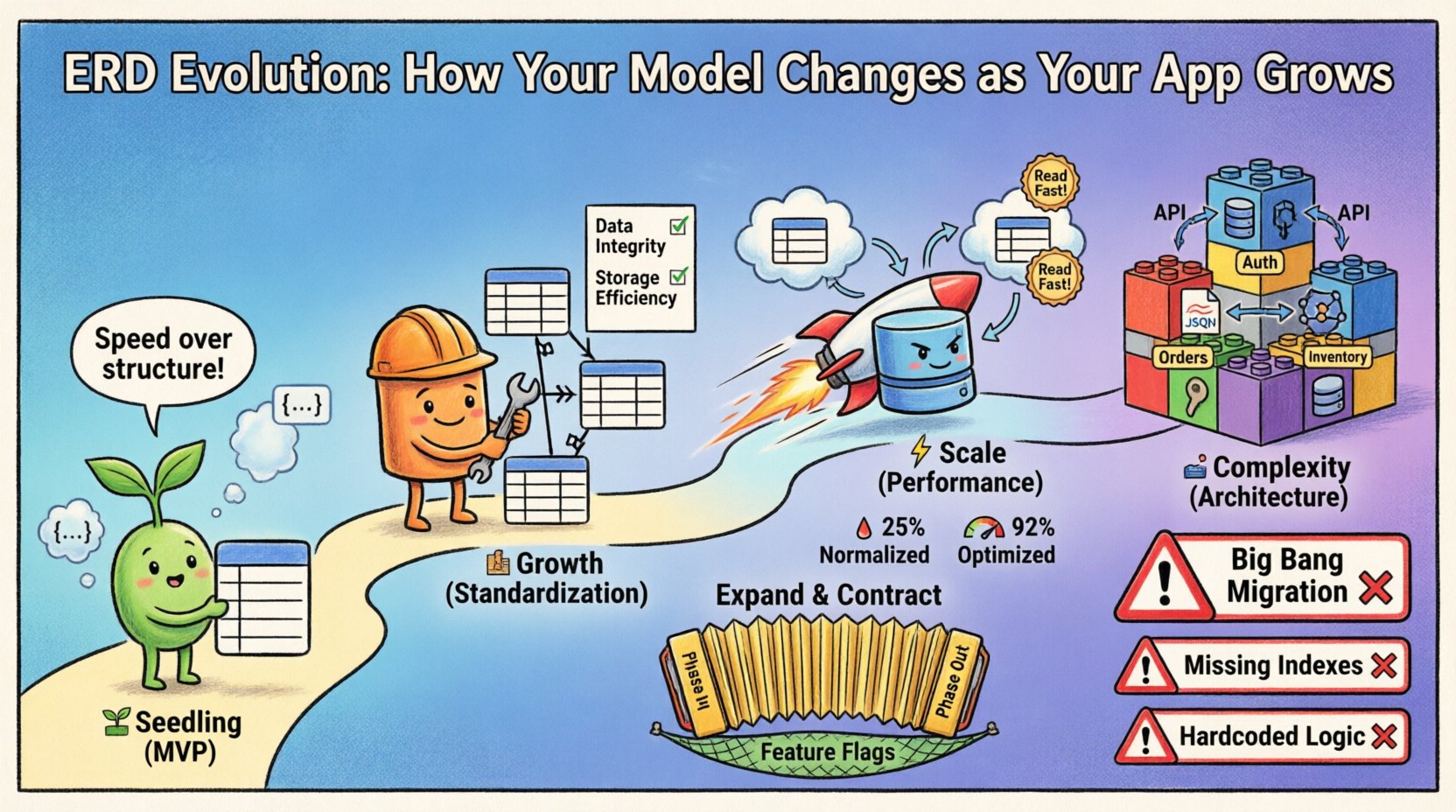
Этап 1: Этап проростка (MVP) 🌱
В начале основным показателем является скорость. Цель — проверить основную гипотезу с минимальным сопротивлением. На этом этапе ERD часто нестабилен, отражая текущие потребности, а не долгосрочные прогнозы.
- Фокус:Функциональность важнее структуры.
- Структура:Плоские схемы являются распространёнными. Связи часто не нормализованы, чтобы снизить сложность операций соединения.
- Ограничения:Внешние ключи могут быть ослаблены или опущены, чтобы обеспечить быструю итерацию.
- Изменения:Изменения схемы происходят еженедельно, иногда ежедневно.
На этом этапе вы можете увидеть сущности, тесно связанные между собой. Например, таблица Пользователь может содержать JSON-объект с настройками профиля вместо отдельной таблицы Профиль таблицы. Это уменьшает необходимость в соединениях, ускоряя операции чтения для панели управления. Однако это создаёт технический долг. По мере зрелости приложения запросы к вложенным данным становятся медленнее и сложнее в поддержке.
Ключевые характеристики моделей на ранних этапах
- Минимальные ограничения внешних ключей.
- Гибкие типы столбцов (например, использование VARCHAR для всего).
- Одна база данных.
- Прямое отображение объектов приложения на таблицы базы данных.
Этап 2: Этап роста (стандартизация) 🏗️
Как только продукт набирает популярность, первоначальная гибкость становится недостатком. Дублирование данных приводит к несогласованности. Если пользователь обновляет свой адрес электронной почты в одном месте, но не в другом, система теряет доверие. Это этап, когда нормализация становится приоритетом.
Зачем нормализовать сейчас?
- Целостность данных: Обеспечение целостности ссылок предотвращает появление «сиротских» записей.
- Эффективность хранения: Удаление избыточных данных экономит место на диске.
- Поддерживаемость:Обновление одного записей в нормализованной таблице обновляет ее везде логически.
- Предсказуемость запросов:Стандартизированные структуры делают написание запросов менее подверженным ошибкам.
Во время этого перехода вы должны рефакторить ERD. Плоская таблица пользователей может быть разделена наПользователи и Сведения о пользователе. Это вводит отношения. Вам нужно определить, являются ли они один к одному, один ко многим или многие ко многим.
Чек-лист перехода
- Определите все дублирующиеся поля по всем таблицам.
- Определите первичные ключи для всех сущностей.
- Реализуйте ограничения внешнего ключа для обеспечения связей.
- Просмотрите существующие запросы на предмет влияния новых соединений на производительность.
- Планируйте совместимость с предыдущими версиями во время миграции.
Этап 3: Этап масштабирования (производительность) ⚡
Когда существуют миллионы записей, нормализованная структура может стать узким местом. Соединения становятся вычислительно затратными при масштабировании. Именно здесь модель снова эволюционирует, часто уходя от строгой нормализации к стратегической денормализации для повышения производительности.
Стратегическая денормализация
Это не возврат к этапу MVP. Это обдуманное решение. Вы сознательно дублируете данные, чтобы избежать дорогостоящих соединений на больших таблицах.
- Нагрузки с преобладанием чтения: Если ваше приложение в основном предназначено для чтения, кэширование данных в схеме снижает нагрузку на базу данных.
- Таблицы отчетов:Предварительно агрегированные данные для панелей управления избегают вычисления сумм в реальном времени.
- Разделение: Разделение таблиц по дате или региону требует специального проектирования схемы для обеспечения эффективного запроса.
Сравнение: Нормализованная vs. Оптимизированная
| Функция | Нормализованная (этап 2) | Оптимизированная (этап 3) |
|---|---|---|
| Целостность | Высокая (обеспечивается базой данных) | Управление логикой приложения |
| Скорость записи | Быстро | Медленнее (обновление нескольких таблиц) |
| Скорость чтения | Медленнее (требует соединений) | Быстро (один запрос) |
| Хранение | Эффективно | Менее эффективно (избыточность) |
Этап 4: Этап сложности (архитектура) 🏛️
На уровне предприятия одиночной модели базы данных часто бывает недостаточно. Система может разделяться на микросервисы или использовать полиглотное хранение данных. ERD больше не представляет собой единую физическую диаграмму, а представляет собой совокупность моделей, взаимодействующих между собой.
Микросервисы и владение данными
В монолитной архитектуре таблица Заказы таблица используется службами выставления счетов, доставки и уведомлений. В распределённой системе каждая служба владеет своими данными. Это требует изменения подхода к моделированию отношений.
- Потенциальная согласованность: Вы не можете полагаться на транзакции ACID между службами. ERD должен учитывать синхронизацию состояния.
- Договоры API: Отношения часто определяются ответами API, а не внешними ключами.
- Синхронизация данных: Необходимы инструменты для поддержания согласованности данных между различными хранилищами (например, SQL для заказов, NoSQL для журналов).
Полиглотное хранение данных
Разные данные требуют разных систем хранения. ERD развивается, включая нереляционные концепции.
- Графовые данные: Для социальных сетей или систем рекомендаций модель графа заменяет реляционные таблицы.
- Хранилища документов: Для гибкого содержимого, такого как каталоги товаров, документы JSON заменяют жесткие столбцы.
- Хранилища пар «ключ-значение»: Для управления сессиями и кэширования простые пары ключ-значение заменяют сложные строки.
Техническое глубокое погружение: Уровни нормализации 🔬
Чтобы эффективно развивать свою модель, вы должны понимать правила, которые вы соблюдаете или нарушаете. Нормализация — это процесс организации данных для уменьшения избыточности.
Первое нормальное формат (1НФ)
- Атомарные значения: каждый столбец содержит только одно значение.
- Нет повторяющихся групп: вы не можете иметь столбцы, такие как
цвет1,цвет2,цвет3. - Уникальные идентификаторы: каждая строка должна быть уникально идентифицируемой.
Второе нормальное формат (2НФ)
- Должно находиться в 1НФ.
- Все атрибуты, не являющиеся ключевыми, должны полностью зависеть от первичного ключа.
- Устраняет частичные зависимости (например, перемещение информации о поставщике в отдельную таблицу, если она зависит только от ID поставщика, а не от ID заказа).
Третье нормальное формат (3НФ)
- Должно находиться в 2НФ.
- Устраняются транзитивные зависимости.
- Столбец не может зависеть от другого неключевого столбца (например,
Городзависит отШтат, а не толькоПочтовый индекс). ПереместитеГородиШтаткМестоположениетаблица.
Распространенные ошибки при эволюции ERD ⚠️
Даже опытные команды допускают ошибки при рефакторинге моделей. Признание этих паттернов помогает избежать дорогостоящего простоя.
1. Миграция «Большого взрыва»
Попытка изменить всю схему в одном развертывании. Это несет высокий риск. Если скрипт миграции не удался, система будет сломана.
- Решение: Используйте пошаговые миграции. Добавьте столбцы, заполните данные, переключите логику, затем удалите старые столбцы.
2. Пренебрежение последствиями индексации
Изменение связей изменяет паттерны запросов. Новая связь внешнего ключа может потребовать нового индекса для хорошей производительности.
- Решение: Проанализируйте журналы медленных запросов до и после изменений схемы.
- Решение: Планируйте создание индексов в часы минимальной нагрузки.
3. Жесткое кодирование ограничений в логике приложения
Некоторые команды предпочитают проверять данные в коде, а не в базе данных. Это приводит к повреждению данных, если несколько сервисов записывают в один и тот же хранилище.
- Решение: Сохраняйте ограничения на уровне базы данных (NOT NULL, ограничения CHECK), даже если приложение распределенное.
Стратегии миграции 🔄
Когда необходимо развивать ERD, вам нужна стратегия, которая минимизирует простои и потери данных.
Паттерн расширения и сжатия
Это золотой стандарт безопасной эволюции схемы.
- Добавить: Добавьте новый столбец или таблицу в схему. Ещё не изменяйте существующую логику.
- Записать: Обновите приложение так, чтобы оно записывало в старую и новую структуры.
- Читать: Обновите приложение так, чтобы оно читало из новой структуры.
- Заполнить данные: Запустите фоновую задачу для заполнения новой структуры старыми данными.
- Договор: После проверки удалите старые столбцы и логику.
Флаги функций
Используйте флаги функций для переключения между старой и новой схемой. Это позволяет немедленно откатиться, если возникнут проблемы, без развертывания скрипта отката.
Документация и версионирование 📝
ERD — это не разовая доставка. Это живой документ. По мере развития модели документация должна соответствовать этому развитию.
Контроль версий для схем
- Рассматривайте файлы схем (SQL-скрипты) как код. Храните их в системе контроля версий.
- Используйте инструменты миграций для отслеживания изменений с течением времени.
- Метки выпусков с версиями схемы (например,
v1.2.0-схема).
Визуальная согласованность
- Стандартизируйте соглашения об именовании (например, snake_case против camelCase).
- Убедитесь, что имена таблиц отражают домен (например,
клиентвместоt1). - Оставляйте комментарии в схеме для контекста бизнес-логики.
Готовность вашей модели к будущему 🚀
Вы не можете предсказать будущее, но можете создать гибкость. Хотя чрезмерная инженерия — это плохо, проектирование с учетом изменений — это умно.
Расширяемые паттерны проектирования
- EAV (сущность-атрибут-значение): Полезно для данных с высокой изменчивостью, хотя при этом теряется производительность запросов.
- Столбцы JSON: Современные базы данных поддерживают типы JSON. Это позволяет хранить гибкие атрибуты без изменения структуры таблицы.
- Системы тегов: Используйте связь «многие ко многим» для метаданных вместо жесткой привязки конкретных атрибутов.
Мониторинг и аудит
- Отслеживайте изменения схемы. Кто что и когда изменил?
- Контролируйте тенденции роста данных. Если таблица растет на 50% в месяц, планируйте разделение до того, как это замедлит работу.
- Настройте оповещения о нарушениях ограничений.
Заключение по адаптивности 🔄
Эволюция ERD отражает зрелость приложения. Она проходит путь от гибкости к целостности, а затем к производительности. Каждая фаза сопряжена с новыми вызовами. Ключевым является предвидение этих изменений и управление ими осознанно.
Не существует единого «идеального» модели. Существует только модель, которая соответствует вашим текущим ограничениям и траектории роста. Понимая компромиссы между нормализацией, денормализацией и архитектурными паттернами, вы можете обеспечить, чтобы ваш слой данных поддерживал ваш бизнес в течение многих лет.
- Начните просто, но планируйте структуру.
- Нормализуйте для целостности, денормализуйте для скорости.
- Документируйте каждое изменение.
- Тщательно тестируйте миграции.
Ваши данные — ваш самый ценный актив. Относитесь к модели, которая их хранит, с должным уважением.